
O código do software de aprendizado de máquina geralmente é complexo e bastante confuso. Detectar e eliminar bugs é uma tarefa que consome muitos recursos. Até as
redes neurais mais simples
de conexão direta requerem uma abordagem séria da arquitetura de rede, inicialização de pesos e otimização de rede. Um pequeno erro pode levar a problemas desagradáveis.
Este artigo é sobre o algoritmo de depuração de suas redes neurais.
A Skillbox recomenda: Um desenvolvedor prático de Python do zero .
Lembramos que: para todos os leitores de "Habr" - um desconto de 10.000 rublos ao se inscrever em qualquer curso Skillbox usando o código promocional "Habr".
O algoritmo consiste em cinco estágios:
- começo simples;
- confirmação de perdas;
- verificação de resultados e compostos intermediários;
- diagnóstico de parâmetros;
- controle de trabalho.
Se algo lhe parecer mais interessante que o resto, você pode ir diretamente para essas seções.
Começo fácil
Uma rede neural com arquitetura complexa, regularização e um planejador de velocidade de aprendizado é mais difícil de iniciar do que uma rede regular. Aqui somos um pouco complicados, pois o item em si tem uma relação indireta com a depuração, mas essa ainda é uma recomendação importante.
Um começo simples é criar um modelo simplificado e treiná-lo em um conjunto de dados (ponto).
Primeiro, criamos um modelo simplificadoPara um início rápido, crie uma pequena rede com uma única camada oculta e verifique se tudo está funcionando corretamente. Em seguida, complicamos gradualmente o modelo, verificando todos os novos aspectos de sua estrutura (camada adicional, parâmetro etc.) e seguimos em frente.
Nós treinamos o modelo em um único conjunto de dados (ponto)Como um teste rápido da integridade do seu projeto, você pode usar um ou dois pontos de dados para treinamento para confirmar se o sistema está funcionando corretamente. A rede neural deve mostrar 100% de precisão do treinamento e da verificação. Se não for esse o caso, o modelo é muito pequeno ou você já possui um erro.
Mesmo que esteja tudo bem, prepare o modelo para a passagem de uma ou mais eras antes de prosseguir.
Estimativa de perda
A estimativa de perda é a principal maneira de refinar o desempenho do modelo. Você precisa garantir que a perda corresponda à tarefa e as funções de perda sejam avaliadas na escala correta. Se você usar mais de um tipo de perda, verifique se eles estão na mesma ordem e estão dimensionados corretamente.
É importante estar atento às perdas iniciais. Verifique se o resultado real está próximo do esperado se o modelo for iniciado com uma suposição aleatória. O
trabalho de Andrei Karpati sugere o seguinte : “Certifique-se de obter o resultado esperado ao começar a trabalhar com um pequeno número de parâmetros. É melhor verificar imediatamente a perda de dados (com o grau de regularização definido como zero). Por exemplo, para o CIFAR-10 com o classificador Softmax, esperamos que a perda inicial seja 2,302, porque a probabilidade difusa esperada é de 0,1 para cada classe (já que existem 10 classes) e a perda do Softmax é a probabilidade logarítmica negativa da classe correta como - ln (0,1) = 2,302 ".
Para um exemplo binário, um cálculo semelhante é simplesmente feito para cada uma das classes. Aqui, por exemplo, estão os dados: 20% 0 e 80% 1's. A perda inicial esperada será de –0,2 ln (0,5) –0,8 ln (0,5) = 0,693147. Se o resultado for maior que 1, isso pode indicar que os pesos da rede neural não estão adequadamente balanceados ou que os dados não estão normalizados.
Verificando resultados e conexões intermediários
Para depurar uma rede neural, é necessário entender a dinâmica dos processos dentro da rede e o papel das camadas intermediárias individuais, uma vez que elas estão conectadas. Aqui estão alguns erros comuns que você pode encontrar:
- Expressões incorretas para atualizações de gradiente
- atualizações de peso não se aplicam;
- gradientes que desaparecem ou explodem.
Se os valores do gradiente forem zero, isso significa que a velocidade de aprendizado no otimizador é muito lenta ou que você encontrou uma expressão incorreta para atualizar o gradiente.
Além disso, é necessário monitorar os valores das funções de ativação, pesos e atualizações de cada uma das camadas. Por exemplo, o valor das atualizações de parâmetros (pesos e compensações)
deve ser 1-e3 .
Existe um fenômeno chamado “Reying DLU” ou
“Disappearing Gradient Problem” quando os neurônios ReLU produzirão zero depois de estudar o grande valor de viés negativo para seus pesos. Esses neurônios nunca são ativados novamente em nenhum local de dados.
Você pode usar o teste de gradiente para detectar esses erros, aproximando o gradiente usando uma abordagem numérica. Se estiver próximo dos gradientes calculados, a propagação de retorno foi implementada corretamente. Para criar uma verificação de gradiente, consulte esses ótimos recursos do CS231
aqui e
aqui , bem como o tutorial de Andrew Nga sobre este tópico.
Fayzan Sheikh aponta três métodos principais para visualizar uma rede neural:
- Preliminar - métodos simples que nos mostram a estrutura geral do modelo treinado. Eles incluem a saída de formas ou filtros de camadas individuais da rede neural e parâmetros em cada camada.
- Com base na ativação. Neles, deciframos a ativação de neurônios individuais ou grupos de neurônios para entender suas funções.
- Baseado em gradiente. Esses métodos tendem a manipular os gradientes que se formam a partir da passagem quando se treina o modelo (incluindo mapas de significância e mapas de ativação de classe).
Existem várias ferramentas úteis para visualizar as ativações e conexões de camadas individuais, por exemplo,
ConX e
Tensorboard .
Diagnóstico de parâmetros
As redes neurais têm muitos parâmetros que interagem entre si, o que complica a otimização. Na verdade, esta seção é objeto de pesquisas ativas de especialistas; portanto, as propostas abaixo devem ser consideradas apenas como conselhos, os pontos de partida nos quais você pode construir.
Tamanho do pacote (
tamanho do lote) - se você deseja que o tamanho do pacote seja grande o suficiente para obter estimativas precisas do gradiente de erro, mas pequeno o suficiente para que a descida do gradiente estocástico (SGD) possa otimizar sua rede. O tamanho pequeno dos pacotes levará a uma rápida convergência devido ao ruído no processo de aprendizado e, no futuro, a dificuldades de otimização. Isso é descrito em mais detalhes
aqui .
Velocidade de aprendizado - Muito lento resultará em convergência lenta ou no risco de ficar preso em pontos baixos locais. Ao mesmo tempo, uma alta velocidade de aprendizado causará uma discrepância na otimização, pois você corre o risco de "pular" no fundo, mas ao mesmo tempo restringe parte da função de perda. Tente usar o planejamento de velocidade para reduzi-lo durante o treinamento da rede neural. O CS231n
possui uma grande seção sobre esse problema .
Recorte de gradiente - aparar os gradientes de parâmetros durante a propagação de retorno no valor máximo ou norma limite. Útil para resolver problemas com gradientes explosivos que você possa encontrar no terceiro parágrafo.
Normalização em lote - usada para normalizar os dados de entrada de cada camada, o que permite resolver o problema do deslocamento covariante interno. Se você usar o Dropout e o Lote Norma juntos,
confira este artigo .
Descida estocástica de gradiente (SGD) - Existem várias variedades de SGD que usam impulso, velocidade de aprendizado adaptável e o método de Nesterov. Ao mesmo tempo, nenhum deles tem uma clara vantagem, tanto em termos de eficiência do treinamento quanto de generalização (
detalhes aqui ).
Regularização - é crucial para a construção de um modelo generalizado, porque acrescenta uma penalidade pela complexidade do modelo ou por valores extremos de parâmetros. Essa é uma maneira de reduzir a variação do modelo sem aumentar significativamente seu deslocamento. Mais
informações aqui .
Para avaliar tudo você mesmo, é necessário desativar a regularização e verificar o gradiente de perda de dados.
A desistência é outra maneira de otimizar sua rede para evitar congestionamentos. Durante o treinamento, a perda ocorre apenas mantendo a atividade de um neurônio com uma certa probabilidade p (hiperparâmetro) ou ajustando-a para zero no caso oposto. Como resultado, a rede deve usar um subconjunto de parâmetros diferente para cada parte do treinamento, o que reduz as alterações em determinados parâmetros que se tornam dominantes.
Importante: se você usar a normalização de abandono e lote, tenha cuidado com a ordem dessas operações ou mesmo com o uso conjunto. Tudo isso ainda é discutido e complementado ativamente. Aqui estão duas discussões importantes sobre esse tópico
no Stackoverflow e
Arxiv .
Controle de trabalho
Trata-se de documentar fluxos de trabalho e experimentos. Se você não documentar nada, poderá esquecer, por exemplo, que tipo de velocidade de treinamento ou peso de classe é usado. Graças ao controle, você pode visualizar e reproduzir facilmente as experiências anteriores. Isso reduz o número de experiências duplicadas.
É verdade que a documentação manual pode ser desafiadora no caso de uma grande quantidade de trabalho. Aqui, ferramentas como o Comet.ml ajudam a registrar automaticamente conjuntos de dados, alterações de código, histórico de experimentos e modelos de produção, incluindo informações importantes sobre o seu modelo (hiperparâmetros, indicadores de desempenho do modelo e informações ambientais).
Uma rede neural pode ser muito sensível a pequenas mudanças, e isso levará a uma diminuição no desempenho do modelo. O trabalho de rastreamento e documentação é o primeiro passo a ser adotado para padronizar seu ambiente e modelagem.
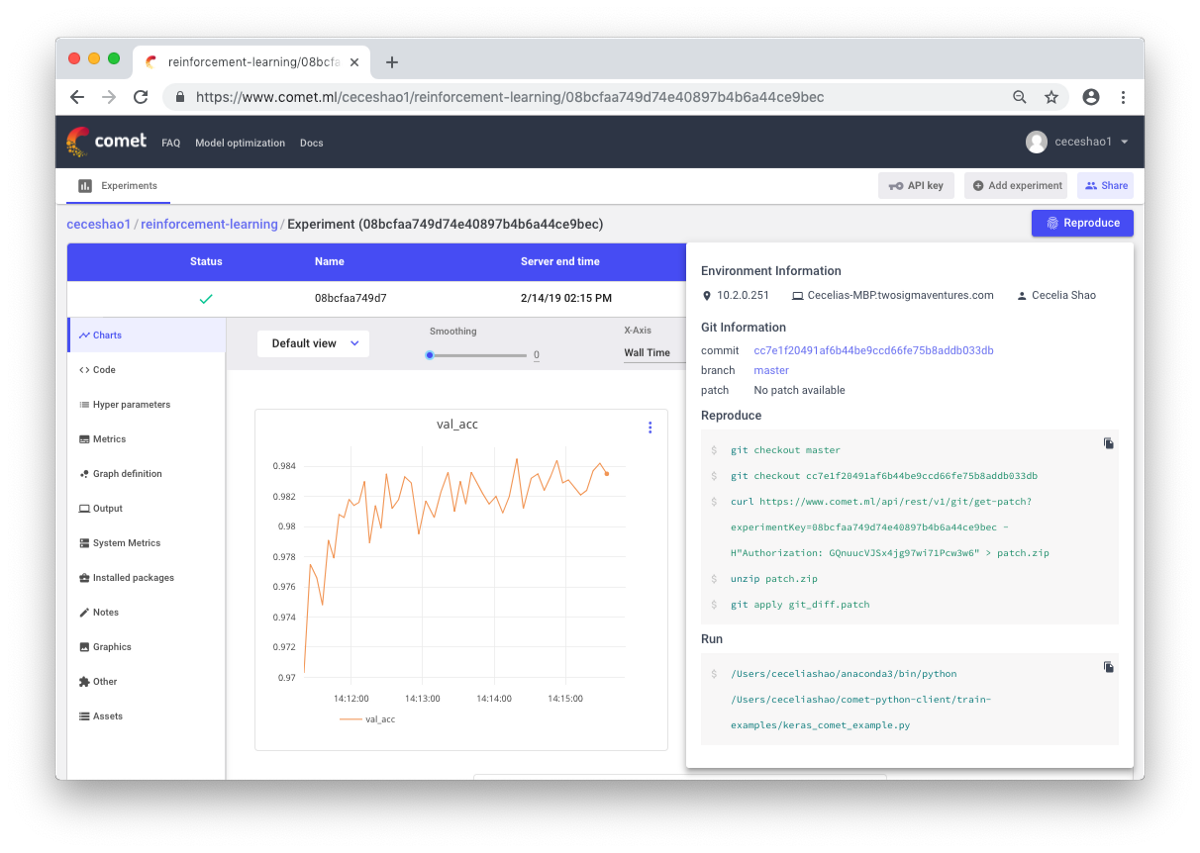
Espero que este post possa se tornar o ponto de partida a partir do qual você começará a depurar sua rede neural.
A Skillbox recomenda: