
O mundo moderno é simplesmente inconcebível sem o uso de sistemas distribuídos. Até o aplicativo móvel mais simples possui uma API através da qual ele se conecta ao armazenamento em nuvem. No entanto, o design de sistemas distribuídos ainda é uma arte, não uma ciência exata. A necessidade de incluir uma base séria está muito atrasada e, se você quiser ganhar confiança na criação, suporte e operação de sistemas distribuídos - comece com este livro!
Brendan Burns, um especialista respeitável em tecnologias de nuvem e Kubernetes, estabelece neste pequeno trabalho o mínimo absoluto necessário para o design adequado de sistemas distribuídos. Este livro descreve os padrões eternos de projetar sistemas distribuídos. Isso ajudará você não apenas a criar esses sistemas a partir do zero, mas também a converter efetivamente os existentes.
Trecho. Padrão Decorador. Converter uma solicitação ou resposta
O FaaS é ideal quando você precisa de funções simples que processam dados de entrada e depois os transferem para outros serviços. Esse tipo de padrão pode ser usado para estender ou decorar solicitações HTTP enviadas ou recebidas por outro serviço. Este padrão é mostrado esquematicamente na Fig. 8.1
A propósito, nas linguagens de programação existem várias analogias para esse padrão. Em particular, o Python possui decoradores de funções que são funcionalmente semelhantes aos decoradores de solicitações ou respostas. Como as transformações de decoração não armazenam estado e geralmente são adicionadas de fato à medida que o serviço se desenvolve, elas são ideais para implementação como FaaS. Além disso, a leveza do FaaS significa que você pode experimentar diferentes decoradores até encontrar um que se integre mais de perto ao serviço.
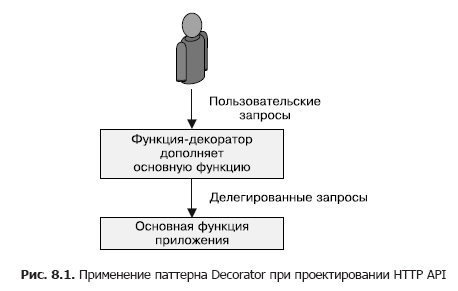
A adição de valores padrão aos parâmetros de entrada das solicitações da API HTTP RESTful demonstra os benefícios do padrão Decorator. Muitas solicitações de API possuem campos que precisam ser preenchidos com valores razoáveis se não forem especificados pelo chamador. Por exemplo, você deseja que o campo seja padronizado como true. Isso é difícil de obter com o JSON clássico, porque o campo vazio padrão é nulo, que geralmente é interpretado como falso. Para resolver esse problema, você pode adicionar a lógica de substituir valores padrão na frente do servidor da API ou no código do aplicativo (por exemplo, se (campo == nulo) campo = verdadeiro). No entanto, essas duas abordagens não são ideais, pois o mecanismo de substituição padrão é conceitualmente independente do processamento de solicitações. Em vez disso, podemos usar o padrão FaaS Decorator, que transforma a solicitação no caminho entre o usuário e a implementação do serviço.
Considerando o que foi dito anteriormente na seção sobre padrões de nó único, você pode estar se perguntando por que não projetamos o serviço de substituição padrão na forma de um contêiner de adaptador. Essa abordagem faz sentido, mas também significa que o dimensionamento do serviço de pesquisa padrão e o dimensionamento do próprio serviço da API dependem um do outro. Substituir valores padrão é uma operação computacionalmente fácil e, provavelmente, você não precisará de muitas instâncias do serviço.
Nos exemplos deste capítulo, usaremos a estrutura FaaS sem kubeless (https://github.com/kubeless/kubeless). O Kubeless é implantado no serviço de orquestrador de contêineres do Kubernetes. Se você já preparou o cluster Kubernetes, continue com a instalação do Kubeless, que pode ser baixada no site correspondente (https://github.com/kubeless/kubeless/releases). Depois de ter o executável kubeless, você pode instalá-lo no cluster com o comando kubeless install.
O Kubeless é instalado como um complemento da API do Kubernetes de terceiros. Isso significa que após a instalação, ele pode ser usado como parte da ferramenta de linha de comando kubectl. Por exemplo, as funções implementadas no cluster podem ser vistas executando o comando kubectl get functions. No momento, não há funções implantadas no seu cluster.
Seminário Substituição de valores padrão antes do processamento da solicitação
Você pode demonstrar a utilidade do padrão Decorator no FaaS usando o exemplo de substituição de valores padrão em uma chamada RESTful por parâmetros cujos valores não foram definidos pelo usuário. Com o FaaS, isso é bastante simples. A função de pesquisa padrão está escrita em Python:
# -, # def handler(context): # obj = context.json # "name" , # if obj.get("name", None) is None: obj["name"] = random_name() # 'color', # 'blue' if obj.get("color", None) is None: obj["color"] = "blue" # API- # # return call_my_api(obj)
Salve esta função em um arquivo chamado defaults.py. Lembre-se de substituir a chamada call_my_api pela API que você deseja. Esta função de substituição padrão pode ser registrada como uma função sem kubeless com o seguinte comando:
kubeless function deploy add-defaults \ --runtime python27 \ --handler defaults.handler \ --from-file defaults.py \ --trigger-http
Para testá-lo, você pode usar a ferramenta kubeless:
kubeless function call add-defaults --data '{"name": "foo"}'
O padrão Decorator mostra como é fácil adaptar e estender APIs existentes com recursos adicionais, como validar ou substituir valores padrão.
Manipulação de eventos
A maioria dos sistemas é orientada a consultas - eles processam fluxos contínuos de solicitações de usuários e API. Apesar disso, existem alguns sistemas orientados a eventos. Parece-me que a diferença entre a solicitação e o evento está no conceito da sessão. Solicitações fazem parte de um processo de interação maior (sessão). No caso geral, cada solicitação de usuário faz parte do processo de interação com um aplicativo Web ou a API como um todo. Eu vejo os eventos como mais "únicos", de natureza assíncrona. Os eventos são importantes e devem ser tratados de acordo, mas são arrancados do contexto principal de interação e a resposta a eles vem somente depois de algum tempo. Um exemplo de evento é a assinatura de um usuário para um determinado serviço, o que causará o envio de uma carta de saudação; carregar um arquivo para uma pasta compartilhada, o que levará ao envio de notificações para todos os usuários desta pasta; ou até mesmo preparar o computador para uma reinicialização, que notificará o operador ou o sistema automatizado de que a ação apropriada é necessária.
Como esses eventos são amplamente independentes e não têm estado interno, e sua frequência é muito variável, eles são ideais para trabalhar em arquiteturas de FaaS orientadas a eventos. Eles geralmente são implantados ao lado do servidor de aplicativos de "batalha" para fornecer recursos adicionais ou para processamento em segundo plano de dados em resposta a eventos emergentes. Além disso, como novos tipos de eventos processados são constantemente adicionados ao serviço, a simplicidade da implantação da função os torna adequados para implementar manipuladores de eventos. E como cada evento é conceitualmente independente dos outros, o enfraquecimento forçado dos relacionamentos dentro de um sistema construído com base em funções nos permite reduzir sua complexidade conceitual, permitindo que o desenvolvedor se concentre nas etapas necessárias para processar apenas um tipo específico de evento.
Um exemplo específico de integração de um componente orientado a eventos em um serviço existente é a implementação da autenticação de dois fatores. Nesse caso, o evento será o login do usuário no sistema. Um serviço pode gerar um evento para esta ação e passá-lo para uma função de manipulador. O processador, com base no código transmitido e nos detalhes de contato do usuário, enviará a ele um código de autenticação na forma de uma mensagem de texto.
Seminário Implementando autenticação de dois fatores
A autenticação de dois fatores indica que, para o usuário entrar no sistema, ele precisa de algo que ele conhece (por exemplo, uma senha) e algo que ele possui (por exemplo, um número de telefone). A autenticação de dois fatores é muito melhor do que apenas uma senha, porque um invasor precisará roubar sua senha e seu número de telefone para obter acesso.
Ao planejar a implementação da autenticação de dois fatores, é necessário processar uma solicitação para gerar um código aleatório, registrá-lo no serviço de logon e enviar uma mensagem ao usuário. Você pode adicionar código que implementa essa funcionalidade diretamente no próprio serviço de logon. Isso complica o sistema, o torna mais monolítico. O envio de uma mensagem deve ser feito simultaneamente com o código que gera a página da web de login, o que pode causar um certo atraso. Esse atraso prejudica a qualidade da interação do usuário com o sistema.
Seria melhor criar um serviço FaaS que gere um número aleatório assincronamente, registre-o no serviço de login e envie-o para o telefone do usuário. Assim, o servidor de login pode simplesmente executar uma solicitação assíncrona ao serviço FaaS, que paralelamente executará a tarefa relativamente lenta de registrar e enviar o código.
Para ver como isso funciona, considere o seguinte código:
def two_factor(context): # code = random.randint(1 00000, 9 99999) # user = context.json["user"] register_code_with_login_service(user, code) # Twillio account = "my-account-sid" token = "my-token" client = twilio.rest.Client(account, token) user_number = context.json["phoneNumber"] msg = ", {}, : {}.".format(user, code) message = client.api.account.messages.create(to=user_number, from_="+1 20652 51212", body=msg) return {"status": "ok"}
Em seguida, registre o FaaS no kubeless:
kubeless function deploy add-two-factor \ --runtime python27 \ --handler two_factor.two_factor \ --from-file two_factor.py \ --trigger-http
Uma instância dessa função pode ser gerada de forma assíncrona a partir do código JavaScript do cliente depois que o usuário digita a senha correta. A interface da web pode exibir imediatamente a página para inserir o código, e o usuário, assim que receber o código, poderá informá-lo do serviço de login no qual esse código já está registrado.
Portanto, a abordagem do FaaS facilitou muito o desenvolvimento de um serviço simples, assíncrono e orientado a eventos que é iniciado quando um usuário faz logon no sistema.
Transportadores de Eventos
Existem vários aplicativos que, de fato, são mais fáceis de considerar como um pipeline de eventos vagamente acoplados. Os pipelines de eventos geralmente se parecem com os bons e antigos fluxogramas. Eles podem ser representados como um gráfico direcionado de sincronização de eventos relacionados. Na estrutura do padrão Event Pipeline, os nós correspondem às funções e os arcos que os conectam correspondem a solicitações HTTP ou outro tipo de chamada de rede.
Entre os elementos do contêiner, como regra, não existe um estado comum, mas pode haver um contexto comum ou outro ponto de referência, com base no qual a pesquisa no armazenamento será realizada.
Qual é a diferença entre essa arquitetura de pipeline e microsserviço? Existem duas diferenças importantes. A primeira e mais importante diferença entre funções de serviço e serviços em execução constante é que os pipelines de eventos são essencialmente orientados a eventos. A arquitetura de microsserviços, pelo contrário, implica um conjunto de serviços em constante funcionamento. Além disso, os pipelines de eventos podem ser assíncronos e vincular uma variedade de eventos. É difícil imaginar como a aprovação do aplicativo Jira pode ser integrada a um aplicativo de microsserviço. Ao mesmo tempo, é fácil imaginar como ele se integra ao pipeline de eventos.
Como exemplo, considere um pipeline no qual o evento de origem é o carregamento do código em um sistema de controle de versão. Este evento causa uma reconstrução do código. A montagem pode levar vários minutos, após os quais é gerado um evento que dispara a função de teste do aplicativo montado. Dependendo do sucesso da montagem, a função de teste executa ações diferentes. Se a montagem foi bem-sucedida, é criado um aplicativo, que deve ser aprovado pela pessoa para que a nova versão do aplicativo entre em operação. Fechar o aplicativo serve como um sinal para colocar a nova versão em operação. Se a montagem falhar, Jira fará uma solicitação para o erro detectado e o pipeline sairá.
Seminário Implementando um pipeline para registrar um novo usuário
Considere a tarefa de implementar uma sequência de ações para registrar um novo usuário. Ao criar uma nova conta, uma série de ações sempre é executada, por exemplo, enviando um email de boas-vindas. Também há várias ações que podem não ser executadas sempre, por exemplo, para assinar um boletim informativo por email sobre novas versões de um produto (também conhecido como spam).
Uma abordagem envolve a criação de um serviço monolítico para a criação de novas contas. Com essa abordagem, uma equipe de desenvolvimento é responsável por todo o serviço, que também é implantado como um todo. Isso dificulta a realização de experimentos e faz alterações no processo de interação do usuário com o aplicativo.
Considere a implementação do login do usuário como um pipeline de eventos de vários serviços FaaS. Com essa separação, a função de criação do usuário não faz ideia do que acontece durante o login do usuário. Ela tem duas listas:
- uma lista de ações necessárias (por exemplo, enviando um email de boas-vindas);
- uma lista de ações opcionais (por exemplo, assinando um boletim informativo).
Cada uma dessas ações também é implementada como FaaS, e a lista de ações nada mais é do que uma lista de funções de retorno de chamada HTTP. Portanto, a função de criação do usuário tem o seguinte formato:
def create_user(context): # for key, value in required.items(): call_function(value.webhook, context.json) # # for key, value in optional.items(): if context.json.get(key, None) is not None: call_function(value.webhook, context.json)
Agora, cada um dos manipuladores também pode ser implementado de acordo com o princípio FaaS:
def email_user(context): # user = context.json['username'] msg = ', {}, , !".format(user) send_email(msg, contex.json['email]) def subscribe_user(context): # email = context.json['email'] subscribe_user(email)
Decomposto dessa maneira, o serviço FaaS se torna muito mais simples, contém menos linhas de código e se concentra na implementação de uma função específica. A abordagem de microsserviço simplifica a gravação de código, mas pode levar a dificuldades na implantação e gerenciamento de três microsserviços diferentes. Aqui, a abordagem FaaS prova-se em toda a sua glória, porque como resultado de seu uso, torna-se muito simples gerenciar pequenos pedaços de código. A visualização do processo de criação de um usuário na forma de um pipeline de eventos também nos permite entender em termos gerais o que exatamente acontece quando um usuário efetua login, simplesmente rastreando a alteração no contexto de função para função dentro do pipeline.
»Mais informações sobre o livro podem ser encontradas no
site do editor»
Conteúdo»
Trecho20% de desconto em cupons para Designers -
Design patternsApós o pagamento da versão em papel do livro, uma versão eletrônica do livro é enviada por e-mail.