Hoje vou lhe contar como conseguimos resolver o problema de portar
aplicativos de fluxo estruturado Spark para
Kubernetes (K8s) e implementar o fluxo de CI.
Como tudo começou?
O streaming é um componente essencial da plataforma FASTEN RUS BI. Os dados em tempo real são usados pela equipe de análise de datas para criar relatórios operacionais.
Os aplicativos de streaming são implementados usando o
Spark Structured Streaming . Essa estrutura fornece uma API de transformação de dados conveniente que atende às nossas necessidades em termos de velocidade das melhorias.
Os próprios fluxos aumentaram no cluster da
AWS EMR . Portanto, ao elevar um novo fluxo ao cluster, um script ssh foi estabelecido para enviar os trabalhos do Spark, após o qual o aplicativo foi iniciado. E, a princípio, tudo parecia nos servir. Porém, com o crescente número de fluxos, a necessidade de implementar o fluxo de IC tornou-se cada vez mais óbvia, o que aumentaria a autonomia do comando de data de análise ao iniciar aplicativos para fornecer dados sobre novas entidades.
E agora veremos como conseguimos resolver esse problema, portando o streaming para o Kubernetes.
Por que Kubernetes?
O Kubernetes, como gerente de recursos, melhor se adequou às nossas necessidades. Essa é uma implantação sem tempo de inatividade e uma ampla variedade de ferramentas de implementação de IC no Kubernetes, incluindo Helm. Além disso, nossa equipe possuía experiência suficiente na implementação de pipelines de CI nos K8s. Portanto, a escolha foi óbvia.
Como é organizado o modelo de gerenciamento de aplicativos Spark baseado em Kubernetes?

O cliente executa o envio de spark nos K8s. Um pod de driver de aplicativo é criado. O Kubernetes Scheduler vincula um pod a um nó de cluster. Em seguida, o driver envia uma solicitação para criar pods para executar executivos, os pods são criados e anexados aos nós do cluster. Depois disso, um conjunto padrão de operações é executado com a subsequente conversão do código do aplicativo em DAG, decomposição em estágios, decomposição em tarefas e seu lançamento em executáveis.
Este modelo funciona com êxito ao iniciar manualmente os aplicativos Spark. No entanto, a abordagem de iniciar o envio de spark fora do cluster não nos convém em termos de implementação de IC. Era necessário encontrar uma solução que permitisse ao Spark executar (enviar o spark) diretamente nos nós do cluster. E aqui o modelo Kubernetes Operator atendeu totalmente aos nossos requisitos.
Operador Kubernetes como modelo de gerenciamento do ciclo de vida de aplicativos Spark
O Kubernetes Operator é um conceito de gerenciamento de aplicativos de estado no Kubernetes, proposto pelo
CoreOS , que envolve a automação de tarefas operacionais, como implantar aplicativos, reiniciar aplicativos em caso de arquivos, atualizar a configuração de aplicativos. Um dos principais padrões do Operador Kubernetes é o CRD (
CustomResourceDefinitions ), que envolve a adição de recursos personalizados ao cluster K8s, que, por sua vez, permite trabalhar com esses recursos, como nos objetos nativos do Kubernetes.
Operador é um daemon que vive no pod do cluster e responde à criação / alteração do estado de um recurso personalizado.
Considere este conceito para o gerenciamento do ciclo de vida de aplicativos Spark.
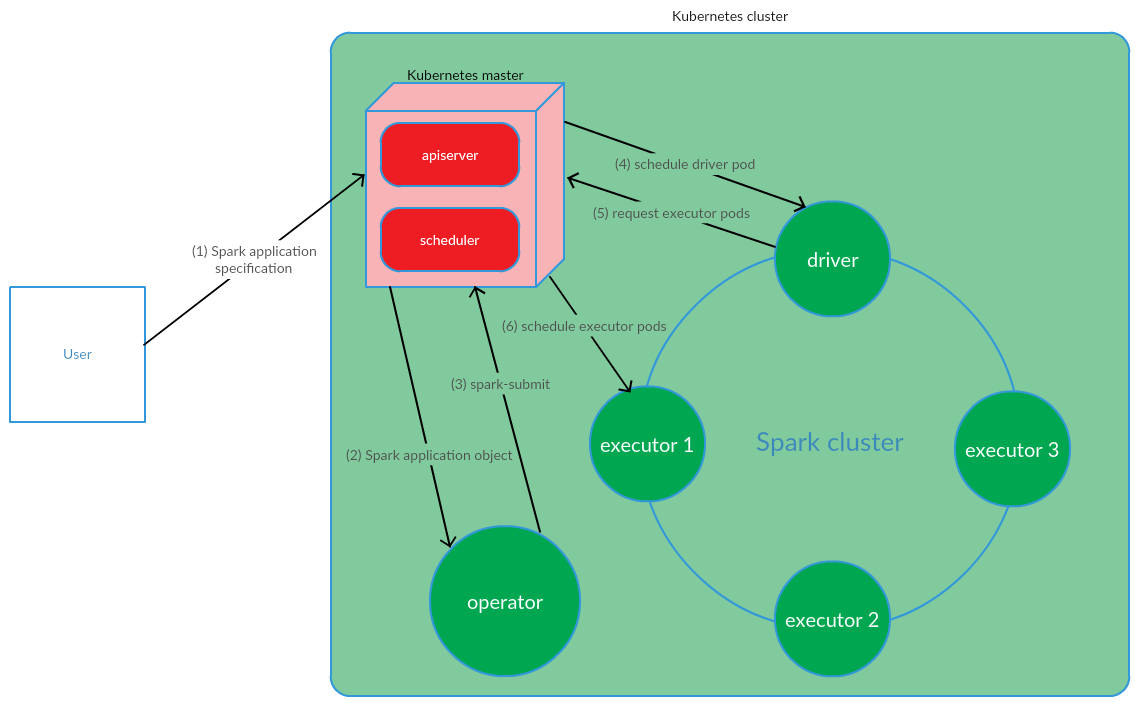
O usuário executa o comando kubectl apply -f spark-application.yaml, em que spark-application.yaml é a especificação do aplicativo Spark. O operador recebe o objeto de aplicativo Spark e executa o envio de spark.
Como podemos ver, o modelo Kubernetes Operator envolve o gerenciamento do ciclo de vida de um aplicativo Spark diretamente no cluster Kubernetes, que foi um argumento sério a favor desse modelo no contexto de solução de nossos problemas.
Como operador da Kubernetes para gerenciar aplicativos de streaming, foi decidido usar o
operador spark-on-k8s . Esse operador oferece uma API bastante conveniente, além de flexibilidade na configuração da política de reinicialização dos aplicativos Spark (o que é bastante importante no contexto do suporte a aplicativos de streaming).
Implementação de IC
Para implementar o streaming de IC,
foi utilizado o GitLab CI / CD . A implantação dos aplicativos Spark nos K8s foi realizada usando as ferramentas
Helm .
O pipeline em si envolve 2 etapas:
- teste - a verificação de sintaxe é realizada, bem como a renderização dos modelos do Helm;
- deploy - implantação de aplicativos de streaming nos ambientes de teste (dev) e produto (prod).
Vamos considerar esses estágios com mais detalhes.
No estágio de teste, o modelo Helm do aplicativo Spark (CRD -
SparkApplication ) é
renderizado com valores específicos do ambiente.
As principais seções do Helm-template são:
- faísca:
- version - versão Apache Spark
- image - imagem do Docker usada
- nodeSelector - contém uma lista (chave → valor) correspondente aos rótulos das lareiras.
- tolerations - indica a lista de tolerâncias do aplicativo Spark.
- mainClass - classe de aplicativo Spark
- applicationFile - caminho local em que o jar do aplicativo Spark está localizado
- restartPolicy - Política de reinicialização do aplicativo Spark
- Nunca - o aplicativo Spark concluído não é reiniciado
- Sempre - o aplicativo Spark concluído é reiniciado independentemente do motivo da parada.
- OnFailure - o aplicativo Spark é reiniciado apenas em caso de arquivo
- maxSubmissionRetries - número máximo de envios de um aplicativo Spark
- motorista / executor:
- núcleos - o número de núcleos alocados ao driver / executor
- instâncias (usadas apenas para configuração de executivos) - o número de executivos
- memória - a quantidade de memória alocada ao processo do driver / executor
- memoryOverhead - a quantidade de memória fora da pilha alocada para o driver / executor
- fluxos:
- nome - nome do aplicativo de streaming
- argumentos - argumentos para o aplicativo de streaming
- sink - o caminho para os conjuntos de dados do Data Lake no S3
Após renderizar o modelo, os aplicativos são implantados no ambiente de teste de desenvolvimento usando o Helm.
Trabalhou o pipeline de IC.
Em seguida, lançamos o trabalho deploy-prod - lançando aplicativos em produção.
Estamos convencidos do desempenho bem-sucedido do trabalho.
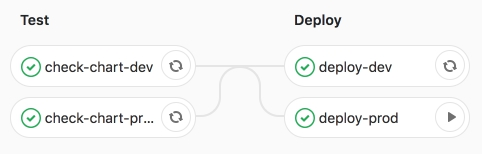
Como podemos ver abaixo, os aplicativos estão em execução, os pods estão no status RUNNING.

Conclusão
A portabilidade de aplicativos de fluxo estruturado Spark para K8s e a subsequente implementação do CI tornaram possível automatizar o lançamento de fluxos para entrega de dados a novas entidades. Para aumentar o próximo fluxo, basta preparar uma Solicitação de Mesclagem com uma descrição da configuração do aplicativo Spark no arquivo yaml de valores e quando o trabalho deploy-prod for iniciado, a entrega de dados ao Data Lake (S3) será iniciada. Essa solução garantiu a autonomia do comando data da análise ao executar tarefas relacionadas à adição de novas entidades ao repositório. Além disso, a transferência de streaming para K8s e, em particular, o gerenciamento de aplicativos Spark usando o operador Kubernetes Operator spark-on-k8s-aumentaram significativamente a resiliência do streaming. Mas mais sobre isso no próximo artigo.