O pacote tidyr faz parte do núcleo de uma das bibliotecas mais populares da linguagem R - tidyverse .
O principal objetivo do pacote é trazer os dados para uma aparência elegante.
No Habré já existe uma publicação dedicada a este pacote, mas remonta a 2015. E quero falar sobre as mudanças mais relevantes anunciadas há alguns dias pelo autor Hadley Wickham.
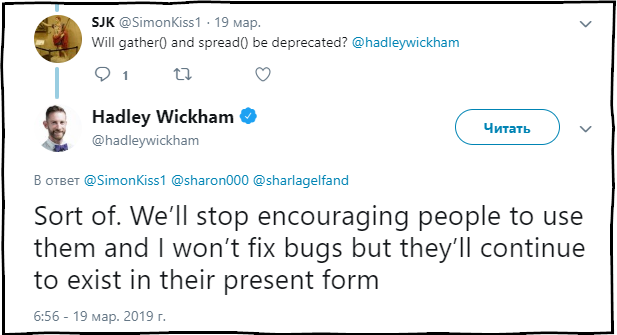
SJK : As funções gather () e spread () serão descontinuadas?
Hadley Wickham : Até certo ponto. Pararemos de recomendar o uso dessas funções e corrigiremos erros, mas elas continuarão presentes no pacote no estado atual.
Conteúdo
TidyData Concept
O objetivo do tidyr é ajudá-lo a trazer os dados para uma aparência elegante. Dados precisos são dados em que:
- Cada variável está em uma coluna.
- Cada observação é uma linha.
- Cada valor é uma célula.
Os dados fornecidos aos dados organizados são muito mais simples e convenientes para trabalhar durante a análise.
As principais funções incluídas no pacote tidyr
O tidyr contém um conjunto de funções para transformar tabelas:
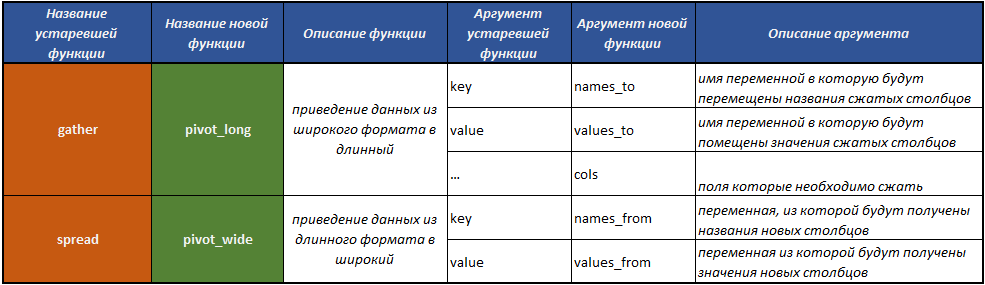
fill() - preenchendo os valores ausentes na coluna com os valores anteriores;separate() - divide um campo em vários através de um separador;unite() - executa a operação de combinar vários campos em um, o inverso da função separate() ;pivot_longer() - uma função que converte dados de um formato amplo para um longo;pivot_wider() - uma função que converte dados de um formato longo para um formato amplo. A operação é oposta à realizada pela função pivot_longer() .gather() obsoleto - uma função que converte dados de um formato amplo para um longo;spread() obsoleto - uma função que converte dados de um formato longo para um formato amplo. A operação é o oposto do que a função gather() executa.
Anteriormente, as funções gather() e spread() usadas para esse tipo de transformação. Ao longo dos anos de existência dessas funções, tornou-se óbvio que, para a maioria dos usuários, incluindo o autor do pacote, os nomes dessas funções e seus argumentos não eram muito óbvios, e causaram dificuldades em encontrá-las e entender qual dessas funções traz o período de um longo para o longo formato e vice-versa.
Nesse contexto, duas novas funções importantes foram adicionadas ao tidyr , projetadas para transformar os quadros de datas.
As novas funções pivot_longer() e pivot_wider() foram inspiradas por algumas das funções no pacote cdata criadas por John Mount e Nina Zumel.
Instalando a versão mais atual do tidyr 0.8.3.9000
Para instalar a nova versão mais recente do pacote tidyr 0.8.3.9000 , na qual novas funções estão disponíveis, use o código a seguir.
devtools::install_github("tidyverse/tidyr")
No momento da escrita, essas funções estão disponíveis apenas na versão dev do pacote no GitHub.
Mudar para novos recursos
Na verdade, não é difícil transferir scripts antigos para trabalhar com novas funções. Para um melhor entendimento, darei um exemplo da documentação de funções antigas e mostrarei como essas mesmas operações são executadas usando as novas funções pivot_*() .
Converta formatos largos em longos.
Código de amostra da documentação da função de coleta # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
Convertendo um formato longo para amplo.
Código de exemplo da documentação da função spread # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
Porque nos exemplos acima, de trabalhar com pivot_longer() e pivot_wider() , nos estoques da tabela de origem não há colunas listadas nos argumentos names_to e values_to, seus nomes devem ser indicados entre aspas.
A tabela com a ajuda da qual você descobrirá com mais facilidade como mudar para trabalhar com o novo conceito tidyr .
Nota do autor
Todo o texto abaixo é adaptável, eu diria mesmo uma tradução gratuita da vinheta do site oficial da biblioteca organizada.
pivot_longer () - torna os conjuntos de dados mais longos, diminuindo o número de colunas e aumentando o número de linhas.

Para executar os exemplos apresentados no artigo, você deve primeiro conectar os pacotes necessários:
library(tidyr) library(dplyr) library(readr)
Suponha que tenhamos uma tabela com os resultados de uma pesquisa na qual (entre outras coisas) as pessoas foram questionadas sobre sua religião e renda anual:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
Esta tabela contém dados de religião dos entrevistados em linhas e os níveis de renda estão espalhados pelos nomes das colunas. O número de entrevistados de cada categoria é armazenado nos valores das células na interseção entre religião e nível de renda. Para trazer a tabela para um formato limpo e correto, basta usar pivot_longer() :
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
Argumentos para pivot_longer()
- O primeiro argumento, colunas, descreve quais colunas mesclar. Nesse caso, todas as colunas, exceto o tempo .
- O argumento names_to fornece o nome da variável que será criada a partir dos nomes das colunas que combinamos.
- values_to fornece o nome da variável que será criada a partir dos dados armazenados nos valores das células das colunas unidas.
Especificações
Essa é a nova funcionalidade do pacote tidyr , que anteriormente não estava disponível ao trabalhar com funções obsoletas.
Uma especificação é um quadro de dados, cada linha corresponde a uma coluna em um novo quadro de data de saída e duas colunas especiais que começam com:
- .name contém o nome original da coluna.
- .value contém o nome da coluna na qual os valores da célula serão inseridos.
As colunas restantes da especificação refletem como o nome das colunas compactáveis de .name será exibido na nova coluna.
A especificação descreve os metadados armazenados no nome da coluna, com uma linha para cada coluna e uma coluna para cada variável combinada com o nome da coluna; provavelmente agora essa definição parece confusa, mas depois de considerar alguns exemplos, tudo ficará muito mais claro.
O significado da especificação é que você pode recuperar, modificar e configurar novos metadados para o quadro de dados convertido.
A função pivot_longer_spec() é pivot_longer_spec() para trabalhar com especificações ao converter uma tabela de um formato amplo para um longo.
Como essa função funciona, ele pega qualquer período de data e gera seus metadados conforme descrito acima.
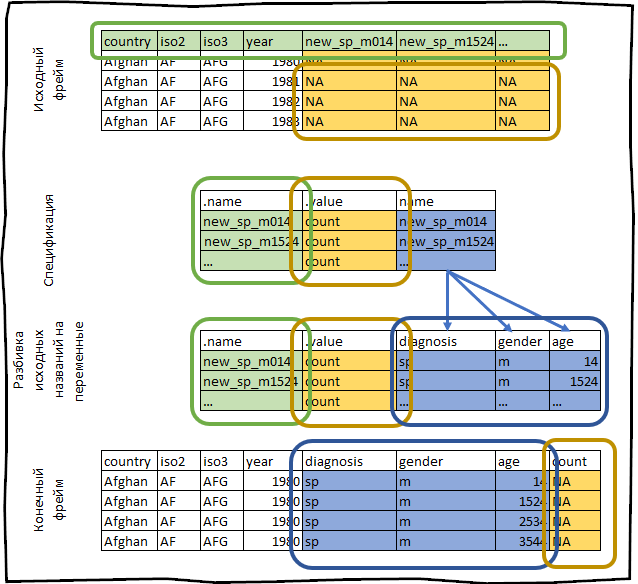
Por exemplo, vamos pegar o conjunto de dados who que acompanha o pacote tidyr . Este conjunto de dados contém informações fornecidas pela organização internacional de saúde sobre a incidência de tuberculose.
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
Nós construímos sua especificação.
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
Os campos country , iso2 , iso3 já são variáveis. Nossa tarefa é inverter as colunas de new_sp_m014 para newrel_f65 .
Os nomes dessas colunas armazenam as seguintes informações:
- O prefixo
new_ indica que a coluna contém dados sobre novos casos de tuberculose; o período atual contém informações apenas sobre novas doenças; portanto, esse prefixo no contexto atual não tem significado. sp / rel / sp / ep descreve um método para diagnosticar uma doença.m / f sexo do paciente.014 etária 014 do paciente.
Podemos separar essas colunas usando a função extract() usando uma expressão regular.
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
Observe que a coluna .name deve permanecer inalterada, pois esse é o nosso índice nos nomes de coluna do conjunto de dados de origem.
Sexo e idade (colunas de sexo e idade ) têm valores fixos e conhecidos; portanto, é recomendável converter essas colunas em fatores:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
Finalmente, para aplicar a especificação que criamos à data original do quadro who , precisamos usar o argumento spec na função pivot_longer() .
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
Tudo o que acabamos de fazer pode ser esquematicamente representado da seguinte maneira:
Especificação usando vários valores (.value)
No exemplo acima, a coluna de especificação .value continha apenas um valor; na maioria dos casos, isso acontece.
Mas, ocasionalmente, pode surgir uma situação quando você precisa coletar dados de colunas com diferentes tipos de dados nos valores. Usando a função spread() obsoleta, isso seria bastante difícil.
O exemplo a seguir é emprestado da vinheta para o pacote data.table .
Vamos criar um quadro de dados de treinamento.
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
O período criado em cada linha contém dados sobre os filhos de uma família. As famílias podem ter um ou dois filhos. Para cada criança, são fornecidos dados sobre a data de nascimento e sexo e os dados de cada criança estão em colunas separadas, nossa tarefa é trazer esses dados para o formato correto para análise.
Observe que temos duas variáveis com informações sobre cada criança: seu sexo e data de nascimento (as colunas com o prefixo dop contêm a data de nascimento, as colunas com o prefixo gênero contêm o sexo da criança). No resultado esperado, eles devem ir em colunas separadas. Podemos fazer isso gerando uma especificação na qual a coluna .value terá dois valores diferentes.
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
Então, vamos percorrer as etapas executadas pelo código acima.
pivot_longer_spec(-family) - crie uma especificação que comprima todas as colunas disponíveis, exceto a coluna da família.separate(col = name, into = c(".value", "child")) - separe a coluna .name , que contém os nomes dos campos de origem, sublinhados e coloque os valores nas colunas .value e filho .mutate(child = parse_number(child)) - converte os valores do campo filho de texto em tipo de dados numérico.
Agora podemos aplicar a especificação recebida ao quadro de dados inicial e trazer a tabela para o formulário desejado.
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
Usamos o argumento na.rm = TRUE , porque o formulário de dados atual nos obriga a criar linhas extras para observações inexistentes. Porque a família 2 tem apenas um filho, na.rm = TRUE garante que a família 2 tenha uma linha na saída.
pivot_wider() - é a transformação inversa e vice-versa aumenta o número de colunas na data do quadro, reduzindo o número de linhas.
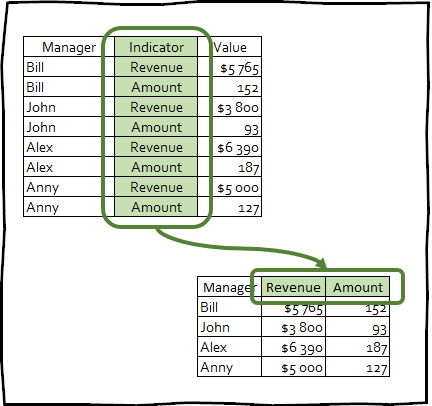
Esse tipo de transformação raramente é usado para trazer os dados para uma aparência elegante, no entanto, essa técnica pode ser útil para criar tabelas dinâmicas usadas em apresentações ou para integração com outras ferramentas.
De fato, as funções pivot_longer() e pivot_wider() são simétricas e executam ações opostas, ou seja: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) e df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) retornará o df original.
Para demonstrar a operação da função pivot_wider() , usaremos o conjunto de dados fish_encounters , que armazena informações sobre como várias estações registram o movimento dos peixes ao longo do rio.
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
Na maioria dos casos, esta tabela será mais informativa e conveniente de usar se você fornecer informações para cada estação em uma coluna separada.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
Este conjunto de dados registra informações apenas quando o peixe foi detectado pela estação, ou seja, se algum peixe não tiver sido consertado por alguma estação, esses dados não estarão na tabela. Isso significa que a saída será preenchida por NA.
No entanto, neste caso, sabemos que a ausência de um registro significa que o peixe não foi percebido; portanto, podemos usar o argumento values_fill na função pivot_wider() e preencher esses valores ausentes com zeros:
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
Gerando um nome de coluna a partir de várias variáveis de origem
Imagine que temos uma tabela contendo uma combinação de produto, país e ano. Para gerar uma data do quadro de teste, você pode executar o seguinte código:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
Nossa tarefa é expandir o período para que uma coluna contenha dados para cada combinação de produto e país. Para fazer isso, basta passar o vetor que contém os nomes dos campos a serem unidos no argumento names_from .
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
Você também pode aplicar especificações à função pivot_wider() . Porém, quando fornecida a pivot_wider() especificação faz o oposto de pivot_longer() : as colunas especificadas em .name são criadas usando valores de .value e outras colunas.
Para esse conjunto de dados, você pode gerar uma especificação do usuário se desejar que cada combinação possível de país e produto tenha sua própria coluna, e não apenas as que estão presentes nos dados:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
Alguns exemplos avançados de como trabalhar com o novo conceito tidyr
Trazendo dados para uma aparência elegante usando o conjunto de dados de censo de receita e aluguel dos EUA como exemplo
O conjunto de dados us_rent_income contém informações sobre a renda e o aluguel médios de cada estado nos EUA para 2017 (o conjunto de dados está disponível no pacote tidycensus ).
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
Na forma em que os dados são armazenados no conjunto de dados us_rent_income , trabalhar com eles é extremamente inconveniente, portanto, gostaríamos de criar um conjunto de dados com colunas: rent , rent_moe , come , Income_moe . Existem várias maneiras de criar essa especificação, mas o principal é que precisamos gerar cada combinação dos valores das variáveis e estimar / moe e gerar o nome da coluna.
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
Fornecer esta especificação para pivot_wider() nos dá o resultado que estamos procurando:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
Banco Mundial
Às vezes, trazer o conjunto de dados para o formato correto requer várias etapas.
O conjunto de dados world_bank_pop contém dados do Banco Mundial sobre a população de cada país entre 2000 e 2018.
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
Nosso objetivo é criar um conjunto de dados limpo em que cada variável esteja em uma coluna separada. Ainda não está claro quais etapas são necessárias, mas começaremos com o problema mais óbvio: o ano está distribuído por várias colunas.
Para corrigir isso, você deve usar a função pivot_longer() .
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
Conclusão
, tidyr , spread() gather() . pivot_longer() pivot_wider() .