
O banco de dados de séries temporais (TSDB) no Prometheus 2 é um ótimo exemplo de solução de engenharia que oferece grandes melhorias em relação ao armazenamento v2 no Prometheus 1 em termos de velocidade de armazenamento de dados e execução de consultas, eficiência de recursos. Implementamos o Prometheus 2 no Percona Monitoring and Management (PMM) e tive a oportunidade de entender o desempenho do Prometheus 2 TSDB. Neste artigo, falarei sobre os resultados dessas observações.
Carga de trabalho média do Prometheus
Para aqueles que estão acostumados a lidar com bancos de dados primários, a carga de trabalho regular do Prometheus é bastante curiosa. A velocidade da acumulação de dados tende a um valor estável: geralmente os serviços que você monitora enviam aproximadamente o mesmo número de métricas, e a infraestrutura muda relativamente lentamente.
Os pedidos de informações podem vir de diferentes fontes. Alguns deles, como alertas, também buscam um valor estável e previsível. Outros, como consultas de usuários, podem causar picos, embora isso não seja típico na maior parte da carga.
Teste de carga
Durante o teste, concentrei-me na capacidade de acumular dados. Implantei o Prometheus 2.3.2 compilado com o Go 1.10.1 (como parte do PMM 1.14) no serviço Linode usando este script:
StackScript . Para a geração de carga mais realista, usando esse
StackScript, lancei vários nós do MySQL com uma carga real (Sysbench TPC-C Test), cada um deles emulando 10 nós do Linux / MySQL.
Todos os testes a seguir foram realizados em um servidor Linode com oito núcleos virtuais e 32 GB de memória, nos quais foram iniciadas 20 simulações de carga de monitoramento de duzentas instâncias do MySQL. Ou, em termos de Prometheus, 800 destinos, 440 rastreios por segundo, 380 mil amostras por segundo e 1,7 milhão de séries temporais ativas.
Desenho
A abordagem usual dos bancos de dados tradicionais, incluindo o usado pelo Prometheus 1.x, é
o limite de memória . Se não for suficiente para suportar a carga, você encontrará grandes atrasos e algumas solicitações não serão atendidas.
O uso da memória no Prometheus 2 é configurado usando a chave
storage.tsdb.min-block-duration , que determina por quanto tempo os registros serão armazenados na memória antes da liberação para o disco (por padrão, são 2 horas). A quantidade de memória necessária dependerá do número de séries temporais, rótulos e da intensidade da coleta de dados (raspas) no total com o fluxo de entrada líquido. Em termos de espaço em disco, o Prometheus pretende usar 3 bytes por registro (amostra). Por outro lado, os requisitos de memória são muito maiores.
Apesar de ser possível configurar o tamanho do bloco, não é recomendável configurá-lo manualmente, para que você precise dar ao Prometheus a quantidade de memória necessária para a sua carga.
Se não houver memória suficiente para suportar o fluxo de métricas recebidas, o Prometheus ficará sem memória ou o killer do OOM alcançará.
Adicionar swap para atrasar a falha quando o Prometheus ficar sem memória realmente não ajuda, porque o uso desse recurso causa um consumo explosivo de memória. Eu acho que o problema é o Go, seu coletor de lixo e como ele funciona com o swap.
Outra abordagem interessante é definir o bloco principal a ser redefinido para o disco em um horário específico, em vez de contá-lo desde o início do processo.
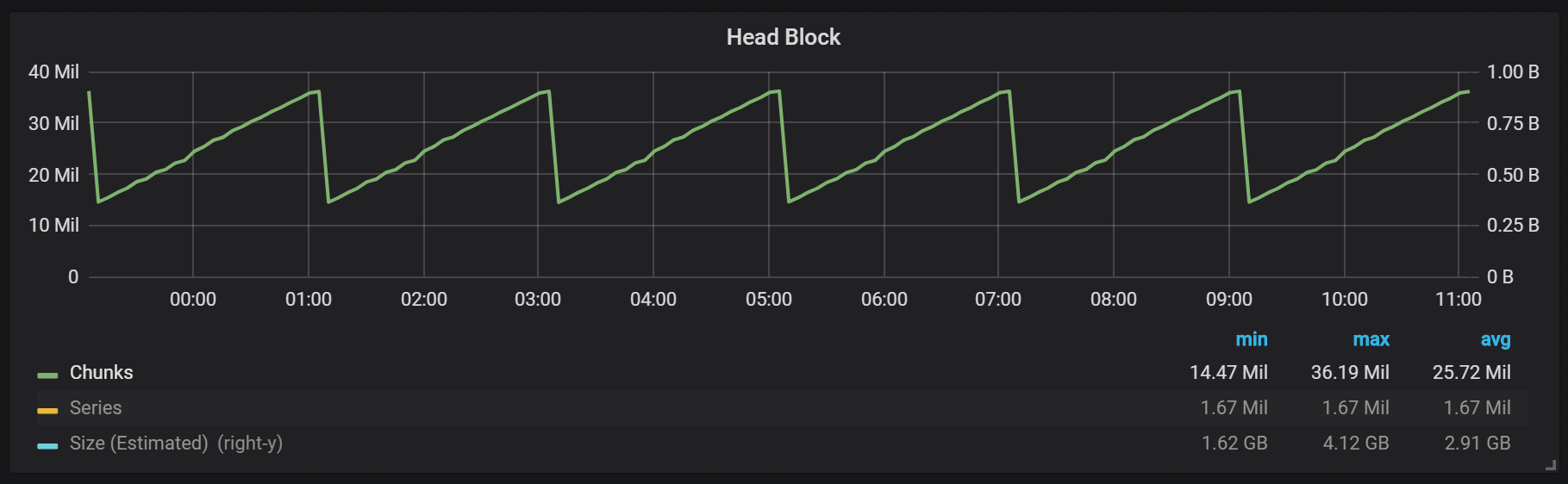
Como você pode ver no gráfico, as descargas de disco ocorrem a cada duas horas. Se você alterar o parâmetro min-block-duration para uma hora, essas descargas ocorrerão a cada hora, começando em meia hora.
Se você quiser usar esse e outros gráficos na instalação do Prometheus, poderá usar este painel . Foi desenvolvido para PMM, mas, com pequenas modificações, é adequado para qualquer instalação do Prometheus.Temos um bloco ativo chamado bloco de cabeça, que é armazenado na memória; blocos com dados mais antigos são acessíveis através do
mmap() . Isso elimina a necessidade de configurar o cache separadamente, mas também significa que você precisa deixar espaço suficiente para o cache do sistema operacional se desejar fazer solicitações de dados mais antigas que o bloco principal.
Isso também significa que o consumo de memória virtual do Prometheus parecerá bastante alto, o que não vale a pena se preocupar.

Outro ponto de design interessante é o uso do WAL (escrever com antecedência). Como você pode ver na documentação de armazenamento, o Prometheus usa o WAL para evitar perdas devido a quedas. Os mecanismos específicos para garantir a capacidade de sobrevivência dos dados, infelizmente, não estão bem documentados. A versão 2.3.2 do Prometheus libera o WAL para o disco a cada 10 segundos e esse parâmetro não é configurável pelo usuário.
Selos (Compactação)
O Prometheus TSDB foi projetado à imagem de um repositório LSM (mesclagem de log estruturada - uma árvore estruturada em log com mesclagem): o bloco principal é periodicamente liberado para o disco, enquanto o mecanismo de compactação combina vários blocos para impedir a varredura de muitos blocos durante as solicitações. Aqui você pode ver o número de blocos que observei no sistema de teste após um dia de trabalho.
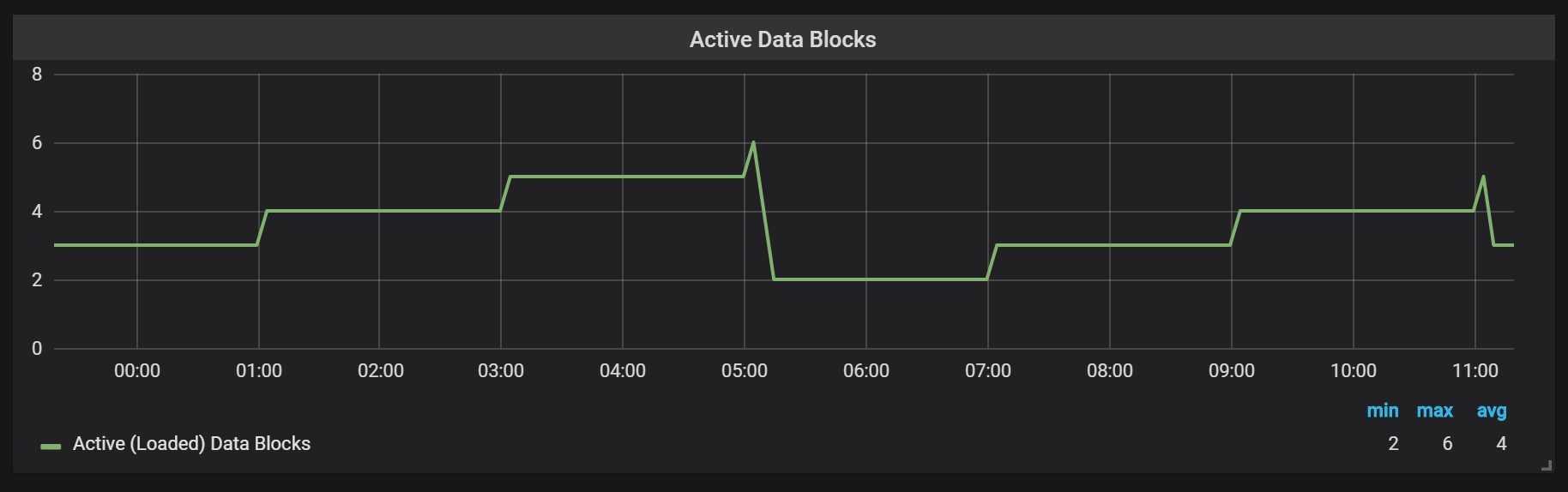
Se você quiser saber mais sobre o repositório, pode estudar o arquivo meta.json, que contém informações sobre os blocos disponíveis e como eles apareceram.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
Os selos em Prometeu estão ligados ao momento em que um bloco de cabeça foi liberado para o disco. Nesse ponto, várias dessas operações podem ser executadas.
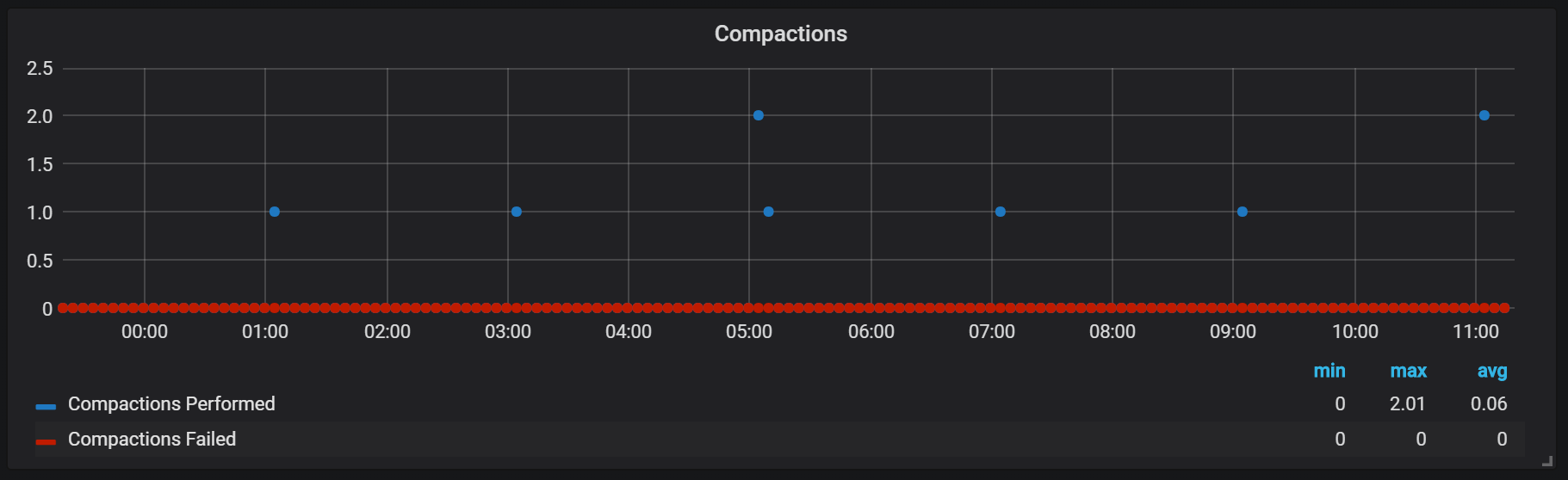
Aparentemente, os selos são ilimitados de qualquer forma e podem causar grandes saltos de E / S de disco em tempo de execução.

Picos de download da CPU

Obviamente, isso afeta negativamente a velocidade do sistema e também é um sério desafio para o armazenamento LSM: como fazer selos para suportar altas velocidades de consulta e não causar muita sobrecarga?
O uso da memória no processo de compactação também parece bastante interessante.

Podemos ver como, após a compactação, a maioria da memória muda de estado de Cache para Livre: significa que informações potencialmente valiosas foram removidas de lá. É curioso saber se o
fadvice() ou alguma outra técnica de minimização é usada aqui ou é causada pelo fato de o cache ter sido liberado dos blocos destruídos durante a compactação?
Recuperação de falha
A recuperação de desastres leva tempo e é justificada. Para um fluxo de entrada de um milhão de registros por segundo, tive que esperar cerca de 25 minutos enquanto a recuperação era realizada, levando em consideração a unidade SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
O principal problema do processo de recuperação é alto consumo de memória. Apesar do fato de que, em uma situação normal, o servidor pode funcionar de maneira estável com a mesma quantidade de memória, quando falha, ele não pode aumentar devido ao OOM. A única solução que encontrei foi desativar a coleta de dados, aumentar o servidor, permitir a recuperação e a reinicialização com a coleção já ativada.
Aquecer
Outro comportamento que deve ser lembrado durante o aquecimento é a proporção de baixa produtividade e alto consumo de recursos logo após o início. Durante algumas partidas, mas nem todas, observei uma carga séria na CPU e na memória.
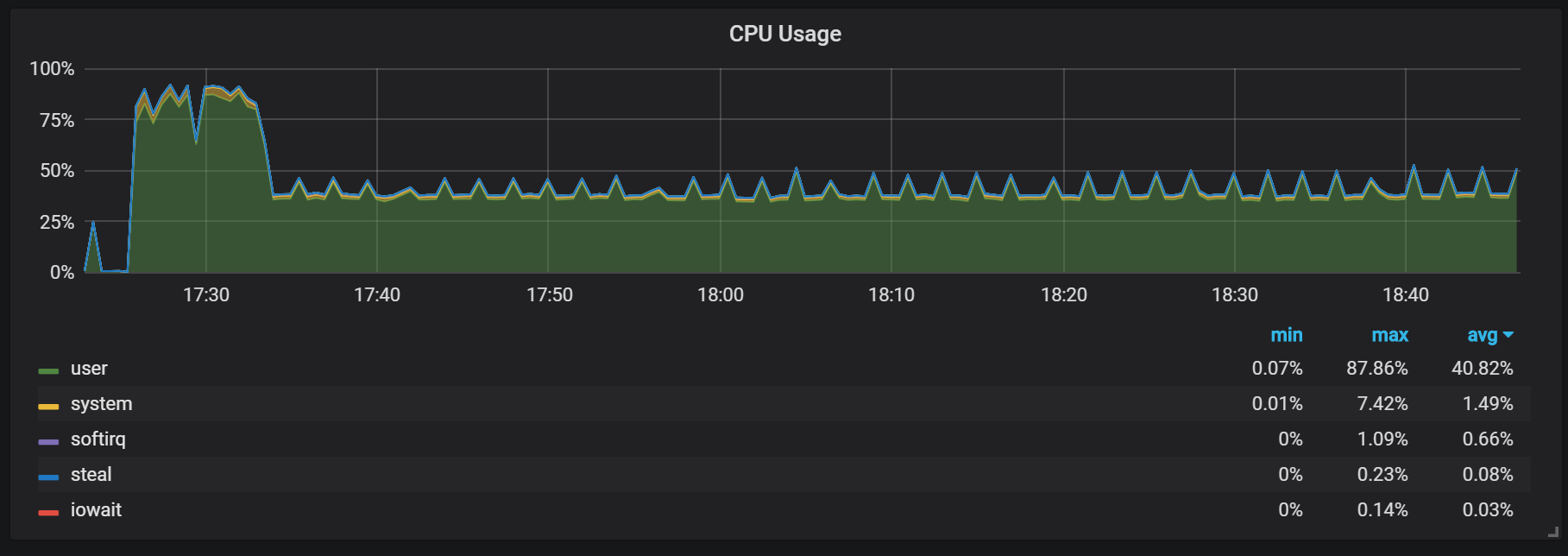

Os lapsos de memória indicam que o Prometheus não pode configurar todas as cobranças desde o início e algumas informações são perdidas.
Não descobri os motivos exatos para a alta carga no processador e na memória. Suspeito que isso se deva à criação de novas séries temporais no bloco principal com alta frequência.
Picos de carga da CPU
Além dos selos, que criam uma carga de E / S bastante alta, notei saltos graves na carga no processador a cada dois minutos. As explosões duram mais com um fluxo de entrada alto e parece que elas são causadas pelo coletor de lixo Go, pelo menos alguns kernels estão totalmente carregados.

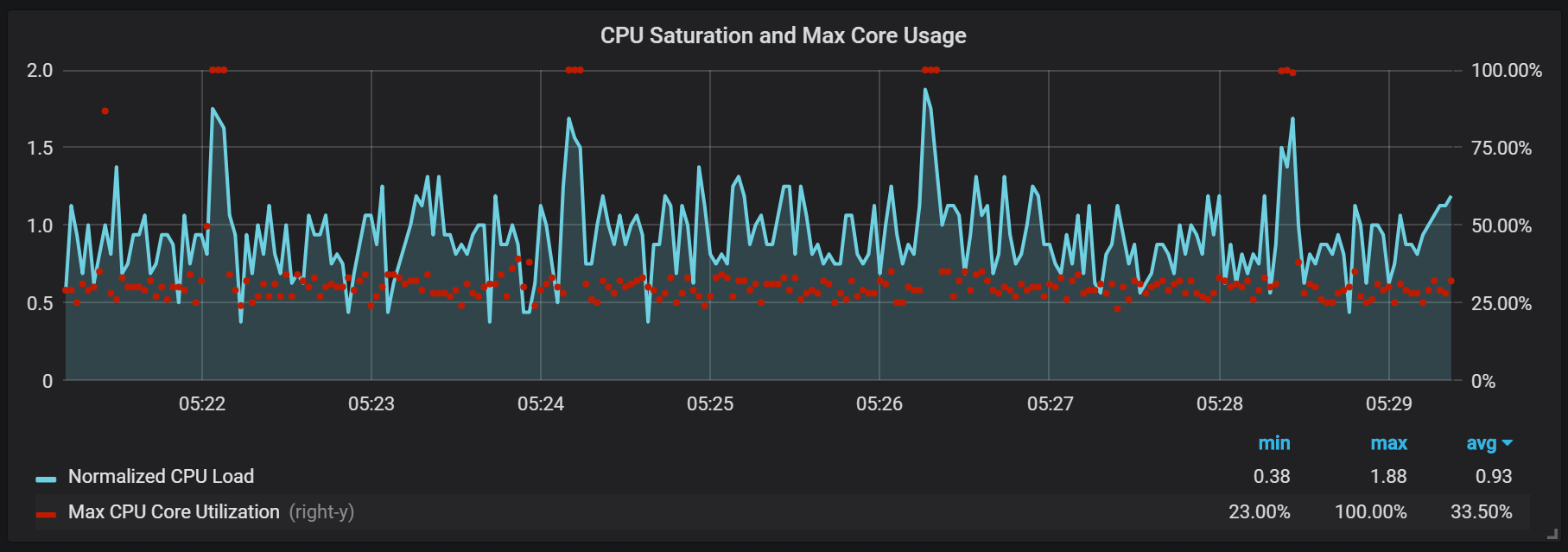
Esses saltos não são tão insignificantes. Parece que, quando ocorrem, o ponto de entrada interno e as métricas do Prometheus se tornam inacessíveis, o que causa lacunas de dados nos mesmos intervalos de tempo.
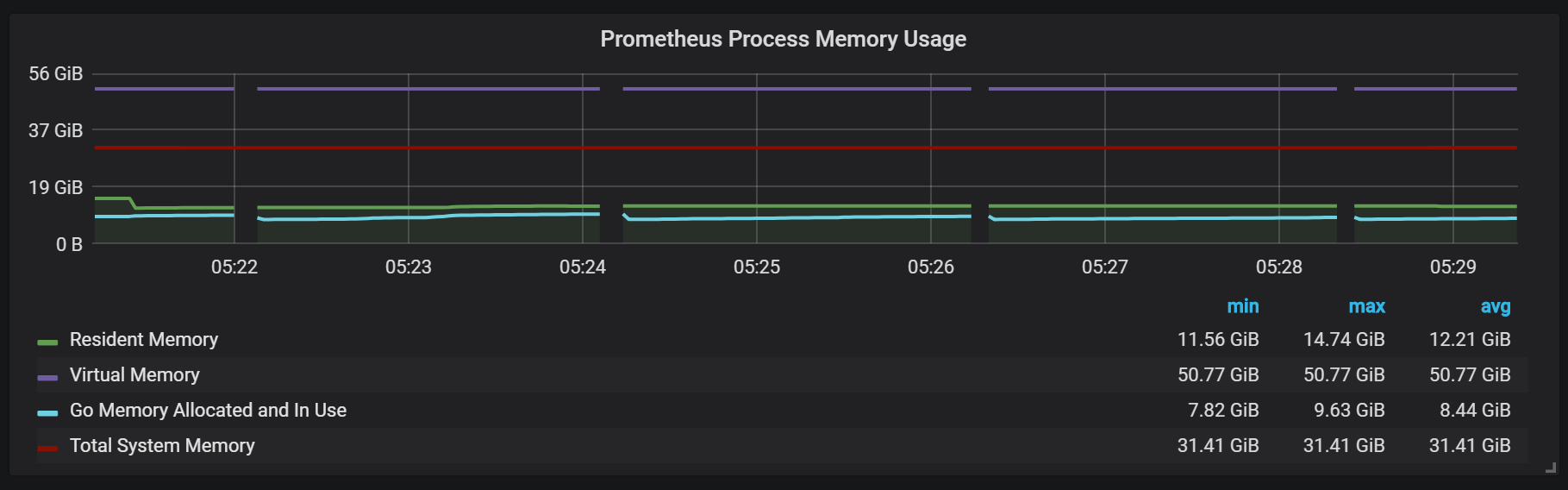
Você também pode perceber que o exportador de Prometheus é desligado por um segundo.
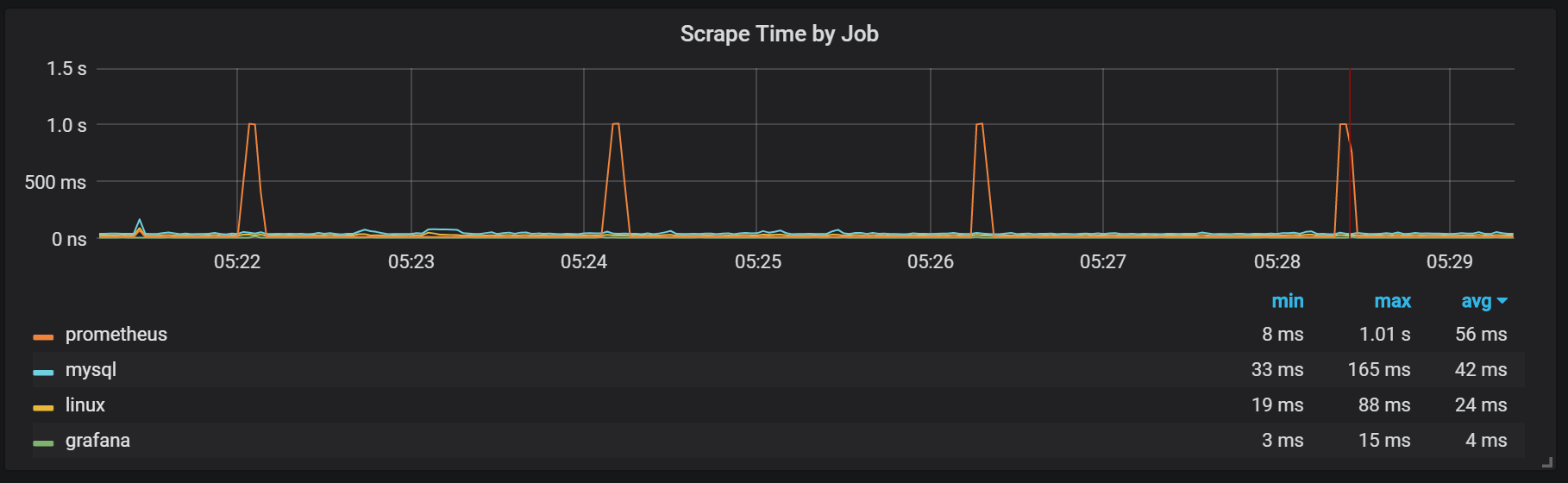
Podemos ver correlações com a coleta de lixo (GC).

Conclusão
O TSDB no Prometheus 2 é rápido, capaz de lidar com milhões de séries temporais e ao mesmo tempo com milhares de gravações por segundo usando hardware bastante modesto. A utilização da E / S da CPU e do disco também é impressionante. Meu exemplo mostrou até 200.000 métricas por segundo por núcleo usado.
Para planejar a extensão, você precisa se lembrar de volumes de memória suficientes, e isso deve ser memória real. A quantidade de memória usada que observei foi de cerca de 5 GB por 100.000 entradas por segundo do fluxo recebido, que combinado com o sistema operacional armazenava em cache cerca de 8 GB de memória ocupada.
Obviamente, ainda há muito trabalho para domar as explosões de E / S de CPU e disco, e isso não é surpreendente, dado o quão jovem o TSDB Prometheus 2 é comparado ao InnoDB, TokuDB, RocksDB, WiredTiger, mas todos tiveram problemas semelhantes no início do ciclo de vida.