Olá Habr!
Eu trabalho para uma empresa de jogos que desenvolve jogos online. Atualmente, todos os nossos jogos estão divididos em muitos "mercados" (um "mercado" por país) e em cada "mercado" há uma dúzia de mundos entre os quais os jogadores são distribuídos durante o registro (bem, ou às vezes eles mesmos podem escolher). Cada mundo possui um banco de dados e um ou mais servidores de aplicativos / web. Assim, a carga é dividida e distribuída pelos mundos / servidores quase uniformemente e, como resultado, obtemos o máximo on-line de jogadores de 6K-8K (esse é o máximo, geralmente várias vezes menos) e 200 a 300 solicitações por horário nobre por mundo.
Essa estrutura com a divisão de players em mercados e mundos está se tornando obsoleta; os jogadores querem algo global. Nos últimos jogos, paramos de dividir as pessoas por país e deixamos apenas um / dois mercados (América e Europa), mas ainda com muitos mundos em cada um. O próximo passo será o desenvolvimento de jogos com uma nova arquitetura e a unificação de todos os jogadores em um único mundo com
um banco de dados .
Hoje, eu queria falar um pouco sobre como me encarregaram de verificar o que acontece se todo o online (e são de 50 a 200 mil usuários de cada vez) de um de nossos jogos populares "enviar" para jogar o próximo jogo baseado na nova arquitetura e se todo o sistema, especialmente o banco de dados (
PostgreSQL 11 ), pode suportar praticamente essa carga e, se não puder, descobrir onde está o máximo. Vou falar um pouco sobre os problemas que surgiram e as decisões de se preparar para testar tantos usuários, o próprio processo e um pouco sobre os resultados.
Introdução
No passado, na
InnoGames GmbH, cada equipe de jogo criava um projeto de jogo de acordo com o seu gosto e cor, geralmente usando diferentes tecnologias, linguagens de programação e bancos de dados. Além disso, temos muitos sistemas externos responsáveis por pagamentos, enviando notificações push, marketing e muito mais. Para trabalhar com esses sistemas, os desenvolvedores também criaram suas interfaces exclusivas da melhor maneira possível.
Atualmente, no negócio de jogos para celular, muito
dinheiro e, consequentemente, muita concorrência. Aqui é muito importante recuperar o valor de cada dólar gasto em marketing e um pouco mais acima, portanto, todas as empresas de jogos costumam "fechar" os jogos, mesmo na fase de testes fechados, se não atenderem às expectativas analíticas. Consequentemente, perder tempo com a invenção da próxima roda não é rentável, por isso foi decidido criar uma plataforma unificada que fornecerá aos desenvolvedores uma solução pronta para integração com todos os sistemas externos, um banco de dados com replicação e todas as melhores práticas. Tudo o que os desenvolvedores precisam é desenvolver e "colocar" um bom jogo em cima disso e não perder tempo com desenvolvimento não relacionado ao jogo em si.
Essa plataforma é chamada
GameStarter :

Então, direto ao ponto. Todos os futuros jogos da InnoGames serão construídos nesta plataforma, que possui dois bancos de dados - mestre e jogo (PostgreSQL 11). O Master armazena informações básicas sobre os jogadores (login, senha, etc.) e participa, principalmente, apenas do processo de login / registro no próprio jogo. Jogo - o banco de dados do próprio jogo, onde, consequentemente, todos os dados e entidades do jogo são armazenados, que é o núcleo do jogo, para onde toda a carga irá.
Assim, surgiu a questão de saber se toda essa estrutura poderia suportar um número tão potencial de usuários igual ao máximo on-line de um de nossos jogos mais populares.
Desafio
A tarefa em si era a seguinte: verificar se o banco de dados (PostgreSQL 11), com a replicação ativada, pode suportar toda a carga que atualmente temos no jogo mais carregado, tendo à sua disposição todo o hipervisor PowerEdge M630 (HV).
Esclarecerei que a tarefa no momento era
apenas verificar , usando as configurações de banco de dados existentes, que formamos, levando em consideração as práticas recomendadas e nossa própria experiência.
Eu direi imediatamente o banco de dados e todo o sistema se mostrou bem, com exceção de alguns pontos. Mas esse projeto de jogo em particular estava no estágio de protótipo e, no futuro, com a complicação da mecânica do jogo, as solicitações ao banco de dados se tornarão mais complicadas e a carga em si poderá aumentar significativamente e sua natureza poderá mudar. Para evitar isso, é necessário testar iterativamente o projeto com cada marco mais ou menos significativo. Automatizar a capacidade de executar esses tipos de testes com algumas centenas de milhares de usuários tornou-se a principal tarefa neste estágio.
Perfil
Como qualquer teste de carga, tudo começa com um perfil de carga.
Nosso valor potencial CCU60 (CCU é o número máximo de usuários por um determinado período de tempo, neste caso 60 minutos) é considerado
250.000 usuários. O número de usuários virtuais competitivos (VUs) é menor que o CCU60 e os analistas sugeriram que ele pode ser dividido com segurança em dois. Arredonde e aceite
150.000 VUs competitivas.
O número total de solicitações por segundo foi obtido de um jogo bastante carregado:
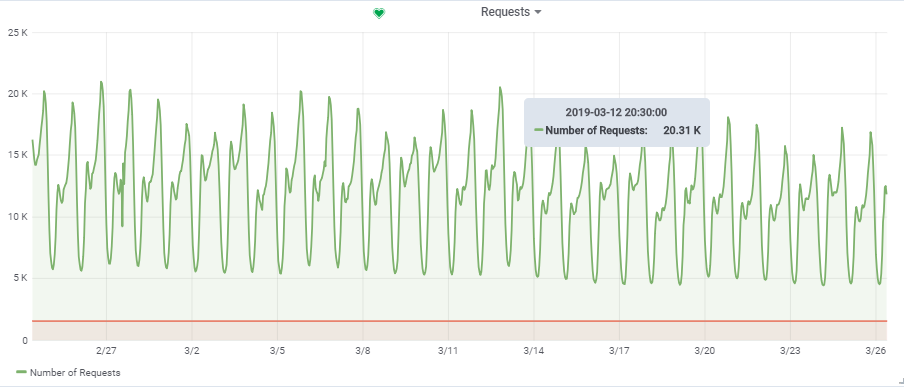
Assim, nossa carga alvo é de ~
20.000 solicitações / s a
150.000 VU.
Estrutura
Características do “stand”
Em um
artigo anterior
, eu já falei sobre como automatizar todo o processo de teste de carga. Além disso, posso me repetir um pouco, mas vou lhe contar alguns pontos com mais detalhes.

No diagrama, os quadrados azuis são nossos hipervisores (HV), uma nuvem composta por muitos servidores (Dell M620 - M640). Em cada HV, uma dúzia de máquinas virtuais (VMs) é lançada via KVM (web / app e db no mix). Ao criar qualquer nova VM, ocorre o balanceamento e a pesquisa através do conjunto de parâmetros de uma HV adequada, e ainda não se sabe em qual servidor ele estará.
Banco de Dados (DB do Jogo):
Mas, para nosso propósito db1, reservamos um
targer_hypervisor HV separado
com base no M630.
Breves características do targer_hypervisor:
Dell M_630
Nome do modelo: CPU Intel® Xeon® E5-2680 v3 a 2.50GHz
CPU (s): 48
Tópico (s) por núcleo: 2
Núcleo (s) por soquete: 12
Soquete (s): 2
RAM: 128 GB
Debian GNU / Linux 9 (esticamento)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
Especificações detalhadasDebian GNU / Linux 9 (esticamento)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
lscpu
Arquitetura: x86_64
Modo (s) operacional (s) da CPU: 32 bits, 64 bits
Ordem de bytes: Little Endian
CPU (s): 48
Lista (s) de CPU (s) on-line: 0-47
Tópico (s) por núcleo: 2
Núcleo (s) por soquete: 12
Soquete (s): 2
Nó (s) NUMA: 2
ID do fornecedor: GenuineIntel
Família de CPUs: 6
Modelo: 63
Nome do modelo: CPU Intel® Xeon® E5-2680 v3 a 2.50GHz
Passo: 2
CPU MHz: 1309.356
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4988.42
Virtualização: VT-x
Cache L1d: 32K
Cache L1i: 32K
Cache L2: 256K
Cache L3: 30720K
NUMA Nó0 CPU (s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42 44,46
CPU (s) NUMA node1: 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43 , 45,47
Sinalizadores: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constante qtsopmopcopoptsoptsoptsoptsoptsoptsopts SMX est tm2 SSSE3 sdbg fma CX16 xtpr PDCM PCID dca sse4_1 sse4_2 x2apic movbe POPCNT tsc_deadline_timer aes xsave AVX F16C rdrand lahf_lm ABM EPB invpcid_single SSBD ibrs ibpb stibp Kaiser tpr_shadow vnmi FlexPriority ept VPID fsgsbase tsc_adjust bmi1 AVX2 SMEP bmi2 erms invpcid CQM xsaveopt cqm_llc cqm_occup_llc dtherm IDA arat pln pts flush_l1d
/ usr / bin / qemu-system-x86_64 --version
Emulador QEMU versão 2.8.1 (Debian 1: 2.8 + dfsg-6 + deb9u5)
Copyright © 2003-2016 Fabrice Bellard e os desenvolvedores do Projeto QEMU
Breves características do db1:
Arquitetura: x86_64
CPU (s): 48
RAM: 64 GB
4.9.0-8-amd64 # 1 SMP Debian 4.9.144-3.1 (19/02/2019) x86_64 GNU / Linux
Debian GNU / Linux 9 (esticamento)
psql (PostgreSQL) 11.2 (Debian 11.2-1.pgdg90 + 1)
Configuração do PostgreSQL com algumas explicaçõesseq_page_cost = 1.0
random_page_cost = 1.1 # Temos SSD
inclua '/etc/postgresql/11/main/extension.conf'
log_line_prefix = '% t [% p-% l]% q% u @% h'
log_checkpoints = ativado
log_lock_waits = ativado
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10s
autovacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128MB
synchronous_commit = desativado
checkpoint_timeout = 30min
listen_addresses = '*'
work_mem = 32MB
effective_cache_size = 26214MB # 50% de memória disponível
shared_buffers = 16384MB # 25% de memória disponível
max_wal_size = 15 GB
min_wal_size = 80MB
wal_level = hot_standby
max_wal_senders = 10
wal_compression = on
archive_mode = ativado
archive_command = '/ bin / true'
archive_timeout = 1800
hot_standby = ativado
wal_log_hints = on
hot_standby_feedback = ativado
O padrão
hot_standby_feedback é desativado, nós o
ativamos , mas mais tarde ele teve que ser desativado para realizar um teste bem-sucedido. Vou explicar mais tarde o porquê.
As principais tabelas ativas no banco de dados (construção, produção, game_entity, building, core_inventory_player_resource, survivor) são pré-preenchidas com dados (aproximadamente 80 GB) usando um script bash.
Replicação:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
Servidor de aplicativos
Em seguida, em HV produtivo (prod_hypervisors) de várias configurações e capacidades, foram lançados 15 servidores de aplicativos: 8 núcleos, 4 GB. A principal coisa a ser dita: openjdk 11.0.1 16/10/2018, primavera, interação com o banco de dados via
hikari (hikari.maximum-pool-size: 50)
Ambiente de teste de estresse
Todo o ambiente de teste de carga consiste em um servidor principal
admin.loadtest e em vários servidores
generatorN.loadtest (nesse caso, havia 14).
generatorN.loadtest - VM "bare" Debian Linux 9, com Java 8. instalado 32 kernels / 32 gigabytes. Eles estão localizados no HV "não produtivo", para não prejudicar acidentalmente o desempenho de VMs importantes.
admin.loadtest - A
máquina virtual Debian Linux 9, 16 núcleos / 16 GB, Jenkins, JLTC e outros softwares sem importância adicionais trabalham nela.
JLTC -
centro de teste de carga do jmeter . Um sistema em Py / Django que controla e automatiza o lançamento de testes, bem como a análise de resultados.
Esquema de Lançamento de Teste

O processo de execução do teste é assim:
- O teste é lançado pela Jenkins . Selecione o trabalho necessário e, em seguida, você precisará inserir os parâmetros de teste desejados:
- DURATION - duração do teste
- RAMPUP - tempo de aquecimento
- THREAD_COUNT_TOTAL - o número desejado de usuários virtuais (VU) ou threads
- TARGET_RESPONSE_TIME é um parâmetro importante, para não sobrecarregar todo o sistema, definimos o tempo de resposta desejado, para que o teste mantenha a carga em um nível no qual o tempo de resposta de todo o sistema não exceda o especificado.
- Lançamento
- Jenkins clona o plano de teste do Gitlab e envia para o JLTC.
- O JLTC trabalha um pouco com um plano de teste (por exemplo, insere um gravador simples de CSV).
- O JLTC calcula o número necessário de servidores Jmeter para executar o número desejado de VUs (THREAD_COUNT_TOTAL).
- O JLTC se conecta a cada gerador loadgeneratorN e inicia o servidor jmeter.
Durante o teste, o
cliente JMeter gera um arquivo CSV com os resultados. Portanto, durante o teste, a quantidade de dados e o tamanho desse arquivo aumentam em um ritmo
insano , e não podem ser usados para análise após o teste - o
Daemon foi inventado (como um experimento), que o analisa
"em tempo real" .
Plano de teste
Você pode baixar o plano de teste
aqui .
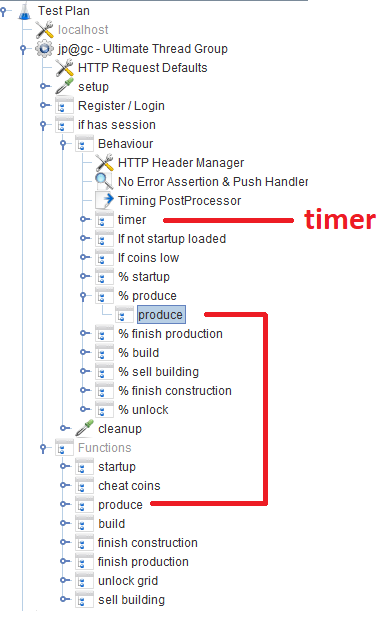
Após o registro / login, os usuários trabalham no módulo
Comportamento , que consiste em vários
controladores de taxa de
transferência que especificam a probabilidade de uma função específica do jogo. Em cada controlador de taxa de transferência, há um
controlador de módulo , que se refere ao módulo correspondente que implementa a função.
Fora do tópico
Durante o desenvolvimento do script, tentamos usar o Groovy ao máximo e, graças ao nosso programador Java, descobri alguns truques para mim (talvez seja útil para alguém):
VU / Threads
Quando um usuário digita o número desejado de VUs usando o parâmetro THREAD_COUNT_TOTAL ao configurar o trabalho no Jenkins, é necessário iniciar de alguma forma o número necessário de servidores Jmeter e distribuir o número final de VUs entre eles. Esta parte está com o JLTC na parte chamada
controlador / provisão .
Em essência, o algoritmo é o seguinte:
- Dividimos o número desejado de threads da VU em 200-300 threads e, com base no tamanho mais ou menos adequado -Xmsm -Xmxm, determinamos o valor de memória necessário por jmeter-server required_memory_for_jri (JRI - eu chamo a instância remota de Jmeter, em vez de Jmeter-server).
- Em threads_num e required_memory_for_jri, encontramos o número total de jmeter-server: target_amount_jri e o valor total da memória necessária : required_memory_total .
- Classificamos todos os geradores loadgeneratorN um por um e iniciamos o número máximo de servidores jmeter com base na memória disponível nele. Contanto que o número de instâncias current_amount_jri em execução não seja igual a target_amount_jri.
- (Se o número de geradores e a memória total não forem suficientes, adicione um novo ao pool)
- Nós nos conectamos a cada gerador, usando netstat, lembramos de todas as portas ocupadas e executamos em portas aleatórias (desocupadas) o número necessário de servidores jmeter:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- Coletamos todos os servidores jmeter em execução ao mesmo tempo no endereço de formato: port, por exemplo generator13: 15576, generator9: 14015, generator11: 19152, generator14: 12125, generator2: 17602
- A lista resultante e threads_per_host são enviados ao cliente JMeter quando o teste é iniciado:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
No nosso caso, o teste foi realizado simultaneamente a partir de 300 servidores Jmeter, 500 threads cada, o formato de inicialização de um servidor Jmeter com parâmetros Java ficou assim:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50ms
A tarefa é determinar o quanto o nosso banco de dados pode suportar, em vez de sobrecarregá-lo e todo o sistema como um todo para um estado crítico. Com tantos servidores Jmeter, você precisa, de alguma forma, manter a carga em um determinado nível e não matar o sistema inteiro. O parâmetro
TARGET_RESPONSE_TIME especificado ao iniciar o teste é responsável por isso. Concordamos que 50
ms é o tempo de resposta ideal pelo qual o sistema deve ser responsável.
No JMeter, por padrão, existem muitos timers diferentes que permitem controlar a taxa de transferência, mas não se sabe onde obtê-la no nosso caso. Mas existe o
JSR223-Timer com o qual você pode criar algo usando o
tempo de resposta atual do sistema. O cronômetro está no bloco principal de
comportamentos :

Análise dos resultados (daemon)
Além dos gráficos em Grafana, também é necessário ter resultados de teste agregados para que os testes possam ser comparados posteriormente no JLTC.
Um desses testes gera solicitações de 16 a 20k por segundo, é fácil calcular que em 4 horas gera um arquivo CSV com algumas centenas de GB de tamanho, por isso foi necessário criar um trabalho que analise dados a cada minuto, envie-o para o banco de dados e limpe o arquivo principal.
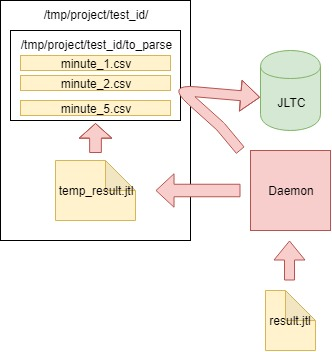
O algoritmo é o seguinte:
- Lemos os dados do arquivo CSV result.jtl gerado pelo jmeter-client, salvamos e limpamos o arquivo (você precisa limpá-lo corretamente, caso contrário, o arquivo vazio se parecerá com o FD antigo do mesmo tamanho):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- Escrevemos os dados lidos no arquivo temporário temp_result.jtl :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- Lemos o arquivo temp_result.jtl . Distribuímos os dados lidos "em minutos":
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- Os dados para cada minuto de minutes_data são gravados no arquivo correspondente na pasta to_parse / . (assim, no momento, cada minuto do teste tem seu próprio arquivo de dados, durante a agregação , não importa em que ordem os dados foram inseridos em cada arquivo):
for key, value in minutes_data.iteritems():
- Ao longo do caminho, analisamos os arquivos na pasta to_parse e, se algum deles não foi alterado em um minuto, esse arquivo é candidato à análise, agregação e envio de dados ao banco de dados JLTC:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- Se houver esses arquivos (um ou vários), então os enviaremos analisados para a função parse_csv_data (cada arquivo em paralelo):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
O próprio daemon no cron.d é iniciado a cada minuto:
daemon inicia a cada minuto com cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
Assim, o arquivo com os resultados não aumenta para tamanhos inconcebíveis, mas é analisado
em tempo real e limpo.
Resultados
O aplicativo
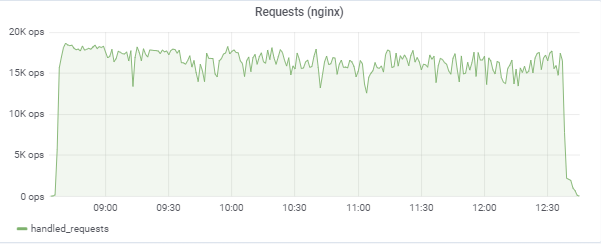
Nossos 150.000 jogadores virtuais:

O teste tenta "igualar" o tempo de resposta de 50ms, para que a própria carga salte constantemente na região entre 16k-18k solicitações / c:
Carga do servidor de aplicativos (15 app). Dois servidores são “azarados” por estarem no M620 mais lento:
Tempo de resposta do banco de dados (para servidores de aplicativos):

Banco de Dados
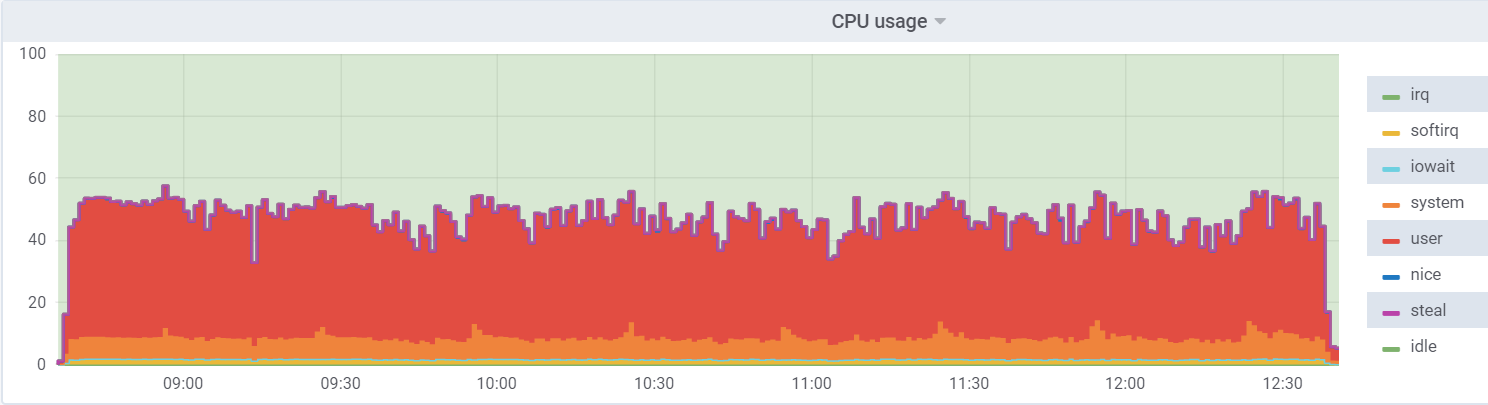
Utilitário de CPU no db1 (VM):
Utilitário de CPU no hipervisor:
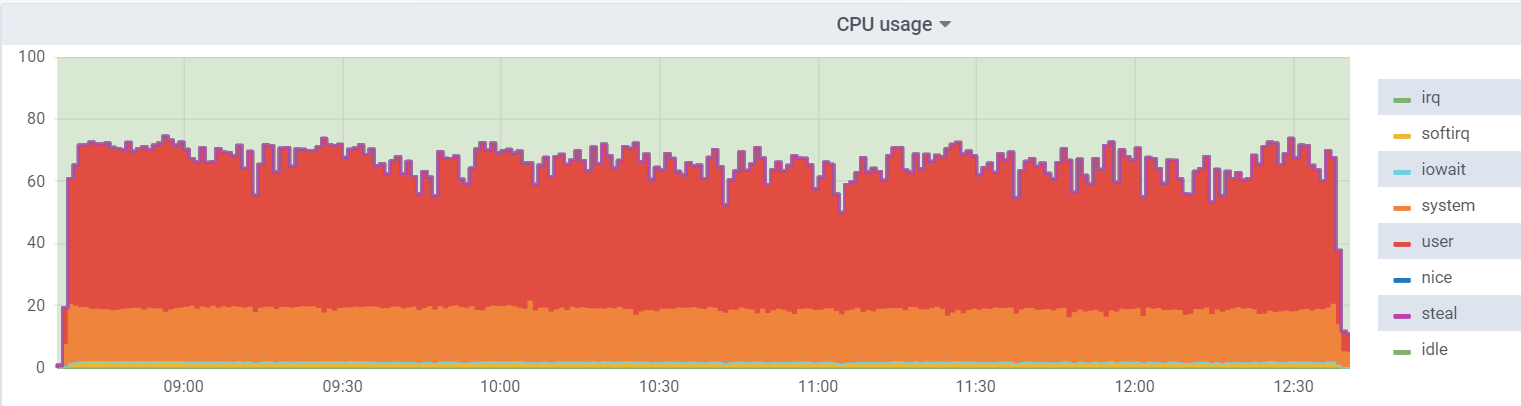
A carga na máquina virtual é menor, pois acredita que possui 48 núcleos reais à sua disposição; na verdade, existem 24 núcleos de
hyperthreading no hypervisor.
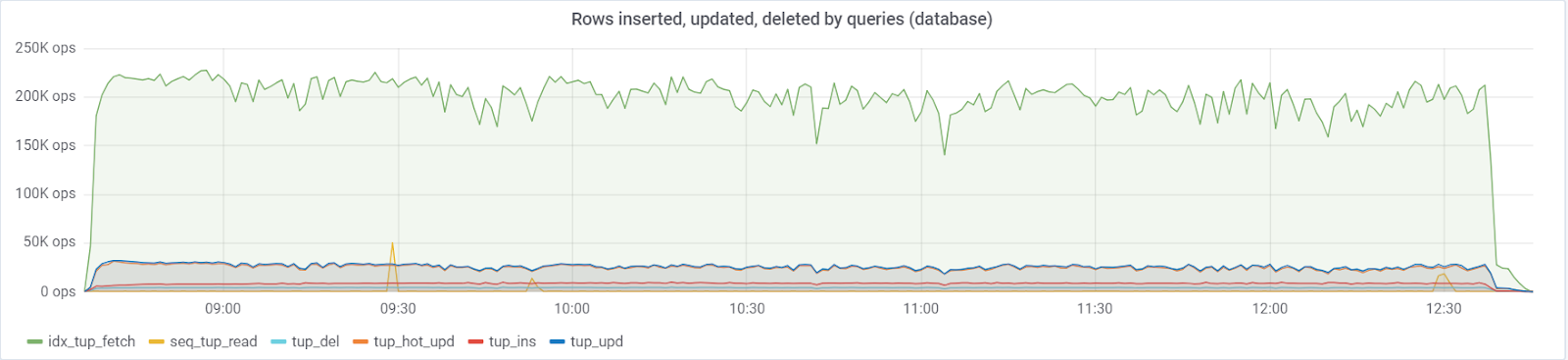
Um
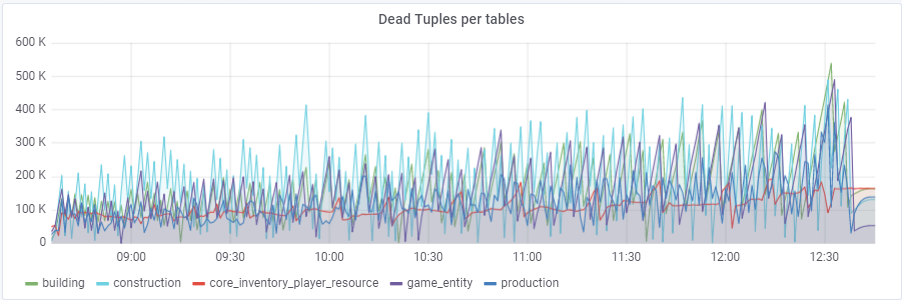
máximo de ~ 250K consultas / s vai para o banco de dados, consistindo em (83% seleciona, 3% - inserções, 11,6% - atualizações (90% HOT), 1,6% exclui):

Com um valor padrão de
autovacuum_vacuum_scale_factor = 0.2, o número de tuplas mortas cresceu muito rapidamente com o teste (com tamanhos de tabela cada vez maiores), o que levou várias vezes a problemas curtos de desempenho do banco de dados que arruinaram o teste inteiro várias vezes. Eu tive que "domesticar" esse crescimento para algumas tabelas atribuindo valores pessoais a esse parâmetro autovacuum_vacuum_scale_factor:
ALTER TABLE ... SET (autovacuum_vacuum_scale_factor = ...)Construção ALTER TABLE SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE produção SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE criando SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE criando SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE SET core_inventory_player_resource SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE sobrevivente SET (autovacuum_vacuum_scale_factor = 0,01);
ALTER TABLE sobrevivente SET (autovacuum_analyze_scale_factor = 0,01);
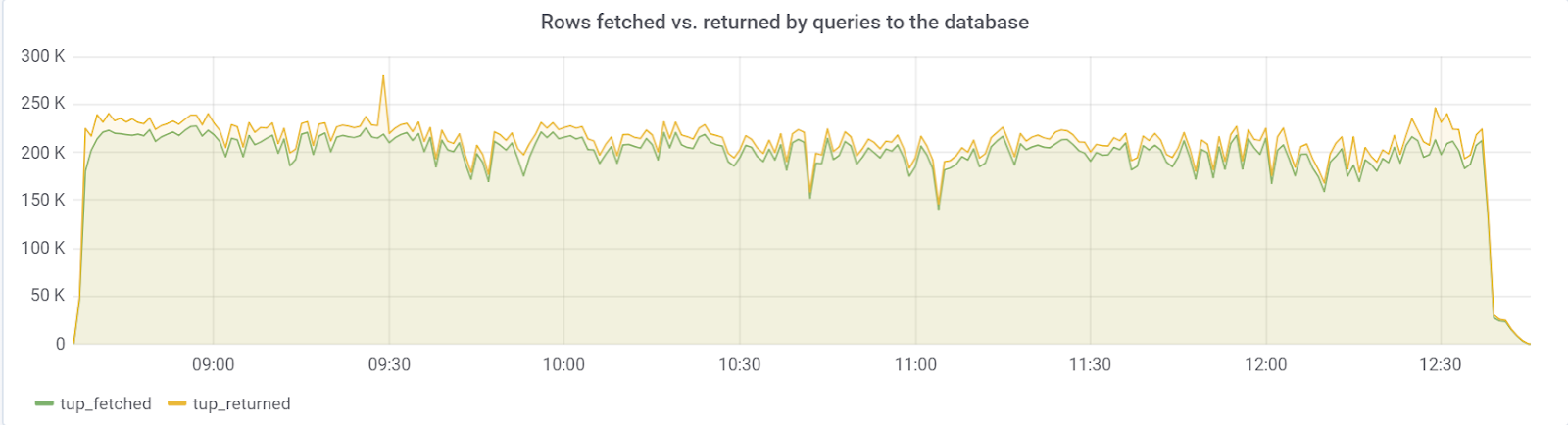
Idealmente, o número de linhas_fetch deve estar próximo do número de linhas_retornado, o que felizmente observamos:
hot_standby_feedback
O problema estava no parâmetro
hot_standby_feedback , que pode afetar bastante o desempenho do servidor
principal se os servidores em
espera não tiverem tempo para aplicar alterações nos arquivos WAL. A documentação (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) afirma que "determina se o servidor de espera ativa notificará o mestre ou escravo superior sobre as solicitações que está executando atualmente". Por padrão, está desativado, mas foi ativado em nossa configuração. O que levou a consequências tristes: se houver dois servidores em espera e o atraso na replicação durante o carregamento for diferente de zero (por vários motivos), você poderá observar uma imagem como essa, que pode levar ao colapso de todo o teste:
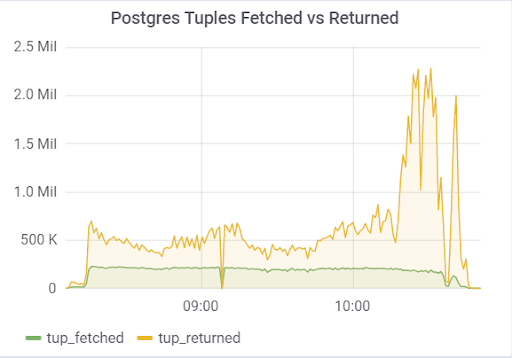

Isso ocorre porque quando hot_standby_feedback está ativado, o VACUUM não deseja excluir tuplas mortas se os servidores em espera estiverem atrasados em seu ID de transação, a fim de evitar conflitos de replicação. Artigo detalhado
O que hot_standby_feedback no PostgreSQL realmente faz :
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
Um número tão grande de tuplas mortas leva à imagem mostrada acima. Aqui estão dois testes, com hot_standby_feedback ativado e desativado:
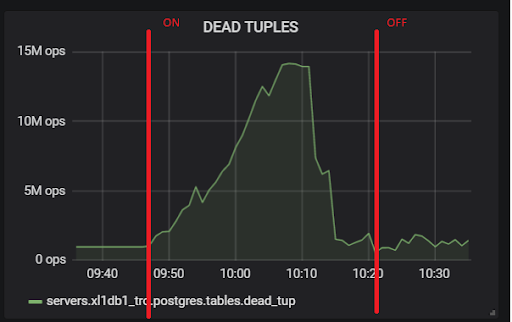
E este é o nosso atraso de replicação durante o teste, com o qual será necessário fazer algo no futuro:
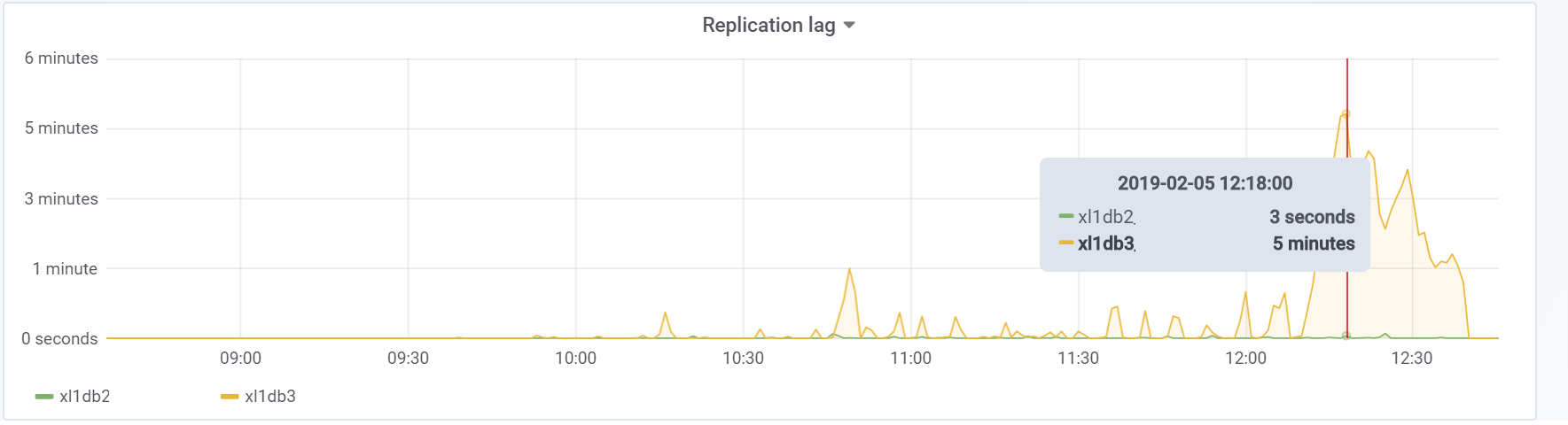
Conclusão
Felizmente, este teste (ou infelizmente para o conteúdo do artigo) mostrou que, nesta fase do protótipo do jogo, é possível sobrecarregar a carga desejada por parte dos usuários, o que é suficiente para dar luz verde para prototipagem e desenvolvimento adicionais. Nos estágios subseqüentes do desenvolvimento, é necessário seguir as regras básicas (para manter a simplicidade das consultas executadas, evitar uma superabundância de índices, além de leituras não indexadas etc.) e, o mais importante, testar o projeto em cada estágio significativo do desenvolvimento para encontrar e corrigir problemas. pode ser mais cedo. Talvez em breve escreverei um artigo, pois já resolvemos problemas específicos.
Boa sorte a todos!
Nosso
GitHub apenas no caso;)