A Yandex possui um serviço de desenvolvimento de componentes de pesquisa que constrói uma base de pesquisa no MapReduce, fornece dados para composição tipográfica para renderização, gera algoritmos e estruturas de dados e resolve problemas de ML do crescimento da qualidade. Alexey Shlyunkin, chefe de um dos grupos desse serviço, explica em que consiste o tempo de execução da pesquisa e como gerenciamos.
Quer bisbilhotar no ML - bisbilhotar. Você quer apenas o MapReduce - ok. Quer tempo de execução - tempo de execução.
- O que é uma pesquisa hoje? Yandex começou fazendo uma pesquisa, desenvolvendo-a. 20 anos se passaram. Temos uma base de pesquisa para centenas de bilhões de documentos.
Chamamos um documento de qualquer página da Internet, mas, de fato, não apenas isso. Ainda - seu conteúdo, várias estatísticas sobre quais usuários gostam de acessar, quantos deles. Mais os dados que calculamos.
Eles também são dezenas de milhares de instâncias que, em resposta a cada solicitação, processam dados, pesquisam algo, enriquecem a resposta da pesquisa. Algumas instâncias procuram imagens, outras para documentos de texto comuns, outras para vídeo, etc. Ou seja, dezenas de milhares de máquinas são ativadas para todas as suas solicitações. Todos eles tentam encontrar algo e melhorar o resultado que é mostrado a você. Assim, dezenas de milhares de máquinas atendem a milhares de solicitações por segundo. Essas dezenas de milhares de instâncias são combinadas em centenas de serviços projetados para resolver um problema.

Existe um núcleo de pesquisa - um serviço de pesquisa na web. E existe um serviço de pesquisa de vídeos etc. Por conseguinte, existe uma coisa que combina as respostas de diferentes pesquisas e tenta escolher o que e em que ordem é melhor mostrar ao usuário. Se esse é algum tipo de solicitação sobre música, provavelmente é melhor mostrar o Yandex.Music primeiro e, em seguida, por exemplo, uma página sobre esse grupo de músicas. Isso é chamado de liquidificador. Já existem centenas desses serviços, e eles também fazem algo para cada solicitação e tentam ajudar os usuários de alguma forma. E, é claro, tudo isso usa o aprendizado de máquina de todos os tipos, desde algumas estatísticas simples, modelos lineares a incrementos de gradiente, redes neurais e assim por diante.
Vou falar sobre infraestrutura e ML agora.
Meu grupo é chamado de novo grupo de desenvolvimento de tempo de execução, faz parte do serviço de desenvolvimento de componentes de pesquisa. Para que você tenha uma idéia, vou contar um pouco sobre o que nosso serviço faz.

De fato, para todos. Se você enviar uma pesquisa, lançamos nossas mãos em quase tudo, começando com a construção de uma base de pesquisa. Ou seja, temos o MapReduce, coletamos todos os dados sobre os documentos lá, fervemos, construímos todos os tipos de estruturas de dados, para que, quando os consultamos, possamos calcular algo com eficiência. Dessa forma, trabalhamos de baixo quando o documento chega até nós, desde o primeiro estágio, quando esses documentos obtêm algo e o classificam e até o topo, onde o layout recebe JSON condicional e o desenha com todas as fotos e coisas bonitas. De baixo para cima, estamos desenvolvendo algo em toda a pilha.
Mas não estamos apenas escrevendo código e, consequentemente, estamos fazendo tudo isso em infraestrutura. Na verdade, estamos treinando redes neurais, CatBoost. E outras coisas de ML que você pode imaginar e gravar, também ensinamos. Além disso, como temos grandes cargas e grandes dados, é claro que vasculhamos algoritmos e estruturas de dados e nunca nos impedimos de apresentá-los em algum lugar. Por exemplo, em vários lugares, usamos árvores de segmentos. Temos nossa própria compactação de índices que constroem boro e, de acordo com ela, consideramos a dinâmica de como melhor construir dicionários.
Em geral, lidando com um colosso tão grande como uma pesquisa, estávamos saturados de tarefas tão simples. Portanto, é claro que adoramos algo complexo, novo, algo que nos desafia. E não apenas escrevemos, como sempre, dez linhas de código. Precisamos pensar em alguns experimentos. Em geral, as tarefas que nos propomos muitas vezes estão à beira da ficção. Às vezes você pensa: provavelmente não é possível. Mas então você, talvez, de alguma forma experimentou - experimentos podem levar um ano inteiro - mas no final algo acontece. Então começamos a apresentar, refazer algo.
Além de todos os projetos, habilidades e assim por diante, em geral, somos uma das equipes mais ambiciosas e de rápido crescimento da Yandex. Por exemplo, eu vim há dois anos, era a nona pessoa em nosso serviço. Agora, temos um serviço de quase 60 pessoas. De fato, isso acontece com os estagiários, mas, em geral, quatro vezes crescemos exatamente em dois anos. Isso é para você ter uma ideia do que nosso serviço está fazendo.
Agora, quero falar um pouco sobre as principais tarefas e a direção em que, ao que parece, em um futuro próximo, seremos cada vez mais relevantes. Mas, para isso, você deve primeiro descrever brevemente como funciona a camada de pesquisa mais básica.
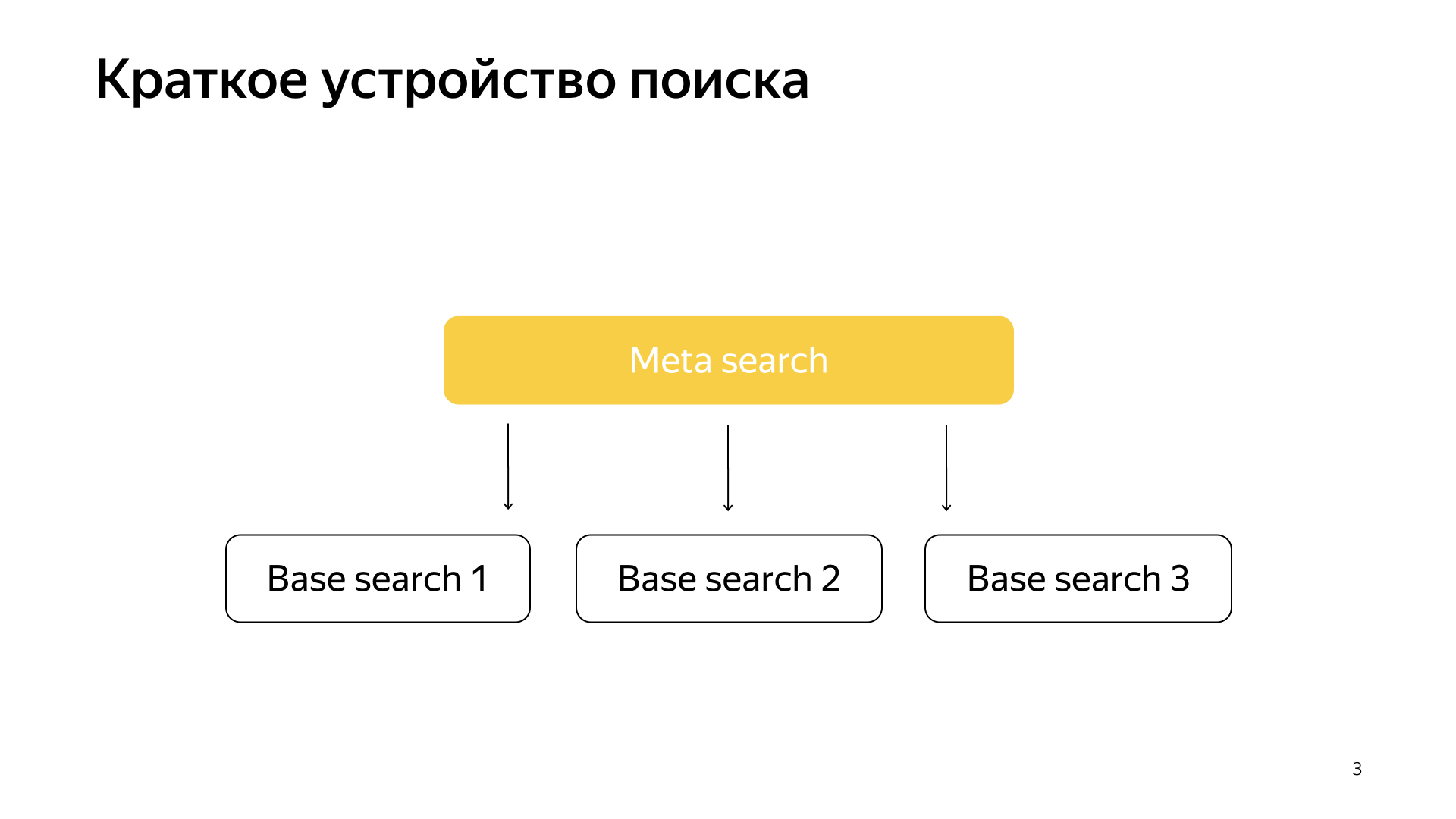
De um modo geral, tudo funciona de maneira muito simples. Temos nossa base de pesquisa, todos os documentos e dividimos todos esses documentos de maneira mais ou menos uniforme em N partes. Eles são chamados de fragmentos. E um programa chamado "Pesquisa básica" é lançado sobre o fragmento. Sua tarefa é pesquisar, nesse sentido, esse pedaço da Internet. Ou seja, ela sabe como procurar e não sabe mais nada sobre a outra Internet. E temos N shards assim. As pesquisas básicas são iniciadas acima delas e, consequentemente, há uma meta pesquisa sobre isso. A solicitação do usuário se encaixa nela e, consequentemente, simplesmente é acessada por todos os shards, e cada shard realiza uma pesquisa, depois cada um retorna um resultado, executa algum tipo de mesclagem e fornece uma resposta.
Foi assim que a pesquisa foi organizada por quase todos os 20 anos e, em geral, por um longo tempo, eles pensaram que isso continuaria assim, e nada melhor poderia ser feito. Mas tudo está mudando, novas tecnologias estão surgindo e o aprendizado de máquina agora não apenas permite aumentar a qualidade, mas também resolver alguns tipos de problemas de infraestrutura. Recentemente, em nossa pesquisa, os projetos foram filmados muito, exatamente na junção de infraestrutura e aprendizado de máquina. Quando dois desses mastodontes se fundem, são obtidos resultados muito interessantes.

Recentemente, redes neurais apareceram. Temos o texto da solicitação, existe o texto do documento. Queremos obter um vetor de números da solicitação, obter um vetor de números do documento para que o produto escalar preveja o valor que queremos. Por exemplo, queremos treinar o produto escalar para prever a probabilidade de um usuário clicar neste documento. Uma coisa bastante compreensível.
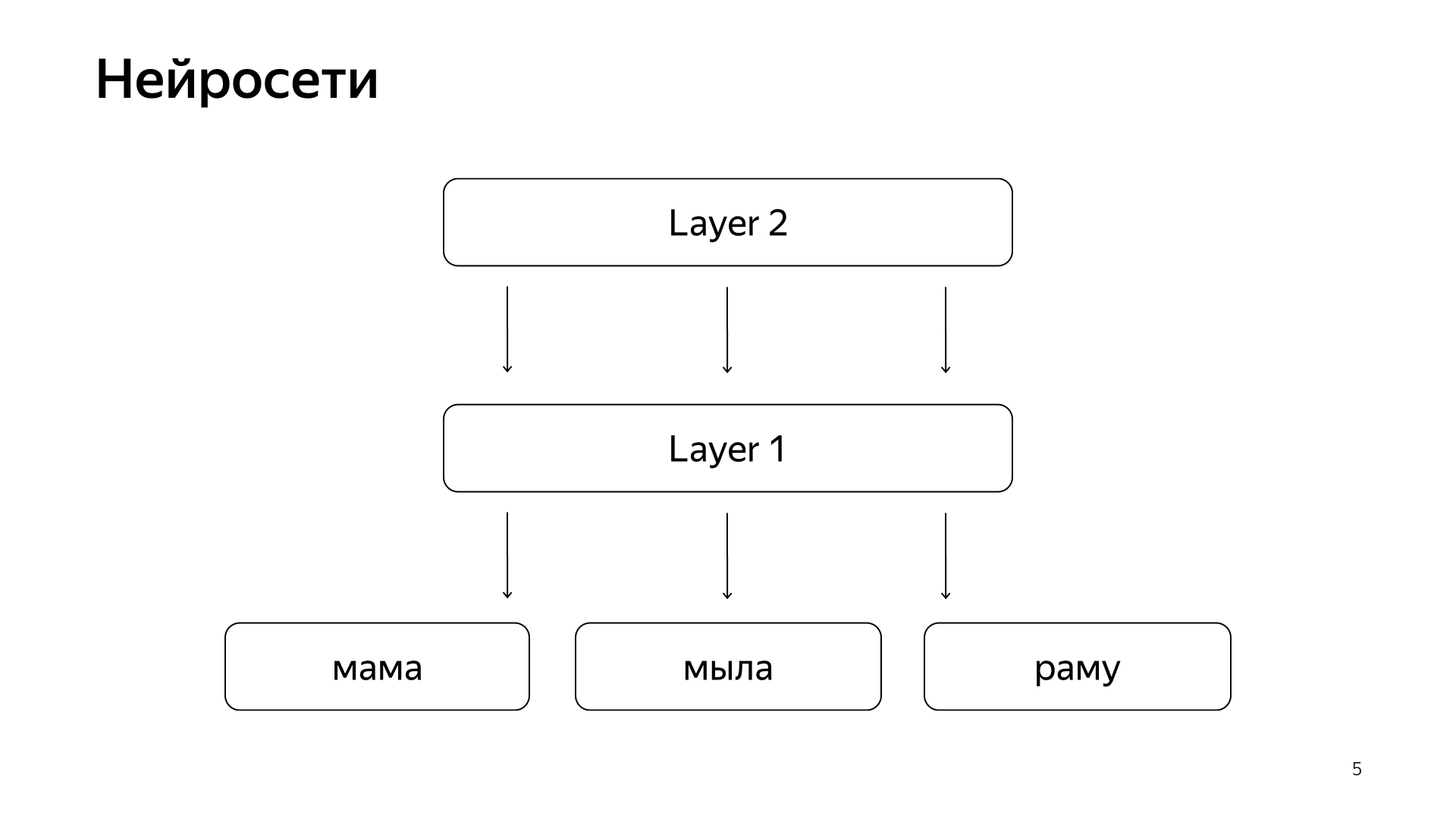
Está organizado aproximadamente assim. Se for muito, muito rude, temos algumas palavras na camada inferior e existem várias camadas da rede. Cada camada, de fato, recebe um vetor como entrada. Ou seja, a camada inferior é um vetor tão esparso, em que cada palavra é uma solicitação. O multiplica por uma matriz, obtém algum tipo de vetor e, consequentemente, aplica alguma não linearidade a cada componente, e faz isso várias vezes. E a última camada, isso é chamado apenas o vetor que acabamos de atender à solicitação, aplicamos essas camadas, e aqui a última camada é o próprio vetor de solicitação.
Consequentemente, essas redes neurais foram ativamente introduzidas na pesquisa nos últimos anos, trouxeram muitos benefícios para a qualidade. Mas eles têm um problema em que todas as quantidades que desejamos prever são boas, mas aproximadas o suficiente, porque, para treinar uma rede neural, a camada inferior é muito grande - todas as palavras são de dezenas de milhões de palavras, então você precisa escrever ela inseriu vários bilhões de dados.
Por exemplo, podemos treinar alguns cliques do usuário, e assim por diante. Mas o principal sinal que é considerado o mais importante em nossa pesquisa é a marcação manual por pessoas especiais. Eles pegam a solicitação, pegam o documento, lêem, entendem como é bom e marcam, ou seja, quanto esse documento se encaixa nessa solicitação. Por um longo tempo, não conseguimos prever essa magnitude pelas redes neurais, porque ainda temos milhões de estimativas, porque contratar um planeta inteiro para marcar constantemente tudo isso é muito caro. Portanto, fizemos alguns truques.
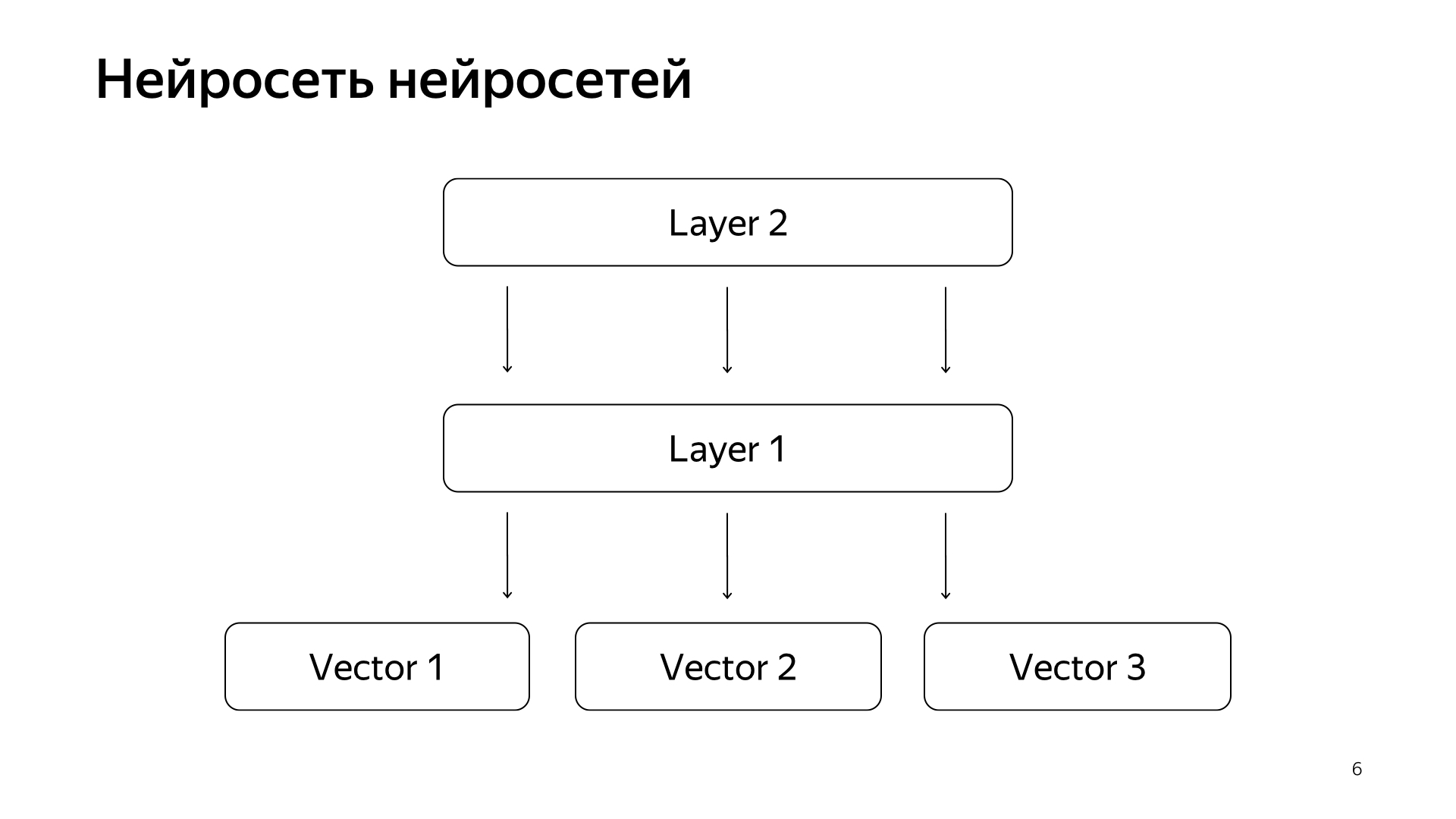
Rede neural de redes neurais. Nos últimos anos, acumulamos muitas redes neurais que prevêem bons sinais, mas um pouco mais difíceis do que a avaliação de pessoas especiais. Assim, decidimos que enviaremos os vetores prontos dessas redes para a camada inferior e, em seguida, treinaremos a rede neural para prever nossa relevância de pesquisa apenas na rede de dados menor.
O resultado foi um modelo muito bom. Ela traz as solicitações de documentos para um vetor, e seu produto escalar prediz diretamente a real relevância que desejamos prever há muito tempo.
Além disso, tivemos uma ideia de como refazer um pouco a pesquisa. O projeto é chamado de base KNN (método inglês k-vizinhos mais próximos, método k-vizinhos mais próximos).

A ideia básica é essa. Temos um vetor de consulta e um vetor de documento. Precisamos encontrar o mais próximo. Cada documento é representado por um vetor. Vamos destacar N clusters, aqueles que caracterizam todo o espaço do documento. Grosso modo. Fortemente menor que o número de documentos, mas, por exemplo, eles caracterizam tópicos. Em termos simples, há um grupo de gatos, um grupo de compras, um conjunto de programação e assim por diante.
Dessa forma, não dispersaremos os documentos aleatoriamente em fragmentos, como antes, mas colocaremos o documento nesse fragmento, ou seja, cujo centróide está mais próximo do documento. Assim, teremos esses documentos agrupados por tópico no shard.
Além disso, apenas para uma solicitação, agora não podemos ir para todos os shards, mas apenas para um pequeno subconjunto daqueles que estão mais próximos dessa solicitação.
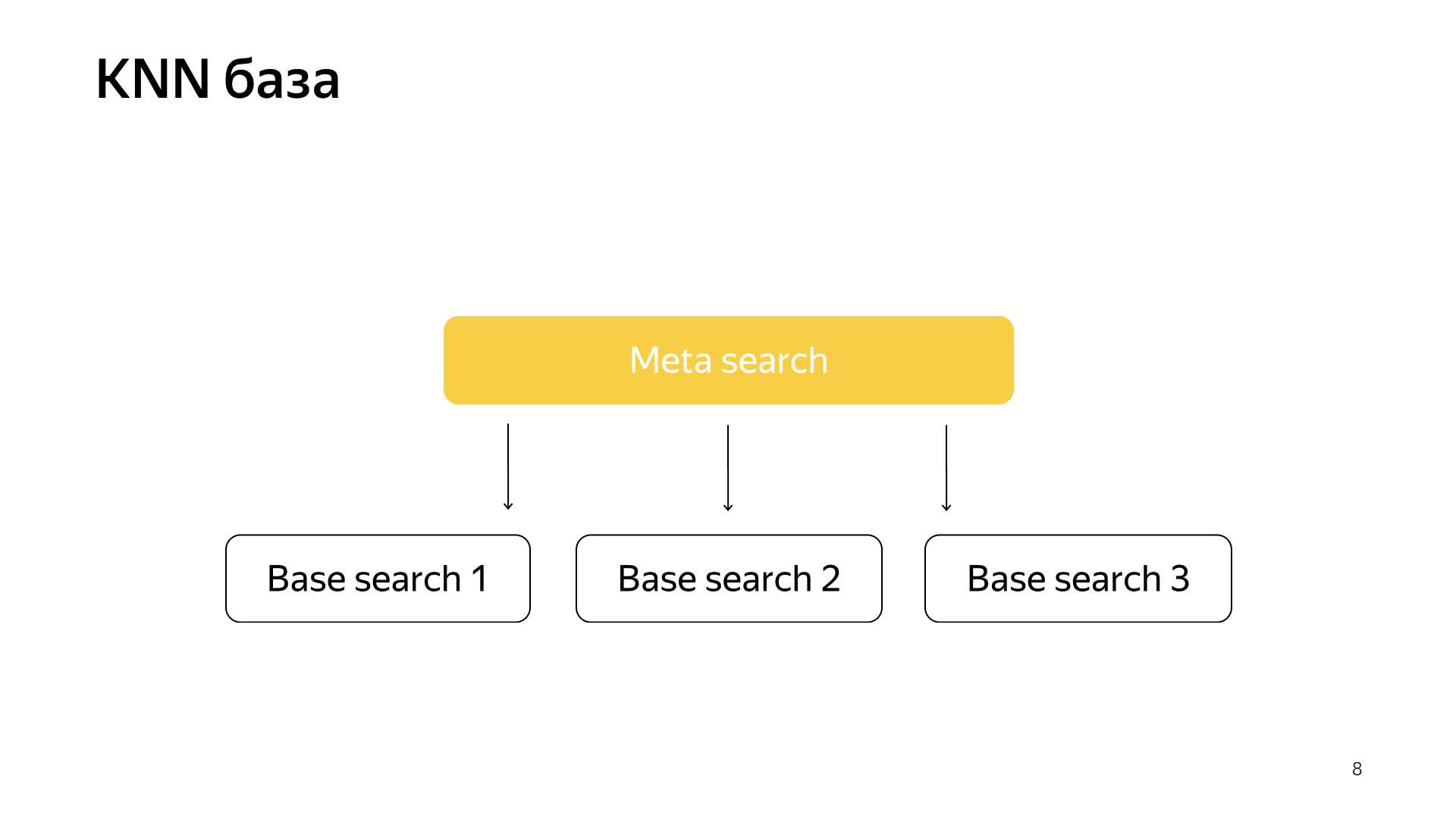
Consequentemente, tínhamos esse esquema, a meta-pesquisa está incluída em todos os shards. E agora ele precisa ir para um número muito menor e, ao mesmo tempo, ainda procuraremos os documentos mais próximos.
O que realmente obtemos desse design? Reduz significativamente o consumo de recursos de computação, simplesmente porque vamos a menos clusters. Isso, como eu já disse, considero um dos destaques de nosso serviço, é a liga de infraestrutura e aprendizado de máquina que oferece resultados tão inéditos que ninguém poderia pensar antes.

E, no final, é apenas uma coisa muito engraçada, porque você conseguiu os modelos aqui e depois refez toda a pesquisa, desativou os petabytes de dados e sua pesquisa funciona, queima dez vezes menos recursos. Você economizou um bilhão de dólares para a empresa, todo mundo está feliz.

Falei sobre um dos projetos que aparece em nossa pesquisa e que está sendo implementado e realizado em conjunto com todos os experimentos para um ano suspenso. Nossas outras tarefas típicas são dobrar a base de pesquisa, porque a Internet está em constante crescimento e queremos alcançá-la e pesquisar em todas as páginas da Internet. E, claro, essa é a aceleração da camada de base, na qual há mais casos, mais ferro. Por exemplo, acelerar a pesquisa básica em um por cento significa economizar cerca de um milhão de dólares.
Também estamos envolvidos na pesquisa como uma incubadora de startups. Eu vou explicar A busca é feita há 20 anos. Já fez muitas coisas, muitas vezes chegamos a um beco sem saída e pensamos que nada mais poderia ser feito. Depois, houve uma longa série de experimentos. Novamente rompemos esse beco sem saída. E durante esse tempo, acumulamos muita experiência em como fazer coisas grandes e legais. Portanto, agora a maioria das novas direções no Yandex é feita na pesquisa, porque as pessoas na pesquisa já sabem como fazer tudo isso, e é lógico pedir que elas criem pelo menos algum novo sistema. E, no máximo - vá e faça você mesmo.
Agora, espero que você tenha uma pequena idéia do nosso trabalho. Vou contar rapidamente a parte temática da minha história sobre estagiários em nosso serviço. Nós os amamos muito. Temos muitos deles, no verão passado, apenas no meu grupo havia 20 estagiários, e acho que isso é bom. Quando você toma um ou três estagiários, eles se sentem um pouco solitários, às vezes têm medo de perguntar aos camaradas mais velhos. E quando existem muitos deles, eles se comunicam como camaradas na desgraça. Se eles tiverem medo de perguntar algo aos desenvolvedores, eles irão sussurrar no canto. Essa atmosfera ajuda a fazer tudo com eficiência.
Temos um milhão de tarefas, a equipe não é muito grande e, portanto, nossos estagiários estão totalmente carregados. Não pedimos ao aluno que fique sentado no registro o tempo todo, escreva testes, refatorar o código, mas imediatamente dê algum tipo de tarefa complicada de produção: acelerar a pesquisa, melhorar a compactação do índice. Claro que ajudamos. Sabemos que tudo isso compensa, por isso estamos felizes em compartilhar nossa experiência. Como nosso campo de atividade é bastante extenso, cada um de nós encontrará uma tarefa para si próprio. Quer bisbilhotar no ML - bisbilhotar. Você quer apenas o MapReduce - ok. Quer tempo de execução - tempo de execução. Existe alguma coisa.
O que você precisa para chegar até nós? Fazemos tudo principalmente em C ++ e Python. Não é necessário conhecer os dois, é possível saber uma coisa. Congratulamo-nos com o conhecimento de algoritmos. Forma um certo estilo de pensamento e ajuda muito. Mas isso também não é necessário: novamente, estamos prontos para ensinar tudo, estamos prontos para investir nosso tempo, porque sabemos que vale a pena. O requisito mais importante que fazemos, nosso lema, é não ter medo de nada e de muitos números. Não tenha medo de diminuir a produção, não tenha medo de começar a fazer algo complicado. Portanto, precisamos de pessoas que também não tenham medo de nada e que também estejam prontas para transformar montanhas. Muito obrigada.