Os sistemas interativos usam muitos diretórios, dicionários de dados, status, códigos, nomes etc. diferentes. Como regra, existem muitos e cada um deles não é grande. Na estrutura, eles geralmente têm atributos comuns: Código, ID, Nome, etc. No código do aplicativo, existem muitas pesquisas diferentes, comparações por Código, por ID de referência. As pesquisas podem ser estendidas, por exemplo: pesquisa por ID, código, obtenha uma lista por critério, classificação, etc. ... E, como resultado, os diretórios são armazenados em cache, reduzindo o acesso frequente ao banco de dados. Aqui, quero mostrar um exemplo de como os repositórios de valor-chave de dados da Spring podem ser úteis para esses fins. A idéia principal é a seguinte: uma pesquisa avançada no repositório de valores-chave e, na ausência de um objeto, faça uma pesquisa nos repositórios de dados do Spring no banco de dados e depois os coloque nos repositórios de valores-chave.
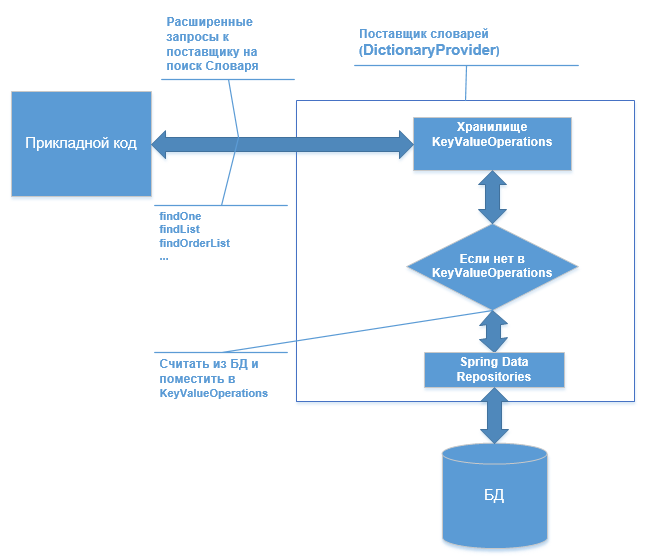
E assim, no Spring, há KeyValueOperations, que é semelhante ao repositório Spring Data, mas opera no conceito de Key-Value e coloca os dados em uma estrutura HashMap (
escrevi aqui sobre os repositórios Spring Data ). Os objetos podem ser de qualquer tipo, o principal é que a chave seja especificada.
public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; ....
Aqui, a chave é statusId, e o caminho completo da anotação é indicado especificamente. No futuro, usarei a Entidade JPA e também haverá um ID, mas já relacionado ao banco de dados.
KeyValueOperations possui métodos semelhantes aos dos repositórios do Spring Data
interface KeyValueOperations { <T> T insert(T objectToInsert); void update(Object objectToUpdate); void delete(Class<?> type); <T> T findById(Object id, Class<T> type); <T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type); .... .
Para que você possa especificar a configuração java KeyValueOperations para o bean Spring
@SpringBootApplication public class DemoSpringDataApplication { @Bean public KeyValueOperations keyValueTemplate() { return new KeyValueTemplate(keyValueAdapter()); } @Bean public KeyValueAdapter keyValueAdapter() { return new MapKeyValueAdapter(ConcurrentHashMap.class); }
A classe de armazenamento do dicionário está listada aqui - ConcurrentHashMap
E como trabalharei com os dicionários de entidades JPA, conectarei dois deles a este projeto.
Este é um dicionário de "Status" e "Cartão"
@Entity public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; @Id @Column(name = "STATUS_ID") public long getStatusId() { return statusId; } .... @Entity public class Card { @org.springframework.data.annotation.Id private long cardId; private String code; private String name; @Id @Column(name = "CARD_ID") public long getCardId() { return cardId; } ...
São entidades padrão que correspondem a tabelas no banco de dados. Chamo a atenção para duas anotações de ID para cada entidade, uma para JPA e a outra para KeyValueOperations
A estrutura dos dicionários é semelhante, um exemplo de um deles
create table STATUS ( status_id NUMBER not null, code VARCHAR2(20) not null, name VARCHAR2(50) not null );
Repositórios Spring Data para eles:
@Repository public interface CardCrudRepository extends CrudRepository<Card, Long> { } @Repository public interface StatusCrudRepository extends CrudRepository<Status, Long> { }
E aqui está o próprio exemplo DictionaryProvider, onde conectamos os repositórios Spring Data e KeyValueOperations
@Service public class DictionaryProvider { private static Logger logger = LoggerFactory.getLogger(DictionaryProvider.class); private Map<Class, CrudRepository> repositoryMap = new HashMap<>(); @Autowired private KeyValueOperations keyValueTemplate; @Autowired private StatusCrudRepository statusRepository; @Autowired private CardCrudRepository cardRepository; @PostConstruct public void post() { repositoryMap.put(Status.class, statusRepository); repositoryMap.put(Card.class, cardRepository); } public <T> Optional<T> dictionaryById(Class<T> clazz, long id) { Optional<T> optDictionary = keyValueTemplate.findById(id, clazz); if (optDictionary.isPresent()) { logger.info("Dictionary {} found in keyValueTemplate", optDictionary.get()); return optDictionary; } CrudRepository crudRepository = repositoryMap.get(clazz); optDictionary = crudRepository.findById(id); keyValueTemplate.insert(optDictionary.get()); logger.info("Dictionary {} insert in keyValueTemplate", optDictionary.get()); return optDictionary; } ....
As injeções automáticas são instaladas nele para repositórios e para KeyValueOperations e, em seguida, para uma lógica simples (aqui, sem verificar nulo etc.), procuramos no dicionário keyValueTemplate, se houver, retornamos; caso contrário, extraímos do banco de dados via crudRepository e colocamos em keyValueTemplate, e fornecemos fora.
Mas se tudo isso se limitar apenas a uma pesquisa de chave, provavelmente não haverá nada de especial. E, portanto, o KeyValueOperations possui uma ampla variedade de operações e solicitações de CRUD. Aqui está um exemplo de uma pesquisa no mesmo keyValueTemplate, mas já por Code usando a consulta KeyValueQuery.
public <T> Optional<T> dictionaryByCode(Class<T> clazz, String code) { KeyValueQuery<String> query = new KeyValueQuery<>(String.format("code == '%s'", code)); Iterable<T> iterable = keyValueTemplate.find(query, clazz); Iterator<T> iterator = iterable.iterator(); if (iterator.hasNext()) { return Optional.of(iterator.next()); } return Optional.empty(); }
E é compreensível que, se antes eu procurei por ID e o objeto entrou em keyValueTemplate, a pesquisa pelo código do mesmo objeto já o retornará de keyValueTemplate, não haverá acesso ao banco de dados. O Spring Expression Language é usado para descrever a solicitação.
Exemplos de teste:
Pesquisa de ID
private void find() { Optional<Status> status = dictionaryProvider.dictionaryById(Status.class, 1L); Assert.assertTrue(status.isPresent()); Optional<Card> card = dictionaryProvider.dictionaryById(Card.class, 100L); Assert.assertTrue(card.isPresent()); }
Pesquisa por Código
private void findByCode() { Optional<Card> card = dictionaryProvider.dictionaryByCode(Card.class, "VISA"); Assert.assertTrue(card.isPresent()); }
Você pode obter listas de dados através de
<T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type);
Você pode especificar a classificação na solicitação
query.setSort(Sort.by(DESC, "name"));
Materiais:
valor-chave dos dados da molaProjeto Github