Olá pessoal! Meu nome é Denis Girko, sou o arquiteto de sistemas da plataforma de comércio eletrônico em Lamoda. No ano passado, falei na conferência DevConf com um relatório que quero compartilhar com você.
Este é um relatório de revisão sobre as dificuldades que uma grande loja online encontra no processo de entrega de pedidos e quais soluções técnicas podem ajudar a superá-las (usando as soluções que testamos na Lamoda como exemplo).

Sobre o que será? Eu vou te dizer:
- Sobre o processo de entrega e identificar problemas;
- como armazenar efetivamente territórios de entrega no banco de dados;
- como melhorar a qualidade dos dados que recebemos do cliente;
- como pesquisar o destinatário no banco de dados de endereços para encontrar resultados mais precisos.
Esquema Geral de Entrega de Pedidos Lamoda
A Lamoda é uma loja on-line com quatro países para entrega: Rússia, Ucrânia, Cazaquistão e Bielorrússia. Entregamos mercadorias no dia seguinte devido ao fato de termos nosso próprio serviço de entrega e uma dúzia de parceiros terceirizados cujos serviços usamos. A entrega é uma grande parte do nosso negócio.
Lamoda aceita o pedido, solicita ao cliente o endereço no momento do registro e o passa para o serviço de correio.
E se não tivermos um serviço de correio, mas vários? Em seguida, é adicionado o próximo passo - para determinar qual serviço de entrega faremos o pedido.
Pode haver alguns critérios de seleção de negócios. Mas a primeira coisa a se pensar é se esse serviço de entrega tem entrega na cidade selecionada pelo cliente ou não. Portanto, o primeiro passo para integrar qualquer empresa de courier em nosso sistema é descobrir sua área de cobertura.
Em seguida, você precisa aprender como verificar se o endereço do cliente se enquadra nesse território ou não.
O esquema geral será aprimorado e terá a seguinte aparência:
- peça um endereço;
- descubra quais serviços de courier podem fornecê-lo;
- selecione o que você deseja dentre os disponíveis.
Agora um pouco mais sobre essas etapas.
Pedimos ao cliente o endereço
Como posso perguntar a ele?
- Peça para preencher um campo grande. O cliente martela em seu endereço, o que ainda não precisa de manipulações complicadas. O endereço pode ser impresso em um pedaço de papel, entregue ao correio a pé, que então o descobrirá.
- A segunda opção é mais complicada. Pedimos ao cliente que preencha cada componente do endereço em seu campo. Aqui você já pode fazer alguma coisa. Por exemplo, compare a cidade de Moscou com uma determinada lista de cidades. Mas funcionará mal, porque a cidade de Moscou pode ser escrita de várias maneiras: “g. Moscow ”,“ Moscow city ”,“ Moscow city ”sem espaço, e assim por diante.
- Portanto, há uma opção ainda mais avançada. Como a lista de cidades que temos é finita, você pode pré-compilar uma lista de cidades e sugerir que o cliente selecione a que ele precisa. O bônus é que, para cada elemento dessa lista, já podemos associar algum identificador aqui. Nós desenvolvedores adoramos trabalhar não com strings, mas com identificadores que podem ser usados em todos os nossos sistemas como o equivalente à cidade selecionada. Eu tenho um índice central dos correios no slide como um identificador.

Que serviço de entrega estamos transportando?
Como temos um identificador (índice), deixe o território armazenado em nosso banco de dados ser representado por uma lista de índices. Nesse caso, o algoritmo para verificar a entrada da cidade no território é muito simples. Então, vamos fazê-lo: colocaremos os territórios de entrega recebidos dos serviços de correio no banco de dados na forma de índices.
Os índices têm seus prós e contras. Eu digo antecipadamente que, no início, a Lamoda fez exatamente isso: o resultado da escolha de um cliente da cidade foi um índice e nossos índices foram armazenados no banco de dados. Por que um plus? Como eu disse, um índice é algo que todos entendem. Qualquer gerente que acabou de trabalhar sabe o que é um índice. Ele pode receber da empresa de courier da cidade, de alguma forma convertê-los em índices e usá-los. A desvantagem é que o índice é o identificador dos correios dos correios russos. E os assentamentos próximos podem compartilhar o mesmo índice.
Por que os índices estão ausentes?
Um exemplo simples: Lyubertsy. Perto é a vila de Marusino. Marusino não tem uma agência postal, a correspondência chega a uma das agências postais de Lyubertsy. Se quiséssemos adicionar entrega ao Lyubertsy, mas não entregar ao Marusino, porque pode não ser financeiramente lucrativo para nós, não poderíamos fazer isso apenas por índice.
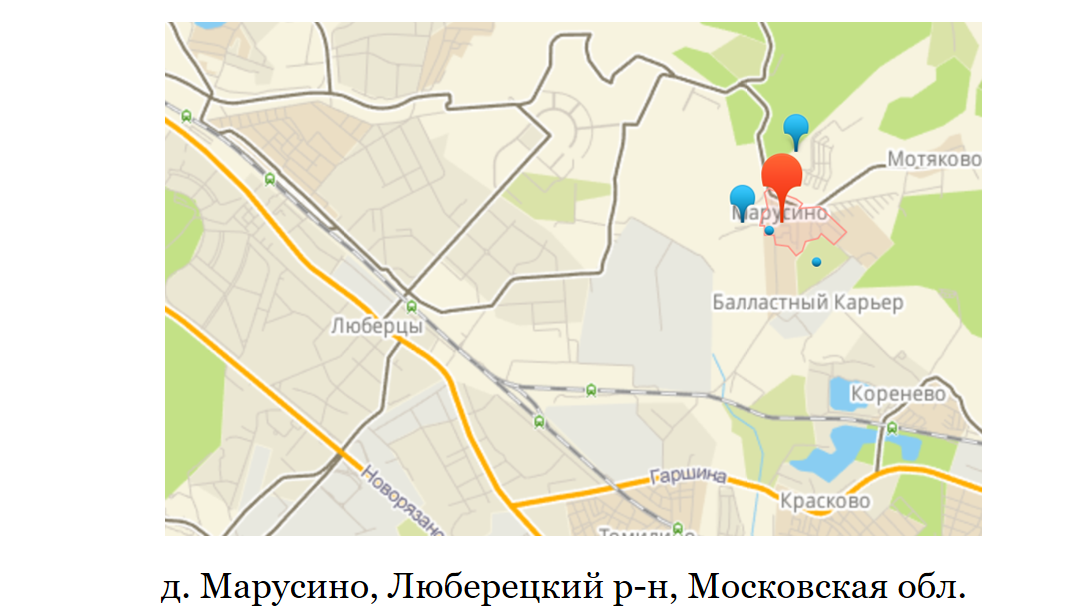
Outro exemplo é quando Lamoda expandiu e abriu um segundo armazém de transporte em Moscou. Era necessário dividir Moscou nas partes norte e sul. E já na hora de fazer o pedido, entenda em qual armazém de trânsito a entrega será realizada. Nesse caso, um índice por cidade não seria suficiente.
Decidimos usar coordenadas geográficas juntamente com índices. Pegamos o endereço do cliente, executamos no geocoder Yandex . Na saída, obtemos não apenas o índice, mas também as coordenadas. Usamos índices nos casos em que os detalhes não são importantes. E as coordenadas especificam esses casos quando você precisa fazer uma divisão fina do território.
Eles forneceram uma interface em seu programa de configuração para logísticos, que permite desenhar um polígono no topo do mapa. É simples: o ponto cai no aterro - há entrega, não cai - não.
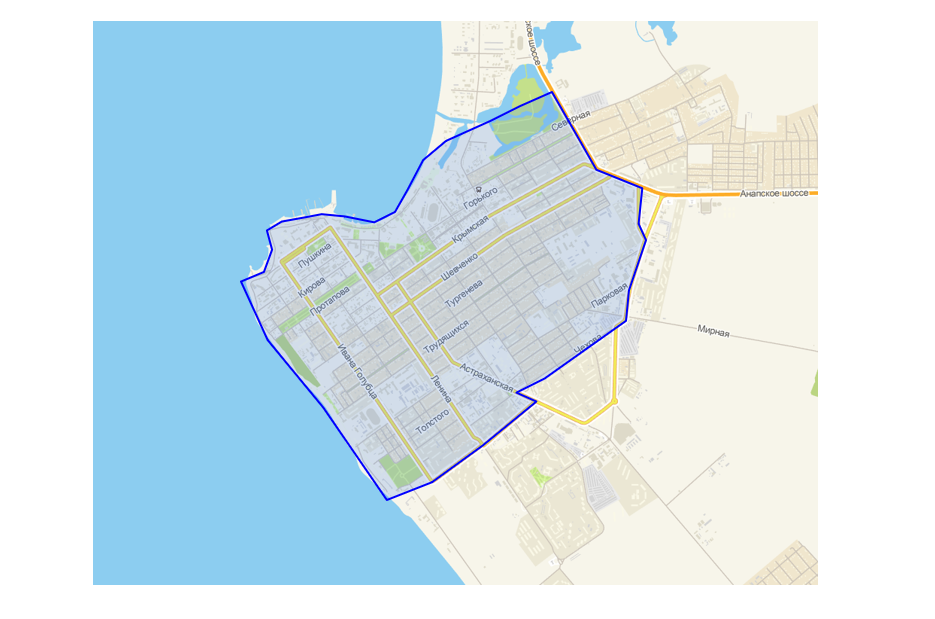
Interface de criação de zona de polígono
O bônus que temos coordenadas geográficas para cada pedido foi a oportunidade de melhorar a interface que os logísticos usam para fazer rotas para os representantes de vendas. A interface exibe um mapa no qual os pedidos dos clientes são marcados. O logístico usa a ferramenta laço, que combina as ordens adjacentes em uma rota. Além disso, essa rota vai para um representante de vendas, ou seja, uma pessoa não precisa ir de um extremo da cidade para o outro extremo durante o dia para receber todos os seus pedidos - todos eles estão geograficamente próximos.
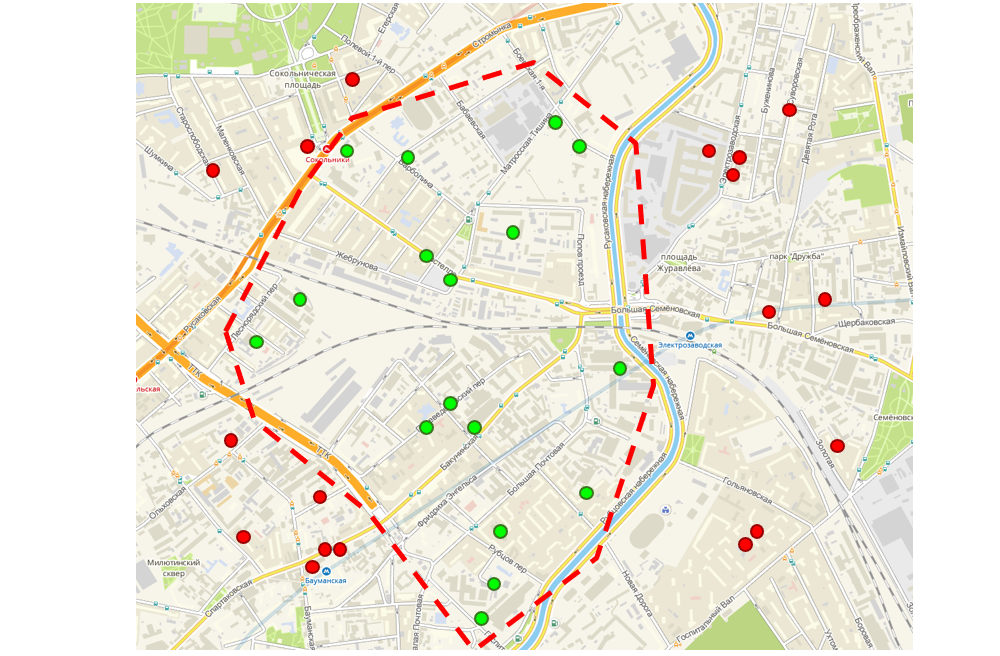
Interface de roteamento
O endereço digitado pelo cliente é convertido em coordenadas. A probabilidade de obtermos as coordenadas para um determinado endereço depende diretamente da qualidade do endereço digitado pelo cliente. Portanto, a primeira coisa que pensamos é em como aumentar o número de endereços bem reconhecidos. Portanto, você precisa ajudar o cliente a inserir o endereço correto.
O fato é que os clientes geralmente não seguem os cenários que fornecemos para eles; portanto, adquirimos bancos de dados de endereços para cada um dos quatro países para os quais entregamos pedidos. E fizeram uma festa, não só para a cidade, mas também para a rua e até para o número da casa. Para fazer uma lista de casas, analisamos os dados abertos do openstreetmap.org .
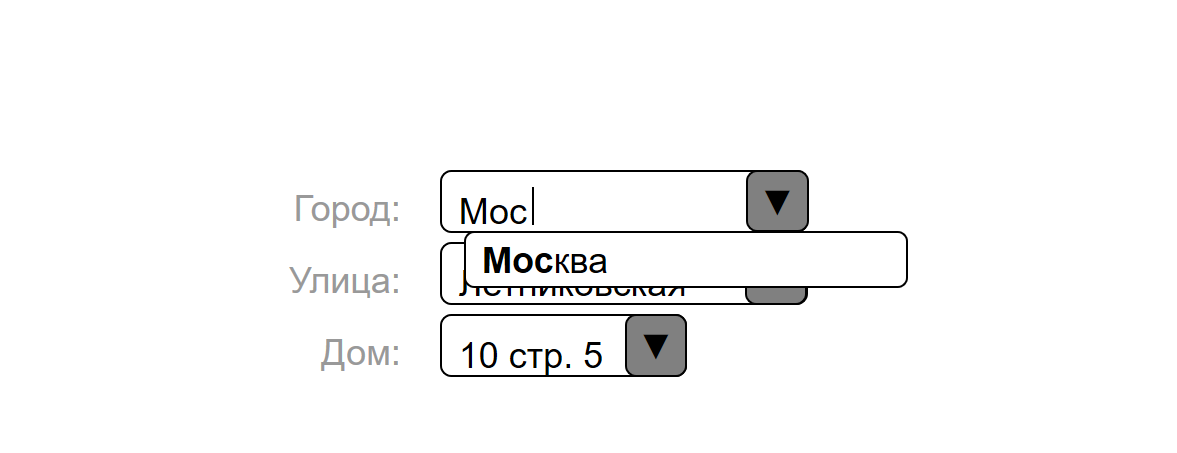
O formulário de checkout oferece dicas para formalizar dados de endereço
Base de endereço
Para fazer uma sujest na base de endereço, você precisa mantê-la em casa. Onde conseguimos todas as bases de endereços para nossos quatro países? Na Rússia, é o FIAS , a base de endereços que é compilada e mantida por nosso serviço de impostos. É bastante completo, embora não sem falhas. Nossos parceiros de entrega nos ajudaram com outros países.

Também temos um conjunto de scripts PHP que assumem o formato com o qual a base de endereços chega até nós e da mesma maneira que a adiciona ao PostgreSQL . Por que da mesma forma? Porque uma das tarefas é atualizar periodicamente esses bancos de dados das mesmas fontes. Isso significa que, se fornecêssemos a conversão, ela teria que ser repetida a cada atualização.Portanto, os dados vão para o PostgreSQL e, a partir daí, são convertidos e armazenados no Apache Solr ; O Solr permite procurar rapidamente por eles e fazer sajest. Um pequeno servidor web PHP é capaz de criar solicitações no Solr, de acordo com os resultados, uma lista é criada para o cliente no site para o sujest.
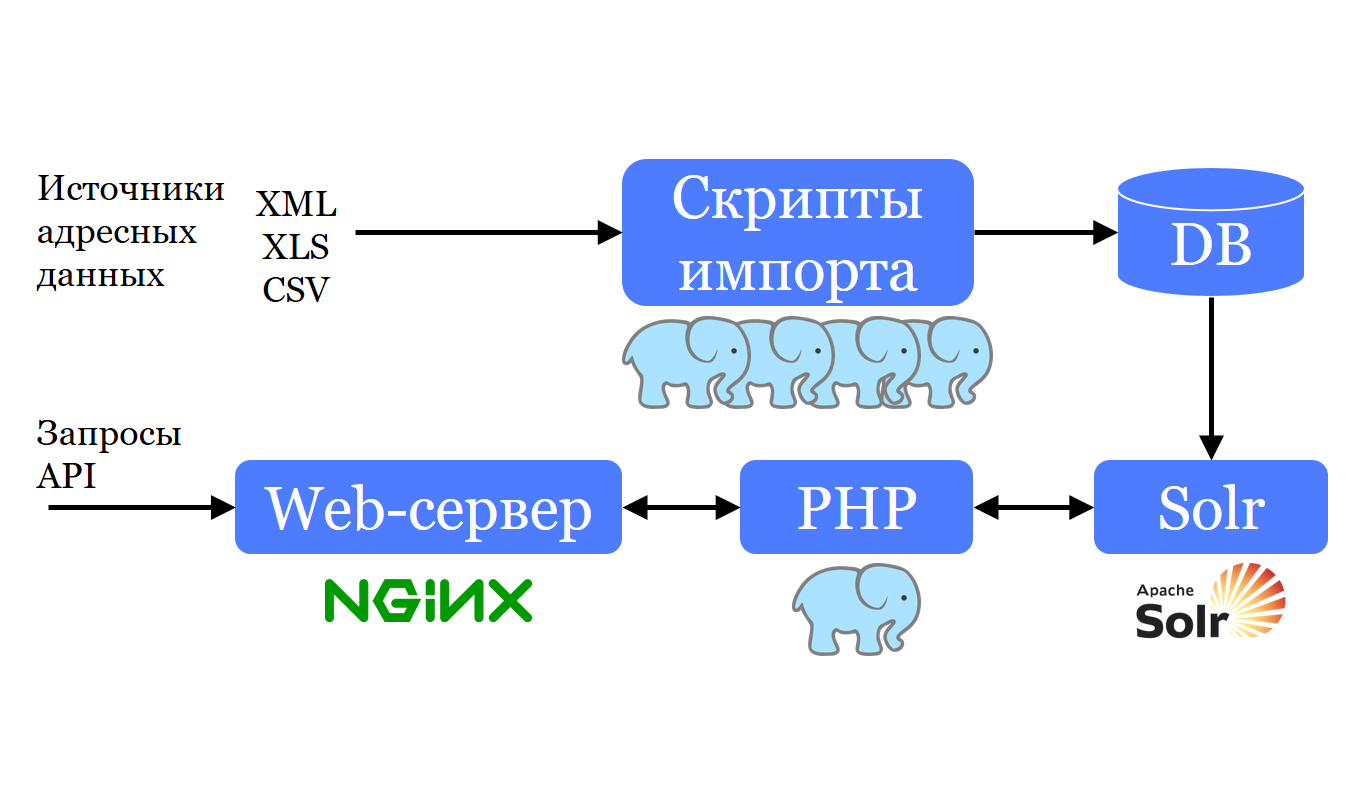
Fazemos o download de dados da fonte aproximadamente da mesma forma em que eles chegaram até nós. Ou seja, com o mesmo conjunto de campos, com os mesmos tipos de colunas e assim por diante. Adicione-os como estão. Tentamos usar os dados neste formulário desde o início e, para transformá-los nas estruturas com as quais podemos trabalhar, escrevemos várias visualizações. Como temos 4 países, tudo isso foi multiplicado por 4, e foi muito difícil e caro apoiar. Portanto, era necessário fazer algo a respeito.
A primeira coisa de que nos livramos é a estrutura não estruturada, ou melhor, a estrutura específica , em um estágio inicial. Ou seja, assim que os dados brutos são carregados, com a ajuda de visualizações, os transformamos em um formato unificado, com o qual todas as outras transformações são configuradas. Isso nos impediu de multiplicar por 4. E é nesse momento que esquecemos a estrutura em que os dados chegaram até nós e trabalhamos apenas com o que inventamos para nós mesmos.
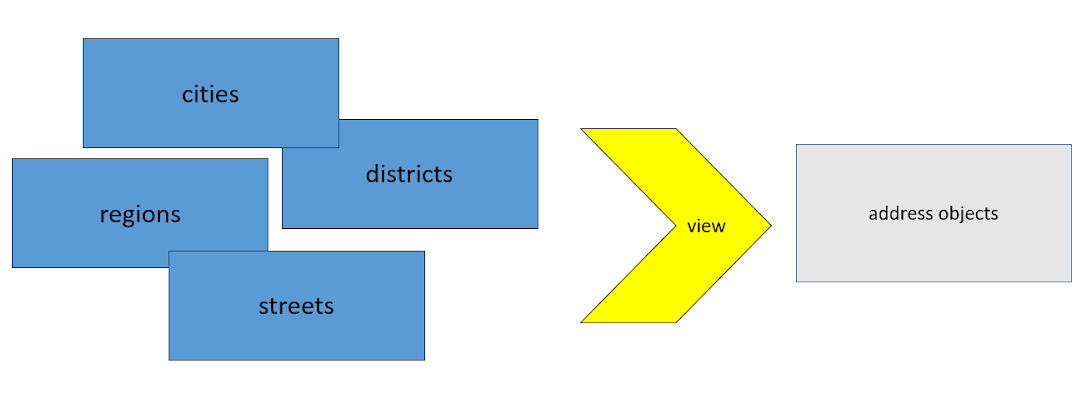
Se você precisar de duas fontes - faça o download. O principal é que o formato dessa saída de dados após a conversão em visualizações seja o mesmo.
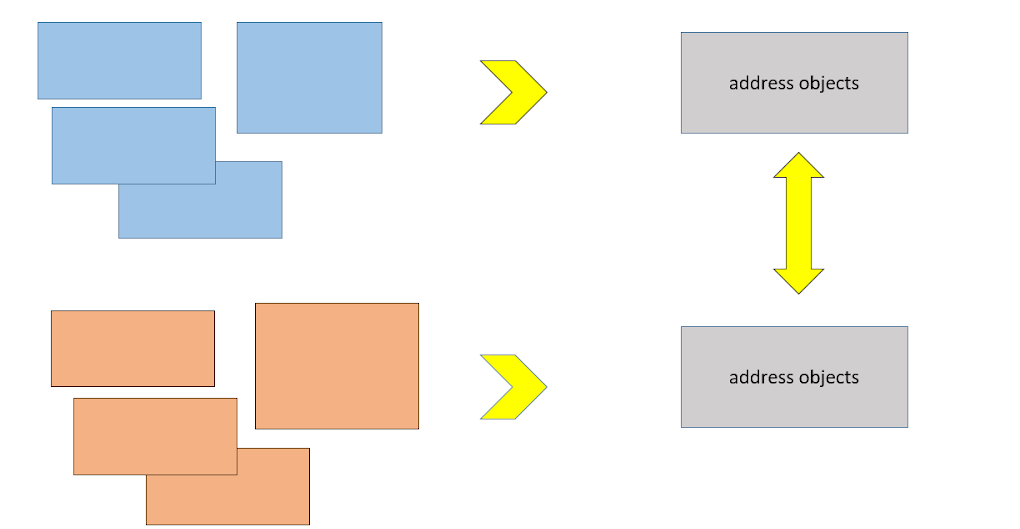
Outro requisito para bancos de dados de endereços carregados era que era necessário fazer correções de pontos. Um exemplo simples: no FIAS, a República Chuvash é chamada "Rep Chuvash. "Chuvashia." Bem, queremos apenas a República Chuvash. Por que precisamos desse traço? E, ao mesmo tempo, ainda não podemos evitar atualizações periódicas de fontes.
Aqui estão as seguintes camadas que temos no PostgreSQL.

As tabelas à esquerda são dados brutos baixados da fonte.
Atrás deles, exibições que convertem dados em um formato padrão.
Substituições locais são nosso conjunto de tabelas que redefinem apontadormente alguns atributos dos dados de endereço carregados. Incluímos aqui, por exemplo, que um registro com esse identificador deve receber em vez de “Chuvash rep. - Chuvashia ”é o nosso nome escolhido.
A tabela Mapeamento é o nosso repositório de identificadores, que nós mesmos atribuímos aos objetos de endereço que baixamos - isso nos permitiu abstrair nossos sistemas da fonte, daqueles identificadores usados na fonte e também ocultar não uma fonte, mas até várias - sob um ID. Vou contar um pouco mais tarde. Tudo isso junto é combinado e corrigido em uma visão materializada. Assim, obtemos quase o equivalente da tabela final, que pode ser atualizada executando um comando SQL REFRESH MATERIALIZED VIEW .
Objetos de endereço - base de endereços formada com todas as correções e adições.
Portanto, na saída já corrigimos os objetos de endereço, já com novos nomes e nossos identificadores. Tudo isso é transformado e desnormalizado, conveniente para pesquisar e adicionado ao Solr.
Como agora temos bancos de dados de endereços, seria legal usá-los não apenas para solicitar o formulário de pedido, mas também para fazer uma pesquisa. Onde uma pesquisa pode ser útil? Acontece muito onde. As mesmas áreas de entrega que recebemos dos serviços de courier são muitas vezes representadas simplesmente por uma lista de cidades. E a lista de cidades está repleta dos mesmos problemas da entrada do usuário: as cidades podem ter interpretações diferentes, nomes diferentes e muito mais.
Eu tenho um slide especial aqui, uma história de horror - o que teríamos que fazer se pegássemos tudo manualmente para convertê-lo em PHP: isto é, Chechênia, República da Chechênia e assim por todas as fontes de dados - o inferno é um inferno.

Adição: na tela - um código real do serviço, que se tornou desnecessário apenas por causa das soluções descritas.
Classificamos esses problemas.
1) Nomes equivalentes dos mesmos objetos. Por exemplo, sinônimos comuns como Chuvashia e República Chuvash.
2) Cidades renomeadas. A Ucrânia está agora na fase ativa de se livrar do passado comunista, e é por isso que literalmente todos os dias fazem mudanças nos nomes de seus assentamentos. Por esse motivo, pode acontecer que em um banco de dados tenhamos nomes antigos e em outro - novos.
3) Muitos erros. Muitas vezes confundido com o status dos assentamentos. Há uma vila, aqui é uma vila ou aqui é uma vila, há uma fazenda.
4) Palavras estrangeiras transliteradas para o russo, geralmente o mesmo nome é transliterado de maneiras diferentes.
5) Existem muitos erros na hierarquia: Zelenograd, por hábito, pertence à região de Moscou, embora formalmente também esteja listado em Moscou como FIAS. Escreva corretamente "Cidade de Moscou, Zelenograd".
Como chegamos a isso?
A primeira coisa que fazemos é separar todos os componentes insignificantes do endereço dos nomes. Nós não os jogamos fora, eles participam da pesquisa, mas separadamente das partes significativas.
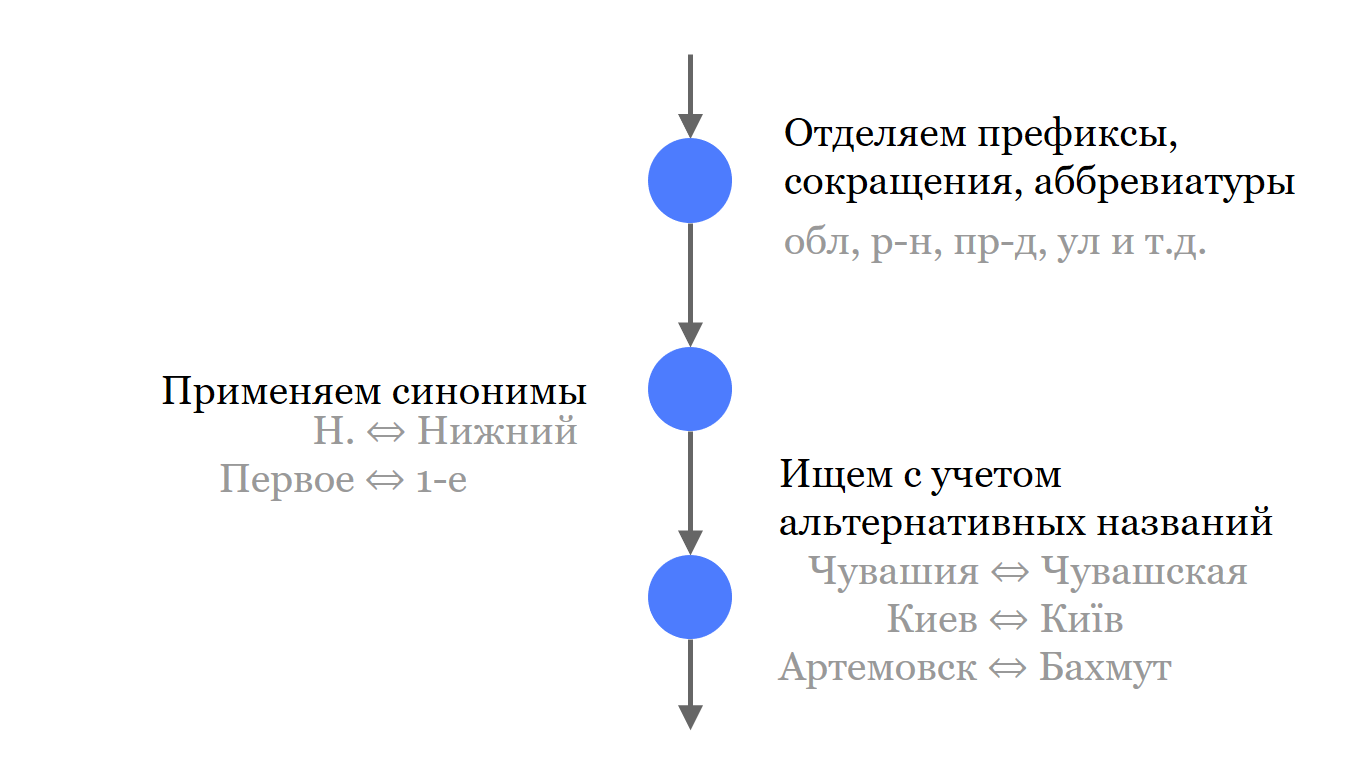
Em seguida, fizemos uma pequena lista de sinônimos e abreviações comuns usados nos nomes. Onde a fonte permitia, carregamos e colocamos todos os nomes no Solr. Não apenas os sinônimos mais relevantes, mas também possíveis sinônimos e nomes históricos.
Para pesquisar melhor, jogamos fora todas as letras que podem apresentar discrepâncias. Isso se aplica ao idioma russo e aos idiomas com os quais ainda temos que lidar.
Corrigimos erros de digitação e corrigimos o layout.
Finalmente, criamos pais fantasmas - esses são pais atribuídos a objetos. Eles são relevantes na pesquisa, mas não participam do resultado da pesquisa. Por exemplo, para Zelenograd, adicionamos a região de Moscou. Agora você pode procurar por "Moscow Region, Zelenograd" e encontrar o objeto de que precisamos, mas nos resultados da pesquisa ainda será o "Moscow, Zelenograd" correto.
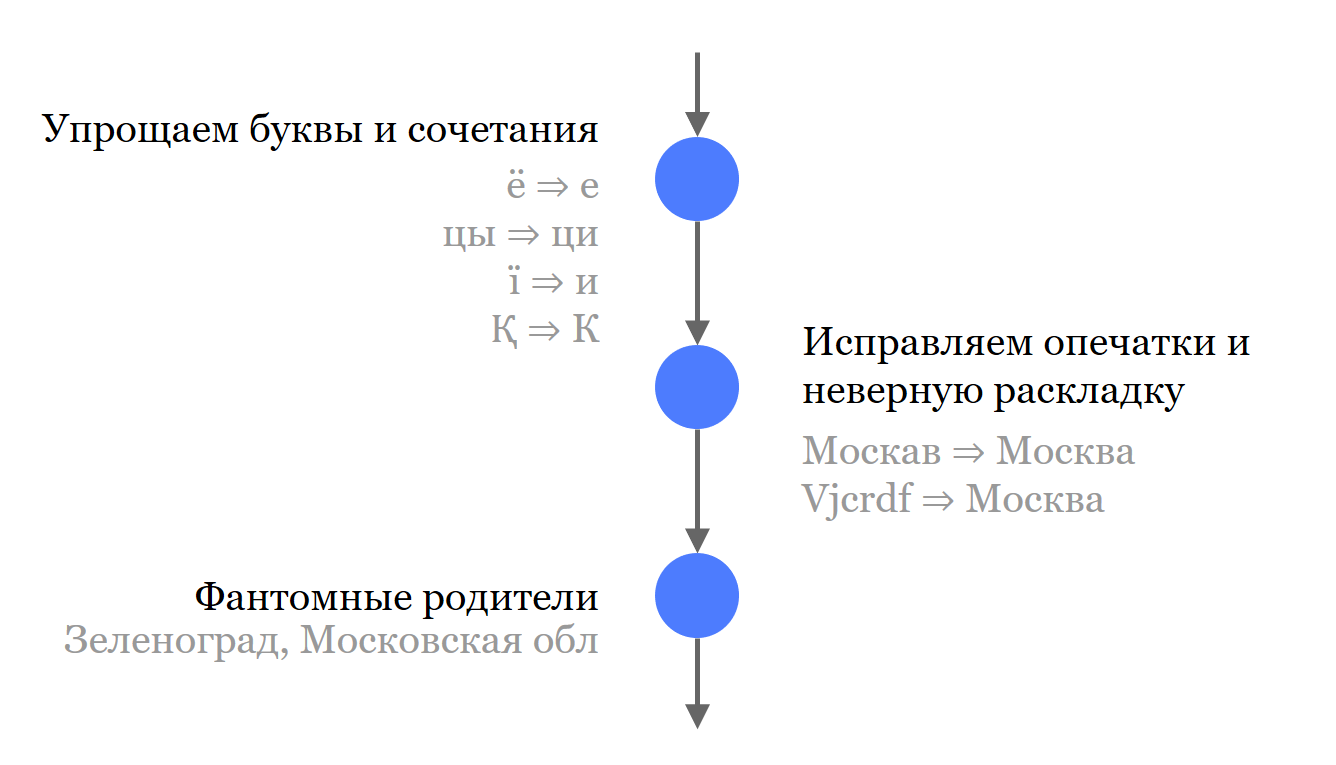
Dependendo dos requisitos de negócios, é necessária uma gradação diferente da precisão da pesquisa. Portanto, temos 4 graus, cada um deles dá um resultado com maior probabilidade, mas com uma menor probabilidade, será exatamente o resultado que se deseja.

E onde encontramos esse aplicativo de pesquisa?
- Mais uma vez, executamos o endereço digitado pelo cliente por meio dessa pesquisa. Se ele não usou nossas dicas na página de checkout, temos mais uma chance de transformar as linhas que ele inseriu em identificadores. Temos um endereço formalizado.
- Executamos essa pesquisa em tudo o que os serviços de correio nos enviam - reconhecemos as cidades que eles nos transmitem. Isso nos permitiu lançar apenas 10 peças por dia, o que é relevante para o B2B - a Lamoda fornece sua entrega a empresas terceirizadas, portanto há muitos novos serviços de correio conectados por unidade de tempo.
- Isso nos permitiu “encadear” várias informações úteis em nossos identificadores nos bancos de dados de endereços. Por exemplo, baixamos fusos horários, endereços IP, para procurar cidades pelos endereços IP dos clientes.
- Agora temos a oportunidade de ocultar a base de endereços combinada de duas fontes com um de nossos identificadores. Ou seja, permitiu evitar duplicatas e combinar os mesmos objetos de endereço nas duas bases.
Nós não paramos. Este é um processo que ainda podemos melhorar.
Em primeiro lugar, Lamoda trabalha em índices. Ou seja, nossos identificadores são índices, dos quais sabemos os menos. Quase todos os nossos sistemas mudaram para a nova API; eles operam não com índices, mas com os mesmos identificadores que nós mesmos atribuímos aos nossos objetos de endereço. A vantagem é que a verificação de uma cidade no território é tão simples quanto nos índices. No entanto, não há menos no fato de que vários assentamentos podem se esconder atrás de um ID.
Além disso: o tempo passou desde o momento do meu discurso, e agora estou feliz em me corrigir: nossos índices agora permanecem apenas no caso, quando o correio nos dá seu território na forma de uma lista deles, por exemplo, Russian Post. Em outros casos, os índices foram suplantados por nossos identificadores de endereço interno.
No slide, há uma parte da interface que permite configurar manualmente o território, mas, na verdade, tudo é configurado a partir de listas carregadas em lote de objetos de endereço na forma de seqüências de caracteres.

Baixamos as coordenadas geográficas do openstreetmap.org para residências. Agora, em uma grande porcentagem de casos, não precisamos ir a um serviço externo para descobrir o local. Isso nos reduziu 10 vezes a viagens para Yandex, que naturalmente economizavam dinheiro.
Nós nos livramos do PHP na cadeia de pesquisa de dados de endereço. Reescrevemos o código que acessou o Solr em Lua. Substituído nginx pelo Openresty , agora tudo é muito rápido e pode suportar cargas pesadas. 95% das respostas de nosso serviço de pesquisa cabem em 10 milissegundos, o que é mais do que suficiente para nós.

Além disso: o uso do Openresty e Lua, que atraiu seu desempenho, foi um tipo de experiência que valeu a pena: o serviço funciona rapidamente, é estável sob carga e é facilmente mantido. Mas desde então, Lamoda adotou Golang, que tem as mesmas qualidades, como uma das linguagens de programação para o back-end carregado. Se a decisão de desenvolver o serviço fosse tomada agora, nós o preferiríamos.
Conclusão
Minha moral pessoal de todo o trabalho realizado é que os dados de endereço são uma área em que você não pode esperar a qualidade ideal dos dados. Isso nunca vai acontecer. Nunca receberemos dados perfeitos de um cliente ou de fontes externas. Portanto, você precisa extrair o máximo do que é.