 O ProxylessNAS otimiza diretamente a arquitetura das redes neurais para uma tarefa e equipamento específicos, o que pode aumentar significativamente a produtividade em comparação com as abordagens de proxy anteriores. Em um conjunto de dados ImageNet, uma rede neural é projetada em 200 horas de GPU (200 a 378 vezes mais rápida que suas contrapartes) e o modelo CNN projetado automaticamente para dispositivos móveis atinge o mesmo nível de precisão que o MobileNetV2 1.4, trabalhando 1,8 vezes mais rápido.
O ProxylessNAS otimiza diretamente a arquitetura das redes neurais para uma tarefa e equipamento específicos, o que pode aumentar significativamente a produtividade em comparação com as abordagens de proxy anteriores. Em um conjunto de dados ImageNet, uma rede neural é projetada em 200 horas de GPU (200 a 378 vezes mais rápida que suas contrapartes) e o modelo CNN projetado automaticamente para dispositivos móveis atinge o mesmo nível de precisão que o MobileNetV2 1.4, trabalhando 1,8 vezes mais rápido.Pesquisadores do Instituto de Tecnologia de Massachusetts desenvolveram um algoritmo eficiente para o design automático de redes neurais de alto desempenho para hardware específico,
escreve a publicação
MIT News .
Algoritmos para o design automático de sistemas de aprendizado de máquina são um novo campo de pesquisa no campo da IA. Essa técnica é chamada de busca na arquitetura neural (NAS) e é considerada uma tarefa computacional difícil.
As redes neurais projetadas automaticamente têm um design mais preciso e eficiente do que as desenvolvidas por seres humanos. Mas a busca pela arquitetura neural requer cálculos realmente enormes. Por exemplo, o moderno algoritmo NASNet-F, desenvolvido recentemente pelo Google para rodar em GPUs, leva 48.000 horas de computação em GPU para criar uma rede neural convolucional, usada para classificar e detectar imagens. Obviamente, o Google pode executar centenas de GPUs e outros hardwares especializados em paralelo. Por exemplo, em mil GPUs, esse cálculo leva apenas dois dias. Mas nem todos os pesquisadores têm essas oportunidades e, se você executar o algoritmo na nuvem de computação do Google, ele poderá ganhar um centavo.
Os pesquisadores do MIT prepararam um artigo para a Conferência Internacional sobre Representações de Aprendizagem,
ICLR 2019 , que será realizada de 6 a 9 de maio de 2019. O artigo
ProxylessNAS: pesquisa direta da arquitetura neural na tarefa e hardware de destino descreve o algoritmo ProxylessNAS que pode desenvolver diretamente redes neurais convolucionais especializadas para plataformas de hardware específicas.
Quando executado em um conjunto massivo de dados de imagem, o algoritmo projetou a arquitetura ideal em apenas 200 horas de operação da GPU. São duas ordens de magnitude mais rápidas que o desenvolvimento da arquitetura da CNN usando outros algoritmos (consulte a tabela).
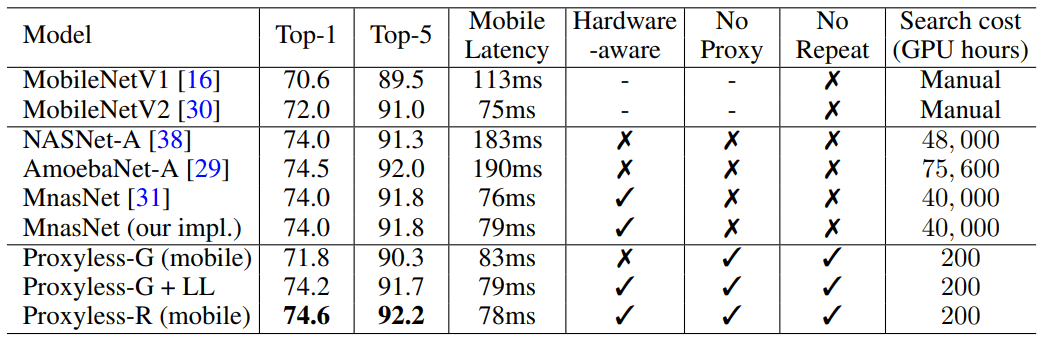
Pesquisadores e empresas com recursos limitados serão beneficiados pelo algoritmo. Um objetivo mais geral é "democratizar a IA", diz o co-autor da ciência Song Han, professor associado de engenharia elétrica e ciência da computação nos Laboratórios de Tecnologia de Microsistemas do MIT.
Khan acrescentou que esses algoritmos NAS nunca substituirão o trabalho intelectual dos engenheiros: "O objetivo é descarregar o trabalho repetitivo e tedioso que vem com o design e o aprimoramento da arquitetura das redes neurais".
Em seu trabalho, os pesquisadores descobriram maneiras de remover componentes desnecessários de uma rede neural, reduzir o tempo computacional e usar apenas parte da memória do hardware para executar o algoritmo NAS. Isso garante que a CNN desenvolvida funcione com mais eficiência em plataformas de hardware específicas: CPU, GPU e dispositivos móveis.
A arquitetura da CNN consiste em camadas com parâmetros ajustáveis chamados "filtros" e possíveis relacionamentos entre eles. Os filtros processam pixels da imagem em grades quadradas - como 3 × 3, 5 × 5 ou 7 × 7 - onde cada filtro cobre um quadrado. De fato, os filtros se movem pela imagem e combinam as cores da grade de pixels em um pixel. Em diferentes camadas, os filtros são de tamanhos diferentes, conectados de maneiras diferentes para a troca de dados. A saída CNN produz uma imagem compactada combinada de todos os filtros. Como o número de arquiteturas possíveis - o chamado "espaço de pesquisa" - é muito grande, o uso do NAS para criar uma rede neural em conjuntos maciços de dados de imagem requer enormes recursos. Normalmente, os desenvolvedores executam o NAS em conjuntos de dados menores (proxies) e transferem as arquiteturas CNN resultantes para o destino. No entanto, esse método reduz a precisão do modelo. Além disso, a mesma arquitetura se aplica a todas as plataformas de hardware, resultando em problemas de desempenho.
Os pesquisadores do MIT treinaram e testaram o novo algoritmo na tarefa de classificar imagens diretamente no conjunto de dados ImageNet, que contém milhões de imagens em mil classes. Primeiro, eles criaram um espaço de pesquisa que contém todos os “caminhos” possíveis para os candidatos da CNN, para que o algoritmo encontre a arquitetura ideal entre eles. Para ajustar o espaço de pesquisa na memória da GPU, eles usaram um método chamado binarização em nível de caminho, que salva apenas um caminho por vez e economiza memória por uma ordem de magnitude. A binarização é combinada com a poda no nível do caminho, um método que tradicionalmente estuda quais neurônios em uma rede neural podem ser removidos com segurança sem danificar o sistema. Somente em vez de remover neurônios, o algoritmo NAS remove caminhos inteiros, alterando completamente a arquitetura.
No final, o algoritmo elimina todos os caminhos improváveis e salva apenas o caminho com maior probabilidade - essa é a arquitetura CNN final.
A ilustração mostra exemplos de redes neurais para classificar imagens que o ProxylessNAS desenvolveu para GPUs, CPUs e processadores móveis (de cima para baixo, respectivamente).
