Neste post, falaremos sobre um estudo piloto de ML para o hipermercado online Utkonos, onde previmos a recompra de produtos perecíveis. Ao mesmo tempo, levamos em consideração os dados não apenas sobre os saldos de estoque, mas também o calendário de produção com fins de semana e feriados e até o clima (calor, neve, chuva e granizo nada mais são que o Taft Three Weathers, mas não clientes). Agora sabemos, por exemplo, que a “misteriosa alma russa” tem fome especial de carne aos sábados e aprecia ovos brancos acima dos marrons. Mas as primeiras coisas primeiro.

Piloto de varejo mais que piloto
No varejo, o aprendizado de máquina está em uma posição dupla. Por um lado, os varejistas acumularam quantidades impressionantes de dados em períodos muito impressionantes: recibos de compra individuais, dados de cartões de fidelidade ... Por outro lado, os varejistas existem há tanto tempo que o problema de previsão de demanda começou a ser resolvido muito antes do surgimento da moda da ciência de dados e hoje ela está à sua disposição ferramentas de BI necessárias.
Acontece que o varejo é um dos campos mais promissores para experimentos de cientistas de dados e a introdução do aprendizado de máquina, mas os negócios encaram tudo isso com ceticismo: isso é realmente bom para mim? Afinal, já existem soluções de trabalho comprovadas por muitos anos de experiência.
E então é hora de concordar com um estudo piloto!
Os próprios pilotos, em comparação com um projeto completo de ML, têm limitações e especificidades compreensíveis.
- É gasto bastante tempo em um estudo piloto para mostrar aos clientes as possibilidades de aprendizado de máquina em seus dados, mas não tanto quanto perder dinheiro.
- Além disso, como regra, os datahistists não terão mais uma segunda chance: se os primeiros resultados do negócio não parecerem interessantes, ele permanecerá cético e fiel aos antigos métodos de previsão. Então, você precisa apontar com precisão.
- Durante o projeto piloto, nenhuma relação de confiança pode surgir entre o cliente e o datacenter. E as unidades e especialistas que possuem os dados importantes para interpretação provavelmente não estão disponíveis durante o piloto, além de informações importantes comercialmente.
Obviamente, esses recursos não se manifestam em todos os projetos-piloto, mas constituem uma parte importante de seus riscos.
Um pouco sobre a tarefa
Muito antes de se familiarizar com o aprendizado de máquina, a Utkonos já usava seu próprio sistema analítico, que previa o reembolso de mercadorias por uma semana com uma precisão muito alta. No entanto, o varejista está interessado na possibilidade de aumentar a eficácia do planejamento. Trata-se principalmente de produtos perecíveis, muitos dos quais também são muito caros. Garfo tradicional: se você comprar muito - haverá perdas, se você não comprar o suficiente - o comprador procurará o concorrente pelo seu amado lombo de vitelo colhido com lua cheia e chuva levemente chuviscada. Para uma previsão suficientemente precisa para o dia seguinte a amanhã, as soluções baseadas no aprendizado de máquina são mais adequadas, permitindo que mais fatores sejam levados em conta do que as ferramentas clássicas de BI. Utkonos concordou em atuar como nosso parceiro em um experimento destinado a testar as hipóteses de aplicabilidade do Machine Learning ao comércio eletrônico.
Para mostrar as possibilidades de aprendizado de máquina para resolver esse problema, de acordo com o negócio, vários nomes comerciais foram selecionados:
- dois produtos da categoria “Carnes refrigeradas” - como produtos perecíveis, cujos dados são mais importantes para atualizar rapidamente;
- e dois produtos da categoria “Ovo de galinha” - como produtos com demanda sazonal específica, que não podem ser previstos simplesmente como “na quinta-feira todo mundo compra X e na sexta-feira - X se multiplica por um fator”. Embora os ovos de galinha não sejam difíceis de prever execuções hipotecárias e apenas para eles o horizonte de planejamento semanal seja bastante aceitável, foi nesses produtos que foi necessário mostrar que o aprendizado de máquina realmente vê relacionamentos complexos e faz uma previsão não trivial.
Escolhemos produtos específicos para o nosso gosto, contando com a integridade dos dados históricos. Alguns produtos foram introduzidos na linha recentemente, outros - pelo contrário, foram vendidos uma vez, mas no momento eles já foram retirados do sortimento, portanto o valor dos dados neles era apenas histórico.
Os dados fornecidos pela Utkonos continham informações sobre as vendas de quatro nomes de commodities nos 2 anos anteriores e sobre a disponibilidade desses produtos em estoque nos períodos relevantes. Do conjunto de dados geral, "cortamos" imediatamente os últimos seis meses, do início de novembro ao final de abril - este será o nosso conjunto de testes. Incluía meses de outono relativamente calmos e uma série de férias de inverno e primavera.
Uma curta mas emocionante aventura nos esperava.
Dados de armazéns: misteriosos e necessários
Ao trabalhar com dados históricos, a primeira pergunta que surgiu diante de nós foi como separar as vendas reais das “vendas máximas disponíveis” (ou seja, casos em que as mercadorias que terminam no armazém foram resgatadas 100%, mas, se disponíveis, o volume de vendas poderia ser maior)? Afinal, esses desejos não satisfeitos dos compradores não são exibidos nos dados de forma alguma.
Disponibilidade de mercadorias em estoque. A propósito, a partir da experiência de projetos anteriores no varejo, esperávamos que fossem saldos expressos em unidades de medida. No entanto, nesse caso, estávamos lidando com o indicador relativo "acessibilidade", medido em porcentagem durante o dia. Quanto à disponibilidade de mercadorias no depósito, esse indicador é muito relativo: o fato de não haver mercadorias em nenhum momento não significava que elas quisessem comprá-las.
Tendo experimentado diferentes opções (reconstrução da “demanda real” com base em coeficientes calculados de maneira diferente e filtragem do conjunto de dados de vendas com diferentes limites de acessibilidade), finalmente selecionamos o limite ideal que não tornava o conjunto de dados muito restrito. O ideal - a disponibilidade de mercadorias ao longo do dia - reduziu significativamente os dados, mesmo para as mercadorias mais vendidas.
Item 1: carne refrigerada (aves de capoeira incomuns)
Começamos a trabalhar com carne refrigerada, pois não duvidamos da capacidade preditiva do modelo, assim que ele estava pronto na forma de rascunho. (Spoiler: mas em vão - no conjunto de dados com vendas de ovos uma surpresa interessante estava esperando por nós, mas mais sobre isso mais tarde).
Para economizar tempo "pronto para uso", temos uma biblioteca pronta que funciona bem com séries temporais - o Profeta do Facebook .

Os resultados do modelo nos dados de treinamento mostram imediatamente vantagens e desvantagens. O modelo capta bem a sazonalidade da demanda, mas capta mal. Também feriados conectados pelo Profeta por padrão. O desvio relativo é de 31,36%, continuaremos a usá-lo como resultado base.
A ferramenta interna de visualização de sazonalidade, que o Profeta vê, permite que você obtenha imediatamente uma pequena visão sobre como as compras de um dos produtos mudaram ao longo de dois anos, quais recursos eles têm durante o ano e durante a semana:

Nossa carne refrigerada tem uma clara tendência ascendente no número total de compras, o número de compras aumenta de segunda a sábado e cai no domingo; no verão, as compras ficam visivelmente "caídas". É ruim que o verão não caia no período de teste; por outro lado, lembre-se de que o período de férias e férias é importante para o nível de vendas, porque as férias de verão estão longe de ser as únicas na Rússia.
A questão lógica é: é possível usar esse modelo imediatamente para prever os próximos seis meses?
Intuitivamente, parece que não. O experimento mostrou que sim. O padrão geral de sazonalidade durante a semana está correto. Mas ficou imediatamente óbvio que há um milhão de desvios em relação ao padrão sazonal geral, tanto para cima quanto para baixo, e o desvio médio de 45,71% é muito superior aos resultados nos dados de treinamento. É claro que isso não é bom.
Para começar, vamos tentar treinar o modelo diariamente, imaginando que todos os dias após a conclusão da loja, o conjunto de dados seja complementado com vendas para "hoje". Já sabemos que nas vendas há uma tendência ascendente em geral - é possível que a rotatividade de nossos dados de teste esteja crescendo com maior intensidade devido a uma atividade de marketing mais ativa do que no conjunto de treinamento.
Sucesso relativo: com o treinamento diário do modelo, o desvio relativo é de 33,79%. Complementamos os parâmetros do modelo com informações sobre os fins de semana adiados, jejum religioso e feriados tradicionais da Rússia (como Ano Novo, Páscoa e vários outros). Mudanças repentinas de clima também foram adicionadas: dias em que a temperatura subia ou descia mais de 10 graus ou simplesmente era notavelmente mais alta ou mais baixa do que nos outros dias deste mês. Agora, em média por seis meses, nossa previsão se desviava das vendas reais em 28,48% e, em geral, o modelo passou a considerar melhor os aumentos na atividade do consumidor. Melhoramos o desvio médio em cinco por cento! Apesar do fato de o Profeta, em princípio, funcionar mal e ser recomendável limpar dados deles, foi um movimento notável para a frente.


Antes de mostrar os resultados preliminares, surgiu a pergunta: podemos melhorar um pouco mais a previsão? Se você observar a correlação das vendas do produto e seu preço médio por dia, fica claro que esses são recursos relacionados e o preço não é levado em consideração na construção do modelo. Mas, a julgar pelo conjunto de dados, poderíamos ter apenas um determinado "preço médio por unidade": em pedidos, ele geralmente variava no mesmo dia, ou seja, foi registrado com um desconto pessoal do comprador e os preços da "loja" não foram incluídos no conjunto de dados.

O coeficiente de correlação entre o preço médio por unidade por dia e o número de volumes vendidos desse tipo de carne resfriada foi de ± 0,61 a p <0,01. É claro que o “preço unitário médio” não é um indicador ideal: se durante o dia houve muitas compras de, digamos, parceiros com um grande desconto constante, ruídos perigosos aparecerão nos dados. Mas queríamos destacar os dias em que houve impactos de marketing: descontos gerais em um grupo de mercadorias, descontos para todos que introduzirem um código promocional de distribuição gratuita etc.
No entanto, mesmo após os dias com o preço médio no quantil de 5% serem alocados como dias promocionais, não houve aumento na precisão do modelo. A precisão aumentou em dias de vendas extremas e o desvio relativo médio por seis meses permaneceu o mesmo.
Mas a idéia de uma relação estatística pronunciada com o preço foi preservada para o futuro.

Ficamos bastante satisfeitos com o resultado preliminar: era hora de passar para outras mercadorias antes que o tempo alocado para o projeto piloto terminasse.
Item 2: Ovo de galinha
Fomos imediatamente avisados de que os ovos são uma das categorias de produtos mais indicativas em termos de impacto de eventos externos. Primeiro, o volume de compras cresce na Páscoa: os ovos são pintados e cozidos com ovos. Mas mais, é claro, é pintado. Isso é fácil de entender comparando-se as vendas de ovos brancos e marrons.

Em geral, nosso modelo espera que haja um ligeiro aumento na demanda na Páscoa, mas sua previsão é quase duas vezes menor que o indicador real (e esse desvio de ~ 100% durante a semana da Páscoa torna o desvio médio de seis meses incrivelmente grande). Porque Afinal, a semana da Páscoa acontece anualmente - deve haver um padrão nos dados dos 2 anos anteriores!
A análise da pesquisa mostrou que não há padrão. Em 2018 (esses são nossos dados de teste), o pico de compras cai toda a semana antes da Páscoa até 7 de abril. Na própria Páscoa (8 de abril de 2018), as compras de ovos sempre caem, o que o modelo vê corretamente. Mas em 2017 a Páscoa cai em 16 de abril, e o pico de compras em dados históricos é 8 de abril, e este ano o pico é de um dia. Em 2016, a Páscoa cai em 1 de maio. O pico de compras é 29 de abril, com aumentos um dia antes e um dia depois. Em 2015, a Páscoa cai em 12 de abril, o pico de compras é novamente um dia, em 9 de abril.

Nossa primeira versão foi a influência dos dias da semana (e a imaginação pintou os pais que, amanhã, precisam pintar uma dúzia de ovos, porque a lição temática e a criança disseram isso hoje). Infelizmente, não é assim. Provavelmente, durante a Páscoa, existem alguns fatores que ainda não encontramos (e não levamos em consideração) - externos e relacionados ao marketing da própria empresa.
Nós podemos fazer melhor!
Esta história é sobre como trabalhar com dados de revendedores por um tempo limitado, e não sobre técnicas de aprendizado de máquina secretas. Mas, ao trabalhar com dados, há uma oportunidade de melhorar o resultado.
Após trabalhar com produtos da categoria “Ovo de galinha”, ficou claro que o modelo pode ser aprimorado adicionando fatores que não usamos no projeto piloto. Portanto, foi decidido realizar um pequeno experimento com uma floresta aleatória e dados que podemos coletar de fontes abertas. Além disso, poderemos ver como o modelo se comporta, onde os dias de venda terão um conjunto diversificado de sinais e não apenas um conjunto de "dias especiais" alocados em uma ou outra base.
As seguintes informações foram coletadas no conjunto de dados sobre o "mundo exterior":
- um calendário de produção completo para todos os anos;
- postos religiosos e feriados, feriados seculares;
- condições climáticas e seus desvios dos valores médios de um mês na região, bem como flutuações no último mês, dia e semana;
- taxas de câmbio do dólar e euro para o Banco Central e suas flutuações como indicadores da condição econômica geral.
Separadamente, foram adicionados sinais para realizar campanhas de marketing separadas e o preço por unidade de mercadorias.
No conjunto de dados estendido, construímos novamente um modelo treinado diariamente em novos dados, agora usando o RandomForestRegressor. O desvio relativo melhorou ligeiramente: para 27,29%. O gráfico mostra que o novo modelo prediz melhor o impacto das campanhas de marketing, mas pior - a sazonalidade semanal.

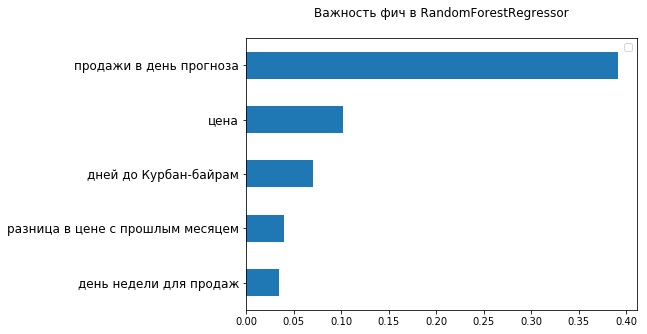
Olhando para os 5 principais sinais mais importantes do ponto de vista do RandomForestRegressor usado, você pode garantir que já existem dois sinais relacionados ao valor dos produtos - o preço atual e suas alterações em relação ao mês passado. Obviamente, o fato de a faixa de preço não poder ser bem estabelecida no Profeta FB afetou sua precisão.
Ao verificar se conseguimos pensar um pouco mais e melhorar o resultado, o estudo piloto foi concluído. Os principais objetivos foram alcançados: mostramos que o aprendizado de máquina é, em princípio, aplicável aos dados do varejista e mostra bons resultados, mesmo no modo "início rápido".
Alexandra Tsareva, Especialista, Análise Inteligente, Jet Infosystems