
A lógica das máquinas é impecável, elas não cometem erros se seu algoritmo funcionar corretamente e os parâmetros definidos corresponderem aos padrões necessários. Peça ao carro para escolher uma rota do ponto A ao ponto B, e ele criará o melhor, levando em consideração a distância, o consumo de combustível, a presença de postos de gasolina, etc. Este é um cálculo puro. O carro não dirá: "Vamos por essa estrada, sinto essa rota melhor". Talvez os carros sejam melhores que nós na velocidade dos cálculos, mas a intuição ainda é um dos nossos trunfos. A humanidade passou décadas criando uma máquina semelhante ao cérebro humano. Mas há muito em comum entre eles? Hoje consideraremos um estudo em que os cientistas, duvidando da inigualável "visão" da máquina com base em redes neurais convolucionais, conduziram um experimento para enganar um sistema de reconhecimento de objetos usando um algoritmo cuja tarefa era criar imagens "falsas". Quão bem-sucedida foi a atividade de sabotagem do algoritmo, as pessoas lidaram com o reconhecimento melhor do que os carros e o que esse estudo trará para o futuro dessa tecnologia? Encontraremos respostas no relatório dos cientistas. Vamos lá
Base de estudo
As tecnologias de reconhecimento de objetos que utilizam redes neurais convolucionais (SNS) permitem à máquina, grosso modo, distinguir um cisne do número 9 ou um gato de uma bicicleta. Essa tecnologia está se desenvolvendo rapidamente e atualmente está sendo aplicada em vários campos, o mais óbvio dos quais é a produção de veículos não tripulados. Muitos são da opinião de que o SNA do sistema de reconhecimento de objetos pode ser considerado um modelo de visão humana. No entanto, esta afirmação é muito alta, devido ao fator humano. O fato é que enganar um carro acabou sendo mais fácil do que enganar uma pessoa (pelo menos em questões de reconhecimento de objetos). Os sistemas SNA são muito vulneráveis aos efeitos de algoritmos maliciosos (hostis, se você desejar), que de todas as maneiras os impedirão de executar corretamente sua tarefa, criando imagens que serão classificadas incorretamente pelo sistema SNA.
Os pesquisadores dividem essas imagens em duas categorias: “enganar” (mudar completamente o alvo) e “embaraçoso” (mudar parcialmente o alvo). As primeiras são imagens sem sentido que são reconhecidas pelo sistema como algo familiar. Por exemplo, um conjunto de linhas pode ser classificado como "beisebol" e ruído digital multicolorido como "tatu". A segunda categoria de imagens ("embaraçosas") são imagens que, em condições normais, seriam classificadas corretamente, mas o algoritmo malicioso as distorce levemente, exagerando dizendo, aos olhos do sistema SNA. Por exemplo, o número manuscrito 6 será classificado como número 5 devido a um pequeno complemento de vários pixels.
Imagine o mal que esses algoritmos podem causar. Vale a pena trocar a classificação dos sinais de trânsito por transporte autônomo e acidentes serão inevitáveis.
Abaixo estão as imagens "falsas" que enganam o sistema SNA, treinadas para reconhecer objetos, e como um sistema semelhante os classificou.
 Imagem Nº 1
Imagem Nº 1Explicação da série:
- e - imagens "fraudulentas" codificadas indiretamente;
- b - imagens "fraudulentas" codificadas diretamente;
- c - imagens “embaraçosas”, forçando o sistema a classificar um dígito como outro;
- d - O ataque ao LaVAN (ruído adversário / malicioso localizado e visível) pode levar a uma classificação incorreta, mesmo quando o "ruído" está localizado apenas em um ponto (no canto inferior direito).
- e - objetos tridimensionais classificados incorretamente de diferentes ângulos.
O mais curioso disso é que uma pessoa pode não sucumbir a enganar um algoritmo malicioso e classificar as imagens corretamente, com base na intuição. Anteriormente, como dizem os cientistas, ninguém fez uma comparação prática das habilidades de uma máquina e de uma pessoa em um experimento para combater algoritmos maliciosos de imagens falsas. Foi isso que os pesquisadores decidiram fazer.
Para isso, foram preparadas várias imagens feitas por algoritmos maliciosos. Os sujeitos foram informados de que a máquina classificou essas imagens (frontal) como objetos familiares, ou seja, a máquina não os reconheceu corretamente. A tarefa dos sujeitos era determinar exatamente como a máquina classificou essas imagens, ou seja, o que eles acham que a máquina viu nas imagens, essa classificação é verdadeira etc.
Foram realizadas 8 experiências, nas quais foram utilizados 5 tipos de imagens maliciosas criadas sem levar em consideração a visão humana. Em outras palavras, eles são criados por máquina para máquinas. Os resultados dessas experiências foram muito divertidos, mas não os estragamos e consideramos tudo em ordem.
Resultados da Experiência
Experiência nº 1: enganando imagens com tags inválidas
No primeiro experimento, 48 imagens enganadas foram usadas, criadas pelo algoritmo para combater o sistema de reconhecimento baseado no SNA chamado AlexNet. Este sistema classificou essas imagens como “engrenagem” e “rosquinha” (
2a ).
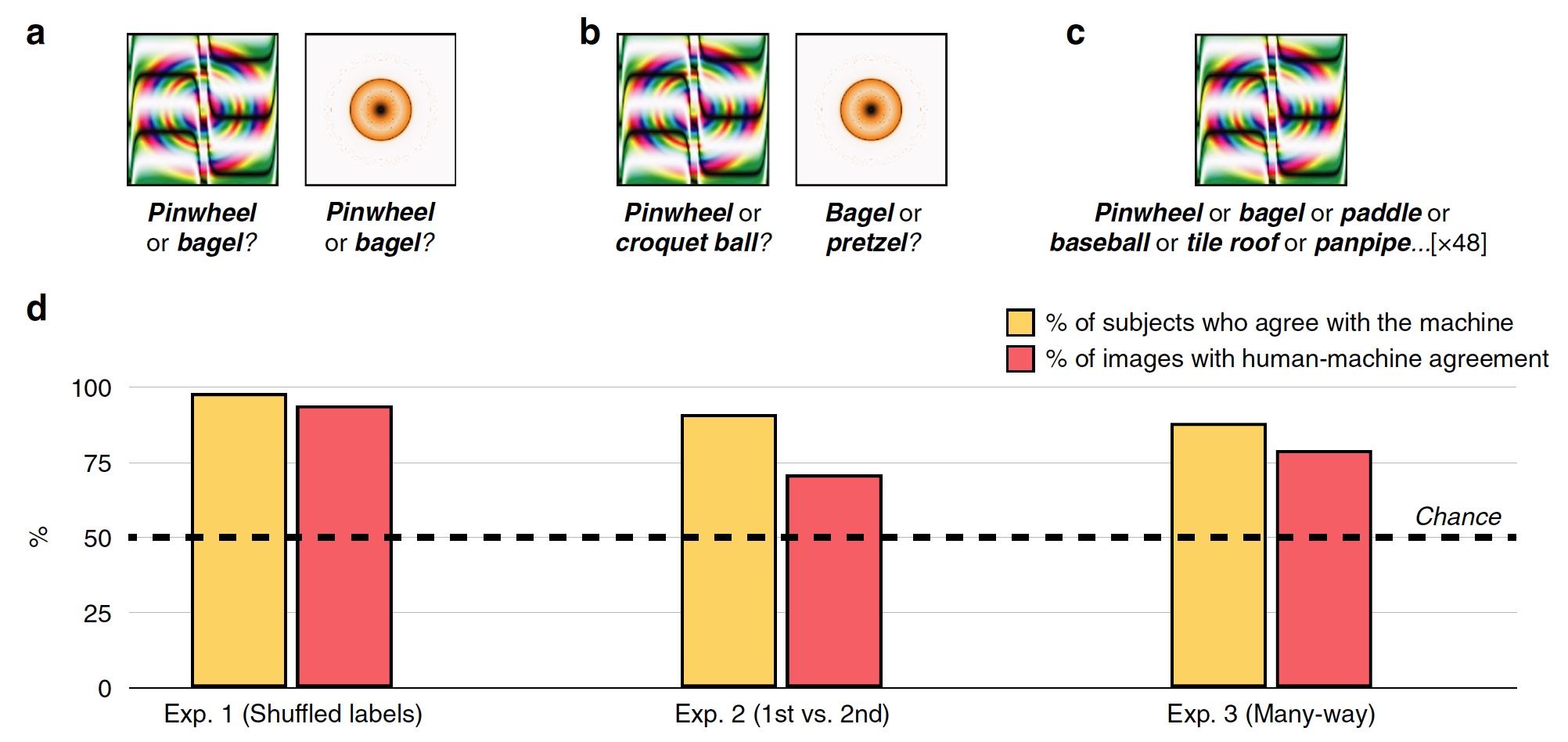 Imagem No. 2
Imagem No. 2Durante cada tentativa, a pessoa do teste, dos quais havia 200, viu uma imagem enganadora e duas marcas, ou seja, etiquetas de classificação: etiqueta do sistema SNS e aleatória das outras 47 imagens. Os sujeitos tiveram que escolher o rótulo que foi criado pela máquina.
Como resultado, a maioria dos sujeitos optou por escolher um rótulo criado pela máquina, em vez de um rótulo de um algoritmo malicioso. Precisão da classificação, ou seja, o grau de consentimento do sujeito com a máquina foi de 74%. Estatisticamente, 98% dos sujeitos escolheram etiquetas de máquinas em um nível superior ao aleatório estatístico (
2d , "% dos sujeitos concorda com a máquina"). 94% das imagens mostraram um alinhamento homem-máquina muito alto, ou seja, de 48, apenas 3 imagens foram classificadas por pessoas de maneira diferente de uma máquina.
Assim, os sujeitos mostraram que uma pessoa é capaz de compartilhar uma imagem real e um tolo, ou seja, agir de acordo com um programa baseado no SNA.
Experiência nº 2: primeira escolha versus segunda
Os pesquisadores fizeram a pergunta - devido a quais sujeitos foram capazes de reconhecer imagens tão bem e separá-las de marcas erradas e imagens enganadoras? Talvez os sujeitos tenham notado o anel amarelo-alaranjado como uma "rosquinha", porque na realidade a rosquinha é exatamente dessa forma e tem a mesma cor. Em reconhecimento, associações e escolhas intuitivas baseadas em experiência e conhecimento podem ajudar uma pessoa.
Para verificar isso, o rótulo aleatório foi substituído pelo que foi selecionado pela máquina como a segunda opção de classificação possível. Por exemplo, a AlexNet classificou o anel amarelo-alaranjado como um "donut" e a segunda opção para este programa foi "pretzel".
Os sujeitos foram confrontados com a tarefa de escolher a primeira marca da máquina ou a que ocupava o segundo lugar nas 48 imagens (
2s ).
O gráfico no centro da imagem
2d mostra os resultados deste teste: 91% dos sujeitos escolheram a primeira versão do rótulo e o nível de correspondência homem-máquina foi de 71%.
Experiência nº 3: classificação multithread
As experiências descritas acima são bastante simples, tendo em vista que os sujeitos podem escolher entre duas respostas possíveis (etiqueta de máquina e etiqueta aleatória). De fato, a máquina no processo de reconhecimento de imagem percorre centenas e até milhares de opções de etiquetas antes de escolher a mais adequada.
Neste teste, todas as notas para 48 imagens estavam imediatamente na frente dos sujeitos. Eles tiveram que escolher deste conjunto o mais adequado para cada imagem.
Como resultado, 88% dos sujeitos escolheram exatamente os mesmos rótulos da máquina e o grau de coordenação foi de 79%. Um fato interessante é que, mesmo ao escolher a etiqueta errada que a máquina escolheu, os assuntos em 63% desses casos escolheram uma das 5 principais etiquetas. Ou seja, todas as marcas no carro são ordenadas em uma lista da mais adequada à mais inadequada (exemplo exagerado: "bagel", "pretzel", "anel de borracha", "pneu" etc. etc. até "falcão no céu noturno" )
Experiência nº 3b: "o que é isso?"
Neste teste, os cientistas mudaram ligeiramente as regras. Em vez de pedir que eles “adivinhem” qual rótulo a máquina escolherá para uma imagem em particular, os participantes foram simplesmente questionados sobre o que viram na frente deles.
Os sistemas de reconhecimento baseados em redes neurais convolucionais selecionam o rótulo apropriado para uma imagem específica. Este é um processo bastante claro e lógico. Neste teste, os sujeitos exibem pensamento intuitivo.
Como resultado, 90% dos sujeitos escolheram uma etiqueta, que também foi escolhida pela máquina. O alinhamento homem-máquina entre as imagens foi de 81%.
Experiência 4: Ruído estático na televisão
Os cientistas observam que em experimentos anteriores, as imagens são incomuns, mas possuem características distintas que podem levar os indivíduos a fazer a escolha certa (ou errada) do rótulo. Por exemplo, a imagem “beisebol” não é uma bola, mas existem linhas e cores presentes em uma bola de beisebol real. Esta é uma característica distintiva impressionante. Mas se a imagem não possui essas características, mas é essencialmente ruído estático, uma pessoa pode reconhecer pelo menos alguma coisa nela? Foi isso que foi decidido verificar.
 Imagem No. 3a
Imagem No. 3aNesse teste, havia 8 imagens com estática na frente dos sujeitos, que o sistema SNS reconhece como um objeto específico (por exemplo, um pássaro-zaryanka). Além disso, na frente dos sujeitos havia um rótulo e imagens normais relacionadas a ele (8 imagens estáticas, 1 rótulo “zaryanka” e 5 fotos desta ave). O sujeito do teste teve que selecionar 1 de 8 imagens estáticas que melhor se adequam a uma ou outra etiqueta.
Você pode testar a si mesmo. Acima, você vê um exemplo desse teste. Qual das três imagens é mais adequada para a tag "zaryanka" e por quê?
81% dos sujeitos escolheram o rótulo que a máquina escolheu. Ao mesmo tempo, 75% das imagens foram rotuladas pelos sujeitos com a etiqueta mais adequada na opinião da máquina (de várias opções, como mencionamos anteriormente).
Para este teste em particular, você pode ter perguntas, como a minha. O fato é que, na estatística proposta (acima), eu pessoalmente vejo três características pronunciadas que as distinguem umas das outras. E apenas em uma imagem, esse recurso se parece muito com o mesmo zaryanka (acho que você entende qual imagem dos três). Portanto, minha opinião pessoal e muito subjetiva é que esse teste não é particularmente indicativo. Embora talvez entre outras opções para imagens estáticas sejam realmente indistinguíveis e irreconhecíveis.
Experiência nº 5: números "duvidosos"
Os testes descritos acima foram baseados em imagens que não podem ser imediatamente completas e sem uma gota de dúvida classificada como um ou outro objeto. Sempre há uma fração de dúvida. As imagens enganadoras são bastante diretas em seu trabalho - estragar a imagem além do reconhecimento. Mas existe um segundo tipo de algoritmo malicioso que adiciona (ou remove) apenas um pequeno detalhe na imagem, que pode violar completamente o sistema de reconhecimento pelo sistema SNA. Adicione alguns pixels e o número 6 magicamente se transforma no número 5 (
1s ).
Os cientistas consideram esses algoritmos um dos mais perigosos. Você pode alterar levemente a etiqueta da imagem e o veículo não tripulado considera incorretamente o sinal de limite de velocidade (por exemplo, 75 em vez de 45), o que pode levar a conseqüências tristes.
 Imagem # 3b
Imagem # 3bNeste teste, os cientistas sugeriram que os sujeitos escolhessem a resposta errada, mas a resposta errada. No teste, foram usadas 100 imagens digitais alteradas por um algoritmo malicioso (o LeNet SNA mudou sua classificação, ou seja, o algoritmo malicioso funcionou com sucesso). Os sujeitos tinham que dizer qual era a opinião da máquina. Como esperado, 89% dos sujeitos concluíram com sucesso este teste.
Experiência 6: fotos e "distorção" localizada
Os cientistas observam que não apenas os sistemas de reconhecimento de objetos estão sendo desenvolvidos, mas também algoritmos maliciosos que os impedem de fazer isso. Anteriormente, para que a imagem fosse classificada incorretamente, era necessário distorcer (alterar, excluir, danificar etc.) 14% de todos os pixels na imagem de destino. Agora, esse número se tornou muito menor. Basta adicionar uma pequena imagem dentro do alvo e a classificação será violada.
 Imagem No. 4
Imagem No. 4Nesse teste, foi usado um algoritmo LaVAN mal-intencionado bastante novo, que coloca uma pequena imagem localizada em um ponto da foto de destino. Como resultado, o sistema de reconhecimento de objetos pode reconhecer o trem do metrô como uma lata de leite (
4a ). Os recursos mais significativos desse algoritmo são precisamente a pequena proporção de pixels danificados (apenas 2%) da imagem de destino e a ausência da necessidade de distorcê-la em sua totalidade ou a parte principal (mais significativa) dela.
No teste, 22 imagens danificadas pelo LaVAN foram usadas (o sistema de reconhecimento SNA Inception V3 foi invadido com sucesso por esse algoritmo). Os sujeitos deveriam classificar a inserção maliciosa na foto. 87% dos sujeitos foram capazes de fazer isso com sucesso.
Experiência 7: objetos tridimensionais
As imagens que vimos anteriormente são bidimensionais, como qualquer foto, foto ou recorte de jornal. A maioria dos algoritmos maliciosos manipula com êxito apenas essas imagens. No entanto, essas pragas podem funcionar apenas sob certas condições, ou seja, possuem várias limitações:
- complexidade: apenas imagens bidimensionais;
- aplicação prática: alterações maliciosas são possíveis apenas em sistemas que lêem as imagens digitais recebidas, e não imagens de sensores e sensores;
- estabilidade: um ataque malicioso perde força se você girar uma imagem bidimensional (redimensionar, recortar, afiar etc.);
- pessoas: vemos o mundo e os objetos ao nosso redor em 3D em diferentes ângulos, iluminação e não na forma de imagens digitais bidimensionais tiradas de um ângulo.
Mas, como sabemos, o progresso não poupou algoritmos maliciosos. Entre eles, apareceu um que é capaz não apenas de distorcer imagens bidimensionais, mas também tridimensionais, o que leva a uma classificação incorreta pelo sistema de reconhecimento de objetos. Ao usar o software para gráficos tridimensionais, esse algoritmo confunde os classificadores com base no SNA (neste caso, o programa Inception V3) de diferentes distâncias e ângulos de visão. O mais surpreendente é que essas imagens 3D enganosas podem ser impressas em uma impressora apropriada, ou seja, crie um objeto físico real e o sistema de reconhecimento de objetos ainda o classificará incorretamente (por exemplo, uma laranja como uma furadeira elétrica). E tudo graças a pequenas alterações na textura na imagem de destino (
4b ).
Para um sistema de reconhecimento de objetos, esse algoritmo malicioso é um adversário sério. Mas o homem não é uma máquina, ele vê e pensa de maneira diferente. Neste teste, antes dos sujeitos, havia imagens de objetos tridimensionais nas quais havia as alterações de textura descritas acima em três ângulos. Os sujeitos também receberam a nota correta e incorreta. Eles precisavam determinar quais rótulos estão corretos, quais não estão e por que, ou seja, se os assuntos de teste veem alterações de textura nas imagens.
Como resultado, 83% dos sujeitos concluíram a tarefa com sucesso.
Para um conhecimento mais detalhado das nuances do estudo, recomendo fortemente que você analise o
relatório dos cientistas .
E
neste link, você encontrará os arquivos de imagem, dados e código que foram usados no estudo.
Epílogo
O trabalho realizado deu aos cientistas a oportunidade de tirar uma conclusão simples e bastante óbvia - a intuição humana pode ser uma fonte de dados muito importantes e uma ferramenta para tomar a decisão certa e / ou a percepção da informação. Uma pessoa é capaz de entender intuitivamente como o sistema de reconhecimento de objetos se comportará, quais rótulos escolherá e por quê.
As razões pelas quais é mais fácil para uma pessoa ver uma imagem real e reconhecê-la corretamente várias. O mais óbvio é o método de obter informações: a máquina recebe uma imagem em formato digital e a pessoa a vê com seus próprios olhos. Para uma máquina, uma imagem é um conjunto de dados, fazendo alterações nas quais você pode distorcer sua classificação. Para nós, a imagem de um trem do metrô sempre será um trem do metrô, não uma lata de leite, porque a vemos.
Os cientistas também enfatizam que esses testes são difíceis de avaliar, porque uma pessoa não é uma máquina e uma máquina não é uma pessoa. Por exemplo, os pesquisadores estão falando sobre o teste com um "anel" e uma "roda". Essas imagens são semelhantes às “rosquinhas” e “roda”, porque o sistema de reconhecimento as classifica dessa maneira. Uma pessoa vê que ela se parece com uma "rosquinha" e uma "roda", mas não é. Essa é a diferença fundamental na percepção de informações visuais entre uma pessoa e um programa.
Obrigado pela atenção, continuem curiosos e tenham uma boa semana de trabalho, pessoal.
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD de 1Gbps até o verão de graça quando pagar por um período de seis meses, você pode fazer o pedido
aqui .
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?