
Neste artigo, falarei sobre minha solução para a parte de texto da tarefa
SNA Hackathon 2019 . Algumas das idéias propostas serão úteis para os participantes da parte em tempo integral do hackathon, que será realizada no escritório de Moscou do Mail.ru Group de 30 de março a 1 de abril. Além disso, essa história pode ser de interesse para os leitores que resolvem os problemas práticos do aprendizado de máquina. Como não posso reivindicar prêmios (trabalho na Odnoklassniki), tentei oferecer a solução mais simples, mas ao mesmo tempo eficaz e interessante.
Lendo sobre novos modelos de aprendizado de máquina, quero entender como o autor raciocinou ao trabalhar em uma tarefa. Portanto, neste artigo, tentarei substanciar detalhadamente todos os componentes da minha solução. Na primeira parte, falarei sobre a declaração e as limitações do problema. No segundo - sobre a evolução do modelo. A terceira parte é dedicada aos resultados e análise do modelo. Finalmente, nos comentários, tentarei responder a quaisquer perguntas que surgirem. Os leitores impacientes podem examinar imediatamente a
arquitetura final .
Desafio
Os organizadores do Hackathon sugeriram que resolvamos o problema de formar uma fita inteligente. Para cada usuário, é necessário classificar o conjunto de postagens para que o número máximo de postagens para as quais o usuário definiu a “classe” esteja no topo da lista. Para configurar o algoritmo de classificação, deveria-se usar dados históricos do formulário (usuário, publicação, feedback). A tabela fornece uma breve descrição dos dados da parte do texto e a notação que usarei neste artigo.
Fonte
| Designação
| Tipo
| Descrição do produto
|
|---|
o usuário
| user_id
| categórico
| ID do usuário
|
post
| post_id
| categórico
| ID da postagem
|
post
| texto
| lista categórica
| lista de palavras normalizadas
|
post
| características
| categórico
| grupo de características da publicação (autor, idioma etc.)
|
feedback
| feedback
| lista binária
| várias ações que o usuário pode realizar com a postagem (exibição, classe, comentário etc.)
|
Antes de começar a construir o modelo, introduzi várias restrições na solução futura. Isso foi necessário para satisfazer os requisitos de simplicidade e praticidade, meus interesses e reduzir o número de opções possíveis. Aqui estão as mais importantes dessas limitações.
Previsão da probabilidade de "classe" . Decidi imediatamente que resolveria esse problema como um problema de classificação. Pode-se aplicar os métodos usados na classificação, por exemplo, para prever a ordem em pares de postagens. Mas decidi por uma formulação mais simples, na qual as postagens são classificadas de acordo com a probabilidade prevista de obter uma "classe". Vale ressaltar que a abordagem descrita abaixo pode ser expandida para formular o ranking.
Modelo monolítico . Apesar do fato de que conjuntos de modelos tendem a vencer competições, manter um conjunto em um sistema de combate é mais difícil do que um único modelo. Além disso, eu queria ter pelo menos alguns recursos de interpretação que não sejam da caixa preta.
Gráfico computacional diferenciável . Primeiramente, os modelos dessa classe (redes neurais) determinam o estado da arte em muitas tarefas, incluindo aquelas relacionadas à
análise de dados de texto . Em segundo lugar, estruturas modernas, no meu caso
Apache MXNet , permitem implementar arquiteturas muito diversas. Portanto, você pode experimentar diferentes modelos alterando apenas algumas linhas de código.
Trabalho mínimo com sinais . Eu queria que o modelo fosse facilmente expandido com novos dados. Isso pode ser necessário na parte do período integral, onde haverá pouco tempo para preparar os sinais. Portanto, decidi pela abordagem mais simples para identificar atributos:
- dados binários são representados por um tag com o valor 1 ou 0;
- os dados numéricos permanecem como estão ou são discretizados em categorias;
- dados categóricos são apresentados por incorporação.
Tendo decidido sobre a estratégia geral, comecei a experimentar diferentes modelos.
Evolução do modelo
O ponto de partida foi a abordagem de fatoração matricial, frequentemente usada em tarefas de recomendação:
pi,j= sigma(ui cdotvj)
Perda(yi,j,pi,j) rightarrowminu,v
Na linguagem dos gráficos computacionais, isso significa que a estimativa da probabilidade de o usuário
i colocar uma "classe" no post
j é o sigmóide do produto escalar de incorporação do identificador do usuário e do identificador do post. O mesmo pode ser expresso por um diagrama:

Esse modelo não é muito interessante: ele não usa todos os recursos, não é muito útil para identificadores de baixa frequência e sofre do problema de partida a frio. Mas, tendo formulado a tarefa na forma de um gráfico computacional, "desamarramos as mãos" e agora podemos resolver problemas em etapas. Primeiro de tudo, para valores de baixa frequência, criaremos a única incorporação
fora do vocabulário . Em seguida, elimine a necessidade de ter embeddings da mesma dimensão. Para fazer isso, substituímos o produto escalar por um perceptron raso, que recebe recursos concatenados como entrada. O resultado é apresentado no diagrama:

Uma vez que nos livramos de uma dimensão fixa, nada nos impede de começar a adicionar novos atributos. Representando o post com todos os tipos de características (idioma, autor, texto, ...), resolveremos o problema do início a frio dos posts. O modelo aprenderá, por exemplo, que um usuário com
user_id = 42 coloca "classes" em postagens em russo que contêm a palavra "tapete". No futuro, poderemos recomendar a esse usuário todas as postagens em russo sobre tapetes, mesmo que elas não apareçam nos dados de treinamento. Para incorporação de texto, por enquanto, simplesmente calcularemos a média das incorporação das palavras incluídas nela. Como resultado, o modelo fica assim:
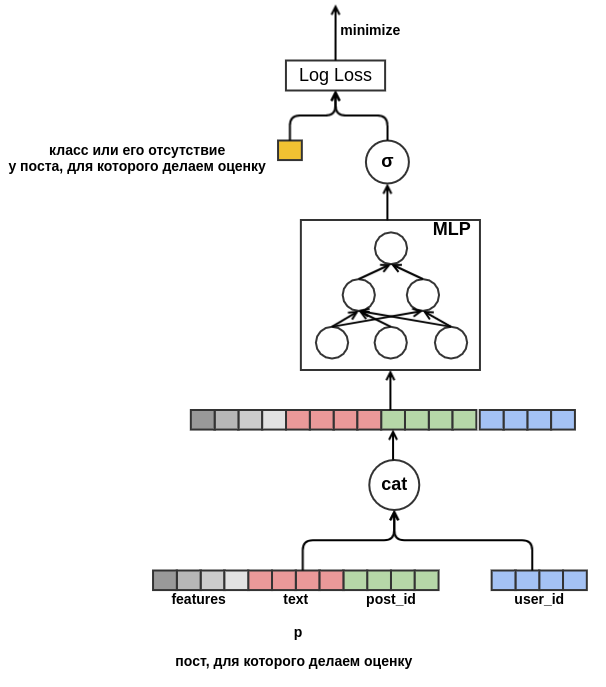
Finalmente, eu gostaria de lidar com o início a frio dos usuários. Seria possível construir recursos a partir de dados históricos nas visualizações do usuário das postagens. Essa abordagem não satisfaz a estratégia escolhida: decidimos minimizar a criação manual de atributos. Portanto, proporcionei ao modelo a oportunidade de aprender independentemente a apresentação do usuário a partir da sequência de postagens visualizadas antes daquela para a qual a probabilidade da “classe” está sendo avaliada. Ao contrário da postagem que está sendo avaliada, todo feedback é conhecido para cada postagem na sequência. Isso significa que o modelo terá acesso a informações sobre se o usuário definiu as “postagens” para postagens anteriores ou, pelo contrário, as excluiu do feed.

Resta decidir como combinar sequências de postes de diferentes comprimentos em uma representação de largura fixa. Como tal, usei a soma ponderada das representações de cada uma das postagens. No gráfico, o peso pós
j é indicado por
α_j . Os pesos foram calculados usando o mecanismo de atenção ao valor da chave de consulta, semelhante ao usado no
transformador ou
NMT . Assim, a apresentação aprendida do usuário também é configurada para a postagem para a qual a avaliação está sendo conduzida. Aqui está uma parte do gráfico responsável pelo cálculo de
α_j :
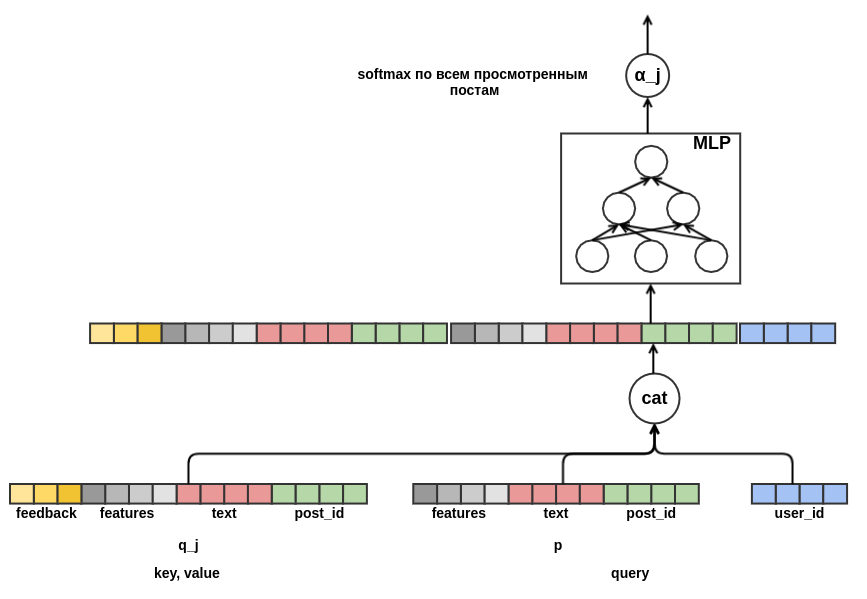
Depois de
sentir um cântico de folia, convenci-me da eficácia da abordagem da atenção, foi decidido usá-la na apresentação de textos. Por uma questão de economizar tempo e ferro, decidi não usar a atenção como no mesmo transformador, mas treinar diretamente a palavra pesos no texto, assim:
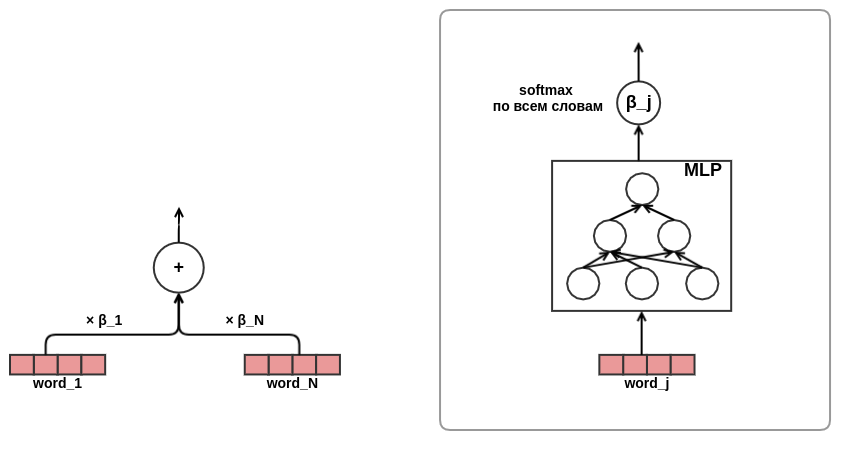
Com isso, o desenvolvimento da arquitetura do modelo foi concluído. Como resultado, passei da fatoração matricial clássica para um modelo de sequência bastante complexo.
Resultados e Análise
Desenvolvi e depurei minha solução em um sétimo dos dados em um laptop com 16 GB de memória e uma placa de vídeo GeForce 930MX. Experimentos completos de dados foram executados em um servidor dedicado com 256 GB de memória e um cartão Tesla T4. Para otimização, foi utilizado o algoritmo Adam com os parâmetros padrão do MXNet. A tabela mostra os resultados para um modelo simplificado - o comprimento da sequência de postagens foi limitado a dez. No envio do concurso, usei sequências de cinquenta anos.
Modelo
| Perda de log
| Melhoria da linha anterior
| Tempo de treinamento
|
|---|
Random
| 0,4374 ± 0,0009
| | |
Perceptron
| 0,4330 ± 0,0010
| 0,0043 ± 0,0002
| 7 min
|
Perceptron com sinais
| 0,4119 ± 0,0008
| 0,0212 ± 0,0003
| 44 min
|
Perceptron com uma sequência de postagens
| 0,3873 ± 0,0008
| 0,0247 ± 0,0003
| 4 horas 16 minutos
|
Perceptron com uma sequência de posts e atenção nos textos
| 0,3874 ± 0,0008
| 0,0001 ± 0,0001
| 4 horas 43 min
|
A última linha acabou sendo a mais inesperada para mim: usar a atenção na apresentação de textos não proporciona uma melhora visível no resultado. Eu esperava que a rede de atenção aprendesse o peso das palavras nos textos, algo como
idf . Talvez isso não tenha acontecido, porque os organizadores removeram as palavras de parada com antecedência e as palavras da mesma importância permaneceram nas listas preparadas. Portanto, a pesagem “inteligente” não ofereceu uma vantagem tangível em comparação à média simples. Outra razão possível é que a rede de atenção às palavras era bastante pequena: continha apenas uma camada oculta estreita. Talvez ela não tivesse capacidade de representação para aprender algo útil.
O mecanismo de atenção ao valor da chave de consulta permite que você olhe dentro do modelo e descubra o que ele “presta atenção” ao tomar uma decisão. Para ilustrar isso,
selecionei alguns exemplos:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
A primeira linha mostra o texto da postagem que precisa ser avaliada, as postagens visualizadas anteriormente e a pontuação de atenção correspondente. Com alívio, notamos que o modelo aprendeu a ignorar o preenchimento. O modelo considerava as postagens as mais importantes sobre tipos de almas e sobre o Windows. Deve-se ter em mente que a atenção pode ser positiva (o usuário responderá a um post sobre uma aura da mesma maneira que um post sobre tipos de almas) ou negativa (avaliaremos um post sobre uma aura - portanto, a reação não será a mesma que a reação ao post sobre tecnologia). O exemplo a seguir é atenção "em toda a sua glória":
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
Aqui, o modelo viu claramente o tema das férias de verão. Até crianças e gatinhos foram pelo caminho. O exemplo a seguir mostra que nem sempre é possível interpretar a atenção. Às vezes, mesmo nada é claro:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
Depois de examinar várias dessas listas, concluí que o modelo era capaz de aprender o que eu esperava. A próxima coisa que fiz foi olhar para a incorporação de palavras. Em nosso problema, não podemos esperar que os casamentos se tornem tão bonitos quanto ao aprender um
modelo de linguagem : estamos tentando prever uma variável bastante barulhenta; além disso, não temos uma pequena janela de contexto - os casamentos de todas as palavras são simplesmente calculados em média, sem levar em consideração sua ordem no texto. Exemplos de tokens e seus vizinhos mais próximos no espaço de incorporação:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
Parte desta lista é fácil de explicar (program - bl), algo é intrigante (iPhone - youki), mas, em geral, o resultado novamente atendeu às minhas expectativas.
Conclusão
Gosto da abordagem para criar modelos com base em gráficos diferenciáveis (
muitos concordam ). Ele permite que você se afaste da tediosa seleção manual de recursos e concentre-se na formulação correta do problema e no design de arquiteturas interessantes. E embora meu modelo tenha ficado apenas em segundo lugar na tarefa de texto do SNA Hackathon 2019, estou bastante satisfeito com esse resultado, dada a sua simplicidade e opções de expansão quase ilimitadas. Estou certo de que, no futuro, haverá cada vez mais modelos interessantes e aplicáveis em sistemas de combate baseados em idéias semelhantes.