
As melhorias na velocidade da CPU estão diminuindo e estamos vendo a indústria de semicondutores mudar para placas aceleradoras, para que os resultados continuem melhorando bastante. A Nvidia se beneficiou mais dessa transição, no entanto, faz parte da mesma tendência, alimentando pesquisas sobre aceleradores de redes neurais, FPGAs e produtos como as TPUs do Google. Esses aceleradores aumentaram incrivelmente a velocidade da eletrônica nos últimos anos, e muitos começaram a esperar que representassem um novo caminho de desenvolvimento, em conexão com a desaceleração da lei de Moore. Mas um novo trabalho científico sugere que, de fato, tudo não é tão otimista quanto alguns gostariam.
Arquiteturas especiais, como GPUs, TPUs, FPGAs e ASICs, mesmo que funcionem de maneira bastante diferente das CPUs de uso geral, ainda usam os mesmos nós funcionais dos processadores x86, ARM ou POWER. E isso significa que o aumento da velocidade desses aceleradores também depende, até certo ponto, das melhorias associadas ao dimensionamento dos transistores. Mas que proporção dessas melhorias dependia da melhoria das tecnologias de produção e do aumento da densidade associada à lei de Moore e qual parte das melhorias nas áreas de destino para as quais esses processadores são destinados? Qual porcentagem de melhorias está relacionada apenas aos transistores?
O professor associado de engenharia elétrica da Universidade de Princeton, David Wenzlaf, e seu aluno de pós-graduação Adi Fuchs criaram um modelo que permite medir a velocidade da melhoria. Seu modelo usa as características de 1612 CPUs e 1001 GPUs de várias capacidades, feitas com base em várias unidades funcionais, para avaliar numericamente os benefícios associados às melhorias nas unidades. Wenzlaf e Fuchs criaram uma
métrica para melhorar o desempenho relacionado ao progresso do CMOS (retorno CMOS-Driven, CDR), que pode ser comparado às melhorias adquiridas através do retorno de especialização em chip (CSR).
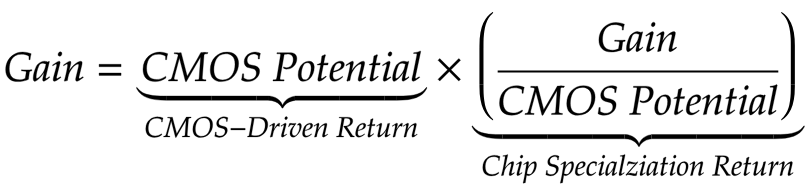
A equipe chegou a uma conclusão desanimadora. As vantagens obtidas devido à especialização de chips estão fundamentalmente relacionadas ao número de transistores colocados em um milímetro de silício a longo prazo, bem como às melhorias desses transistores associados a cada nova unidade funcional. Pior, existem limitações fundamentais em quanta velocidade podemos extrair da melhoria do circuito do acelerador sem melhorar a escala do CMOS.
É importante que todos os itens acima se apliquem a longo prazo. Um estudo de Wenzlaf e Fuchs mostra que a velocidade geralmente aumenta drasticamente quando os aceleradores são comissionados pela primeira vez. Com o tempo, quando métodos ótimos de aceleração acabam sendo estudados e as melhores práticas descritas, os pesquisadores chegam à abordagem mais ideal. Além disso, em aceleradores, tarefas bem definidas de uma área bem estudada que pode ser paralelizada (GPU) são bem resolvidas. No entanto, isso também significa que as mesmas propriedades, devido às quais a tarefa pode ser adaptada para aceleradores, limitam a vantagem obtida com essa aceleração a longo prazo. A equipe chamou esse problema de "acelerador de impasse".
E o mercado de computação de alto desempenho provavelmente já sente isso há algum tempo. Em 2013, escrevemos sobre o
difícil caminho para a expansão de supercomputadores. E mesmo assim, o Top500 previu que os aceleradores dariam um salto único nas classificações de desempenho, mas não aumentariam a velocidade do aumento de velocidade.

No entanto, as consequências dessas descobertas vão além do mercado de computação de alto desempenho. Por exemplo, tendo estudado a GPU, Wenzlaf e Fuchs descobriram que os benefícios que não podiam ser atribuídos à melhoria do CMOS eram muito pequenos.
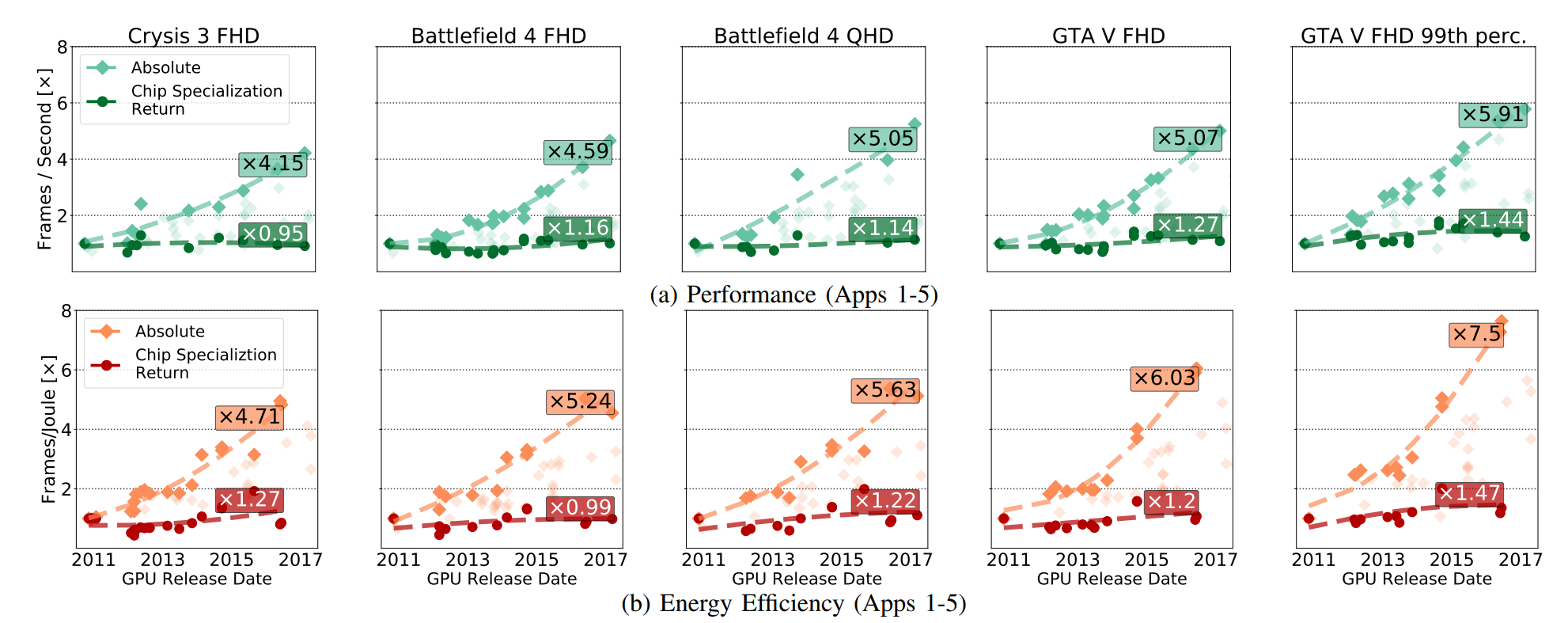
Na fig. Foi demonstrado um crescimento absoluto do desempenho da GPU (incluindo os benefícios obtidos com o desenvolvimento do CMOS), e esses benefícios surgiram apenas do desenvolvimento da RSE. Os CSRs tratam dessas melhorias que permanecem se você remover todas as inovações na tecnologia CMOS do circuito da GPU.
A figura a seguir esclarece a relação de quantidades:
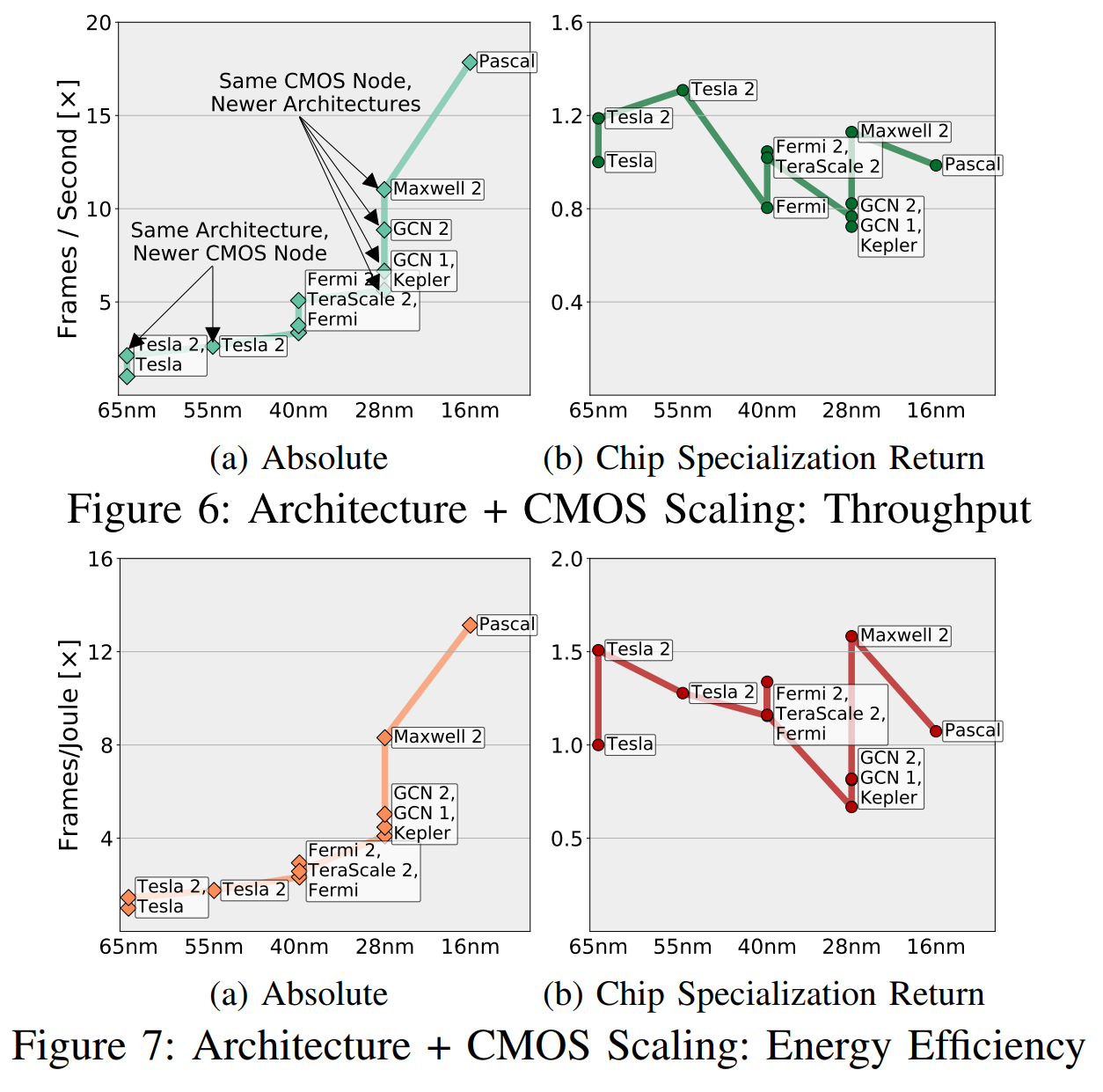
Diminuir a RSE não significa diminuir a GPU em números absolutos. Como Fuchs escreveu:
O CSR normaliza o lucro "com base no potencial do CMOS", e esse "potencial" leva em consideração o número de transistores e a diferença de velocidade, eficiência no uso de energia, área etc. (em diferentes gerações do CMOS). Na fig. 6, fizemos uma comparação aproximada das combinações “arquitetura + nós CMOS”, triangulando as velocidades medidas de todos os aplicativos em diferentes combinações e usando relacionamentos transitivos entre essas combinações que não possuem aplicativos comuns suficientes (menos de cinco).
Intuitivamente, esses gráficos podem ser entendidos como na Fig. 6a mostra o que "engenheiros e gerentes veem" e fig. 6b é "o que vemos, excluindo o potencial do CMOS". Atrevo-me a sugerir que você está mais preocupado em saber se o seu novo chip está à frente do anterior, se não por causa de melhores transistores ou por uma melhor especialização.
O mercado de GPU é bem definido, projetado e especializado, e a AMD e a Nvidia têm todos os motivos para se antecipar, melhorando os circuitos. Mas, apesar disso, vemos que, na maioria das vezes, as acelerações são devidas a fatores relacionados ao CMOS, e não ao CSR.
Os FPGAs e as placas especiais para processamento de codecs de vídeo, estudados por cientistas, também se enquadram nessas características, mesmo que a melhoria relativa ao longo do tempo se torne mais ou menos devido ao crescente mercado. As mesmas características que permitem responder ativamente à aceleração limitam a capacidade dos aceleradores de melhorar sua eficiência. Fuchs e Wenzlaf escrevem sobre a GPU: "Embora a taxa de quadros dos gráficos da GPU tenha aumentado em 16 vezes, presumimos que outras melhorias na velocidade e na eficiência de energia serão 1,4 a 2,4 e 1,4 a 1,7 vezes, respectivamente" . A AMD e a Nvidia não têm um espaço especial para manobras, no qual você pode aumentar a velocidade melhorando o CMOS.
As implicações deste trabalho são importantes. Ela diz que o específico de suas áreas de arquitetura não dará mais melhorias significativas na velocidade quando a lei de Moore deixar de funcionar. E mesmo que os projetistas de chips possam se concentrar em melhorar o desempenho em um número fixo de transistores, essas melhorias serão limitadas pelo fato de que processos bem estudados quase não têm onde melhorar.
O trabalho indica a necessidade de desenvolver uma abordagem fundamentalmente nova para a computação. Uma alternativa em potencial é a
arquitetura Intel Meso . Fuchs e Wenzlaf também
sugeriram o uso de materiais alternativos e outras soluções que vão além do escopo do CMOS, incluindo pesquisas sobre a possibilidade de usar a memória não volátil como aceleradores.