Nos artigos anteriores, discutimos o
mecanismo de indexação do PostgreSQL,
a interface dos métodos de acesso e dois métodos de acesso:
índice de hash e
árvore B. Neste artigo, descreveremos os índices GiST.
Gist
GiST é uma abreviação de "árvore de pesquisa generalizada". Esta é uma árvore de pesquisa equilibrada, assim como "b-tree" discutido anteriormente.
Qual a diferença? O índice "Btree" está estritamente conectado à semântica da comparação: suporte de operadores "maiores", "menos" e "iguais" é tudo o que é capaz (mas muito capaz!). No entanto, os bancos de dados modernos armazenam tipos de dados para os quais esses operadores simplesmente não faz sentido: dados geográficos, documentos de texto, imagens, ...
O método de índice GiST vem em nosso auxílio para esses tipos de dados. Permite definir uma regra para distribuir dados de um tipo arbitrário por uma árvore balanceada e um método para usar essa representação para acesso de algum operador. Por exemplo, o índice GiST pode "acomodar" a árvore R para dados espaciais com suporte de operadores de posição relativa (localizado à esquerda, à direita, contém etc.) ou a árvore RD para conjuntos com suporte para operadores de interseção ou inclusão.
Graças à extensibilidade, um método totalmente novo pode ser criado do zero no PostgreSQL: para esse fim, uma interface com o mecanismo de indexação deve ser implementada. Mas isso requer premeditação não apenas da lógica de indexação, mas também do mapeamento de estruturas de dados para páginas, implementação eficiente de bloqueios e suporte a um log write-ahead. Tudo isso pressupõe altas habilidades de desenvolvedor e um grande esforço humano. O GiST simplifica a tarefa assumindo problemas de baixo nível e oferecendo sua própria interface: várias funções pertencentes não às técnicas, mas ao domínio do aplicativo. Nesse sentido, podemos considerar o GiST como uma estrutura para a construção de novos métodos de acesso.
Estrutura
O GiST é uma árvore com altura equilibrada que consiste em páginas de nós. Os nós consistem em linhas de índice.
Cada linha de um nó folha (linha folha), em geral, contém algum
predicado (expressão booleana) e uma referência a uma linha da tabela (TID). Os dados indexados (chave) devem atender a esse predicado.
Cada linha de um nó interno (linha interna) também contém um
predicado e uma referência a um nó filho, e todos os dados indexados da subárvore filho devem atender a esse predicado. Em outras palavras, o predicado de uma linha interna
inclui os predicados de todas as linhas filhas. Essa característica importante do índice GiST substitui a ordenação simples da árvore B.
A pesquisa na árvore do GiST usa uma
função de consistência especializada ("consistente") - uma das funções definidas pela interface e implementadas de maneira própria para cada família de operadores suportada.
A função de consistência é chamada para uma linha de índice e determina se o predicado dessa linha é consistente com o predicado de pesquisa (especificado como "
expressão do operador de campo indexado "). Para uma linha interna, essa função realmente determina se é necessário descer para a subárvore correspondente e, para uma linha folha, a função determina se os dados indexados atendem ao predicado.
A pesquisa começa com um nó raiz, como uma pesquisa em árvore normal. A função de consistência permite descobrir em quais nós filhos faz sentido inserir (pode haver vários deles) e quais não. O algoritmo é então repetido para cada nó filho encontrado. E se o nó for folha, a linha selecionada pela função de consistência será retornada como um dos resultados.
A pesquisa é aprofundada: o algoritmo primeiro tenta alcançar um nó folha. Isso permite retornar os primeiros resultados em breve, sempre que possível (o que pode ser importante se o usuário estiver interessado apenas em vários resultados e não em todos).
Vamos observar novamente que a função de consistência não precisa ter nada a ver com operadores "maiores", "menos" ou "iguais". A semântica da função consistency pode ser bem diferente e, portanto, não se supõe que o índice retorne valores em uma determinada ordem.
Não discutiremos algoritmos de inserção e exclusão de valores no GiST: mais algumas
funções de interface executam essas operações. Há um ponto importante no entanto. Quando um novo valor é inserido no índice, a posição para esse valor na árvore é selecionada para que os predicados de suas linhas pai sejam estendidos o mínimo possível (idealmente, não estendidos). Mas quando um valor é excluído, o predicado da linha pai não é mais reduzido. Isso acontece apenas em casos como estes: uma página é dividida em duas (quando a página não possui espaço suficiente para inserção de uma nova linha de índice) ou o índice é recriado do zero (com o comando REINDEX ou VACUUM FULL). Portanto, a eficiência do índice GiST para alterar frequentemente os dados pode diminuir com o tempo.
Além disso, consideraremos alguns exemplos de índices para vários tipos de dados e propriedades úteis do GiST:
- Pontos (e outras entidades geométricas) e busca dos vizinhos mais próximos.
- Intervalos e restrições de exclusão.
- Pesquisa de texto completo.
Árvore R para pontos
Ilustraremos o acima por exemplo de um índice de pontos em um plano (também podemos construir índices semelhantes para outras entidades geométricas). Uma árvore B regular não se adequa a esse tipo de dado, pois não há operadores de comparação definidos para pontos.
A idéia da árvore R é dividir o plano em retângulos que, no total, cobrem todos os pontos indexados. Uma linha de índice armazena um retângulo, e o predicado pode ser definido assim: "o ponto procurado está dentro do retângulo especificado".
A raiz da árvore R conterá vários retângulos maiores (possivelmente se cruzam). Os nós filhos conterão retângulos de tamanho menor que são incorporados no pai e no total cobrem todos os pontos subjacentes.
Em teoria, os nós folha devem conter pontos sendo indexados, mas o tipo de dados deve ser o mesmo em todas as linhas do índice e, portanto, novamente os retângulos são armazenados, mas "recolhidos" em pontos.
Para visualizar essa estrutura, fornecemos imagens para três níveis da árvore R. Os pontos são coordenadas de aeroportos (semelhantes às da tabela "aeroportos" do
banco de dados demo , mas são fornecidos mais dados do
openflights.org ).
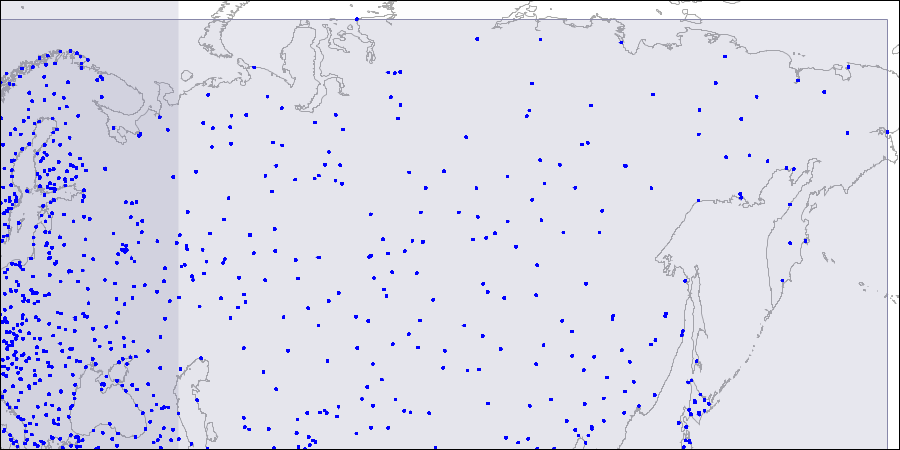 Nível um: dois retângulos grandes que se cruzam são visíveis.
Nível um: dois retângulos grandes que se cruzam são visíveis. Nível dois: retângulos grandes são divididos em áreas menores.
Nível dois: retângulos grandes são divididos em áreas menores.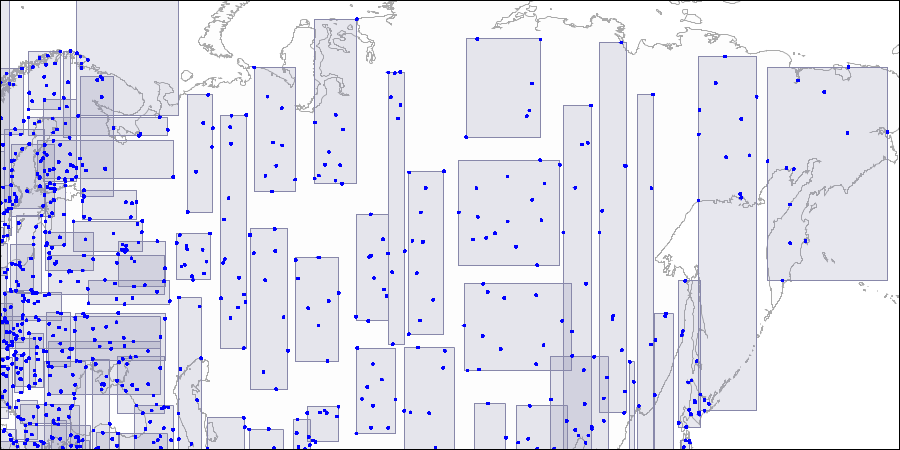 Nível três: cada retângulo contém quantos pontos cabem em uma página de índice.
Nível três: cada retângulo contém quantos pontos cabem em uma página de índice.Agora vamos considerar um exemplo muito simples de "nível único":
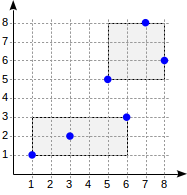
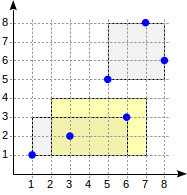
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index on points using gist(p);
Com essa divisão, a estrutura do índice terá a seguinte aparência:
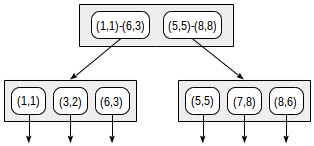
O índice criado pode ser usado para acelerar a seguinte consulta, por exemplo: "encontre todos os pontos contidos no retângulo especificado". Essa condição pode ser formalizada da seguinte maneira:
p <@ box '(2,1),(6,3)' (operador
<@ da família "points_ops" significa "contido em"):
postgres=# set enable_seqscan = off; postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN ---------------------------------------------- Index Only Scan using points_p_idx on points Index Cond: (p <@ '(7,4),(2,1)'::box) (2 rows)
A função de consistência do operador ("
campo indexado <@
expressão ", em que o
campo indexado é um ponto e a
expressão é um retângulo) é definida da seguinte maneira. Para uma linha interna, ele retorna "yes" se seu retângulo cruzar com o retângulo definido pela
expressão . Para uma linha folha, a função retornará "yes" se seu ponto (retângulo "recolhido") estiver contido no retângulo definido pela expressão.
A pesquisa começa com o nó raiz. O retângulo (2,1) - (7,4) cruza com (1,1) - (6,3), mas não cruza com (5,5) - (8,8), portanto, não há necessidade para descer para a segunda subárvore.
Ao atingir um nó folha, passamos pelos três pontos contidos nele e retornamos dois deles como resultado: (3.2) e (6.3).
postgres=# select * from points where p <@ box '(2,1),(7,4)';
p ------- (3,2) (6,3) (2 rows)
Internals
Infelizmente, o "pageinspect" habitual não permite olhar para o índice GiST. Mas outra maneira está disponível: extensão "gevel". Não está incluído na entrega padrão, portanto, consulte
as instruções de instalação .
Se tudo estiver certo, três funções estarão disponíveis para você. Primeiro, podemos obter algumas estatísticas:
postgres=# select * from gist_stat('airports_coordinates_idx');
gist_stat ------------------------------------------ Number of levels: 4 + Number of pages: 690 + Number of leaf pages: 625 + Number of tuples: 7873 + Number of invalid tuples: 0 + Number of leaf tuples: 7184 + Total size of tuples: 354692 bytes + Total size of leaf tuples: 323596 bytes + Total size of index: 5652480 bytes+ (1 row)
É claro que o tamanho do índice nas coordenadas do aeroporto é de 690 páginas e que o índice consiste em quatro níveis: a raiz e dois níveis internos foram mostrados nas figuras acima, e o quarto nível é folha.
Na verdade, o índice de oito mil pontos será significativamente menor: aqui foi criado com um fator de preenchimento de 10% para maior clareza.
Segundo, podemos gerar a árvore de índice:
postgres=# select * from gist_tree('airports_coordinates_idx');
gist_tree ----------------------------------------------------------------------------------------- 0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) + 1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) + 1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) + 1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) + 2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) + 3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) + 4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) + ...
E terceiro, podemos gerar os dados armazenados nas linhas de índice. Observe a seguinte nuance: o resultado da função deve ser convertido no tipo de dados necessário. Na nossa situação, esse tipo é "caixa" (um retângulo delimitador). Por exemplo, observe cinco linhas no nível superior:
postgres=# select level, a from gist_print('airports_coordinates_idx') as t(level int, valid bool, a box) where level = 1;
level | a -------+----------------------------------------------------------------------- 1 | (47.663586,80.803207),(-39.2938003540039,-90) 1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336) 1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047) 1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291) 1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088) (5 rows)
Na verdade, os números fornecidos acima foram criados apenas a partir desses dados.
Operadores para pesquisa e pedidos
Os operadores discutidos até o momento (como
<@ no predicado
p <@ box '(2,1),(7,4)' ) podem ser chamados de operadores de pesquisa, pois especificam condições de pesquisa em uma consulta.
Há também outro tipo de operador: solicitar operadores. Eles são usados para especificações da ordem de classificação na cláusula ORDER BY, em vez de especificações convencionais de nomes de colunas. A seguir, é apresentado um exemplo dessa consulta:
postgres=# select * from points order by p <-> point '(4,7)' limit 2;
p ------- (5,5) (7,8) (2 rows)
p <-> point '(4,7)' aqui é uma expressão que usa um operador de pedidos
<-> , que indica a distância de um argumento para o outro. O significado da consulta é retornar dois pontos mais próximos ao ponto (4.7). Uma pesquisa como essa é conhecida como k-NN - pesquisa do vizinho mais próximo.
Para suportar consultas desse tipo, um método de acesso deve definir uma
função de distância adicional e o operador de pedidos deve ser incluído na classe de operadores apropriada (por exemplo, classe "points_ops" para pontos). A consulta abaixo mostra os operadores, juntamente com seus tipos ("s" - pesquisa e "o" - ordenação):
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------+-------------+-------------- <<(point,point) | s | 1 strictly left >>(point,point) | s | 5 strictly right ~=(point,point) | s | 6 coincides <^(point,point) | s | 10 strictly below >^(point,point) | s | 11 strictly above <->(point,point) | o | 15 distance <@(point,box) | s | 28 contained in rectangle <@(point,polygon) | s | 48 contained in polygon <@(point,circle) | s | 68 contained in circle (9 rows)
Os números de estratégias também são mostrados, com seus significados explicados. É claro que existem muito mais estratégias do que para "btree", apenas algumas delas são suportadas por pontos. Diferentes estratégias podem ser definidas para outros tipos de dados.
A função distance é chamada para um elemento de índice e deve calcular a distância (levando em consideração a semântica do operador) do valor definido pela expressão ("
expressão de operador de ordenação de campo indexado ") para o elemento fornecido. Para um elemento folha, essa é apenas a distância do valor indexado. Para um elemento interno, a função deve retornar o mínimo das distâncias para os elementos da folha filho. Como percorrer todas as linhas filhas seria muito caro, é permitido que a função subestime otimisticamente a distância, mas à custa de reduzir a eficiência da pesquisa. No entanto, a função nunca pode superestimar a distância, pois isso interromperá o trabalho do índice.
A função distance pode retornar valores de qualquer tipo classificável (para ordenar valores, o PostgreSQL utilizará semântica de comparação da família de operadores apropriada do método de acesso "btree", conforme
descrito anteriormente ).
Para pontos em um plano, a distância é interpretada em um sentido muito usual: o valor de
(x1,y1) <-> (x2,y2) é igual à raiz quadrada da soma dos quadrados das diferenças das abscissas e ordenadas. A distância de um ponto a um retângulo delimitador é considerada a distância mínima do ponto até esse retângulo ou zero se o ponto estiver dentro do retângulo. É fácil calcular esse valor sem percorrer os pontos filhos, e o valor certamente não é maior que a distância de qualquer ponto filho.
Vamos considerar o algoritmo de pesquisa para a consulta acima.
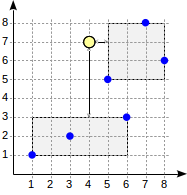
A pesquisa começa com o nó raiz. O nó contém dois retângulos delimitadores. A distância de (1,1) - (6,3) é 4,0 e de (5,5) - (8,8) é 1,0.
Nós filhos são percorridos na ordem de aumentar a distância. Dessa forma, primeiro descemos para o nó filho mais próximo e calculamos as distâncias para os pontos (mostraremos os números na figura para visibilidade):

Esta informação é suficiente para retornar os dois primeiros pontos, (5,5) e (7,8). Como sabemos que a distância para os pontos que estão dentro do retângulo (1,1) - (6,3) é de 4,0 ou superior, não precisamos descer para o primeiro nó filho.
Mas e se precisássemos encontrar os
três primeiros pontos?
postgres=# select * from points order by p <-> point '(4,7)' limit 3;
p
Embora o segundo nó filho contenha todos esses pontos, não podemos retornar (8,6) sem examinar o primeiro nó filho, pois esse nó pode conter pontos mais próximos (desde 4,0 <4,1).

Para linhas internas, este exemplo esclarece os requisitos para a função de distância. Ao selecionar uma distância menor (4,0 em vez de 4,5 reais) para a segunda linha, reduzimos a eficiência (o algoritmo começou desnecessariamente a examinar um nó extra), mas não quebramos a correção do algoritmo.
Até recentemente, o GiST era o único método de acesso capaz de lidar com operadores de pedidos. Mas a situação mudou: o método de acesso ao RUM (a ser discutido mais adiante) já se juntou a esse grupo de métodos, e não é improvável que a boa e velha árvore B se junte a eles: um patch desenvolvido por Nikita Glukhov, nossa colega, está sendo discutido pela comunidade.
A partir de março de 2019, o suporte ao k-NN será adicionado ao SP-GiST no próximo PostgreSQL 12 (também de autoria da Nikita). O patch para a árvore B ainda está em andamento.
Árvore R para intervalos
Outro exemplo do uso do método de acesso GiST é a indexação de intervalos, por exemplo, intervalos de tempo (tipo "tsrange"). Toda a diferença é que os nós internos conterão intervalos delimitadores, em vez de retângulos delimitadores.
Vamos considerar um exemplo simples. Vamos alugar uma casa de campo e armazenar intervalos de reserva em uma tabela:
postgres=# create table reservations(during tsrange); postgres=# insert into reservations(during) values ('[2016-12-30, 2017-01-09)'), ('[2017-02-23, 2017-02-27)'), ('[2017-04-29, 2017-05-02)'); postgres=# create index on reservations using gist(during);
O índice pode ser usado para acelerar a seguinte consulta, por exemplo:
postgres=# select * from reservations where during && '[2017-01-01, 2017-04-01)';
during ----------------------------------------------- ["2016-12-30 00:00:00","2017-01-08 00:00:00") ["2017-02-23 00:00:00","2017-02-26 00:00:00") (2 rows)
postgres=# explain (costs off) select * from reservations where during && '[2017-01-01, 2017-04-01)';
QUERY PLAN ------------------------------------------------------------------------------------ Index Only Scan using reservations_during_idx on reservations Index Cond: (during && '["2017-01-01 00:00:00","2017-04-01 00:00:00")'::tsrange) (2 rows)
&& operador
&& para intervalos indica interseção; portanto, a consulta deve retornar todos os intervalos que se cruzam com o determinado. Para esse operador, a função de consistência determina se o intervalo especificado cruza com um valor em uma linha interna ou folha.
Observe que não se trata de obter intervalos em uma determinada ordem, embora os operadores de comparação estejam definidos para intervalos. Podemos usar o índice "btree" para intervalos, mas, neste caso, teremos que ficar sem o suporte de operações como estas:
postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'range_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gist' and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy -------------------------+-------------+-------------- @>(anyrange,anyelement) | s | 16 contains element <<(anyrange,anyrange) | s | 1 strictly left &<(anyrange,anyrange) | s | 2 not beyond right boundary &&(anyrange,anyrange) | s | 3 intersects &>(anyrange,anyrange) | s | 4 not beyond left boundary >>(anyrange,anyrange) | s | 5 strictly right -|-(anyrange,anyrange) | s | 6 adjacent @>(anyrange,anyrange) | s | 7 contains interval <@(anyrange,anyrange) | s | 8 contained in interval =(anyrange,anyrange) | s | 18 equals (10 rows)
(Exceto a igualdade, que está contida na classe do operador para o método de acesso "btree").
Internals
Podemos olhar para dentro usando a mesma extensão "gevel". Só precisamos lembrar de alterar o tipo de dados na chamada para gist_print:
postgres=# select level, a from gist_print('reservations_during_idx') as t(level int, valid bool, a tsrange);
level | a -------+----------------------------------------------- 1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00") 1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00") 1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00") (3 rows)
Restrição de exclusão
O índice GiST pode ser usado para suportar restrições de exclusão (EXCLUDE).
A restrição de exclusão garante que determinados campos de duas linhas da tabela não "correspondam" entre si em termos de alguns operadores. Se o operador "igual" for escolhido, obteremos exatamente a restrição exclusiva: os campos de duas linhas não são iguais.
A restrição de exclusão é suportada pelo índice, bem como a restrição exclusiva. Podemos escolher qualquer operador para que:
- É suportado pelo método de índice - propriedade "can_exclude" (por exemplo, "btree", GiST ou SP-GiST, mas não GIN).
- É comutativo, ou seja, a condição é atendida: a operador b = b operador a.
Esta é uma lista de estratégias e exemplos adequados de operadores (os operadores, como lembramos, podem ter nomes diferentes e estar disponíveis para todos os tipos de dados):
- Para "btree":
- Para GiST e SP-GiST:
- "Interseção"
&& - "Coincidência"
~= - Adjacência
-|-
Observe que podemos usar o operador de igualdade em uma restrição de exclusão, mas é impraticável: uma restrição exclusiva será mais eficiente. É exatamente por isso que não abordamos as restrições de exclusão quando discutimos as árvores-B.
Vamos dar um exemplo do uso de uma restrição de exclusão. É razoável não permitir reservas para intervalos de interseção.
postgres=# alter table reservations add exclude using gist(during with &&);
Depois de criar a restrição de exclusão, podemos adicionar linhas:
postgres=# insert into reservations(during) values ('[2017-06-10, 2017-06-13)');
Mas uma tentativa de inserir um intervalo de interseção na tabela resultará em um erro:
postgres=# insert into reservations(during) values ('[2017-05-15, 2017-06-15)');
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl" DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
Extensão "Btree_gist"
Vamos complicar o problema. Expandimos nossos humildes negócios e vamos alugar vários chalés:
postgres=# alter table reservations add house_no integer default 1;
Precisamos alterar a restrição de exclusão para que os números das casas sejam levados em consideração. O GiST, no entanto, não suporta a operação de igualdade para números inteiros:
postgres=# alter table reservations drop constraint reservations_during_excl; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Nesse caso, a extensão "
btree_gist " ajudará, o que adiciona o suporte do GiST às operações inerentes às árvores B. O GiST, eventualmente, pode oferecer suporte a qualquer operador, então por que não devemos ensiná-lo a oferecer suporte a operadores "maiores", "menos" e "iguais"?
postgres=# create extension btree_gist; postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
Agora ainda não podemos reservar o primeiro chalé para as mesmas datas:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 1);
ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
No entanto, podemos reservar o segundo:
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 2);
Mas esteja ciente de que, embora o GiST possa de alguma forma oferecer suporte a operadores "maiores", "menos" e "iguais", a B-tree ainda faz isso melhor. Portanto, vale a pena usar essa técnica apenas se o índice GiST for essencialmente necessário, como em nosso exemplo.
Árvore RD para pesquisa de texto completo
Sobre a pesquisa de texto completo
Vamos começar com uma introdução minimalista à pesquisa de texto completo do PostgreSQL (se você souber, pode pular esta seção).
A tarefa da pesquisa de texto completo é selecionar no conjunto de documentos os documentos que
correspondem à consulta de pesquisa. (Se houver muitos documentos correspondentes, é importante encontrar
a melhor correspondência , mas não falaremos sobre isso neste momento.)
Para fins de pesquisa, um documento é convertido em um tipo especializado "tsvector", que contém
lexemes e suas posições no documento. Lexemes são palavras convertidas para o formato adequado para pesquisa. Por exemplo, as palavras são normalmente convertidas em minúsculas e as terminações variáveis são cortadas:
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile');
to_tsvector ----------------------------------------- 'crook':4,10 'man':5 'mile':11 'walk':8 (1 row)
Também podemos ver que algumas palavras (chamadas de
palavras de parada ) são totalmente descartadas ("lá", "era", "a", "e", "ele"), pois presumivelmente ocorrem com muita frequência para que as pesquisas façam sentido. Todas essas conversões certamente podem ser configuradas, mas isso é outra história.
Uma consulta de pesquisa é representada com outro tipo: "tsquery". Grosso modo, uma consulta consiste em um ou vários lexemas articulados por conectivos: "e" & "ou" |, "not"! .. Também podemos usar parênteses para esclarecer a precedência da operação.
postgres=# select to_tsquery('man & (walking | running)');
to_tsquery ---------------------------- 'man' & ( 'walk' | 'run' ) (1 row)
Apenas um operador de correspondência
@@ é usado para pesquisa de texto completo.
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (walking | running)');
?column? ---------- t (1 row)
postgres=# select to_tsvector('There was a crooked man, and he walked a crooked mile') @@ to_tsquery('man & (going | running)');
?column? ---------- f (1 row)
Esta informação é suficiente por enquanto. Vamos nos aprofundar um pouco mais na pesquisa de texto completo em um próximo artigo que apresenta o índice GIN.
Árvores RD
Para uma pesquisa rápida de texto completo, primeiro, a tabela precisa armazenar uma coluna do tipo "tsvector" (para evitar a realização de uma conversão dispendiosa sempre que pesquisar) e, em segundo lugar, um índice deve ser criado nessa coluna. Um dos métodos de acesso possíveis para isso é o GiST.
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# create index on ts using gist(doc_tsv); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc);
Certamente, é conveniente confiar um gatilho na última etapa (conversão do documento em "tsvector").
postgres=# select * from ts;
-[ RECORD 1 ]---------------------------------------------------- doc | Can a sheet slitter slit sheets? doc_tsv | 'sheet':3,6 'slit':5 'slitter':4 -[ RECORD 2 ]---------------------------------------------------- doc | How many sheets could a sheet slitter slit? doc_tsv | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 -[ RECORD 3 ]---------------------------------------------------- doc | I slit a sheet, a sheet I slit. doc_tsv | 'sheet':4,6 'slit':2,8 -[ RECORD 4 ]---------------------------------------------------- doc | Upon a slitted sheet I sit. doc_tsv | 'sheet':4 'sit':6 'slit':3 'upon':1 -[ RECORD 5 ]---------------------------------------------------- doc | Whoever slit the sheets is a good sheet slitter. doc_tsv | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 -[ RECORD 6 ]---------------------------------------------------- doc | I am a sheet slitter. doc_tsv | 'sheet':4 'slitter':5 -[ RECORD 7 ]---------------------------------------------------- doc | I slit sheets. doc_tsv | 'sheet':3 'slit':2 -[ RECORD 8 ]---------------------------------------------------- doc | I am the sleekest sheet slitter that ever slit sheets. doc_tsv | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 -[ RECORD 9 ]---------------------------------------------------- doc | She slits the sheet she sits on. doc_tsv | 'sheet':4 'sit':6 'slit':2
Como o índice deve ser estruturado? O uso da árvore R diretamente não é uma opção, pois não está claro como definir um "retângulo delimitador" para documentos. Mas podemos aplicar alguma modificação dessa abordagem para conjuntos, uma árvore chamada RD (RD significa "Russian Doll"). Um conjunto é entendido como um conjunto de lexemas nesse caso, mas, em geral, um conjunto pode ser qualquer um.
Uma idéia das árvores RD é substituir um retângulo delimitador por um conjunto delimitador, ou seja, um conjunto que contenha todos os elementos dos conjuntos filhos.
Uma questão importante surge como representar conjuntos nas linhas de índice. A maneira mais direta é apenas enumerar todos os elementos do conjunto. Isso pode parecer da seguinte maneira:

Então, por exemplo, para acessar pela condição
doc_tsv @@ to_tsquery('sit') , poderíamos descer apenas para os nós que contêm o
doc_tsv @@ to_tsquery('sit') “sit”:
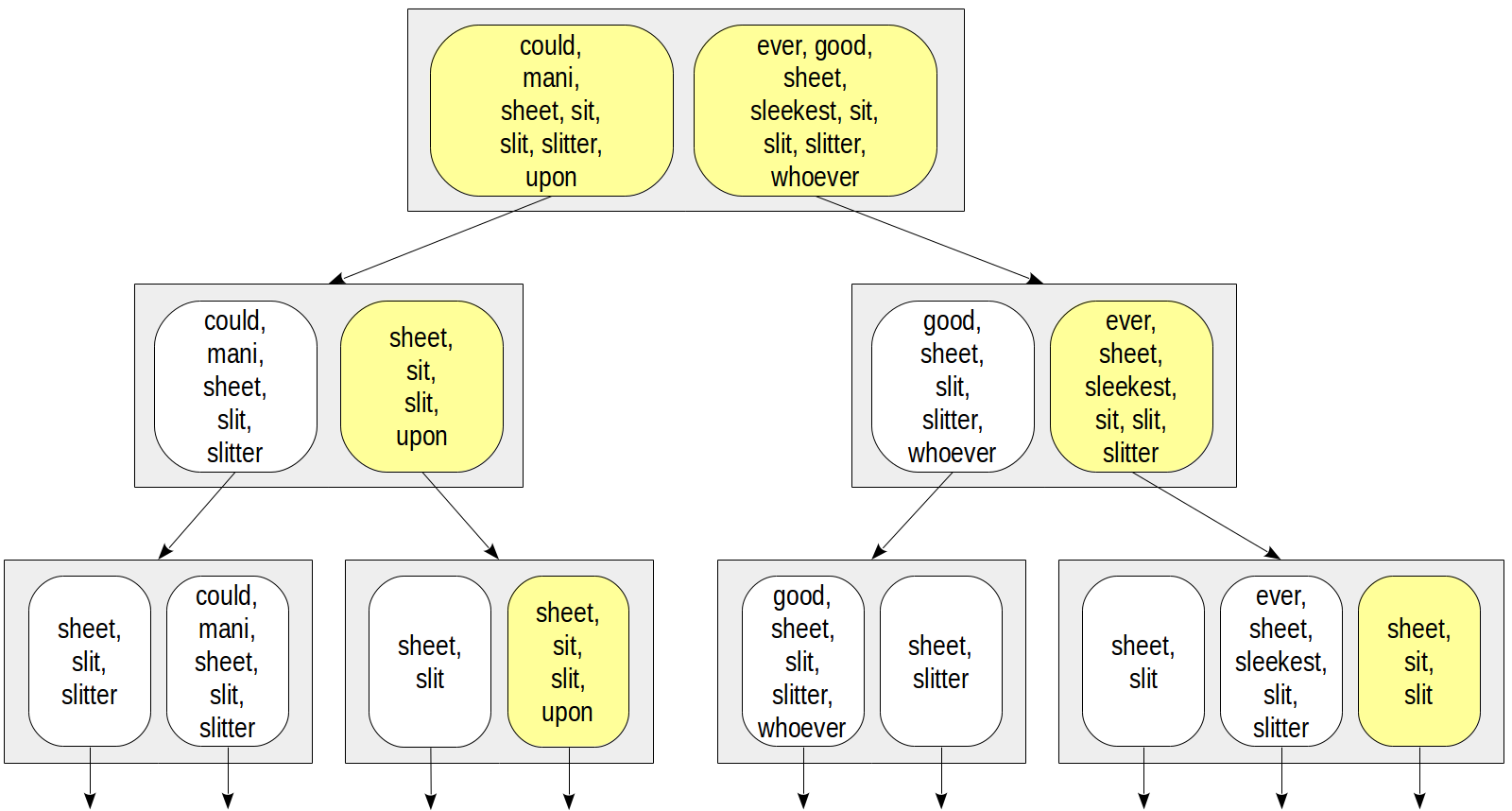
Essa representação tem questões evidentes. O número de lexemes em um documento pode ser bastante grande, portanto, as linhas de índice terão um tamanho grande e entrarão no TOAST, tornando o índice muito menos eficiente. Mesmo que cada documento tenha poucos lexemes exclusivos, a união de conjuntos ainda pode ser muito grande: quanto maior a raiz, maiores as linhas de índice.
Às vezes, uma representação como essa é usada, mas para outros tipos de dados. E a pesquisa de texto completo usa outra solução mais compacta - a chamada
árvore de assinaturas . Sua idéia é bastante familiar para todos os que lidaram com o filtro Bloom.
Cada léxico pode ser representado com sua
assinatura : uma sequência de bits de um determinado comprimento em que todos os bits, exceto um, são zero. A posição desse bit é determinada pelo valor da função hash do léxico (discutimos
anteriormente as funções hash
anteriormente ).
A assinatura do documento é o OR bit a bit das assinaturas de todos os lexemes do documento.
Vamos assumir as seguintes assinaturas de lexemes:
poderia 1.000.000
ever 0001000
good 0000010
mani 0000100
folha 0000100
0100000
sit 0010000
fenda 0001000
talhadeira 0000001
upon 0000010
quem quer que seja 0010000
Em seguida, as assinaturas dos documentos são assim:
Uma folha pode cortar folhas de fenda? 0001101
Quantas folhas uma talhadeira poderia cortar? 1001101
Eu corto uma folha, uma folha eu corto. 0001100
Sobre um lençol cortado, eu sento. 0011110
Quem corta os lençóis é um bom cortador de folhas. 0011111
Eu sou um cortador de folhas. 0000101
Eu corto lençóis. 0001100
Eu sou o cortador de folhas mais elegante que já cortou folhas. 0101101
Ela corta o lençol em que se senta. 0011100
A árvore de índice pode ser representada da seguinte maneira:
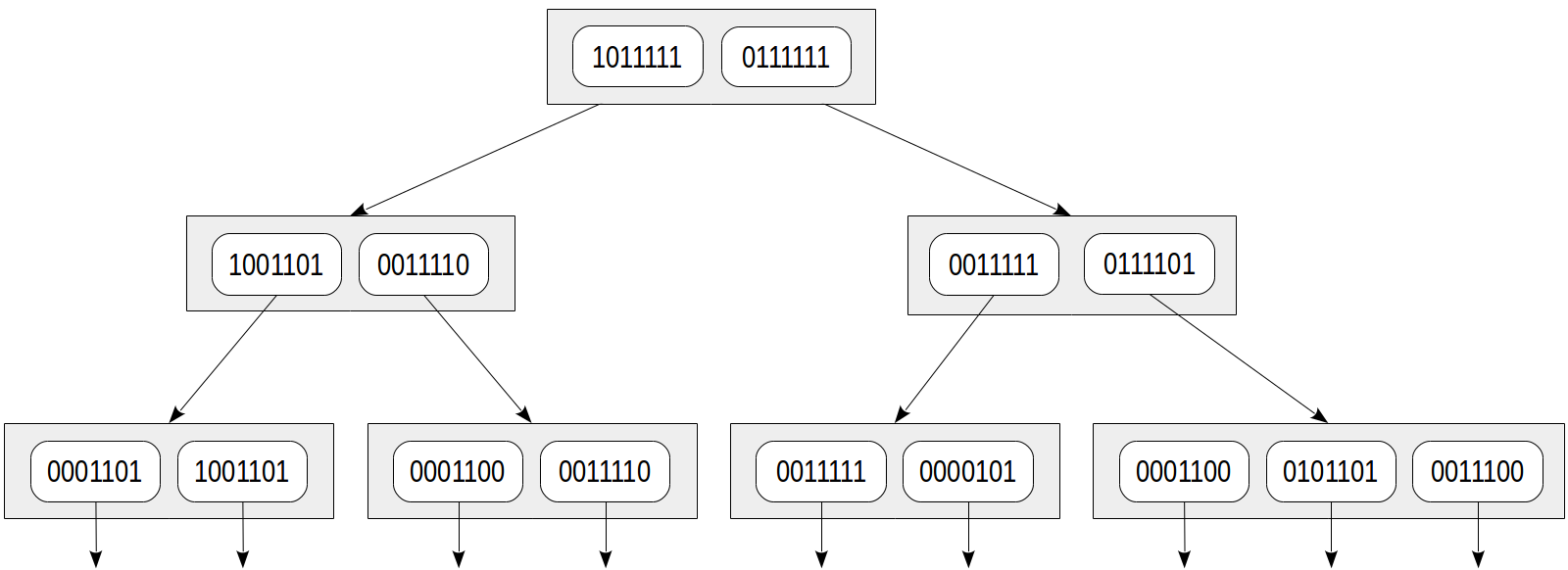
As vantagens dessa abordagem são evidentes: as linhas de índice têm tamanhos pequenos iguais e esse índice é compacto. Mas uma desvantagem também é clara: a precisão é sacrificada à compacidade.
Vamos considerar a mesma condição
doc_tsv @@ to_tsquery('sit') . E vamos calcular a assinatura da consulta de pesquisa da mesma maneira que no documento: 0010000, neste caso. A função de consistência deve retornar todos os nós filhos cujas assinaturas contêm pelo menos um bit da assinatura da consulta:

Compare com a figura acima: podemos ver que a árvore ficou amarela, o que significa que falsos positivos ocorrem e nós excessivos são percorridos durante a pesquisa. Aqui nós escolhemos "quem quer que seja" lexeme, cuja assinatura infelizmente era a mesma que a assinatura de "sit" lexeme. É importante que nenhum falso negativo possa ocorrer no padrão, ou seja, temos certeza de que não perderemos os valores necessários.
Além disso, pode acontecer que documentos diferentes também obtenham as mesmas assinaturas: em nosso exemplo, documentos azarados são "Eu corto uma folha, uma folha eu corto" e "Eu corto folhas" (ambos têm a assinatura 0001100). E se uma linha de índice folha não armazena o valor de "tsvector", o próprio índice fornecerá falsos positivos. Obviamente, nesse caso, o método solicitará que o mecanismo de indexação verifique novamente o resultado com a tabela, para que o usuário não veja esses falsos positivos. Mas a eficiência da pesquisa pode ficar comprometida.
Na verdade, uma assinatura tem 124 bytes de largura na implementação atual, em vez de 7 bits nas figuras, portanto, os problemas acima têm muito menos probabilidade de ocorrer do que no exemplo. Mas, na realidade, muito mais documentos são indexados também. Para reduzir de alguma forma o número de falsos positivos do método index, a implementação fica um pouco complicada: o "tsvector" indexado é armazenado em uma linha de índice folha, mas apenas se seu tamanho não for grande (um pouco menos de 1/16 de uma página, com cerca de meio kilobyte para páginas de 8 KB).
Exemplo
Para ver como a indexação funciona com dados reais, vamos usar o arquivo do email "pgsql-hackers".
A versão usada no exemplo contém 356125 mensagens com a data de envio, assunto, autor e texto:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------ id | 1572389 parent_id | 1562808 sent | 1997-06-24 11:31:09 subject | Re: [HACKERS] Array bug is still there.... author | "Thomas G. Lockhart" <Thomas.Lockhart@jpl.nasa.gov> body_plain | Andrew Martin wrote: + | > Just run the regression tests on 6.1 and as I suspected the array bug + | > is still there. The regression test passes because the expected output+ | > has been fixed to the *wrong* output. + | + | OK, I think I understand the current array behavior, which is apparently+ | different than the behavior for v1.0x. + ...
Adicionando e preenchendo a coluna do tipo "tsvector" e construindo o índice. Aqui, juntaremos três valores em um vetor (assunto, autor e texto da mensagem) para mostrar que o documento não precisa ser um campo, mas pode consistir em partes arbitrárias totalmente diferentes.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(subject||' '||author||' '||body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gist(tsv);
Como podemos ver, um certo número de palavras foi descartado devido ao tamanho muito grande. Mas o índice acabou sendo criado e pode suportar consultas de pesquisa:
fts=# explain (analyze, costs off) select * from mail_messages where tsv @@ to_tsquery('magic & value');
QUERY PLAN ---------------------------------------------------------- Index Scan using mail_messages_tsv_idx on mail_messages (actual time=0.998..416.335 rows=898 loops=1) Index Cond: (tsv @@ to_tsquery('magic & value'::text)) Rows Removed by Index Recheck: 7859 Planning time: 0.203 ms Execution time: 416.492 ms (5 rows)
Podemos ver que, juntamente com 898 linhas correspondentes à condição, o método de acesso retornou 7859 linhas a mais que foram filtradas ao verificar novamente a tabela. Isso demonstra um impacto negativo da perda de precisão na eficiência.
Internals
Para analisar o conteúdo do índice, usaremos novamente a extensão "gevel":
fts=# select level, a from gist_print('mail_messages_tsv_idx') as t(level int, valid bool, a gtsvector) where a is not null;
level | a -------+------------------------------- 1 | 992 true bits, 0 false bits 2 | 988 true bits, 4 false bits 3 | 573 true bits, 419 false bits 4 | 65 unique words 4 | 107 unique words 4 | 64 unique words 4 | 42 unique words ...
Valores do tipo especializado "gtsvector" que são armazenados nas linhas de índice são na verdade a assinatura mais, talvez, a fonte "tsvector". Se o vetor estiver disponível, a saída conterá o número de lexemas (palavras exclusivas), caso contrário, o número de bits verdadeiros e falsos na assinatura.
É claro que, no nó raiz, a assinatura degenerou para "todos", ou seja, um nível de índice tornou-se absolutamente inútil (e mais um tornou-se quase inútil, com apenas quatro bits falsos).
Propriedades
Vejamos as propriedades do método de acesso do GiST (as consultas
foram fornecidas anteriormente ):
amname | name | pg_indexam_has_property --------+---------------+------------------------- gist | can_order | f gist | can_unique | f gist | can_multi_col | t gist | can_exclude | t
A classificação de valores e a restrição exclusiva não são suportadas. Como vimos, o índice pode ser construído em várias colunas e usado em restrições de exclusão.
As seguintes propriedades da camada de índice estão disponíveis:
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | f
E as propriedades mais interessantes são as da camada da coluna. Algumas das propriedades são independentes das classes de operadores:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f search_array | f search_nulls | t
(A classificação não é suportada; o índice não pode ser usado para pesquisar uma matriz; NULLs são suportados.)
Mas as duas propriedades restantes, "distance_orderable" e "returnable", dependerão da classe de operador usada. Por exemplo, para pontos, obteremos:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | t returnable | t
A primeira propriedade informa que o operador de distância está disponível para busca dos vizinhos mais próximos. E o segundo diz que o índice pode ser usado para verificação apenas de índice. Embora as linhas de índice folha armazenem retângulos em vez de pontos, o método de acesso pode retornar o que é necessário.
A seguir estão as propriedades para intervalos:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | t
Para intervalos, a função de distância não é definida e, portanto, a pesquisa dos vizinhos mais próximos não é possível.
E para a pesquisa de texto completo, obtemos:
name | pg_index_column_has_property --------------------+------------------------------ distance_orderable | f returnable | f
O suporte à varredura apenas de índice foi perdido, pois as linhas folha podem conter apenas a assinatura sem os próprios dados. No entanto, essa é uma pequena perda, pois ninguém está interessado no valor do tipo "tsvector" de qualquer maneira: esse valor é usado para selecionar linhas, enquanto é o texto de origem que precisa ser mostrado, mas está ausente no índice.
Outros tipos de dados
Por fim, mencionaremos mais alguns tipos atualmente suportados pelo método de acesso GiST, além dos tipos geométricos já discutidos (por exemplo de pontos), intervalos e tipos de pesquisa de texto completo.
Dos tipos padrão, este é o tipo "
inet " para endereços IP. Todo o resto é adicionado através de extensões:
- cubo fornece o tipo de dados "cubo" para cubos multidimensionais. Para este tipo, assim como para os tipos geométricos em um plano, a classe de operador GiST é definida: R-tree, suportando a pesquisa dos vizinhos mais próximos.
- seg fornece o tipo de dados "seg" para intervalos com limites especificados com uma certa precisão e adiciona suporte ao índice GiST para esse tipo de dados (árvore R).
- O intarray estende a funcionalidade de matrizes inteiras e adiciona suporte ao GiST para elas. Duas classes de operadores são implementadas: "gist__int_ops" (árvore RD com uma representação completa das chaves nas linhas de índice) e "gist__bigint_ops" (árvore RD assinatura). A primeira classe pode ser usada para matrizes pequenas e a segunda - para tamanhos maiores.
- O ltree adiciona o tipo de dados "ltree" para estruturas semelhantes a árvores e o suporte do GiST para esse tipo de dados (RD-tree).
- O pg_trgm adiciona uma classe de operador especializada "gist_trgm_ops" para o uso de trigramas na pesquisa de texto completo. Mas isso deve ser discutido mais adiante, junto com o índice GIN.
Continue lendo .