Às vezes, para resolver um problema, basta olhar para ele de um ângulo diferente. Mesmo que nos últimos 10 anos esses problemas tenham sido resolvidos da mesma maneira com efeitos diferentes, não é fato que esse método seja o único.
Existe um tópico como rotatividade de clientes. A coisa é inevitável, porque os clientes de qualquer empresa podem parar e usar seus produtos ou serviços por vários motivos. Obviamente, para a empresa, a saída é uma ação natural, mas não a mais desejável, então todos estão tentando minimizar essa saída. E melhor ainda - prever a probabilidade de saída de uma categoria específica de usuários ou de um usuário específico e oferecer algumas etapas de retenção.
Analise e tente manter o cliente, se possível, pelo menos pelos seguintes motivos:
- atrair novos clientes é mais caro que os procedimentos de retenção . Para atrair novos clientes, em regra, você precisa gastar algum dinheiro (publicidade), enquanto os clientes existentes podem ser ativados com uma oferta especial com condições especiais;
- Entender por que os clientes estão saindo é a chave para melhorar produtos e serviços .
Existem abordagens padrão para prever vazões. Mas em um dos campeonatos de IA, decidimos usar a distribuição Weibull para isso. Na maioria das vezes, é usado para análise de sobrevivência, previsão do tempo, análise de desastres naturais, engenharia industrial e similares. A distribuição Weibull é uma função de distribuição especial parametrizada por dois parâmetros
e
.
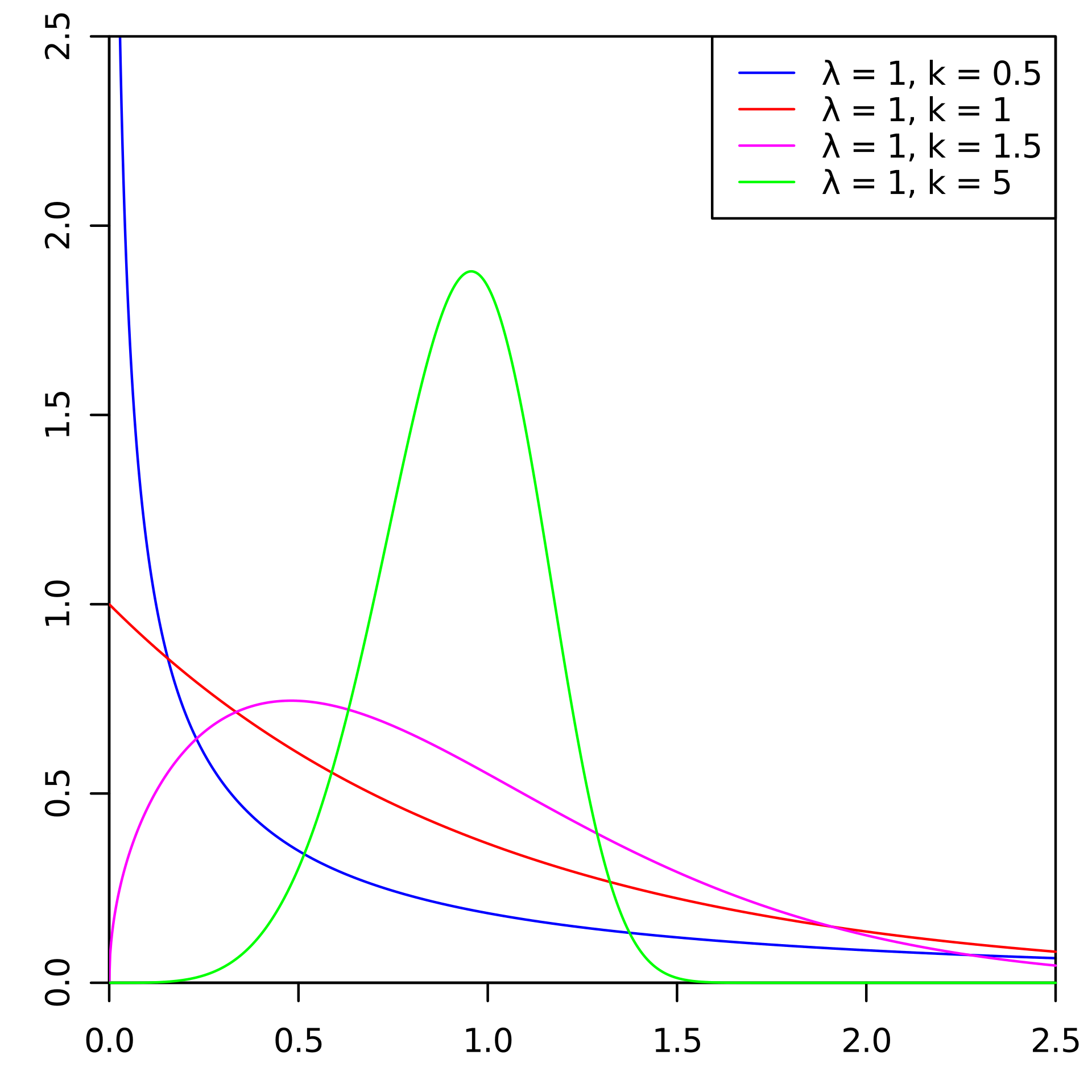 Wikipedia
WikipediaEm geral, a coisa é divertida, mas para prever a vazão e, de fato, na fintech, ela não é usada com tanta frequência. Abaixo, mostramos como fizemos isso (o Laboratório de Mineração de Dados) ao ganhar ouro no AI Championship na nomeação "AI in Banks".
Sobre a saída em geral
Vejamos um pouco o que é a saída do cliente e por que é tão importante. Para os negócios, a base de clientes é importante. Os novos clientes acessam esse banco de dados, por exemplo, depois de aprenderem sobre um produto ou serviço com a publicidade, vivem por algum tempo (usam ativamente os produtos) e depois de algum tempo param de usá-lo. Esse período é chamado de “Ciclo de vida do cliente” (eng. Ciclo de vida do cliente) - um termo que descreve as etapas pelas quais o cliente passa ao descobrir um produto, tomar uma decisão de compra, pagar, usar e se tornar um cliente fiel e, finalmente, parar de usar por um motivo ou outro produto. Consequentemente, a saída é o estágio final do ciclo de vida do cliente quando o cliente deixa de usar os serviços e, para os negócios, isso significa que o cliente deixou de ser lucrativo e, em geral, de qualquer benefício.
Cada cliente do banco é uma pessoa específica que seleciona um cartão bancário específico especificamente para suas necessidades. Muitas vezes viaja - um mapa com milhas é útil. Ele compra muito - olá, cartão com reembolso. Ele compra muito em lojas específicas - e para isso já existe um plástico afiliado especial. Obviamente, às vezes um cartão também é selecionado de acordo com o critério de "Serviço mais barato". Em geral, existem variáveis suficientes aqui.
E outra pessoa escolhe o próprio banco - vale a pena escolher um cartão bancário, cujas agências só estão em Moscou e na região quando você é de Khabarovsk? Se o cartão desse banco for pelo menos duas vezes mais rentável, a presença de agências bancárias próximas ainda é um critério importante. Sim, 2019 já está aqui e o digital é o nosso tudo, mas vários problemas para alguns bancos só podem ser resolvidos na agência. Além disso, novamente, uma parte da população confia em um banco físico muito mais do que em um aplicativo em um smartphone, isso também precisa ser levado em consideração.
Como resultado, uma pessoa pode ter muitos motivos para rejeitar os produtos do banco (ou do próprio banco). Ele mudou de emprego e a taxa do cartão passou de um salário para "Para meros mortais", o que é menos lucrativo. Ele se mudou para outra cidade onde não há agências bancárias. Não gostei de conversar com um operador não qualificado do departamento. Ou seja, pode haver ainda mais motivos para fechar uma conta do que para usar um produto.
E o cliente pode não apenas expressar explicitamente sua intenção - ir ao banco e escrever um extrato, mas simplesmente parar de usar os produtos sem quebrar o contrato. Aqui, para entender esses problemas, foi decidido usar o aprendizado de máquina e a IA.
Além disso, a saída de clientes pode ocorrer em qualquer setor (telecomunicações, provedores de Internet, seguradoras, em geral, onde houver uma base de clientes e transações periódicas).
O que fizemos
Antes de tudo, era necessário descrever um limite claro - desde quando começamos a considerar que o cliente se foi. Do ponto de vista do banco que nos forneceu os dados para o trabalho, o estado de atividade do cliente era binário - está ativo ou não. Havia um sinalizador ACTIVE_FLAG na tabela "Atividade", cujo valor poderia ser "0" ou "1" (respectivamente, "Inativo" e "Ativo"). E tudo ficaria bem, mas a pessoa é capaz de usá-lo ativamente por um tempo e depois sair do ativo por um mês - fica doente, vai para outro país para descansar ou até mesmo para testar o cartão de outro banco. Ou talvez após um longo período de inatividade, comece novamente a usar os serviços do banco
Portanto, decidimos chamar o período de inatividade de um determinado período contínuo durante o qual o sinalizador para ele foi definido como "0".
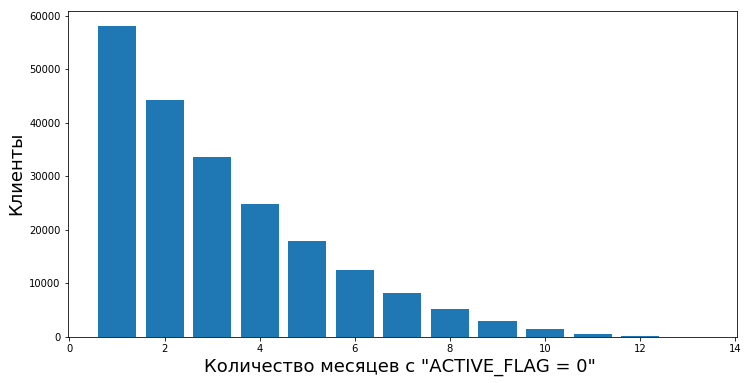
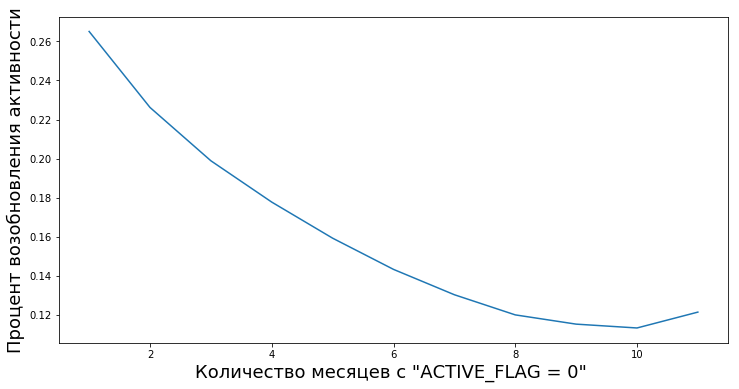
Os clientes passam de inativos para ativos após períodos de inatividade de vários comprimentos. Temos a oportunidade de calcular o grau de valor empírico “confiabilidade dos períodos de inatividade” - ou seja, a probabilidade de uma pessoa voltar a usar os produtos do banco após inatividade temporária.
Por exemplo, este gráfico mostra a retomada da atividade (ACTIVE_FLAG = 1) de clientes após vários meses de inatividade (ACTIVE_FLAG = 0).
Aqui vamos esclarecer um pouco o conjunto de dados com o qual começamos a trabalhar. Portanto, o banco forneceu informações agregadas por 19 meses nas seguintes tabelas:
- “Atividade” - transações mensais de clientes (por cartão, no Internet banking e mobile banking), incluindo informações sobre folha de pagamento e rotatividade.
- "Cartões" - dados de todos os cartões que um cliente possui, com uma programação tarifária detalhada.
- “Contratos” - informações sobre contratos de clientes (abertos e fechados): empréstimos, depósitos, etc., indicando os parâmetros de cada um.
- "Clientes" - um conjunto de dados demográficos (sexo e idade) e a disponibilidade de dados de contato.
Para o trabalho, precisávamos de todas as tabelas, exceto o "Mapa".
A dificuldade aqui era outra coisa - nesses dados o banco não indicava que tipo de atividade ocorreu nos cartões. Ou seja, conseguimos entender se houve transações ou não, mas não conseguimos mais determinar seu tipo. Portanto, não estava claro se o cliente estava sacando dinheiro, se ele recebeu um salário ou se gastou dinheiro em compras. E não tínhamos dados sobre saldos de contas, o que seria útil.
A amostra em si não foi imparcial - nesta seção, durante 19 meses, o banco não fez nenhuma tentativa de reter clientes e minimizar a vazão.
Então, sobre períodos de inatividade.
Para formular a definição de vazão, é necessário escolher um período de inatividade. Para criar uma previsão de saída por vez
, você deve ter um histórico de clientes de pelo menos três meses no intervalo
. Nossa história foi limitada a 19 meses, por isso decidimos levar um período de inatividade de 6 meses, se houver. E pelo período mínimo para uma previsão qualitativa, levaram 3 meses. Os números de 3 e 6 meses foram coletados empiricamente com base em uma análise do comportamento dos dados do cliente.
A definição de saída que formulamos da seguinte forma: saída mensal do cliente
este é o primeiro mês com ACTIVE_FLAG = 0, em que pelo menos seis zeros seguidos no campo ACTIVE_FLAG estão em execução desde este mês, ou seja, o mês desde o qual o cliente está inativo por 6 meses.
 Número de clientes que partiram
Número de clientes que partiram Número de clientes restantes
Número de clientes restantesComo é considerado vazão
Em tais competições e, na verdade, na prática, as saídas são frequentemente previstas dessa maneira. O cliente utiliza produtos e serviços em diferentes intervalos de tempo; os dados sobre a interação com ele são apresentados na forma de um vetor de característica de comprimento fixo n. Na maioria das vezes, essas informações incluem:
- Dados específicos do usuário (dados demográficos, segmento de marketing).
- O histórico do uso de produtos e serviços bancários (são ações do cliente que estão sempre vinculadas a um período ou período específico do intervalo que precisamos).
- Dados externos, se forem capazes de obtê-los - por exemplo, análises de redes sociais.
E depois disso, eles derivam a definição de vazão, própria para cada tarefa. Em seguida, eles usam o algoritmo de aprendizado de máquina, que prevê a probabilidade de o cliente sair
com base no vetor de fatores
. Para aprender o algoritmo, é usada uma das estruturas conhecidas para a construção de conjuntos de árvores de decisão,
XGBoost ,
LightGBM ,
CatBoost ou suas modificações.
O algoritmo em si não é ruim, mas em termos de previsão de vazão, ele tem várias desvantagens sérias.
- Ele não tem a chamada "memória" . A entrada do modelo recebe um determinado número de recursos que correspondem ao momento atual no tempo. Para disponibilizar informações sobre o histórico de alterações nos parâmetros, é necessário calcular recursos especiais que caracterizam alterações nos parâmetros ao longo do tempo, por exemplo, o número ou a quantidade de transações bancárias nos últimos 1,2,3 meses. Essa abordagem pode refletir apenas parcialmente a natureza das mudanças temporárias.
- Horizonte de previsão fixo. O modelo é capaz de prever a saída de clientes apenas por um período predeterminado, por exemplo, uma previsão com um mês de antecedência. Se você precisar de uma previsão para outro período de tempo, por exemplo, por três meses, precisará reconstruir o conjunto de treinamento e treinar novamente o novo modelo.
Nossa abordagem
Decidimos imediatamente que não usaríamos abordagens padrão. Além de nós, 497 pessoas se inscreveram no campeonato, cada uma com uma boa experiência. Portanto, tentar fazer algo de maneira padrão nessas condições não é uma boa ideia.
E começamos a resolver os problemas enfrentados pelo modelo de classificação binária, prevendo a distribuição probabilística dos tempos de saída do cliente. Uma abordagem semelhante pode ser vista
aqui , pois permite uma previsão mais flexível da vazão e teste de hipóteses mais complexas do que na abordagem clássica. Como uma família de distribuições simulando o tempo de saída, escolhemos a
distribuição Weibull por seu amplo uso na análise de sobrevivência. O comportamento do cliente pode ser visto como um tipo de sobrevivência.
Aqui estão exemplos de distribuições de densidade de probabilidade Weibull, dependendo dos parâmetros
e
:
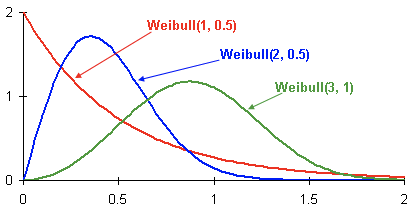
Essa é a distribuição de densidade de probabilidade da rotatividade de clientes de três clientes diferentes ao longo do tempo. O tempo é apresentado em meses. Em outras palavras, este gráfico mostra quando é mais provável que o cliente escoe nos próximos dois meses.Como você pode ver, um cliente com uma distribuição tem um grande potencial de sair mais cedo do que clientes com uma distribuição Weibull (2, 0,5) e Weibull (3.1).
O resultado é um modelo que para todo cliente, para qualquer
do mês prevê os parâmetros de distribuição Weibull, que melhor refletem o início da probabilidade de vazão ao longo do tempo. Se mais detalhes:
- Características-alvo na amostra de treinamento - o tempo restante antes da saída em um mês específico para um cliente específico.
- Se não houver um indicador de vazão para o cliente, assumimos que o tempo de vazão é maior que o número de meses, começando no atual e no final do nosso histórico.
- O modelo utilizado: uma rede neural recorrente com uma camada LSTM.
- Como uma função de perda, usamos a função de probabilidade logarítmica negativa para a distribuição Weibull.
Aqui estão as vantagens deste método:
- A distribuição probabilística, além da possibilidade óbvia de classificação binária, permite prever de forma flexível vários eventos, por exemplo, se o cliente deixa de usar os serviços do banco dentro de 3 meses. Além disso, se necessário, várias métricas podem ser calculadas sobre essa distribuição.
- A rede neural recorrente LSTM possui memória e usa com eficiência todo o histórico. Com a expansão ou aperfeiçoamento da história, a precisão aumenta.
- A abordagem pode ser escalada sem problemas ao dividir os intervalos de tempo em menores (por exemplo, ao dividir meses em semanas).
Mas não basta criar um bom modelo, você também precisa avaliar adequadamente sua qualidade.
Como avaliar a qualidade
Como métrica, escolhemos a curva de elevação. É usado nos negócios para esses casos por causa de uma interpretação compreensível; está bem descrito
aqui e
aqui . Se você descrever o significado dessa métrica em uma frase, obterá “Quantas vezes o algoritmo faz a melhor previsão na primeira
% do que aleatoriamente. "
Treinamos modelos
As condições de concorrência não estabeleceram uma métrica de qualidade específica pela qual vários modelos e abordagens possam ser comparados. Além disso, a definição do conceito de vazão pode ser diferente e pode depender da declaração do problema, que, por sua vez, é determinado pelos objetivos de negócios. Portanto, para entender qual método é melhor, treinamos dois modelos:
- Uma abordagem de classificação binária usada com freqüência usando o algoritmo de aprendizado de máquina de um conjunto de árvores de decisão ( LightGBM );
- Modelo Weibull-LSTM
A amostra de teste consistiu em 500 clientes pré-selecionados que não estavam na amostra de treinamento. Para o modelo, os hiperparâmetros foram selecionados usando a validação cruzada pelo cliente. Para treinar cada modelo, os mesmos conjuntos de atributos foram usados.
Devido ao fato de o modelo não possuir memória, foram tomados sinais especiais para ele, mostrando a razão de alterações nos parâmetros de um mês para o valor médio dos parâmetros nos últimos três meses. O que caracterizou a taxa de mudança de valores no último período de três meses. Sem isso, um modelo baseado na floresta aleatória estaria em uma posição anteriormente perdida em relação ao Weibull-LSTM.
Por que o LSTM com distribuição Weibull é melhor do que a abordagem baseada no conjunto de árvores de decisão
Aqui, tudo é claramente literalmente algumas fotos.
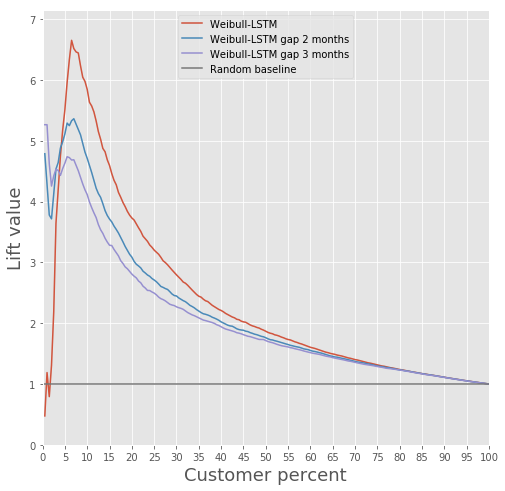 Comparação da curva de elevação para o algoritmo clássico e Weibull-LSTM
Comparação da curva de elevação para o algoritmo clássico e Weibull-LSTM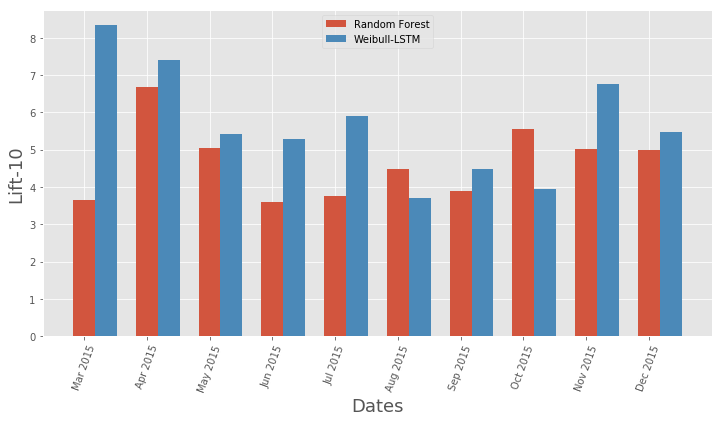 Comparação Métrica da Curva de Elevação Mensal para Algoritmo Clássico e Weibull-LSTM
Comparação Métrica da Curva de Elevação Mensal para Algoritmo Clássico e Weibull-LSTMEm geral, o LSTM executa o algoritmo clássico em quase todos os casos.
Previsão de vazão
Um modelo baseado em uma rede neural recorrente com células LSTM com uma distribuição Weibull pode prever a saída com antecedência, por exemplo, prever a saída de um cliente nos próximos n meses. Considere o caso de n = 3. Nesse caso, para cada mês, a rede neural deve determinar corretamente se o cliente sairá do próximo mês até o nono mês. Em outras palavras, ela deve determinar corretamente se o cliente permanecerá após n meses. Isso pode ser considerado uma previsão antecipada: prever o momento em que o cliente começou a pensar em como sair.
Compare a curva de elevação para Weibull-LSTM 1, 2 e 3 meses antes da saída:
Já escrevemos acima que as previsões feitas para clientes que não estão ativos há algum tempo também são importantes. Portanto, adicionaremos à amostra esses casos quando o cliente que já partiu estiver inativo por um ou dois meses e verificaremos que o Weibull-LSTM classifica corretamente esses casos como vazão. Como esses casos estavam presentes na amostra, esperamos que a rede lide bem com eles:
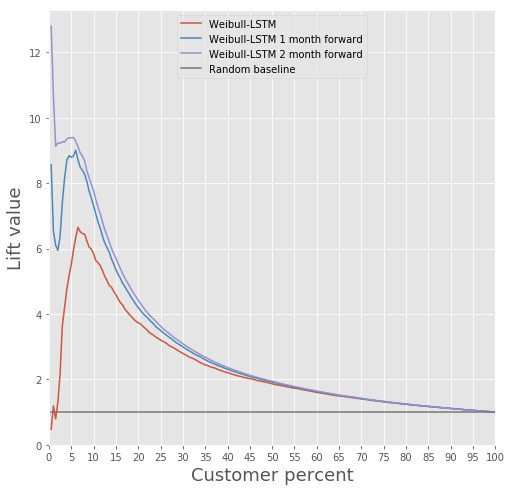
Retenção de clientes
Na verdade, isso é a principal coisa que pode ser feita com informações disponíveis que tais e tais clientes estão preparando para parar de usar o produto. Falando sobre a construção de um modelo que possa oferecer algo útil aos clientes para mantê-los, isso não funcionará se você não tiver um histórico dessas tentativas que terminariam bem.
Como não tínhamos uma história, decidimos assim.
- Estamos construindo um modelo que define produtos interessantes para cada cliente.
- Em cada mês, executamos um classificador e identificamos clientes em potencial.
- Alguns clientes oferecem um produto, de acordo com o modelo do parágrafo 1, lembram-se de suas ações.
- Após alguns meses, analisamos quais desses clientes potencialmente saíram e quais permaneceram. Assim, formamos uma amostra de treinamento.
- Nós treinamos o modelo na história obtida no parágrafo 4.
- Opcionalmente, repita o procedimento, substituindo o modelo do parágrafo 1 pelo modelo obtido no parágrafo 5.
O teste A / B usual pode servir como uma verificação da qualidade dessa retenção - dividimos os clientes que potencialmente saem em dois grupos. Oferecemos produtos baseados em nosso modelo de retenção para um e não oferecemos nada para o segundo. Decidimos treinar um modelo que já poderia se beneficiar no ponto 1 do nosso exemplo.
Queríamos tornar a segmentação o mais interpretável possível. Para isso, escolhemos vários sinais que podem ser facilmente interpretados: número total de transações, salário, rotatividade total da conta, idade, sexo. Os sinais da tabela "Cartões" não foram considerados não informativos e os sinais da tabela 3 "Contratos" - devido à complexidade do processamento, a fim de evitar o vazamento de dados entre o conjunto de validação e o conjunto de treinamento.
O agrupamento foi realizado usando modelos de mistura gaussiana.
O critério de informação de Akaike tornou possível determinar 2 ótimos. O primeiro ideal corresponde a 1 cluster. O segundo ideal, menos pronunciado, corresponde a 80 agrupamentos. A seguinte conclusão pode ser extraída desse resultado: é extremamente difícil dividir dados em clusters sem informações a priori. Para um melhor armazenamento em cluster, você precisa de dados que descrevam cada cliente em detalhes.Portanto, a tarefa de treinar com um professor foi considerada para oferecer a cada cliente individualmente um produto. Foram considerados os seguintes produtos: “Depósito a prazo”, “Cartão de crédito”, “Cheque especial”, “Empréstimo ao consumidor”, “Empréstimo para carro”, “Hipoteca”.Outro tipo de produto estava presente nos dados: “Conta Corrente”. Mas não o consideramos por causa do baixo conteúdo de informações. Por usuários clientes do banco, ou seja, Eles não pararam de usar seus produtos, foi construído um modelo que previa qual produto poderia ser do seu interesse. A regressão logística foi escolhida como modelo, e o valor de elevação dos 10 primeiros percentis foi usado como métrica de avaliação da qualidade.A qualidade do modelo pode ser estimada na figura.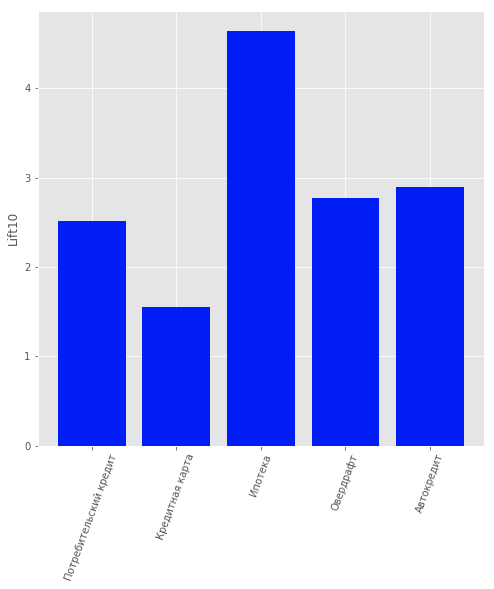 Resultados do modelo de recomendação do cliente
Resultados do modelo de recomendação do clienteSumário
Essa abordagem nos trouxe o primeiro lugar na nomeação “AI nos bancos” no Campeonato de IA do RAIF-Challenge 2017. Aparentemente, o principal foi abordar o problema de um lado incomum e usar um método comumente usado para outras situações.Embora a saída massiva de usuários possa muito bem ser um desastre natural para serviços.Esse método também pode ser observado em qualquer outra área em que é importante considerar a saída, não pelos bancos como um todo. Por exemplo, usamos para calcular nossa própria vazão - nas filiais da Rostelecom na Sibéria e São Petersburgo.Empresa "Laboratório de mineração de dados" "Portal de pesquisa" Sputnik "
Aparentemente, o principal foi abordar o problema de um lado incomum e usar um método comumente usado para outras situações.Embora a saída massiva de usuários possa muito bem ser um desastre natural para serviços.Esse método também pode ser observado em qualquer outra área em que é importante considerar a saída, não pelos bancos como um todo. Por exemplo, usamos para calcular nossa própria vazão - nas filiais da Rostelecom na Sibéria e São Petersburgo.Empresa "Laboratório de mineração de dados" "Portal de pesquisa" Sputnik "