Qualquer operação com big data exige muito poder de computação. Uma transferência típica de dados de um banco de dados para o Hadoop pode levar semanas ou custar tanto quanto uma asa de avião. Não quer esperar e fazer alarde? Equilibre a carga em diferentes plataformas. Uma maneira é a otimização de empilhamento.
Pedi a Alexei Ananyev, o principal instrutor russo para o desenvolvimento e administração de produtos Informatica, para falar sobre a função de otimização de empilhamento no Informatica Big Data Management (BDM). Já aprendeu a trabalhar com os produtos da Informatica? Provavelmente, foi Alex quem lhe disse o básico do PowerCenter e explicou como criar mapeamentos.
Alexey Ananiev, Chefe de Treinamento do DIS Group
O que é pushdown?
Muitos de vocês já estão familiarizados com o Informatica Big Data Management (BDM). O produto pode integrar big data de diferentes fontes, movê-lo entre diferentes sistemas, fornecer acesso fácil a eles, permitir que você os crie e muito mais.
Em mãos hábeis, o BDM pode fazer maravilhas: as tarefas serão concluídas rapidamente e com o mínimo de recursos computacionais.
Você quer isso também? Aprenda a usar o recurso pushdown no BDM para distribuir a carga de computação entre plataformas. A tecnologia de empilhamento permite transformar o mapeamento em um script e escolher o ambiente em que esse script será executado. A possibilidade de uma escolha desse tipo permite combinar os pontos fortes de diferentes plataformas e alcançar o desempenho máximo.
Para configurar o tempo de execução do script, selecione o tipo de empilhamento. O script pode ser totalmente executado no Hadoop ou parcialmente distribuído entre a fonte e o destinatário. Existem 4 tipos possíveis de pushdown. O mapeamento não pode ser transformado em um script (nativo). O mapeamento pode ser realizado o máximo possível na fonte (fonte) ou completamente na fonte (completa). O mapeamento também pode ser transformado em um script Hadoop (nenhum).
Otimização de empilhamento
Os 4 tipos listados podem ser combinados de diferentes maneiras - otimizar o empilhamento para as necessidades específicas do sistema. Por exemplo, geralmente é mais aconselhável extrair dados de um banco de dados usando seus próprios recursos. E para transformar os dados - pelo Hadoop, para que o próprio banco de dados não seja sobrecarregado.
Vejamos o caso em que a fonte e o destinatário estão no banco de dados e a plataforma de execução de transformação pode ser selecionada: dependendo das configurações, será a Informatica, um servidor de banco de dados ou o Hadoop. Esse exemplo permitirá compreender com mais precisão o lado técnico desse mecanismo. Naturalmente, na vida real, essa situação não surge, mas é mais adequada para demonstrar a funcionalidade.
Faça o mapeamento para ler duas tabelas em um único banco de dados Oracle. E deixe os resultados da leitura serem gravados em uma tabela no mesmo banco de dados. O esquema de mapeamento será o seguinte:

Na forma de mapeamento no Informatica BDM 10.2.1, fica assim:
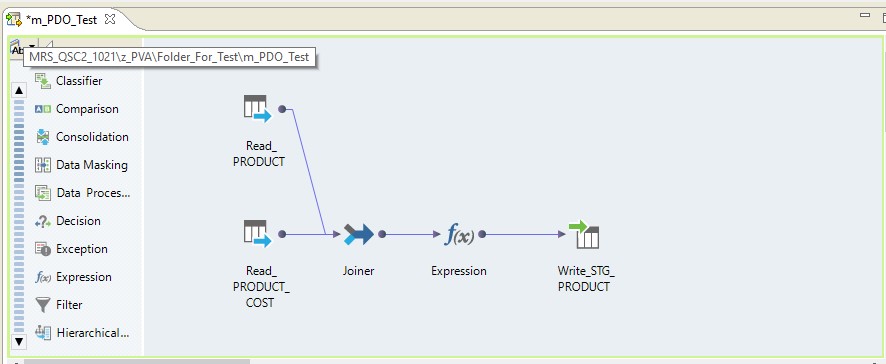
Pushdown de tipo - nativo
Se selecionarmos o tipo nativo de pushdown, o mapeamento será executado no servidor Informatica. Os dados serão lidos no servidor Oracle, transferidos para o servidor Informatica, transformados lá e transferidos para o Hadoop. Em outras palavras, temos um processo ETL regular.
Tipo pushdown - fonte
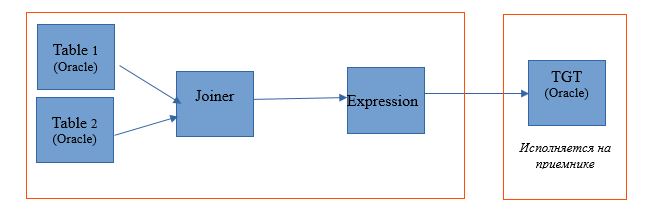
Ao escolher a fonte do tipo, temos a oportunidade de distribuir nosso processo entre o servidor de banco de dados (DB) e o Hadoop. Ao executar um processo com essa configuração, as solicitações para selecionar dados das tabelas voam para o banco de dados. E o restante será feito na forma de etapas no Hadoop.
O esquema de execução terá a seguinte aparência:
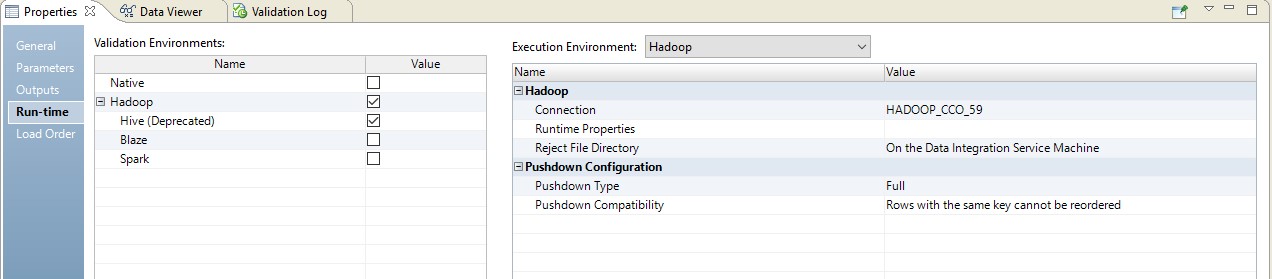
Abaixo está um exemplo de configuração do tempo de execução.
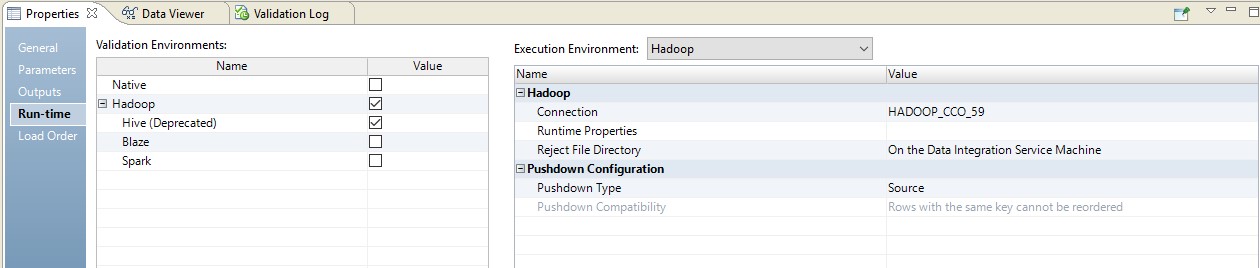
Nesse caso, o mapeamento será realizado em duas etapas. Nas configurações dele, veremos que ele se transformou em um script que será enviado à fonte. Além disso, a combinação de tabelas e conversão de dados será realizada na forma de uma consulta substituída na fonte.
Na figura abaixo, vemos o mapeamento otimizado no BDM e na fonte - uma solicitação substituída.
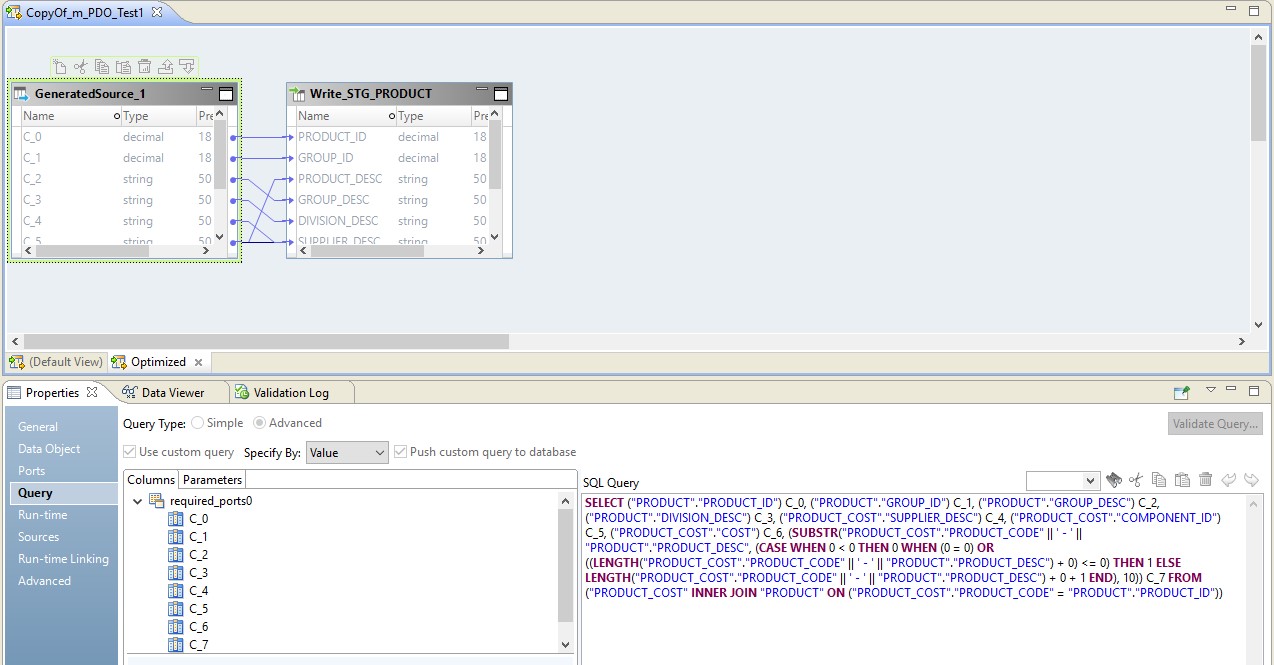
A função do Hadoop nessa configuração se resume a gerenciar o fluxo de dados - conduzi-lo. O resultado da solicitação será enviado ao Hadoop. Após a leitura, o arquivo do Hadoop será gravado no receptor.
Pushdown do tipo - completo
Ao escolher o tipo completo, o mapeamento se transformará completamente em uma solicitação de banco de dados. E o resultado da consulta será direcionado para o Hadoop. Um diagrama desse processo é apresentado abaixo.
Um exemplo de configuração é mostrado abaixo.
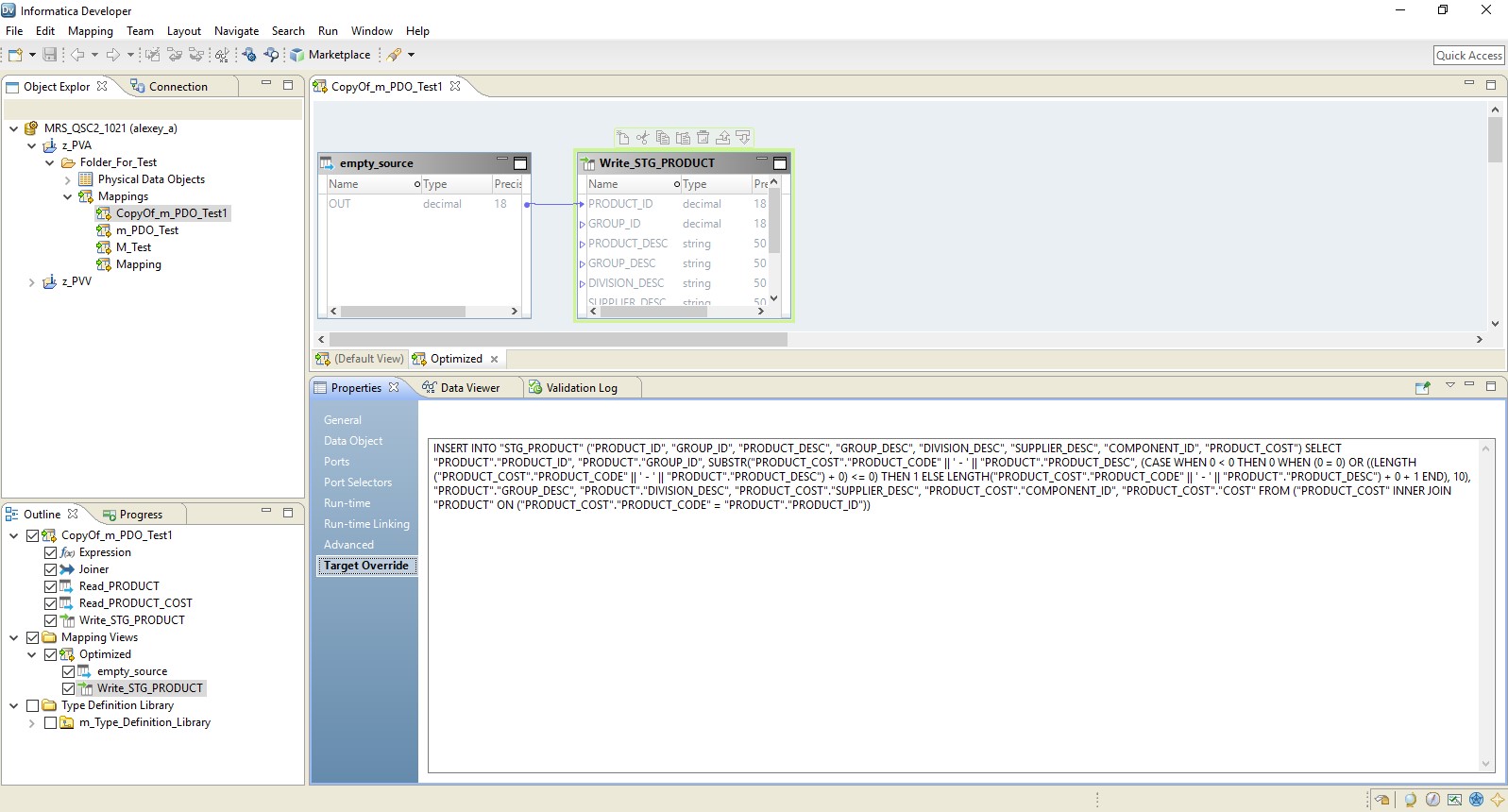
Como resultado, obtemos um mapeamento otimizado semelhante ao anterior. A única diferença é que toda a lógica é transferida para o receptor na forma de uma substituição de sua inserção. Um exemplo de mapeamento otimizado é apresentado abaixo.
Aqui, como no caso anterior, o Hadoop atua como condutor. Mas aqui a fonte é lida na íntegra e, em seguida, no nível do receptor, a lógica de processamento de dados é executada.
Empilhamento de tipo - nulo
Bem, a última opção é o tipo de empilhamento, dentro do qual nosso mapeamento se transformará em um script Hadoop.
O mapeamento otimizado agora terá a seguinte aparência:
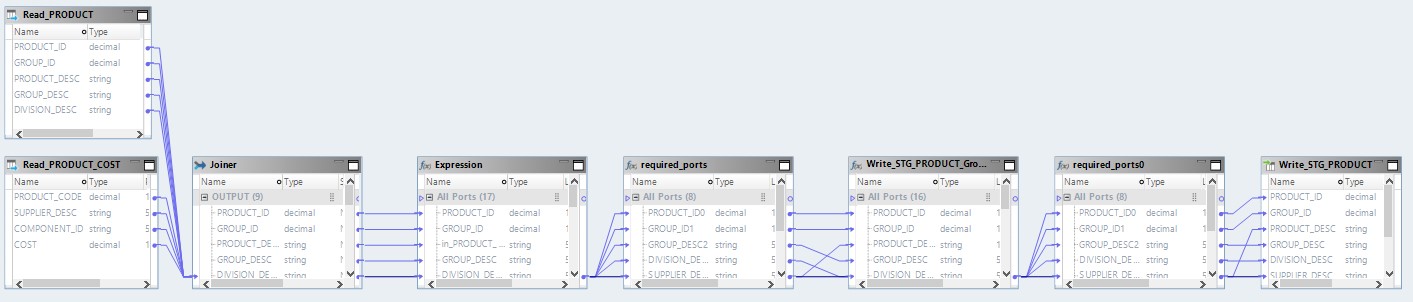
Aqui, os dados dos arquivos de origem serão lidos primeiro no Hadoop. Então, por seus próprios meios, esses dois arquivos serão combinados. Depois disso, os dados serão convertidos e enviados para o banco de dados.
Compreendendo os princípios da otimização de empilhamento, você pode organizar de maneira muito eficaz muitos processos para trabalhar com big data. Então, recentemente, uma grande empresa, em apenas algumas semanas, enviou grandes dados do armazenamento para o Hadoop, que vinha coletando há vários anos.