Em dezembro de 2015 , o PHP 7.0 foi lançado. As empresas que mudaram para o "sete" observaram que a produtividade aumentou e a carga no servidor diminuiu. Os primeiros a passar para os sete foram Vebia e Etsy, e temos o Badoo, Avito e OLX. Para o Badoo, a mudança para os sete custa US $ 1 milhão em economia de servidor. Graças ao PHP 7 no OLX, a carga média do servidor diminuiu 3 vezes, aumentando a eficiência e a economia de recursos.
Dmitry Stogov, da Zend Technologies,
falou no
HighLoad ++ , o que aumentou a produtividade. Na decodificação: sobre a estrutura interna do PHP, sobre as idéias no coração da versão 7.0, sobre mudanças nas estruturas de dados e algoritmos básicos que determinaram o sucesso.
Isenção de responsabilidade: em março de 2019, 80% dos sites são executados em PHP e 70% deles são executados em PHP 5, embora esta versão não seja suportada desde 1 de janeiro de 2019 . O relatório de 2016 de Dmitry sobre os princípios pelos quais houve um salto duplo na produtividade entre o PHP 5 e o 7 também é relevante em março de 2019. Para metade dos sites, com certeza.Sobre o palestrante: Dmitry Stogov começou a programar nos anos 80: “Electronics B3-34”, Basic, montador. Em 2002, Dmitry se familiarizou com o PHP e logo começou a trabalhar para melhorá-lo: ele desenvolveu o Turck MMCache para PHP, liderou o projeto PHPNG e desempenhou um papel importante no trabalho no JIT para PHP. Os últimos 14 anos de Engenheiro Principal na Zend Technologies.
A Zend Technologies está desenvolvendo PHP e soluções comerciais com base nele. Em 1999, foi fundada pelos programadores israelenses Andy Gutmans e Zeev Suraski, que há dois anos criaram o PHP 3. Essas pessoas estavam na vanguarda do desenvolvimento do PHP e determinaram amplamente a aparência atual da linguagem e o sucesso da tecnologia.
A Zend Technologies está desenvolvendo o núcleo e os aplicativos PHP e, durante o trabalho, tive que escrever extensões, entrar em todos os subsistemas e até me envolver em projetos comerciais, às vezes nem um pouco relacionados ao PHP. Mas o tópico mais interessante para mim sempre foi o
desempenho .
Comecei a procurar maneiras de acelerar o PHP antes mesmo de ingressar no Zend, trabalhando em meu próprio projeto que competia com a empresa. Durante o trabalho no projeto, entendi completamente a linguagem e percebi que, trabalhando não com o projeto principal, você pode influenciar apenas certos aspectos da execução do script, e tudo o mais interessante e eficaz pode ser criado
apenas no kernel . Esse entendimento e coincidência me levaram ao Zend.
Uma pequena digressão na história do PHP
PHP não é apenas e
não apenas uma linguagem de programação . PHP significa Personal Home Page - uma ferramenta para criar páginas pessoais e sites dinâmicos. A linguagem é apenas uma de suas partes principais. O PHP é uma enorme biblioteca de funções, muitas extensões para trabalhar com outras bibliotecas de terceiros, por exemplo, para acessar o banco de dados ou analisadores XML, além de um conjunto de módulos para comunicação com vários servidores da web.
O programador dinamarquês
Rasmus Lerdorf introduziu o PHP
em junho de 1995 . Naquela época, era apenas uma
coleção de scripts CGI escritos em Perl . Em abril de 96, Rasmus introduziu o PHP / FI e, em junho, o PHP / FI 2.0 foi lançado. Posteriormente, esta versão foi substancialmente reformulada por Andy Gutmans e Zeev Surasky, e no 98º lançamento do PHP 3.0. Em 2000, a linguagem chegou ao tipo que estamos acostumados a ver hoje em termos de linguagem e arquitetura interna - PHP 4, baseado no Zend Engine.
Desde a versão 4, o PHP evoluiu. O ponto de virada foi o lançamento do PHP 5 em 2004, quando o
modelo de objeto foi completamente atualizado . Foi ela quem abriu a era das estruturas PHP e elevou a questão do desempenho a um novo nível. Antecipando isso, imediatamente após o lançamento do 5.0, nós do Zend pensamos em acelerar o PHP e começamos a trabalhar para melhorar a produtividade.
A versão 7.1, lançada em novembro de 2016 em testes sintéticos,
é 25 vezes mais rápida que a versão de 2002 . De acordo com o gráfico das alterações de desempenho em diferentes ramos, os principais avanços são visíveis em 5.1 e 7.0.

Na versão 5.1, começamos a trabalhar no desempenho, e tudo o que assumimos - acabou sendo, mas depois do 5.3 encontramos uma barreira, todas as tentativas de melhorar o intérprete não deram em nada.
No entanto, descobrimos onde cavar e obtivemos ainda mais do que o esperado - aceleração de 2,5 vezes em comparação com a versão anterior 5.6 nos testes. Mas o mais interessante é que obtivemos a mesma aceleração de 2,5 vezes em aplicativos reais inalterados. Este é um fenômeno, porque desenvolvemos o fator 2 anterior ao longo da vida dos cinco em dez anos.
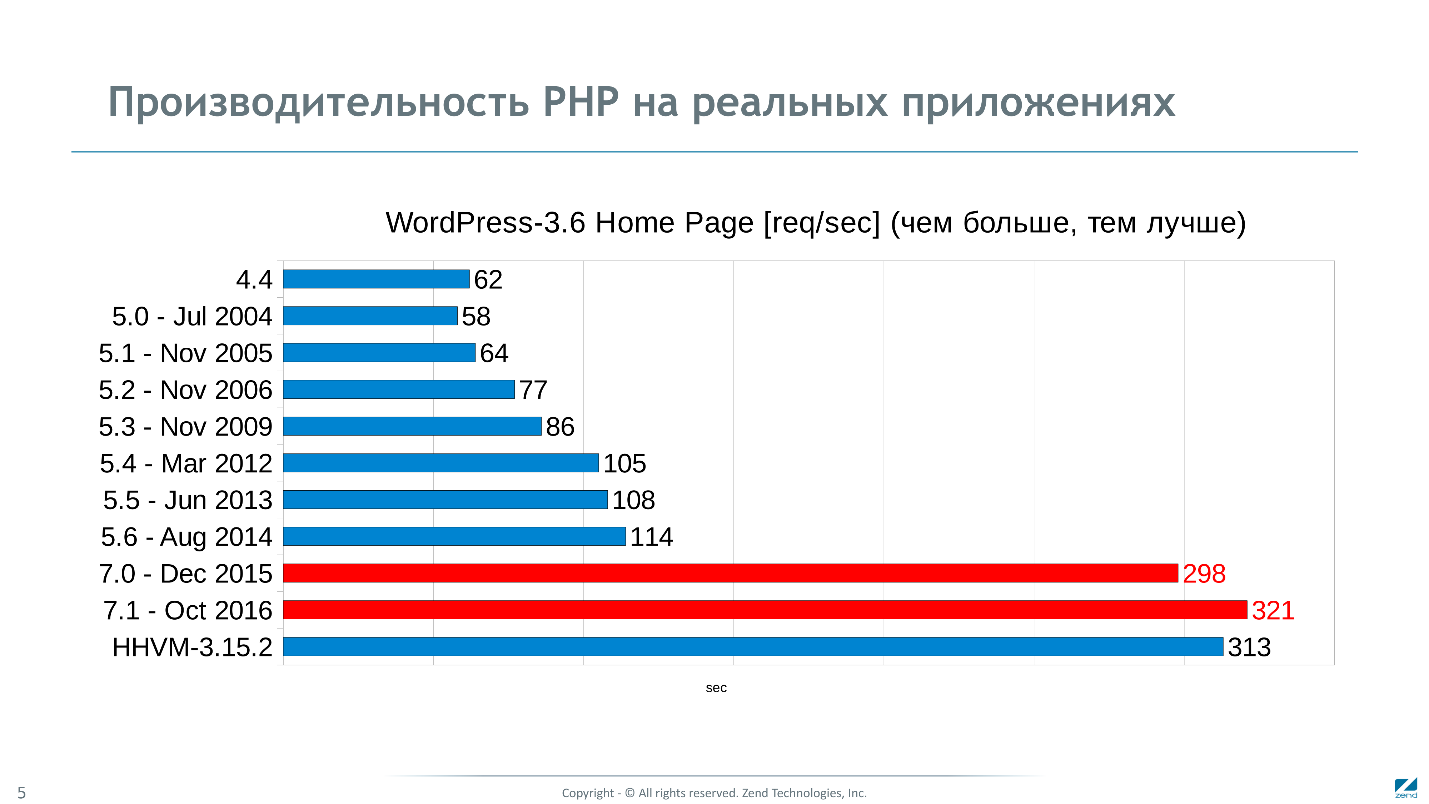
O enorme salto em 5.1 nos testes sintéticos não é perceptível em aplicações reais. O motivo é que, com diferentes usos, o desempenho do PHP depende dos freios associados a diferentes subsistemas.
A história do PHP 7 começa com uma estagnação de três anos que começou em 2012 e terminou em 2015 com o lançamento da sétima versão. Então percebemos que não podíamos mais aumentar a produtividade com pequenas melhorias de nosso intérprete e voltamos para o lado do JIT.
Vagando pelo JIT
Passamos quase dois anos no protótipo JIT para PHP-5.5. Inicialmente, geramos um código muito simples - uma sequência de chamadas para manipuladores padrão, algo como um código Fort costurado. Em seguida, eles escreveram seu próprio
Runtime Assembler , um código separado para soluções alternativas, mas perceberam que essas
otimizações de baixo nível não davam efeito
prático nem nos testes.
Então pensamos em derivar tipos de variáveis usando métodos de análise estática. Tendo percebido a conclusão, recebemos imediatamente a
aceleração em duas vezes nos testes. Encorajados, eles tentaram escrever alocadores de registros globais, mas falharam. Usamos uma representação de alto nível e era quase impossível usá-la para alocação de registros.
Para evitar problemas de baixo nível, decidimos experimentar o LLVM e, um ano depois, obtivemos uma
aceleração de 10x para o bench.php , mas nada em aplicativos reais. Além disso, a compilação de aplicativos reais agora levou minutos, por exemplo, a primeira
solicitação para o Wordpress levou 2 minutos e não deu aceleração. Obviamente, isso era completamente inadequado para a prática real.
Um bom código é possível com a previsão de tipo adequada, que funciona mal em aplicativos reais, e o uso de estruturas de dados PHP torna o código gerado ineficiente.
O que diminui a velocidade?
Repensamos as razões das falhas e decidimos mais uma vez ver por que o PHP é lento. A imagem mostra o resultado da criação de perfil de vários pedidos na página inicial do Wordpress.
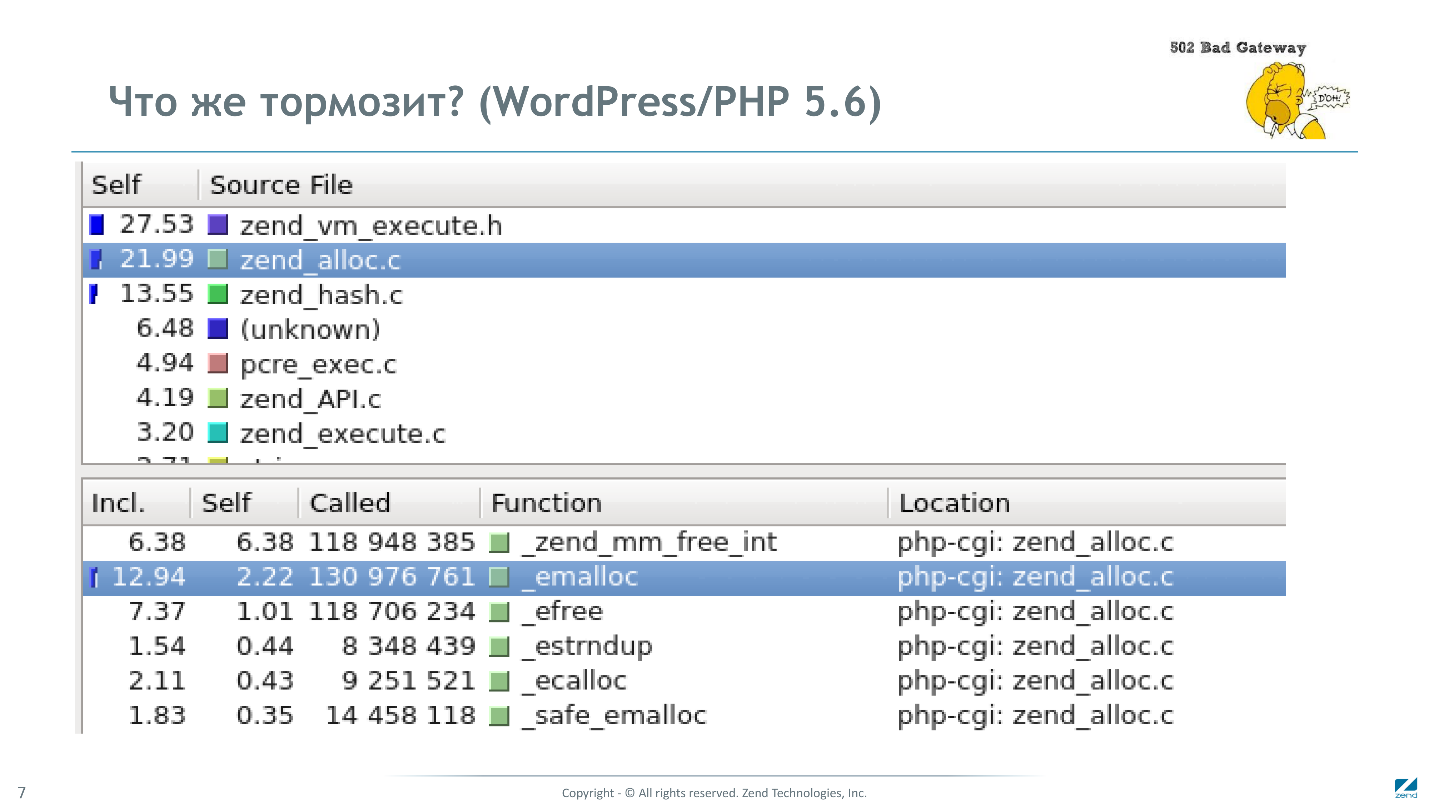
Menos de 30% é gasto na interpretação de código de código, 20% é a sobrecarga do gerenciador de memória, 13% está trabalhando com tabelas de hash e 5% está trabalhando com expressões regulares.
Trabalhando no JIT, nos livramos apenas dos primeiros 30% e tudo o mais estava em peso morto. Em quase todos os lugares, fomos forçados a usar estruturas de dados PHP padrão, o que implicava sobrecarga: alocação de memória, contagem de referência etc. Esse entendimento levou à conclusão de que é necessário substituir as principais estruturas de dados no PHP. Com essa
substituição da fundação , o projeto
PHPNG começou.Phpng Nova geração
O projeto foi desenvolvido após tentativas malsucedidas de criar JIT para PHP. O objetivo principal é
alcançar um novo nível de produtividade e estabelecer as bases para futuras melhorias .
Prometemos a nós mesmos por algum tempo não usar mais testes sintéticos para medir o desempenho - geralmente são pequenos programas de computação que usam uma quantidade limitada de dados que se encaixa completamente no cache do processador. Aplicações reais, ao contrário, estão sujeitas aos freios associados à memória do subsistema, e uma única leitura da memória pode custar 100 instruções computacionais.
O projeto PHPNG é uma refatoração das principais estruturas de dados PHP para otimizar o acesso à memória . Nenhuma inovação, 100% compatível com PHP 5.
Como mudar essas estruturas estava claro. Mas o volume de mudanças dependentes foi enorme, porque o
núcleo do PHP em si
é de 150.000 linhas e quase todo terço precisava ser alterado. Adicione mais cem extensões incluídas na distribuição básica, uma dúzia de módulos para diferentes servidores da Web e você perceberá a grandeza do projeto.
Não tínhamos certeza de que terminaríamos o projeto. Portanto, eles lançaram o projeto em segredo e o abriram apenas quando os primeiros resultados otimistas apareceram. Demorou duas semanas para
compilar o kernel . Duas semanas depois, o bench.php ganhou. Passamos um mês e meio para garantir o trabalho do Wordpress. Um mês depois, abrimos o projeto - era maio de 2014. Naquela época, tivemos uma
aceleração de 30% no Wordpress . Já parecia um grande evento.
O PHPNG despertou imediatamente uma onda de interesse e, em agosto de 2014, foi
adotado como base para o futuro do PHP 7 . Já era outro projeto, com um conjunto diferente de objetivos, onde a produtividade era apenas um deles.
PHP 7.0
A versão número 7 estava em dúvida. A versão anterior foi a quinta. E o sexto foi desenvolvido há vários anos e foi completamente dedicado ao suporte nativo a
Unicode , mas as decisões malsucedidas tomadas nos estágios iniciais do desenvolvimento levaram à complexidade excessiva do código do kernel e de cada extensão. No final, foi decidido congelar o projeto.
Nessa época, já havia sido acumulado muito material dedicado ao PHP 6: discursos em conferências, livros publicados. Para não confundir ninguém, chamamos o projeto PHP 7, pulando o PHP 6. Esta versão foi muito mais sortuda - o PHP 7 foi lançado em dezembro de 2015, quase conforme o planejado.
Além do desempenho, algumas inovações há muito procuradas apareceram no PHP 7:
- Capacidade de definir tipos escalares de parâmetros e retornar valores.
- Exceções em vez de erros - agora podemos capturá-las e processá-las.
- Apareceu
Zero-cost assert() , classes anônimas, inconsistências de limpeza, novos operadores e funções (<=>, ??).
A inovação é boa, mas voltando às mudanças internas. Vamos falar sobre o caminho que o PHP 7 seguiu e para onde esse caminho pode nos levar.
zval
Essa é a estrutura básica de dados PHP. É usado para
representar qualquer valor em PHP . Como nossa linguagem é digitada dinamicamente e o tipo de variáveis pode ser alterado durante a execução do programa, precisamos armazenar um campo de tipo (tipo zend_uchar), que pode receber os valores IS_NULL, IS_BOOL, IS_LONG, IS_DOUBLE, IS_ARRAY, IS_OBJECT etc., e de fato o valor representado por union (value), onde um número inteiro, número real, string, matriz ou objeto pode ser armazenado.
zval no PHP 5
A memória para cada uma dessas estruturas foi alocada separadamente no Heap. Além do tipo e valor, o contador de referências à estrutura também foi armazenado nela. Portanto, a estrutura ocupou 24 bytes, sem contar a sobrecarga do gerenciador de memória e o ponteiro para ele.
A figura no canto superior direito mostra as estruturas de dados que foram criadas na memória do PHP 5 para um script simples.

Na pilha, a memória foi alocada para 4 variáveis representadas por ponteiros. Os próprios valores (zval) estão na pilha. No nosso caso, esses são apenas dois zval, cada um dos quais é referenciado por duas variáveis e, portanto, seus contadores de referência são definidos como 2.
Para acessar um tipo ou valor escalar, você precisa de pelo menos duas leituras: primeiro leia o valor do ponteiro e, em seguida, o valor da estrutura. Se você precisar ler não um valor escalar, mas, por exemplo, parte de uma string ou matriz, precisará de pelo menos mais uma leitura.
zval no PHP 7
Onde usamos ponteiros antes, nos sete começamos a incorporar zval. Afastamos a contagem de referência para tipos escalares. Os campos tipo e valor permaneceram sem alterações significativas, mas foram adicionadas mais algumas bandeiras e um local reservado, sobre o qual falarei um pouco mais adiante.

À esquerda está o que parecia no PHP 5, e à direita, no PHP 7.

Agora, o próprio zval está na pilha. Para ler tipos e valores escalares, apenas uma instrução de máquina é suficiente. Todos os valores são agrupados em uma área de memória, o que significa que, ao trabalhar com variáveis locais, praticamente não teremos perdas devido a falhas no cache do processador. Mas o verdadeiro poder do novo desempenho é incluído quando a cópia é necessária.
Copiar registro
Na linha superior do script, outra tarefa foi adicionada.

No PHP5, alocamos memória do heap para um novo zval, inicializamos seu int (2), alteramos o valor do ponteiro para a variável b e diminuímos o contador de referência do valor ao qual b havia se referido anteriormente.
No PHP 7, nós simplesmente
inicializamos a variável b diretamente no lugar com algumas instruções , enquanto no PHP 5 ele exigia centenas de instruções. Então o zval parece agora na memória.
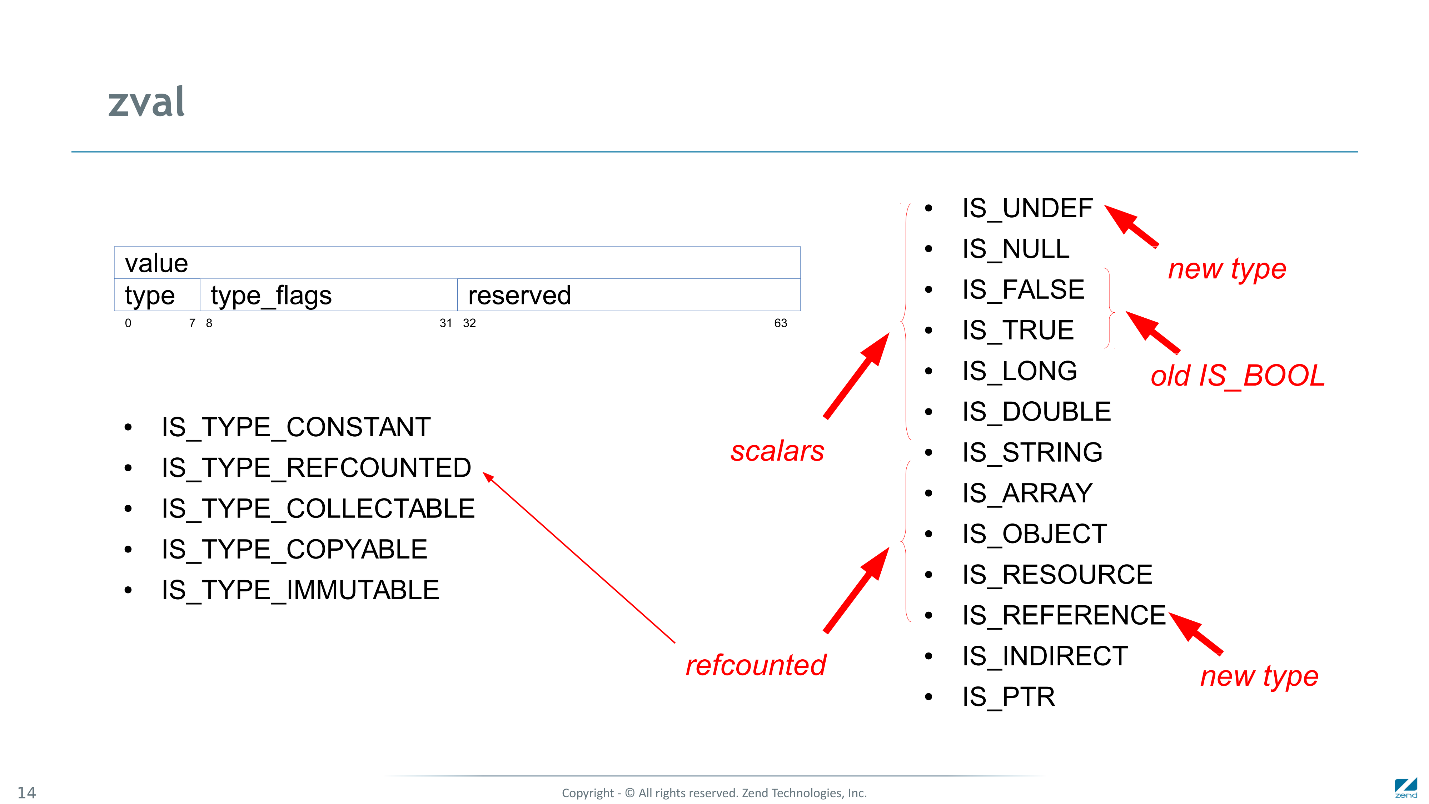
Estas são duas palavras de 64 bits. A primeira palavra é
significado: inteiro, real ou ponteiro. Na segunda palavra, o
tipo (diz como interpretar o significado), sinalizadores e um local reservado que ainda seria adicionado ao alinhar. Mas não desaparece, mas é usado por diferentes subsistemas para armazenar valores indiretamente relacionados.
Flags são um conjunto de bits em que cada bit indica se o zval suporta um protocolo. Por exemplo, se for
IS_TYPE_REFCOUNTED , ao trabalhar com esse zval, o mecanismo deve cuidar do valor do contador de referência. Ao atribuir, aumente; ao sair do escopo, diminua; se o contador de referência atingir zero, destrua a estrutura dependente.
Dos tipos, comparados ao PHP 5, vários novos apareceram.
IS_UNDEF - um marcador de uma variável não inicializada.- O único
IS_BOOL substituído por IS_FALSE e IS_FALSE separados. - Adicionado um tipo separado para links e mais alguns tipos mágicos.
Os tipos de
IS_UNDEF a
IS_DOUBLE são escalares e não requerem memória adicional. Para copiá-las, basta copiar a primeira palavra de 64 bits da máquina com um valor e metade do segundo com um tipo e sinalizadores.
Recontado
Com outros tipos mais difíceis. Todos eles são representados por uma estrutura subordinada, e o zval simplesmente armazena uma referência a essa estrutura. Para cada tipo, essa estrutura é diferente, mas em termos de POO, todos eles têm um ancestral ou estrutura abstrata comum zend_refcounted. Ele determina o formato da primeira
palavra de 64 bits , onde a contagem de referência e outras informações para o coletor de lixo são armazenadas.

Essa palavra pode ser considerada simplesmente como informação para o coletor de lixo, e estruturas para tipos específicos adicionam seus campos após essa primeira palavra.
Linhas
Nos sete da string, armazenamos o valor calculado da função hash, seu comprimento e os próprios caracteres. O tamanho dessa estrutura é variável e depende do comprimento da sequência. A função hash é calculada para a sequência uma vez, quando necessário. No PHP 5, foi recalculado a cada necessidade.

Agora, as strings se tornaram contáveis por referência, e se no PHP 5 copiámos os próprios caracteres, agora é suficiente aumentar a contagem de referência para essa estrutura.
Como no PHP 5, ainda temos o conceito de
seqüências imutáveis ou internas . Eles geralmente existem em uma instância, permanecem até o final da consulta e podem se comportar como valores escalares. Não precisamos cuidar do contador de referências a eles e, para copiar, basta copiar apenas o próprio zval com a ajuda de quatro instruções da máquina.
Matrizes
As matrizes são representadas por uma tabela de hash embutida e não são muito diferentes do PHP 5. A própria tabela de hash mudou, mas mais sobre isso separadamente.

Agora, as matrizes são uma
estrutura adaptativa que altera levemente sua estrutura e comportamento internos, dependendo dos dados armazenados. Se armazenarmos apenas elementos com chaves numéricas fechadas, teremos acesso diretamente aos elementos por índice com uma velocidade comparável à velocidade de matrizes em C.
É assim que a tabela de hash se parece no PHP 5.
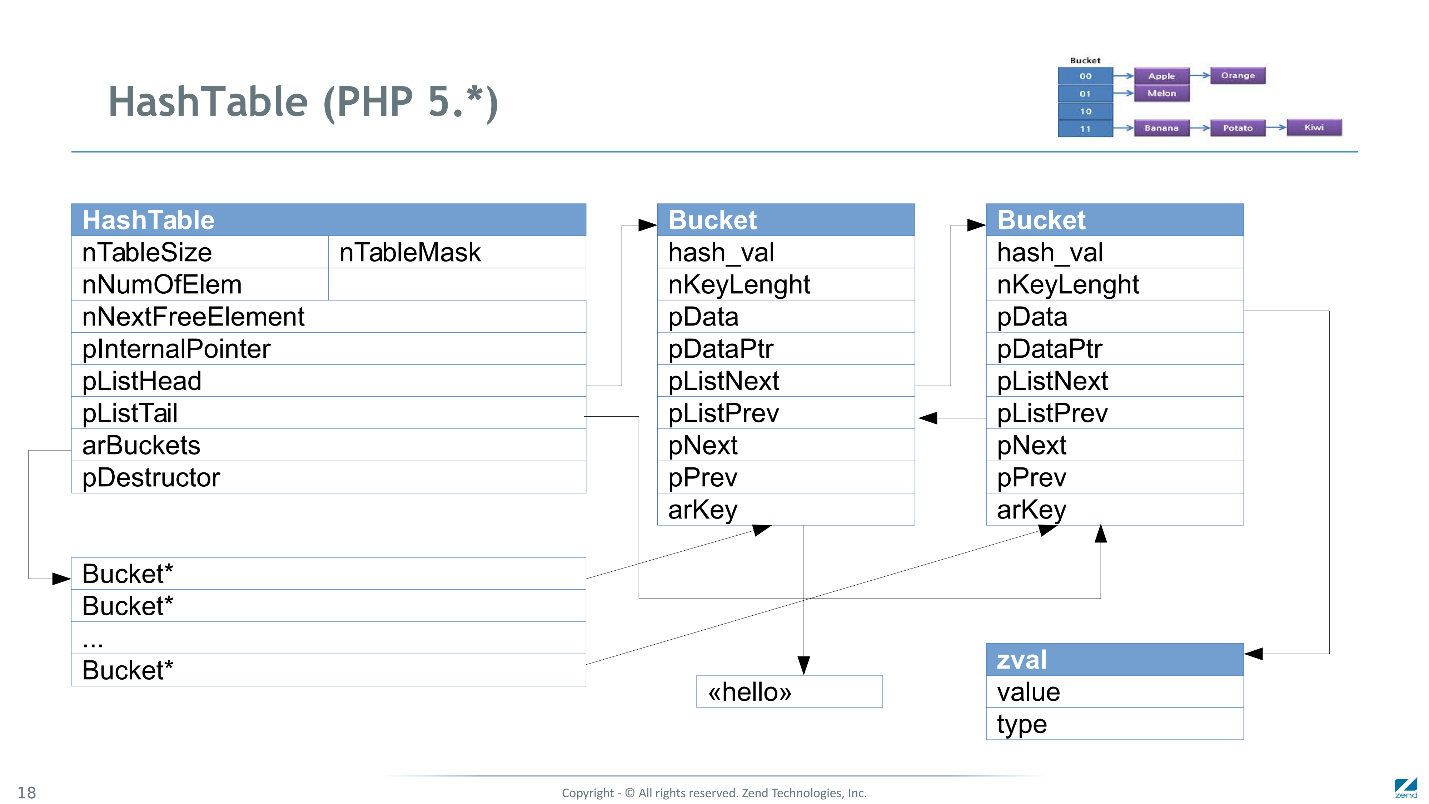
Esta é uma implementação clássica de tabela de hash com resolução de colisão usando listas lineares (mostradas no canto superior direito). Cada item é representado por um balde. Todos os buckets são vinculados por listas duplamente vinculadas para resolver colisões e vinculados por outra lista duplamente vinculada para iterar em ordem. Os valores para cada zval são alocados separadamente - no Bucket, apenas armazenamos um link para ele. Além disso, as chaves de sequência podem ser alocadas separadamente.
Assim, para cada tabela de hash, você precisa alocar muitos pequenos blocos de memória e, para encontrar algo mais tarde, precisa executar os ponteiros. Cada uma dessas transições pode causar perda de carga e um atraso de ~ 10-100 ciclos do processador.
Foi o que aconteceu no PHP 7.

A estrutura lógica permaneceu inalterada, apenas a física mudou. Agora, em uma tabela de hash, a memória é alocada com uma operação.
Na figura, na parte inferior do ponteiro base, existem elementos e, na parte superior, há uma matriz de hash endereçada por uma função de hash. Para matrizes planas ou compactadas, quando armazenamos apenas elementos com índices numéricos, a parte superior não é alocada e endereçamos o bucket diretamente por número.
Para ignorar elementos, nós os classificamos sequencialmente de cima para baixo ou de baixo para cima, o que os processadores modernos fazem na perfeição. Os valores são incorporados nos buckets, mas o espaço reservado neles é usado apenas para resolver colisões. Ele armazena o índice de outro Balde com o mesmo valor da função de hash ou o final do marcador da lista.
A memória para os valores da string das chaves é alocada separadamente, mas ainda é a mesma zend_string. Ao colar em uma matriz, basta aumentar o contador de referência da string, embora antes tenhamos que copiar os caracteres diretamente e, ao pesquisar, agora possamos comparar não os caracteres, mas os ponteiros para as próprias strings.
Matrizes imutáveis
Anteriormente, tínhamos seqüências imutáveis, mas agora matrizes imutáveis também apareceram. Como cadeias de caracteres, elas não usam a contagem de referência e não são destruídas até o final da solicitação. Este é um script simples que cria uma matriz de um milhão de elementos e cada elemento é a mesma matriz com um único elemento "olá".

No PHP 5, a cada iteração de loop, uma nova matriz vazia era criada, o "hello" era gravado nela e tudo isso era adicionado à matriz resultante. No PHP 7, em tempo de compilação,
criamos apenas um array imutável que se comporta como um escalar e o adicionamos ao resultante. No exemplo apresentado, isso nos permite obter uma redução de mais de 10 vezes no consumo de memória e uma aceleração de quase 10 vezes.
Matrizes constantes de milhões de elementos em aplicações reais, é claro, nem sempre são encontradas, mas as pequenas são bastante comuns. Em cada um deles você terá uma pequena, mas uma vitória.
Os objetos
Os links para todos os objetos no PHP 5 estavam em um repositório separado, e no zval havia apenas identificador - um ID de objeto exclusivo.
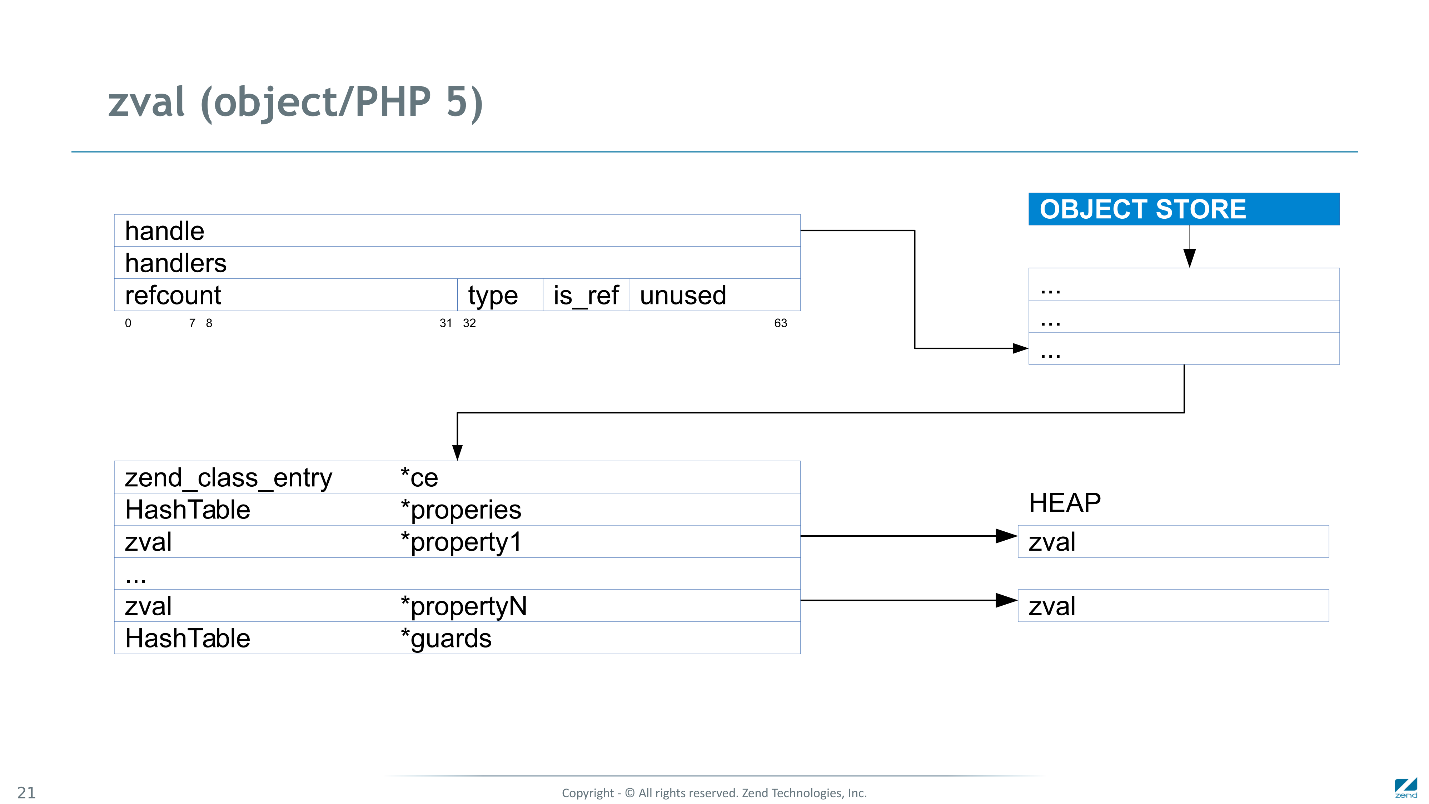
Para chegar ao objeto, fizemos pelo menos três leituras. Além disso, a memória para o valor de cada propriedade do objeto foi alocada separadamente, e precisávamos de pelo menos mais 2 leituras para lê-lo.
No PHP 7, fomos capazes de passar para o endereçamento direto.

O endereço
zend_object está acessível com uma única instrução de máquina. E as propriedades são incorporadas e, para lê-las, você precisa de apenas uma leitura adicional. Eles também são agrupados, o que
melhora a localização dos dados e ajuda os processadores modernos a não tropeçar.
Além da propriedade predefinida, um link para a classe desse objeto também é armazenado aqui, alguns manipuladores - um análogo de tabelas de métodos virtuais e uma tabela de hash para propriedades que não foram definidas. No PHP, você pode adicionar propriedades a qualquer objeto que não foi definido originalmente e, se várias instruções da máquina forem suficientes para acessar a propriedade predefinida, para propriedades não predefinidas, será necessário usar uma tabela de hash, o que exigirá dezenas de instruções da máquina. Claro, isso é muito mais caro.
Referência
Finalmente, tivemos que introduzir um
tipo separado para representar links PHP.

Este é um tipo completamente transparente. Não é visível para scripts PHP. Os scripts veem outro zval incorporado à estrutura zend_reference. Entende-se que nos referimos a uma dessas estruturas de pelo menos dois locais, e o contador de referência dessa estrutura é sempre maior que 1. Assim que o contador cai para 1, o link se transforma em um valor escalar regular. O zval incorporado no link é copiado para o último zval que o referencia e a própria estrutura é excluída.
Parece que trabalhar com referência agora é muito mais complicado do que com outros tipos (e isso é verdade), mas na verdade no PHP 5 tivemos que fazer um trabalho de complexidade comparável ao acessar qualquer valor (mesmo um número inteiro primo). Agora, estamos aplicando protocolos mais complexos a apenas um tipo e, portanto, aceleramos o trabalho com todos os outros, especialmente com valores escalares.
IS_FALSE e IS_TRUE
Eu já disse que o tipo único IS_BOOL foi dividido em IS_FALSE e IS_TRUE. Essa idéia foi espionada na implementação do LuaJIT e foi criada para acelerar uma das operações mais comuns - a transição condicional.

Se no PHP 5 foi necessário ler o tipo, verificar booleano, ler o valor, descobrir se é verdadeiro ou falso e fazer uma transição com base nisso, agora basta verificar o tipo e compará-lo com true:
- se é verdade, seguimos um ramo;
- se for menor que verdade, vá para outro ramo;
- se for mais do que verdadeiro, vá para o chamado caminho lento (caminho lento) e lá verificamos de que tipo ele veio e o que fazer com ele: se for inteiro, devemos comparar seu valor com 0, se float - novamente com 0 ( mas real) etc.
Convenção de chamada
Uma alteração na convenção de chamada ou convenção de chamada de função é uma otimização importante que afeta não apenas as estruturas de dados, mas também os algoritmos subjacentes. Na figura à esquerda, há um pequeno script que consiste na função foo () e em sua chamada. Abaixo está o bytecode no qual este script foi compilado pelo PHP 5.

Primeiro, eu vou lhe contar como funcionou no PHP 5.
Convenção de Chamada no PHP 5
A primeira instrução
SEND_VAL foi enviar o valor "3" para a função foo. Para fazer isso, ela foi forçada a alocar um novo zval na pilha, copiar o valor (3) lá e escrever o valor do ponteiro nessa estrutura na pilha.
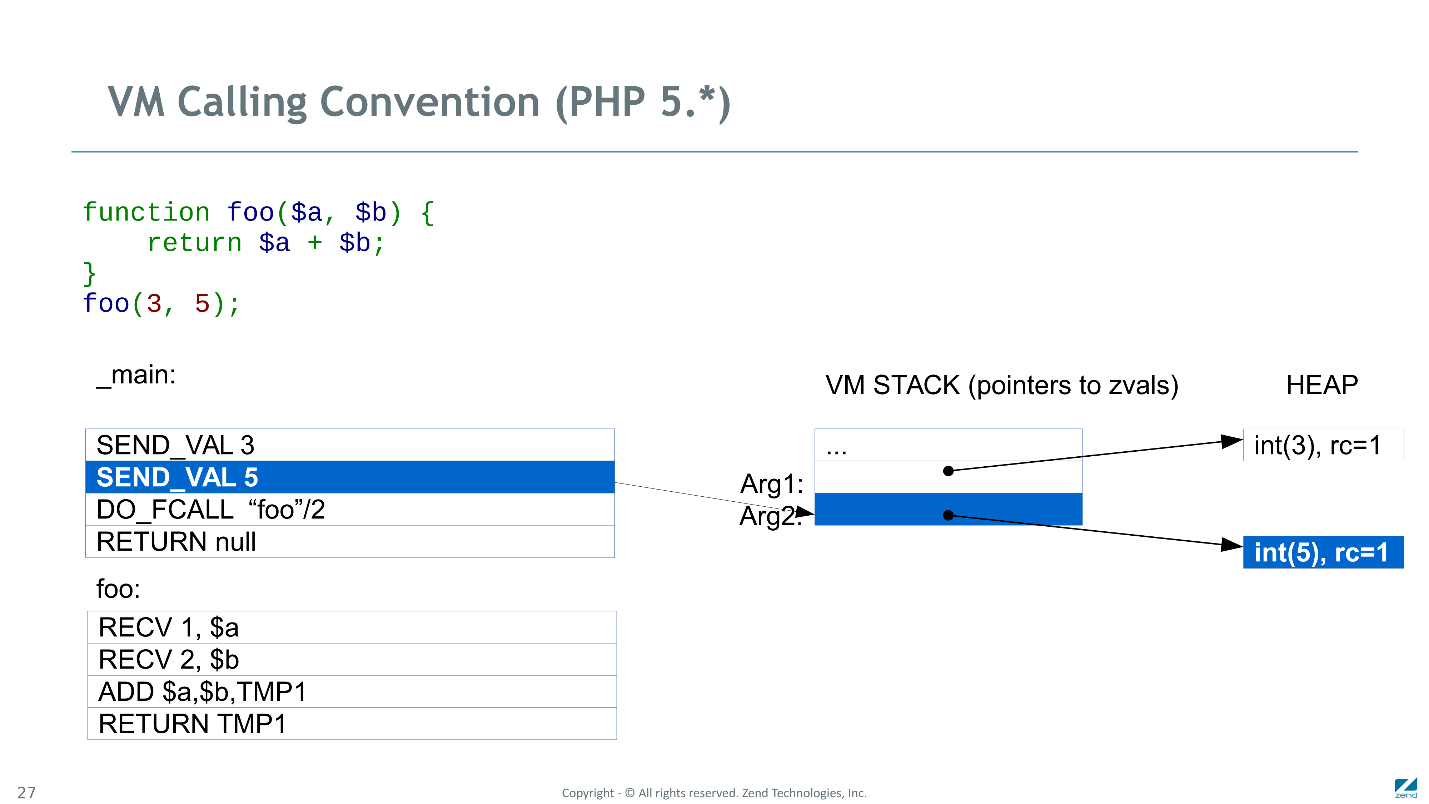
Da mesma forma com a segunda instrução.
DO_FCALL inicializou
CALL FRAME , reservou um local para variáveis locais e temporárias e transferiu o controle para a função chamada.
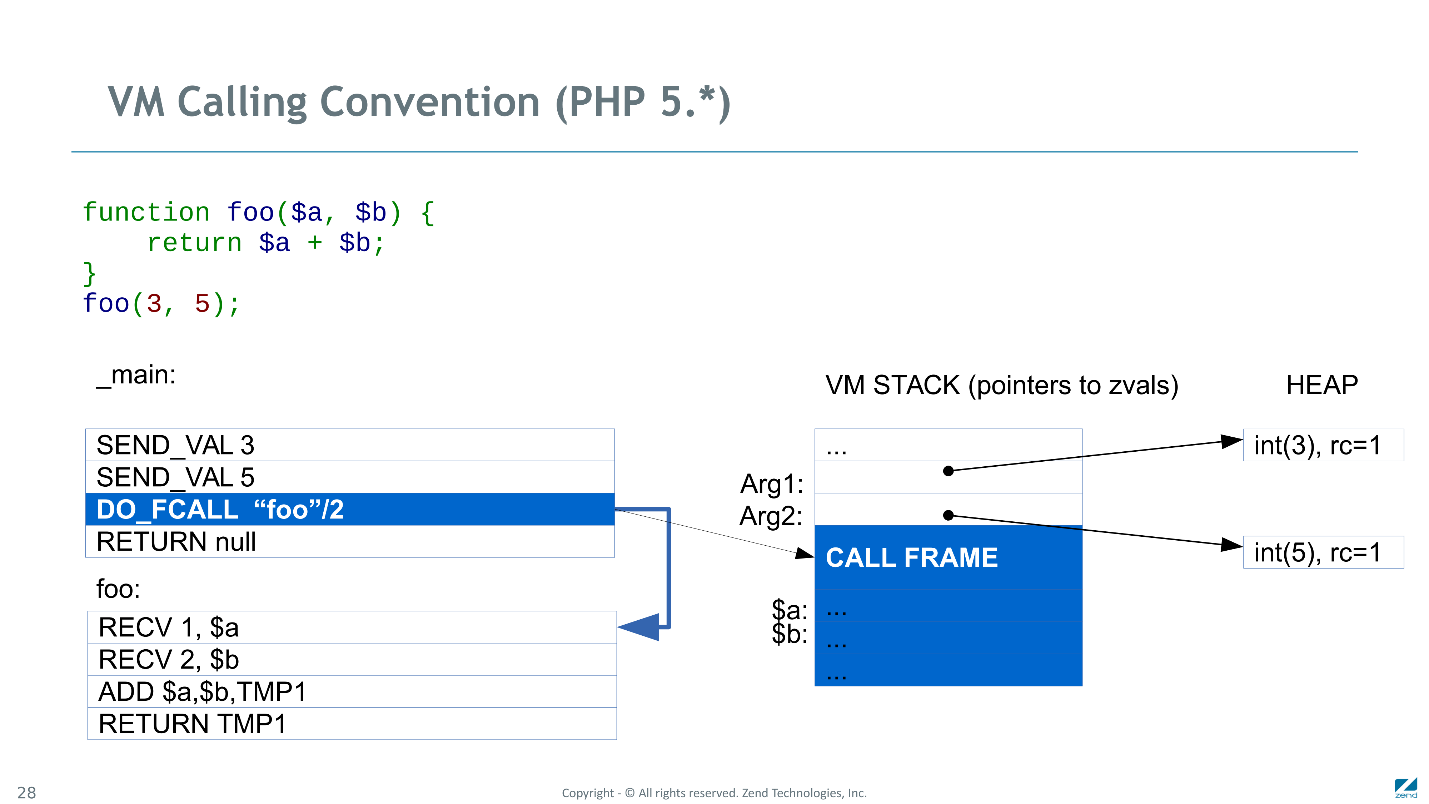
A primeira
RECV verificou o primeiro argumento e inicializou o slot na pilha com a variável local correspondente ($ a). Aqui fizemos sem copiar e simplesmente aumentamos o contador de referência do parâmetro correspondente (zval com um valor de 3). Da mesma forma, a segunda
RECV estabeleceu uma conexão entre a variável $ be o parâmetro 5.

Outras funções corporais. A adição de 3 + 5 aconteceu - resultou em 8. Esta é uma variável temporária e seu valor foi armazenado diretamente na pilha.

RETURN e retornamos da função.

Ao retornar, liberamos todas as variáveis e argumentos que estão fora do escopo. Para fazer isso, passamos por todo o zval referenciado por slots do quadro liberado e, para cada um, diminuímos a contagem de referência. Se atingir 0, destrua a estrutura correspondente.
Como você pode ver, mesmo uma operação simples como enviar uma constante para uma função requer alocar nova memória, copiar e aumentar o contador de referência e, em seguida, diminuir e excluir duas vezes.
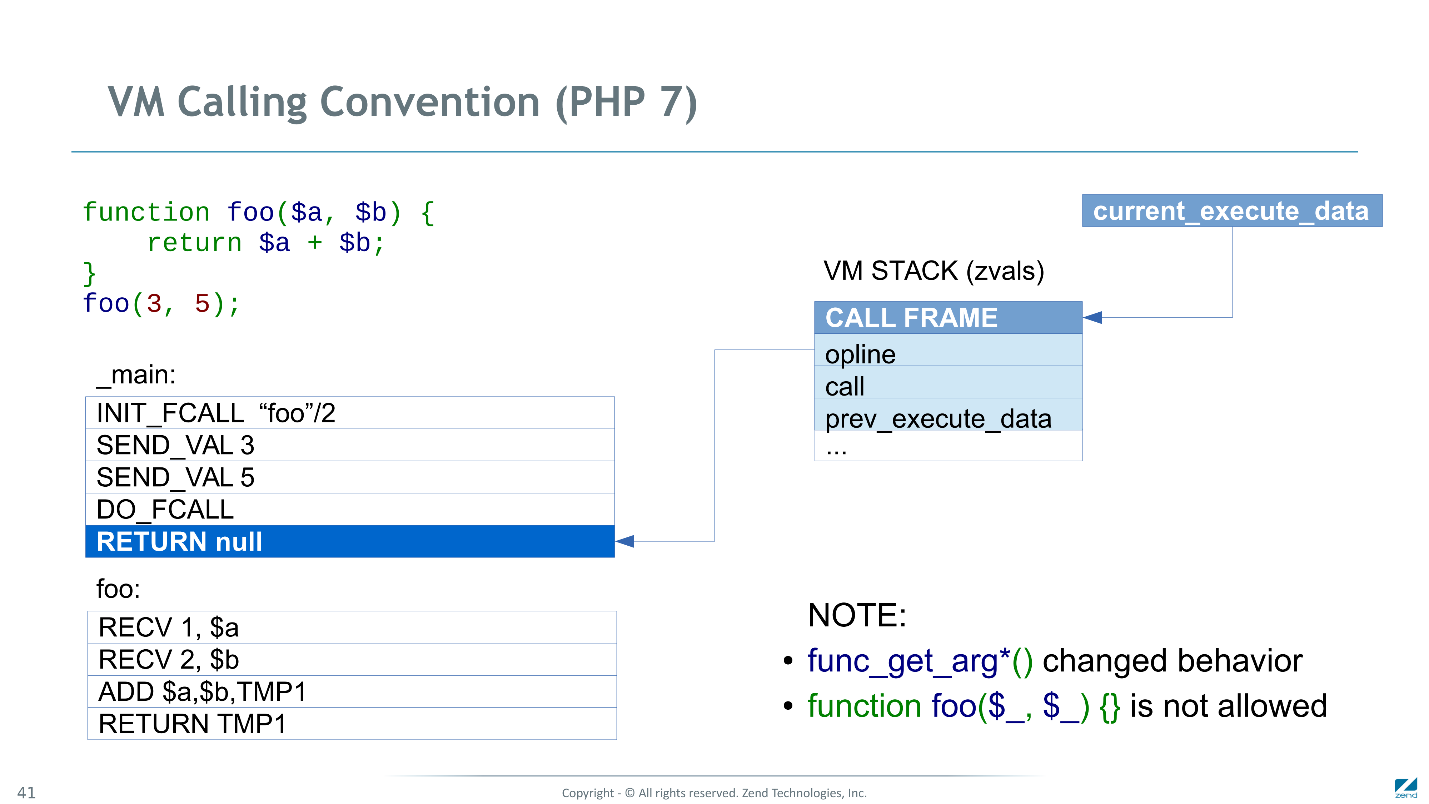
Convenção de Chamada no PHP 7
No PHP 7, esses problemas foram corrigidos - agora, na pilha, armazenamos não os ponteiros zval, mas os próprios zval.

Também introduzimos uma nova instrução,
INIT_FCALL , que agora é responsável por inicializar e alocar memória sob
CALL FRAME e reservar espaço para argumentos e variáveis temporárias.

SEND_VAL 3 agora apenas copia o argumento para o primeiro espaço após o
CALL FRAME . Próximo
SEND_VAL 5 para o segundo espaço.

Então o mais interessante. Parece que
DO_FCALL deve passar o controle para a primeira instrução da função chamada. Mas os argumentos já atingiram os slots reservados para os parâmetros variáveis $ a e $ b, e as instruções
RECV simplesmente não fazem nada. Portanto, você pode simplesmente ignorá-los. Enviamos dois parâmetros, então pulamos duas instruções. Se eles mandassem três, teriam perdido três.

Então, vamos diretamente ao corpo da função, fazemos acréscimos e retornamos.

Ao retornar, limpamos todas as variáveis locais, mas agora apenas para dois slots, e como temos escalares lá, novamente não precisamos fazer nada.

Minha história é um pouco simplificada, não leva em conta funções com um número variável de argumentos e a necessidade de verificação de tipo e alguns outros pontos.
A nova convenção de chamadas quebrou um pouco a compatibilidade . O PHP possui funções como
func_get_arg e
func_get_args . Se antes eles retornavam o valor original do parâmetro enviado, agora retornam o valor atual da variável local correspondente, porque simplesmente não armazenamos os valores originais. Assim como o C. debuggers
Além disso, a função não pode mais ter vários parâmetros com o mesmo nome. Não havia sentido nisso antes, mas eu conheci esse código PHP
foo($_, $_) . Como é isso? (Eu reconheci Prolog)
Novo gerenciador de memória
Concluindo a otimização das estruturas de dados e dos algoritmos básicos, chamamos novamente a atenção para todos os subsistemas de frenagem. O gerenciador de memória no PHP 5 ocupou
quase 20% do tempo do processador no Wordpress.
Depois que nos livramos de muitas alocações, seus custos indiretos se tornaram menores, mas ainda significativos - e não porque ele estava fazendo um trabalho significativo, mas porque tropeçou no cache. Isso se deve ao fato de termos utilizado o algoritmo malloc clássico de Doug Lea, que envolvia a localização adequada de memória livre viajando através de links e árvores, e todas essas viagens causavam inevitavelmente falhas no cache.
Atualmente, existem novos algoritmos de gerenciamento de memória que levam em consideração os recursos dos processadores modernos. Por exemplo:
jemalloc e
ptmalloc do Google . Inicialmente, tentamos usá-los inalterados, mas não obtivemos uma vitória, pois a falta de funcionalidade específica do PHP tornava mais caro liberar completamente a memória no final da solicitação. Como resultado, abandonamos o dlmalloc e escrevemos algo próprio, combinando idéias do antigo gerenciador de memória e jemalloc.
Reduzimos a sobrecarga do Memory Manager para 5% , reduzimos a sobrecarga de memória para obter informações de serviço e melhoramos o uso do cache da CPU. Os blocos de memória adequados agora são pesquisados por bitmaps, a memória para blocos pequenos é alocada em páginas separadas e armazenada em cache após a liberação, adicionando funções especializadas para tamanhos de bloco usados com freqüência.
Muitas pequenas melhorias
Falei apenas sobre as melhorias mais importantes, mas houve muito mais pequenas. Eu posso mencionar alguns deles.
- API rápida para analisar parâmetros de funções internas e uma nova API para iterar no HashTable.
- Novas instruções da VM: concatenação de strings, especialização, super instruções.
- Algumas funções internas foram transformadas em instruções da VM: strlen, is_int.
- Usando registros da CPU para registros da VM: IP e FP.
- Otimização da duplicação e exclusão de matrizes.
- Usar a contagem de links em vez de copiar sempre que possível.
- PCRE JIT.
- Otimização de funções internas e serialização ().
- Tamanho de código reduzido e dados processados.
Alguns eram muito simples, por exemplo, eram necessárias apenas três linhas de código para habilitar o JIT em expressões Perl regulares, e isso imediatamente trouxe aceleração visível (2-3%) para quase todos os aplicativos. Outras otimizações abordaram alguns aspectos estreitos de certas funções do PHP e não são particularmente interessantes, embora a contribuição total de todas essas pequenas melhorias seja bastante significativa.
O que você veio a
Esta é a contribuição de vários subsistemas no WordPress / PHP 7.0.
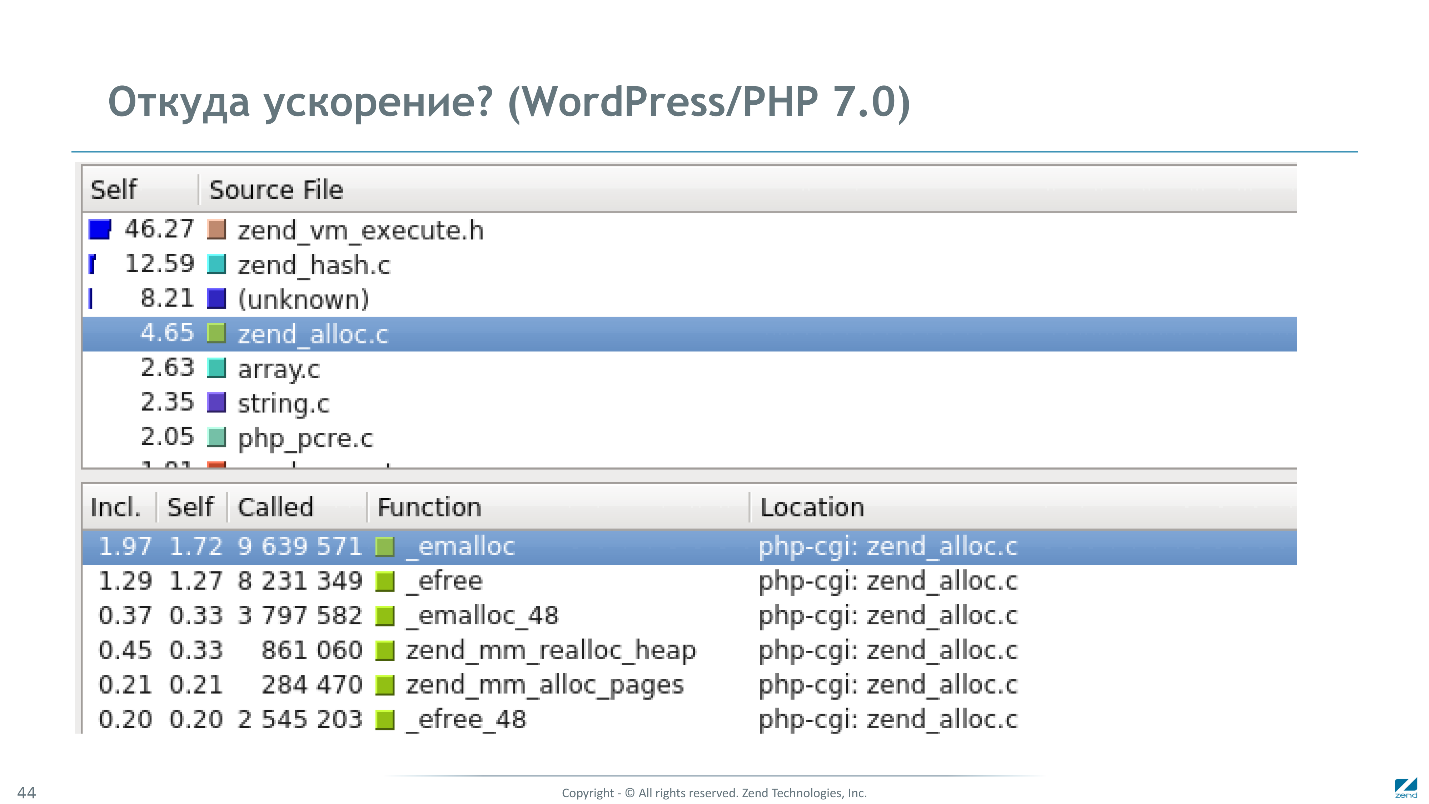
A contribuição da máquina virtual aumentou para 50%. Memory Manager 5% — Memory Manager, . 130 . , 10 . , Memory Manager , .

:
- 2 .
- MM 17 .
- - 4 .
- WordPress 3,5 .
2,5- , . ? , , CPU time, — , . PHP , .
PHP 7
WordPress 3.6 — . - , PHP 7 mysql, , .

, PHPNG. 2/3 . , .
, WordPress, , — 1,5 2- .
PHP 7 HHVM
HHVM.
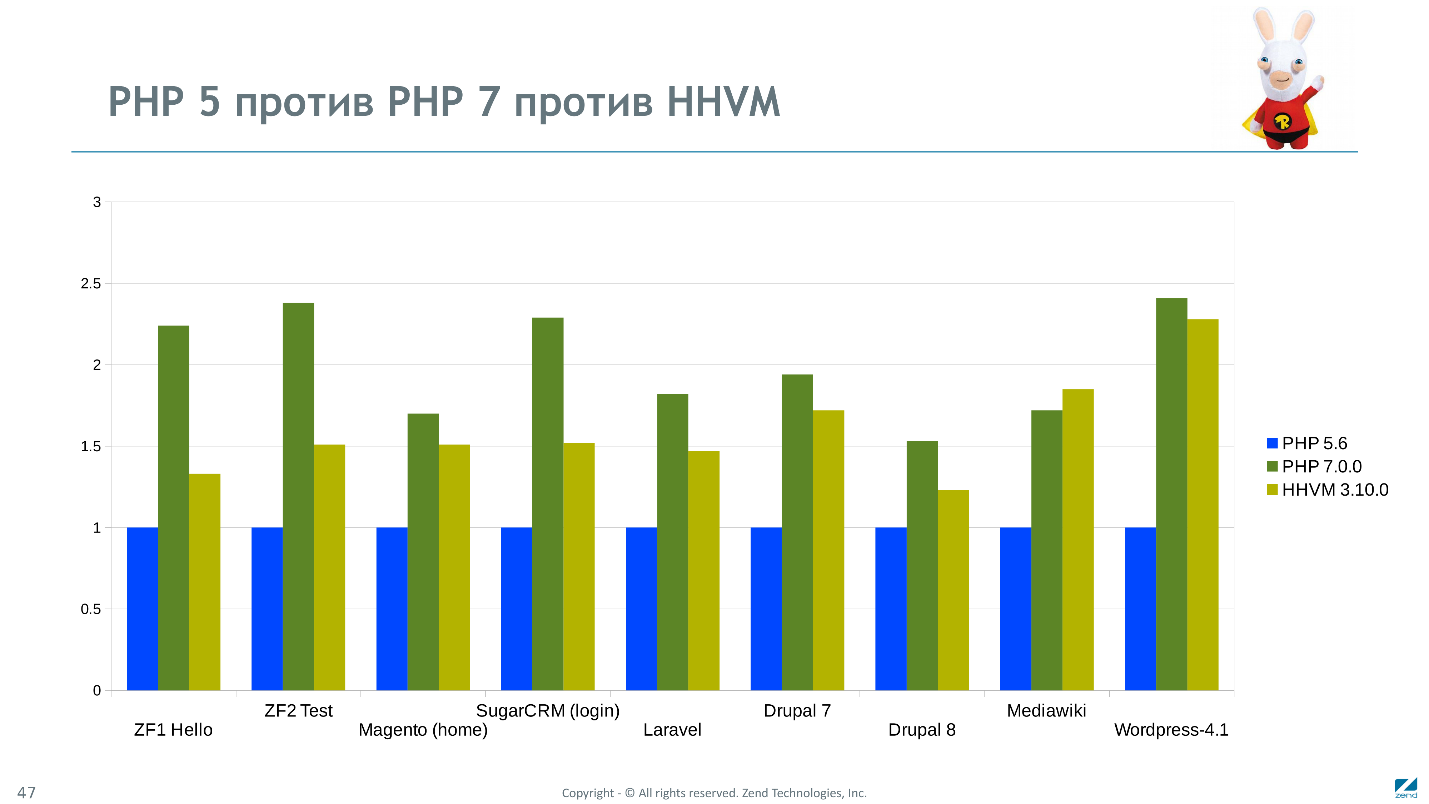
— . . Facebook . HHVM . , , , , .

PHP 7 — . Vebia, Etsy Badoo. Highload- , .
PHP 7.0 Etsy Badoo -. Badoo
.
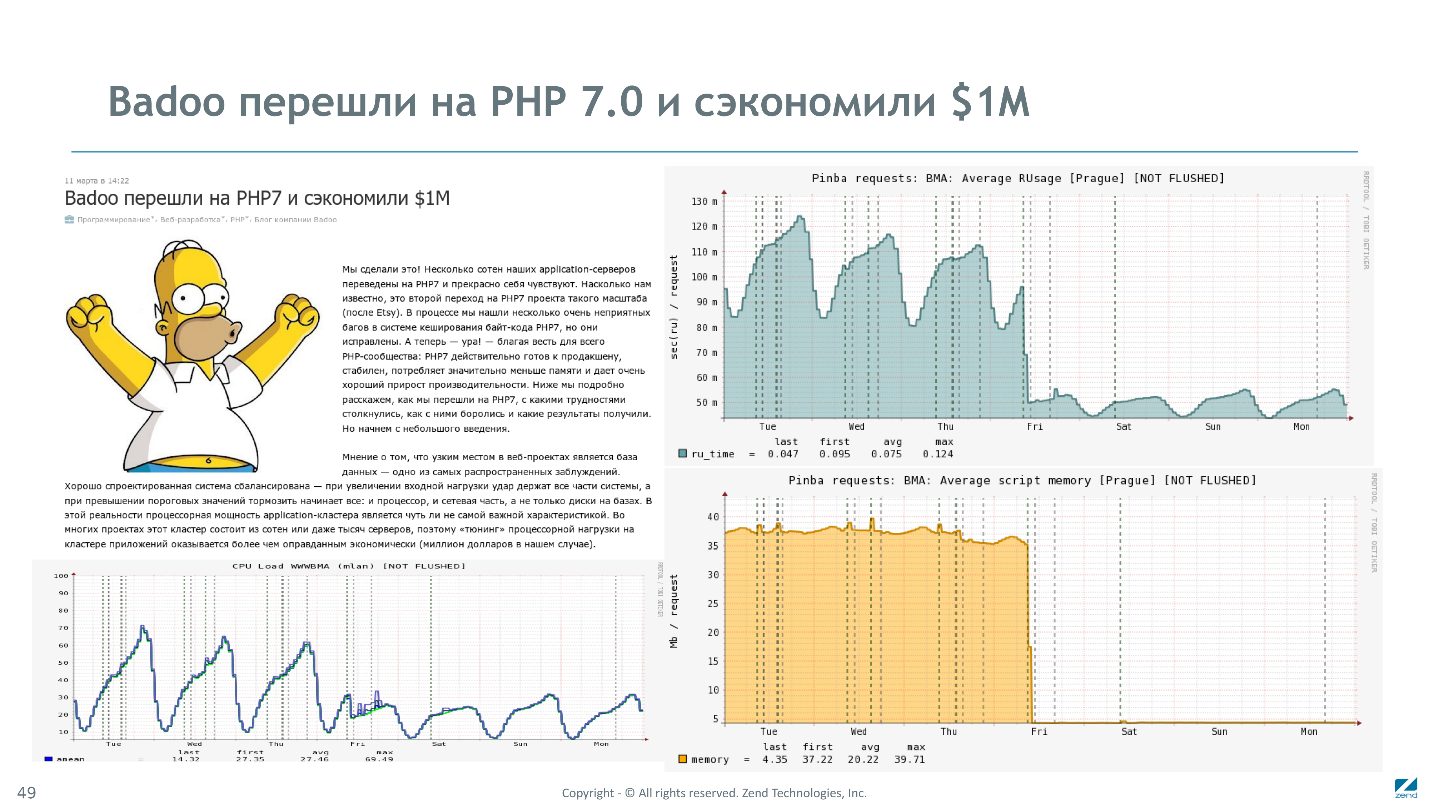
, 2 , — 7 .
PHP 7.0.
, PHP 7.1, .
PHP Russia PHP 8 . PHP, , , — 1 . , , — , , , .