Na última vez em que conversamos sobre a consistência dos dados, analisamos a diferença entre os diferentes níveis de isolamento de transações pelos olhos do usuário e descobrimos por que é importante saber. Agora estamos começando a aprender como o PostgreSQL implementa o isolamento baseado em imagem e o mecanismo de multi-versão.
Neste artigo, veremos como os dados estão fisicamente localizados em arquivos e páginas. Isso nos afasta do tópico do isolamento, mas essa digressão é necessária para entender mais material. Precisamos entender como o armazenamento de dados de baixo nível funciona.
Relações
Se você olhar dentro das tabelas e índices, eles serão organizados de maneira semelhante. Tanto isso quanto outro - objetos de base que contêm alguns dados que consistem em linhas.
O fato de a tabela consistir em linhas está fora de dúvida; para o índice, isso é menos óbvio. No entanto, imagine uma árvore B: consiste em nós que contêm valores indexados e links para outros nós ou para linhas da tabela. Esses nós podem ser considerados linhas de índice - de fato, do jeito que são.
De fato, ainda existem vários objetos organizados de maneira semelhante: sequências (essencialmente tabelas de linha única), visualizações materializadas (essencialmente tabelas que lembram a consulta). E há as visualizações usuais, que por si só não armazenam dados, mas em todos os outros sentidos são semelhantes às tabelas.
Todos esses objetos no PostgreSQL são chamados de
relação de palavras comuns. A palavra é extremamente infeliz, porque é um termo da teoria relacional. Você pode traçar um paralelo entre a relação e a tabela (exibição), mas certamente não entre a relação e o índice. Mas aconteceu: as raízes acadêmicas do PostgreSQL se fazem sentir. Eu acho que no começo isso foi chamado de tabelas e visualizações, e o resto cresceu com o tempo.
Além disso, por simplicidade, falaremos apenas sobre tabelas e índices, mas o restante dos
relacionamentos é estruturado exatamente da mesma maneira.
Camadas (garfos) e arquivos
Geralmente, cada relação tem várias
camadas (garfos). As camadas são de vários tipos e cada uma delas contém um certo tipo de dados.
Se houver uma camada, primeiro ela será representada por um único
arquivo . O nome do arquivo consiste em um identificador numérico ao qual a final correspondente ao nome da camada pode ser adicionada.
O arquivo aumenta gradualmente e quando seu tamanho atinge 1 GB, o próximo arquivo da mesma camada é criado (esses arquivos são chamados de
segmentos ). O número do segmento é anexado ao final do nome do arquivo.
A limitação de tamanho de arquivo de 1 GB surgiu historicamente para oferecer suporte a vários sistemas de arquivos, alguns dos quais não podem funcionar com arquivos grandes. A restrição pode ser alterada ao criar o PostgreSQL (
./configure --with-segsize ).
Assim, vários arquivos podem corresponder a uma relação em um disco. Por exemplo, para uma mesa pequena, haverá três delas.
Todos os arquivos de objetos pertencentes a um espaço de tabela e um banco de dados serão colocados em um diretório. Isso deve ser levado em consideração, porque os sistemas de arquivos geralmente não funcionam muito bem com um grande número de arquivos em um diretório.
Observe que os arquivos, por sua vez, são divididos em
páginas (ou
blocos ), geralmente 8 KB. Falaremos sobre a estrutura interna das páginas abaixo.
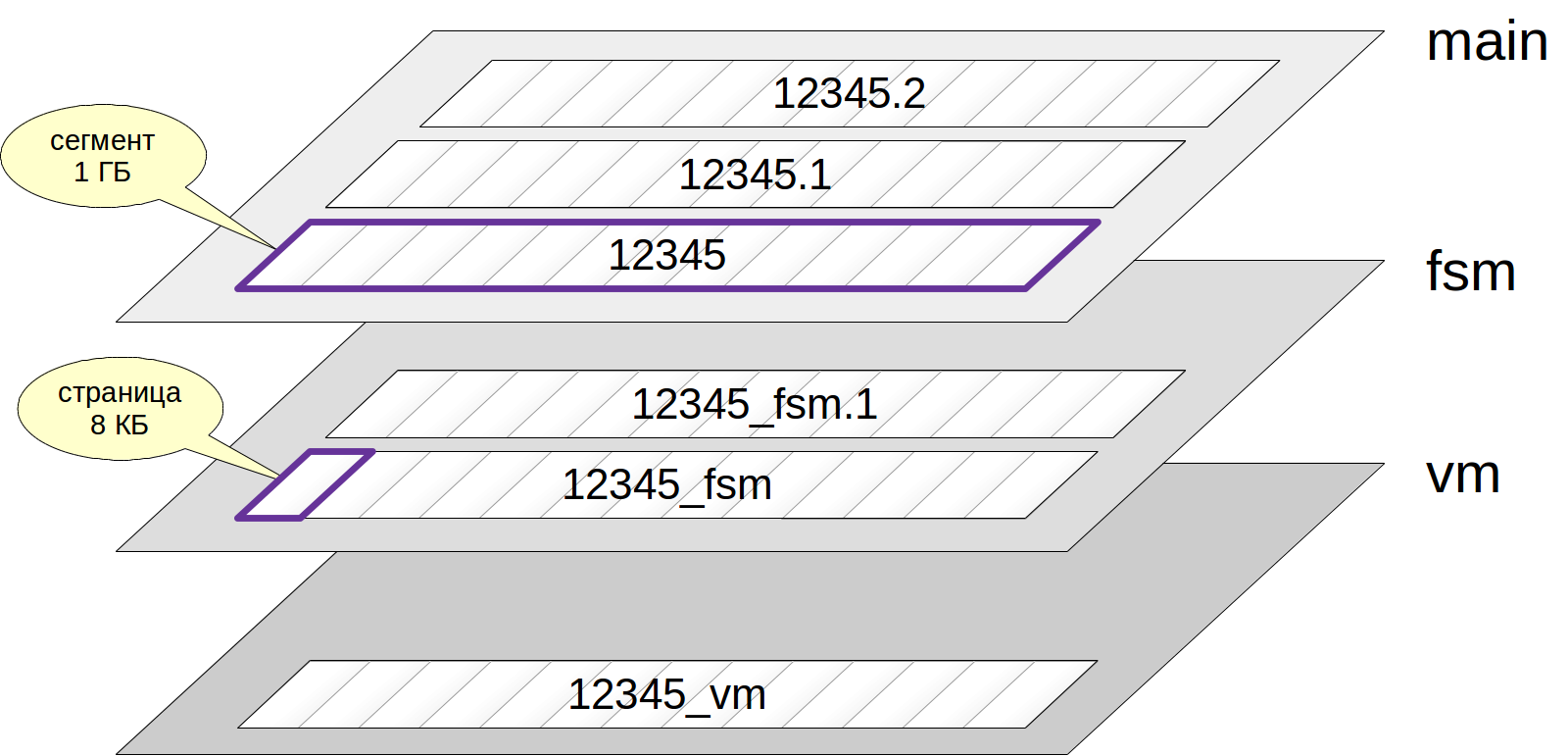
Agora vamos ver os tipos de camadas.
A camada principal são os próprios dados: a mesma tabela ou linhas de índice. A camada principal existe para qualquer relacionamento (exceto para representações que não contêm dados).
Os nomes dos arquivos na camada principal consistem em apenas um identificador numérico. Aqui está um caminho de exemplo para o arquivo de tabela que criamos na última vez:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
De onde vêm esses identificadores? O diretório base corresponde ao espaço de tabela pg_default, o próximo subdiretório corresponde ao banco de dados e o arquivo em que estamos interessados já está nele:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
O caminho é relativo, é contado a partir do diretório de dados (PGDATA). Além disso, quase todos os caminhos no PostgreSQL são contados no PGDATA. Graças a isso, você pode transferir o PGDATA com segurança para outro local - ele não contém nada (a menos que você precise configurar o caminho para as bibliotecas em LD_LIBRARY_PATH).
Analisamos mais a fundo o sistema de arquivos:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
Uma camada de inicialização existe apenas para tabelas não registradas no diário (criadas com UNLOGGED) e seus índices. Esses objetos não são diferentes dos objetos comuns, exceto que as ações com eles não são registradas no log de pré-registro. Devido a isso, o trabalho com eles é mais rápido, mas, no caso de uma falha, é impossível restaurar os dados em um estado consistente. Portanto, ao recuperar, o PostgreSQL simplesmente exclui todas as camadas desses objetos e grava a camada de inicialização no local da camada principal. O resultado é um "manequim". Falaremos sobre o registro em diário em detalhes, mas em um ciclo diferente.
A tabela de contas é registrada no diário, portanto, não há camada de inicialização para ela. Mas para a experiência, você pode desativar o log:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
A capacidade de ativar e desativar o registro no diário em tempo real, como pode ser visto no exemplo, envolve a substituição de dados em arquivos com nomes diferentes.
A camada de inicialização tem o mesmo nome que a camada principal, mas com o sufixo "_init":
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
Mapa de espaço livre (mapa de espaço livre) - uma camada na qual há um espaço vazio dentro das páginas. Este lugar está mudando constantemente: quando novas versões de strings são adicionadas, ela diminui, enquanto a limpeza - ela aumenta. O mapa de espaço livre é usado ao inserir novas versões de linhas para encontrar rapidamente uma página adequada na qual os dados a serem adicionados serão ajustados.
O mapa de espaço livre possui o sufixo "_fsm". Mas o arquivo não aparece imediatamente, mas somente se necessário. A maneira mais fácil de conseguir isso é limpar a mesa (por que - vamos conversar no devido tempo):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
Um mapa de visibilidade é uma camada na qual as páginas que contêm apenas versões atuais de cadeias são marcadas com um bit. Grosso modo, isso significa que quando uma transação tenta ler uma linha dessa página, a linha pode ser exibida sem verificar sua visibilidade. Examinaremos em detalhes como isso acontece nos seguintes artigos.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Páginas
Como já dissemos, os arquivos são logicamente divididos em páginas.
Normalmente, uma página tem 8 KB de tamanho. Você pode alterar o tamanho dentro de certos limites (16 KB ou 32 KB), mas apenas durante a montagem (
./configure --with-blocksize ). A instância montada e em execução pode funcionar com páginas de apenas um tamanho.
Independentemente de qual camada os arquivos pertencem, eles são usados pelo servidor aproximadamente da mesma maneira. As páginas são lidas primeiro no cache do buffer, onde os processos podem lê-las e modificá-las; depois, se necessário, as páginas são enviadas de volta ao disco.
Cada página possui marcação interna e geralmente contém as seguintes seções:
0 + ----------------------------------- +
| posição
24 + ----------------------------------- +
| matriz de ponteiros para seqüências de versão |
menor + ----------------------------------- +
| espaço livre |
superior + ----------------------------------- +
| versões de linha |
especial + ----------------------------------- +
| área especial |
tamanho da página + ----------------------------------- +
É fácil descobrir o tamanho dessas seções com a página "pesquisa"; inspecione a extensão:
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Aqui, examinamos o
título da primeira página (zero) da tabela. Além do tamanho das áreas restantes, o cabeçalho contém outras informações sobre a página, mas ainda não nos interessa.
Na parte inferior da página, há uma
área especial , no nosso caso, vazia. É usado apenas para índices e depois não para todos. O "fundo" aqui corresponde à imagem; talvez seja mais correto dizer "em endereços altos".
Após a área especial estão
as versões de linha - os mesmos dados que armazenamos na tabela, além de algumas informações gerais.
No topo da página, imediatamente após o cabeçalho, está o índice: uma
matriz de ponteiros para a versão das linhas disponíveis na página.
Entre versões de linhas e ponteiros, pode haver
espaço livre (marcado no mapa de espaço livre). Observe que não há fragmentação dentro da página, todo o espaço livre é sempre representado por um fragmento.
Ponteiros
Por que os ponteiros para versões de cadeia são necessários? O fato é que as linhas de índice devem, de alguma forma, se referir à versão das linhas na tabela. É claro que o link deve conter o número do arquivo, o número da página no arquivo e alguma indicação da versão da linha. Um deslocamento do início da página pode ser usado como uma indicação, mas isso é inconveniente. Não poderíamos mover a versão da linha para dentro da página, pois isso quebraria os links existentes. E isso levaria à fragmentação do espaço dentro das páginas e outras conseqüências desagradáveis. Portanto, o índice se refere ao número do índice e o ponteiro se refere à posição atual da versão da linha na página. Acontece endereçamento indireto.
Cada ponteiro ocupa exatamente 4 bytes e contém:
- link para a versão da string;
- o comprimento desta versão da string;
- vários bits que determinam o status da versão de uma string.
Formato de dados
O formato dos dados no disco coincide completamente com a representação dos dados na RAM. A página é lida no cache do buffer "como está", sem nenhuma transformação. Portanto, os arquivos de dados de uma plataforma são incompatíveis com outras plataformas.
Por exemplo, na arquitetura x86, a ordem dos bytes é adotada da menos significativa para a mais alta (little-endian), o z / Architecture usa a ordem inversa (big-endian) e, no ARM, a ordem dos comutadores.
Muitas arquiteturas fornecem alinhamento de dados através dos limites das palavras de máquina. Por exemplo, em um sistema x86 de 32 bits, números inteiros (tipo inteiro, ocupa 4 bytes) serão alinhados no limite de palavras de 4 bytes, além de números de ponto flutuante de precisão dupla (tipo de precisão dupla, 8 bytes). E em um sistema de 64 bits, os valores duplos serão alinhados na borda das palavras de 8 bytes. Esse é outro motivo de incompatibilidade.
Devido ao alinhamento, o tamanho da linha da tabela depende da ordem dos campos. Normalmente, esse efeito não é muito perceptível, mas, em alguns casos, pode levar a um aumento significativo no tamanho. Por exemplo, se você colocar os campos char (1) e número inteiro misturados, 3 bytes geralmente serão desperdiçados entre eles. Você pode ver mais sobre isso na apresentação de Nikolai Shaplov "
What's Inside It ".
Versões String e TOAST
Sobre como as versões das strings são organizadas por dentro, falaremos em detalhes da próxima vez. Até agora, a única coisa importante para nós é que cada versão deve caber inteiramente em uma página: o PostgreSQL não fornece uma maneira de "continuar" a linha na próxima página. Em vez disso, é usada uma tecnologia chamada TOAST (The Oversized Attributes Storage Technique). O próprio nome sugere que o barbante possa ser cortado em brindes.
Falando sério, o TOAST envolve várias estratégias. Os valores dos atributos "longos" podem ser enviados para uma tabela de serviço separada, previamente cortada em pequenos pedaços de torradas. Outra opção é compactar o valor para que a versão da linha ainda caiba em uma página de tabela comum. E é possível tanto isso como outro: primeiro comprimir e só depois cortar e enviar.
Para cada tabela principal, se necessário, é criada uma tabela separada, mas uma para todos os atributos, a tabela TOAST (e um índice especial). A necessidade é determinada pela presença de atributos potencialmente longos na tabela. Por exemplo, se uma tabela tiver uma coluna do tipo numérico ou texto, uma tabela TOAST será criada imediatamente, mesmo que valores longos não sejam usados.
Como a tabela TOAST é essencialmente uma tabela regular, ela ainda possui o mesmo conjunto de camadas. E isso dobra o número de arquivos que "servem" a tabela.
Inicialmente, as estratégias são determinadas pelos tipos de dados da coluna. Você pode visualizá-los com o comando
\d+ no psql, mas como também exibe muitas outras informações, usaremos a solicitação no diretório do sistema:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
Os nomes das estratégias têm os seguintes significados:
- plain - TOAST não é usado (usado para tipos de dados obviamente "curtos", como número inteiro);
- estendido - a compactação e o armazenamento em uma tabela TOAST separada são permitidos;
- valores externos externos são armazenados na tabela TOAST descompactada;
- Os valores main - long são compactados primeiro e somente na tabela TOAST se a compactação não ajudar.
Em termos gerais, o algoritmo é o seguinte. O PostgreSQL deseja que pelo menos 4 linhas caibam na página. Portanto, se o tamanho da linha exceder a quarta parte da página, levando em consideração o cabeçalho (com uma página normal de 8K, 2040 bytes), o TOAST deve ser aplicado a parte dos valores. Agimos na ordem descrita abaixo e paramos assim que a linha parar de exceder o limite:
- Primeiro, classificamos atributos com estratégias externas e estendidas, passando do mais longo para o mais curto. Os atributos estendidos são compactados (se isso tiver um efeito) e, se o valor em si exceder um quarto da página, ele será imediatamente enviado para a tabela TOAST. Atributos externos são tratados da mesma maneira, mas não são compactados.
- Se após a primeira passagem a versão da linha ainda não se ajustar, enviaremos os atributos restantes com as estratégias externas e estendidas para a tabela TOAST.
- Se isso também não ajudar, tente compactar os atributos com a estratégia principal, deixando-os na página da tabela.
- E somente se depois disso a linha ainda não for curta o suficiente, os principais atributos serão enviados para a tabela TOAST.
Às vezes, pode ser útil alterar a estratégia para algumas colunas. Por exemplo, se for sabido antecipadamente que os dados na coluna não estão compactados, você pode definir uma estratégia externa para isso - isso economizará em tentativas de compactação inúteis. Isso é feito da seguinte maneira:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
Repetindo a solicitação, obtemos:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
As tabelas e índices TOAST estão localizados em um esquema pg_toast separado e, portanto, geralmente não são visíveis. Para tabelas temporárias, o esquema pg_toast_temp_
N é usado, semelhante ao usual pg_temp_
N.É claro que, se desejado, ninguém se incomoda em espiar a mecânica interna do processo. Digamos que haja três atributos potencialmente longos na tabela de contas, portanto, uma tabela TOAST deve ser. Aqui está:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
É lógico que, para os “brindes” nos quais a linha é cortada, a estratégia simples seja aplicada: o TOAST do segundo nível não existe.
O índice do PostgreSQL é oculto com mais cuidado, mas também é fácil encontrar:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
A coluna do cliente usa a estratégia estendida: os valores nela serão compactados. Verifique:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
Não há nada na tabela TOAST: caracteres repetidos são perfeitamente compactados e, depois disso, o valor se encaixa em uma página de tabela comum.
Agora deixe o nome do cliente consistir em caracteres aleatórios:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Esta sequência não pode ser compactada e se enquadra na tabela TOAST:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
Como você pode ver, os dados são cortados em fragmentos de 2000 bytes.
Ao acessar um valor "longo", o PostgreSQL automaticamente, transparente para a aplicação, restaura o valor original e o retorna ao cliente.
Obviamente, muitos recursos são gastos em compactação fatiada e recuperação subseqüente. Portanto, armazenar dados volumosos no PostgreSQL não é uma boa ideia, especialmente se for usado ativamente e a lógica transacional não for necessária para eles (como um exemplo: originais digitalizados de documentos contábeis). Uma alternativa mais lucrativa pode ser armazenar esses dados no sistema de arquivos e no DBMS, os nomes dos arquivos correspondentes.
Uma tabela TOAST é usada apenas quando se refere a um valor "longo". Além disso, a tabela de brinde possui seu próprio controle de versão: se a atualização de dados não afetar o valor "longo", a nova versão da linha fará referência ao mesmo valor na tabela de brinde - isso economizará espaço.
Observe que o TOAST funciona apenas para tabelas, mas não para índices. Isso impõe um limite no tamanho das chaves indexadas.
Você pode ler mais sobre a organização interna de dados na documentação .
Para ser continuado .