O que pode fazer uma grande empresa como a Lamoda com um processo simplificado e dezenas de serviços interconectados mudarem significativamente a abordagem? A motivação pode ser completamente diferente: do legislativo ao desejo inerente a todos os programadores de experimentar.
Mas isso não significa que não se possa contar com benefícios adicionais. O que exatamente pode ser ganho se você implementar a API orientada a eventos no Kafka, Sergey Zaika (
fewald ) dirá. Sobre inchaços empalhados e descobertas interessantes, certamente haverá - um experimento não pode ficar sem eles.
 Isenção de responsabilidade: este artigo é baseado nos materiais da mitap realizada por Sergey em novembro de 2018 no HighLoad ++. A experiência ao vivo de Lamoda com Kafka atraiu ouvintes não menos que outros relatórios de programação. Parece-nos que este é um ótimo exemplo do fato de que é sempre possível e necessário encontrar pessoas com idéias semelhantes, e os organizadores do HighLoad ++ continuarão tentando criar uma atmosfera propícia a isso.
Isenção de responsabilidade: este artigo é baseado nos materiais da mitap realizada por Sergey em novembro de 2018 no HighLoad ++. A experiência ao vivo de Lamoda com Kafka atraiu ouvintes não menos que outros relatórios de programação. Parece-nos que este é um ótimo exemplo do fato de que é sempre possível e necessário encontrar pessoas com idéias semelhantes, e os organizadores do HighLoad ++ continuarão tentando criar uma atmosfera propícia a isso.Sobre o processo
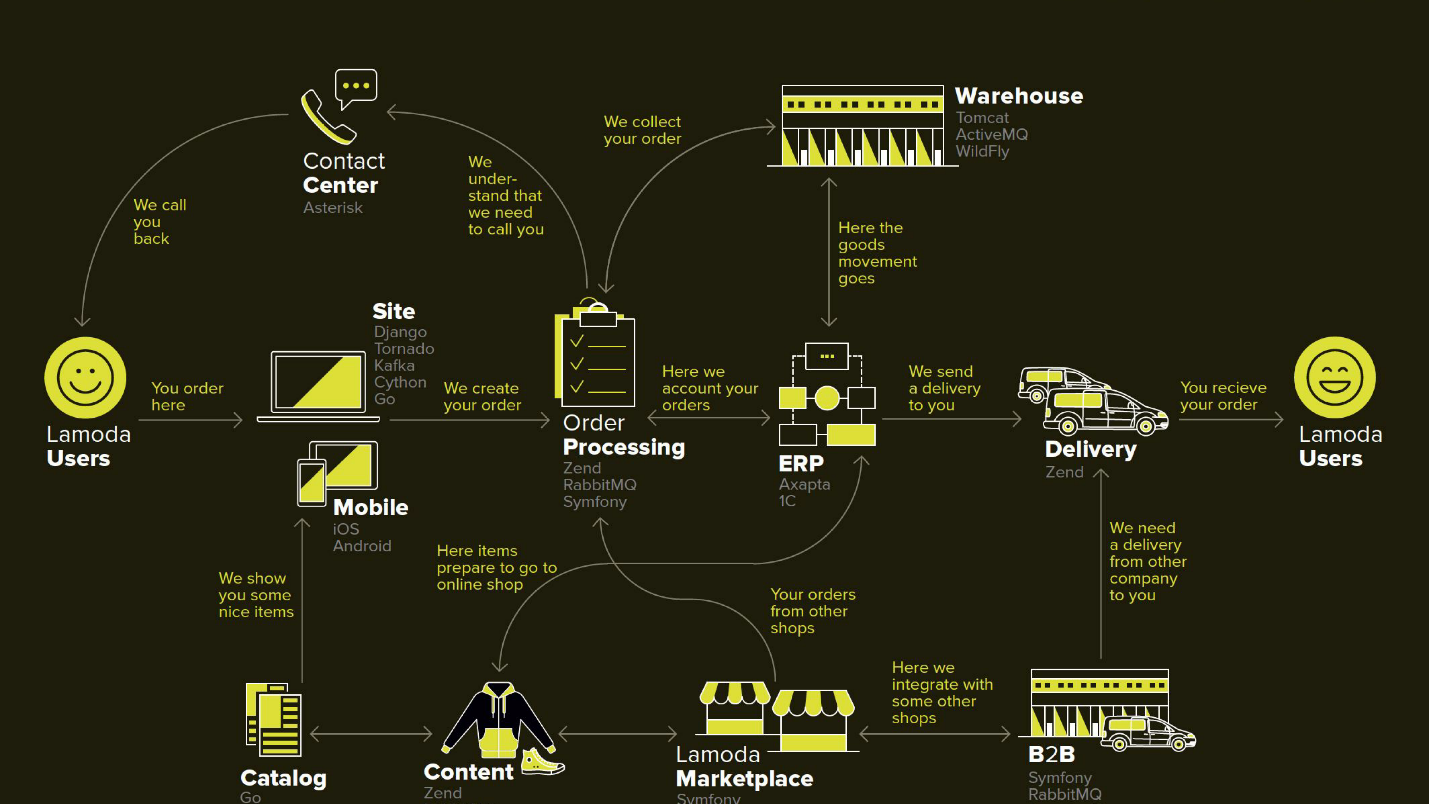
A Lamoda é uma grande plataforma de comércio eletrônico que possui seu próprio contact center, serviço de entrega (e muitos afiliados), um estúdio de fotografia, um enorme armazém e tudo isso funciona em seu software. Existem dezenas de métodos de pagamento, parceiros B2B que podem usar parte ou todos esses serviços e desejam conhecer as informações mais recentes sobre seus produtos. Além disso, a Lamoda opera em três países além da Federação Russa e lá tudo é um pouco diferente. No total, provavelmente existem mais de cem maneiras de configurar um novo pedido, que deve ser processado à sua maneira. Tudo isso funciona com a ajuda de dezenas de serviços que às vezes se comunicam de maneira não óbvia. Existe também um sistema central cuja principal responsabilidade é o status dos pedidos. Nós a chamamos de BOB, eu trabalho com ela.
Ferramenta de reembolso com API orientada a eventos
A palavra orientada a eventos é bastante falsa, um pouco mais adiante definiremos com mais detalhes o que isso significa. Começarei com o contexto em que decidimos experimentar a abordagem da API orientada a eventos Kafka.

Em qualquer loja, além dos pedidos pelos quais os clientes pagam, há momentos em que a loja precisa devolver dinheiro, porque o produto não se encaixa no cliente. Este processo relativamente curto: esclarecemos as informações, se houver, e transferimos o dinheiro.
Mas o retorno foi complicado devido a mudanças na legislação e tivemos que implementar um microsserviço separado para isso.

Nossa motivação:
- Lei FZ-54 - brevemente, a lei exige que você informe à administração fiscal sobre cada transação monetária, seja um reembolso ou um recebimento, em um SLA bastante curto em alguns minutos. Nós, como comércio eletrônico, realizamos algumas operações. Tecnicamente, isso significa uma nova responsabilidade (e, portanto, um novo serviço) e melhorias em todos os sistemas envolvidos.
- Divisão do BOB - o projeto interno da empresa para livrar o BOB de um grande número de responsabilidades não essenciais e reduzir sua complexidade geral.

Este diagrama mostra os principais sistemas Lamoda. Agora, a maioria deles é mais como uma
constelação de 5 a 10 microsserviços em torno de um monólito decrescente . Eles estão crescendo lentamente, mas estamos tentando diminuí-los, porque é assustador implantar o fragmento destacado no meio - não pode cair. Todas as trocas (setas) somos forçadas a reservar e apostamos no fato de que alguma delas pode estar indisponível.
Também existem muitas trocas no BOB: pagamento, entrega, sistemas de notificação etc.
Tecnicamente, o BOB é:
- ~ 150k linhas de código + ~ 100k linhas de testes;
- php7.2 + Zend 1 e componentes Symfony 3;
- > 100 API e ~ 50 integrações de saída;
- 4 países com sua própria lógica de negócios.
A implantação do BOB é cara e penosa, a quantidade de código e as tarefas que ele resolve são tais que ninguém pode colocar na cabeça deles. Em geral, existem muitas razões para simplificá-lo.
Processo de devolução
Inicialmente, dois sistemas estão envolvidos no processo: BOB e Pagamento. Agora, mais dois aparecem:
- Serviço de Fiscalização, que resolverá problemas com fiscalização e comunicação com serviços externos.
- Ferramenta de reembolso, na qual novas trocas são simplesmente realizadas para não inflar o BOB.
Agora, o processo é assim:
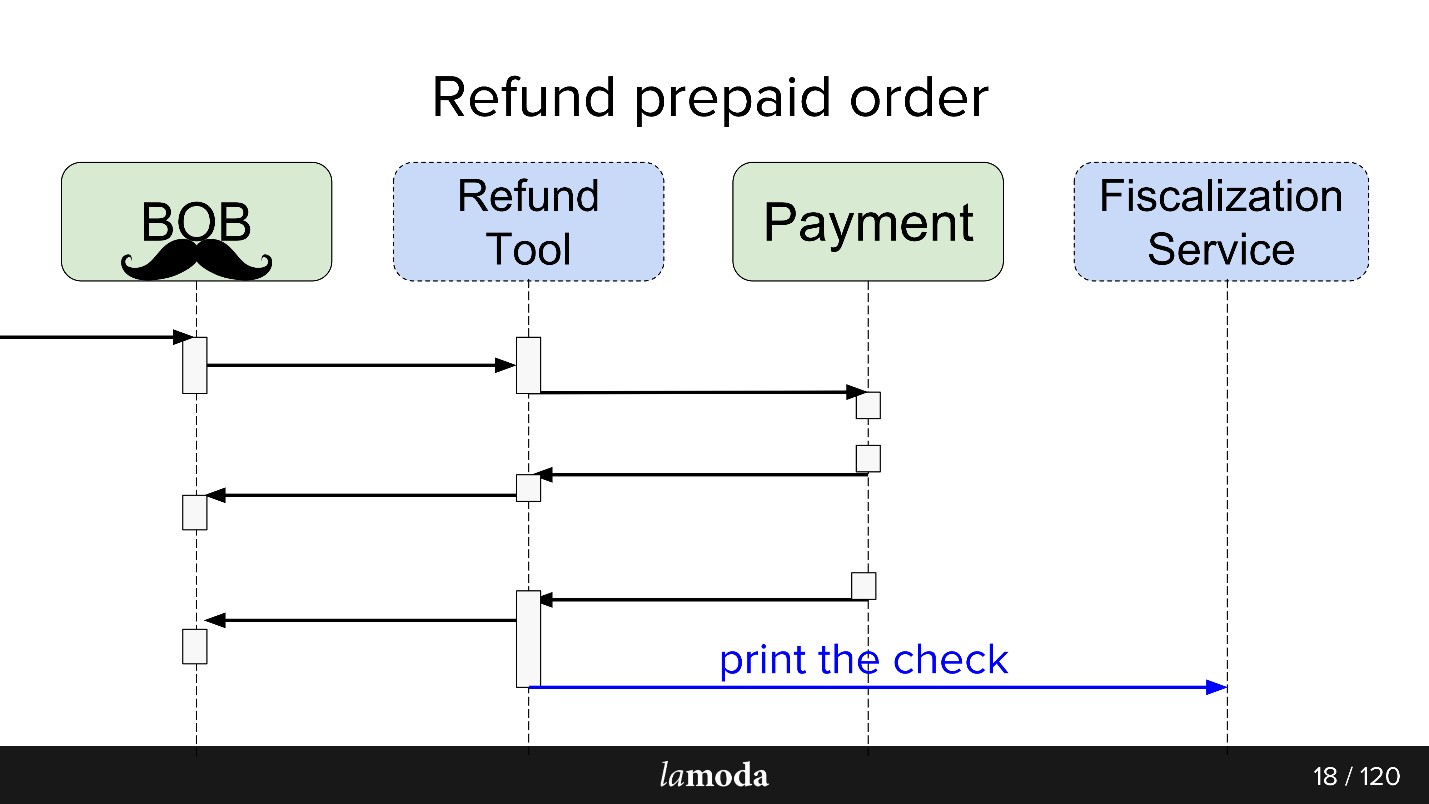
- O BOB recebe uma solicitação de reembolso.
- BOB fala sobre essa ferramenta de reembolso.
- A Ferramenta de reembolso diz Pagamento: "Receba o dinheiro de volta".
- O pagamento retorna o dinheiro.
- A Ferramenta de reembolso e o BOB sincronizam os status entre si, porque, por enquanto, os dois precisam. Ainda não estamos prontos para mudar totalmente para a Ferramenta de reembolso, pois o BOB possui interface do usuário, relatórios para contabilidade e geralmente muitos dados que você não pode transferir facilmente. Temos que sentar em duas cadeiras.
- A solicitação de fiscalização sai.
Como resultado, fizemos um tipo de barramento de evento em Kafka - um barramento de evento, no qual tudo começou. Viva, agora temos um único ponto de falha (sarcasmo).

Os prós e contras são bastante óbvios. Fizemos um ônibus, agora todos os serviços dependem dele. Isso simplifica o design, mas introduz um único ponto de falha no sistema. Kafka cairá, o processo aumentará.
O que é uma API orientada a eventos
Uma boa resposta para essa pergunta está no relatório de Martin Fowler (GOTO 2017)
"Os muitos significados da arquitetura orientada a eventos" .
Resumidamente, o que fizemos:
- Quebra de todas as trocas assíncronas através do armazenamento de eventos . Em vez de informar a cada consumidor interessado sobre a alteração de status pela rede, escrevemos um evento de alteração de status no repositório centralizado, e os consumidores interessados no tópico lêem tudo o que aparece a partir daí.
- Um evento neste caso é uma notificação ( notificações ) de que algo mudou em algum lugar. Por exemplo, o status do pedido foi alterado. Um consumidor interessado em algum tipo de dado que acompanha a alteração de status e que não consta da notificação pode descobrir o status dele.
- A opção máxima é uma fonte de eventos completa, transferência de estado , na qual o evento contém todas as informações necessárias para o processamento: de onde e para qual status você alternou, como exatamente os dados foram alterados etc. A única questão é se vale a pena e quanta informação você pode armazenar.
Como parte do lançamento da Ferramenta de reembolso, usamos a terceira opção. Isso simplificou o processamento de eventos, uma vez que não era necessário obter informações detalhadas, além de excluir o cenário em que cada novo evento gera uma onda de esclarecimentos de solicitações de recebimento dos consumidores.
O serviço da Ferramenta de reembolso
não é
carregado , portanto, Kafka é mais um teste de caneta do que uma necessidade. Eu não acho que se o serviço de reembolso se tornar um projeto de alta carga, os negócios ficarão felizes.
Troca assíncrona COMO ESTÁ
Para trocas assíncronas, o departamento PHP normalmente usa o RabbitMQ. Coletamos os dados para a solicitação, os colocamos na fila e o consumidor do mesmo serviço os leu e os enviou (ou não os enviou). Para a própria API, Lamoda usa ativamente o Swagger. Nós projetamos a API, descrevemos no Swagger, geramos código de cliente e servidor. Também usamos um JSON RPC 2.0 um pouco avançado.
Aqui e ali, os barramentos esb são usados, alguém mora no activeMQ, mas, em geral, o
RabbitMQ é o padrão .
Troca assíncrona PARA SER
Ao projetar uma troca através do barramento de eventos, é feita uma analogia. Da mesma forma, descrevemos a troca futura de dados por meio de descrições da estrutura de eventos. O formato yaml, a geração do código teve que ser feita por nós mesmos, o gerador cria o DTO de acordo com a especificação e ensina clientes e servidores a trabalhar com eles. A geração entra em dois idiomas -
golang e php . Isso mantém as bibliotecas consistentes. O gerador é escrito em golang, para o qual recebeu o nome gogi.
O fornecimento de eventos em Kafka é uma coisa típica. Existe uma solução da versão corporativa principal do Kafka Confluent, existe um
nakadi , uma solução de nossos "irmãos" na área de domínio de Zalando. Nossa
motivação para começar com o Kafka de baunilha é deixar a solução livre até que finalmente decidamos usá-la em qualquer lugar e também deixar espaço para manobras e melhorias: queremos suporte para o
JSON RPC 2.0 , geradores para dois idiomas e ver o que mais.
É irônico que, mesmo em um caso tão feliz, quando há um negócio semelhante ao de Zalando, que tomou uma decisão semelhante, não podemos usá-lo efetivamente.
Em termos de arquitetura, na inicialização, o padrão é o seguinte: leia diretamente do Kafka, mas escreva apenas através do barramento de eventos. Há muito pronto para leitura em Kafka: corretores, balanceadores e está mais ou menos pronto para o dimensionamento horizontal, eu queria mantê-lo. O registro, queríamos encerrar um Gateway, chamado Events-bus, e é por isso.
Ônibus de eventos
Ou um ônibus de eventos. Este é apenas um gateway http sem estado que assume várias funções importantes:
- Validação da produção - verificamos se os eventos atendem às nossas especificações.
- Um sistema mestre de eventos , ou seja, é o principal e único sistema da empresa que responde à pergunta de quais eventos com quais estruturas são consideradas válidas. A validação simplesmente inclui tipos de dados e enumerações para uma especificação estrita do conteúdo.
- A função hash para sharding - a estrutura de mensagens do Kafka é o valor-chave e aqui é calculada pelo hash da chave onde colocá-lo.
Porque
Trabalhamos em uma grande empresa com um processo simplificado. Por que mudar alguma coisa?
Este é um experimento e esperamos obter vários benefícios.
1: n + 1 trocas (uma para muitas)
Com o Kafka, é muito fácil conectar novos consumidores à API.
Suponha que você tenha um diretório que precise ser atualizado em vários sistemas ao mesmo tempo (e em alguns novos). Anteriormente, inventamos um pacote que implementava uma API de conjunto e os endereços dos consumidores eram relatados ao sistema mestre. Agora, o sistema mestre envia atualizações para o tópico e para todos os interessados em ler. Um novo sistema apareceu - eles o assinaram no tópico. Sim, também pacote, mas mais simples.
No caso da ferramenta de reembolso, que é uma parte do BOB, é conveniente mantê-los sincronizados por meio do Kafka. O pagamento diz que eles devolveram o dinheiro: BOB, RT descobriu, mudou seu status, o Serviço de Fiscalização descobriu e cancelou um cheque.

Temos planos de criar um único Serviço de Notificações, que notificará o cliente sobre as notícias em seu pedido / devolução. Agora essa responsabilidade está espalhada entre os sistemas. É o suficiente para ensinarmos o Serviço de Notificações a capturar e responder às informações relevantes da Kafka (e desativar essas notificações em outros sistemas). Não serão necessárias novas trocas diretas.
Orientado por dados
As informações entre os sistemas tornam-se transparentes - não importa o quão sangrenta seja sua empresa e quão incômoda seja sua carteira de pedidos. A Lamoda possui um departamento de Análise de dados que coleta dados nos sistemas e os coloca em uma forma reutilizável, tanto para empresas quanto para sistemas inteligentes. O Kafka permite que você rapidamente forneça muitos dados e mantenha essas informações atualizadas.
Log de replicação
As mensagens não desaparecem após a leitura, como no RabbitMQ. Quando o evento contém informações suficientes para processamento, temos um histórico de alterações recentes no objeto e, se desejado, a capacidade de aplicar essas alterações.
O período de armazenamento do log de replicação depende da intensidade da gravação neste tópico.O Kafka permite que você defina com flexibilidade limites para o tempo de armazenamento e o volume de dados. Para tópicos intensivos, é importante que todos os consumidores tenham tempo para ler as informações antes que elas desapareçam, mesmo no caso de inoperabilidade a curto prazo. Normalmente, eles armazenam dados por
unidades de dias , o que é suficiente para suporte.
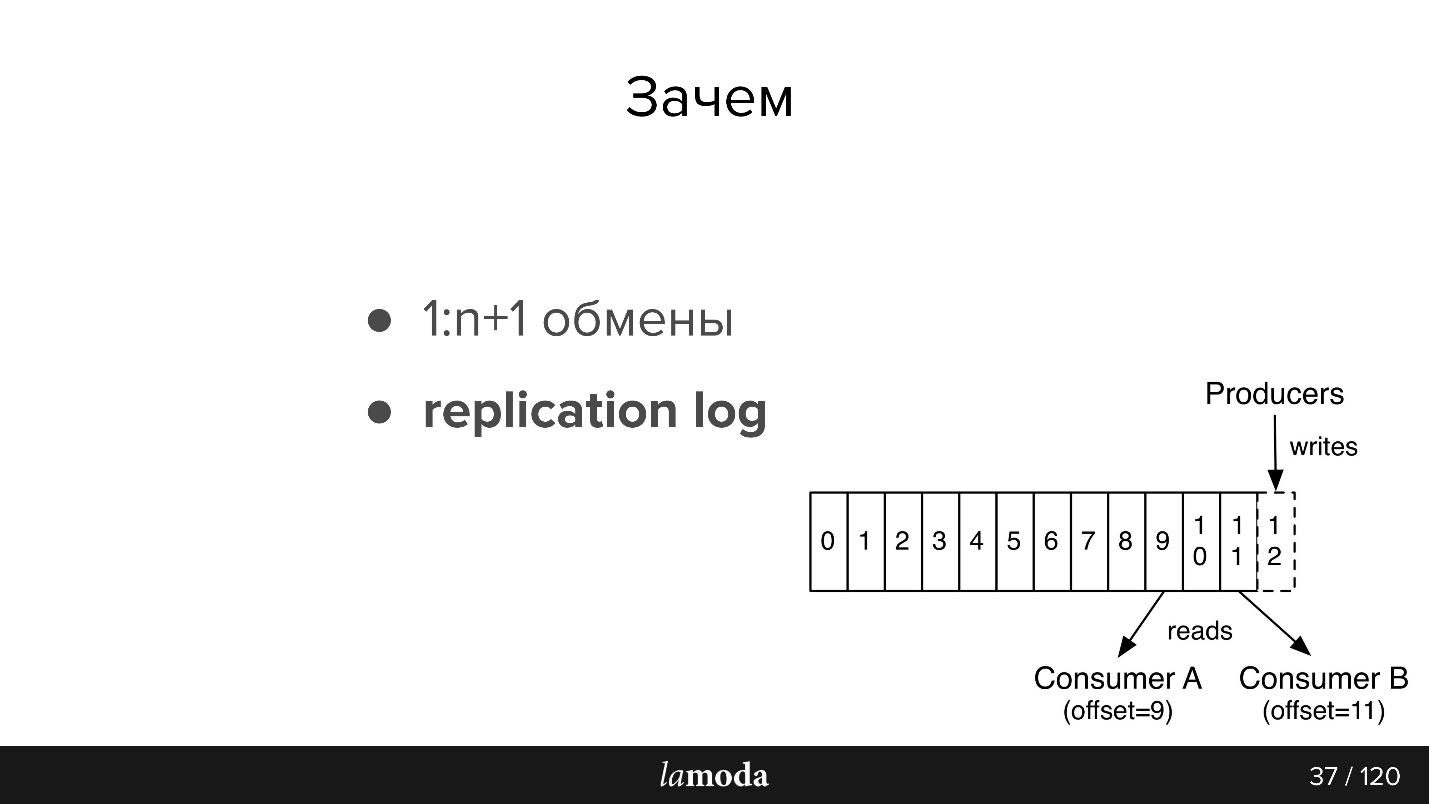
Em seguida, um pouco de recontagem da documentação, para aqueles que não estão familiarizados com Kafka (a imagem também é da documentação)
Existem filas no AMQP: escrevemos mensagens na fila para o consumidor. Como regra, uma fila é processada por um sistema com a mesma lógica de negócios. Se você precisar notificar vários sistemas, poderá ensinar o aplicativo a gravar em várias filas ou configurar o intercâmbio com o mecanismo de fanout, que por sua vez os clona.
Kafka tem uma abstração de
tópico semelhante na qual você escreve mensagens, mas elas não desaparecem após a leitura. Por padrão, quando você se conecta ao Kafka, recebe todas as mensagens e, ao mesmo tempo, há a oportunidade de salvar o local de onde parou. Ou seja, você lê sequencialmente, não pode marcar a mensagem como lida, mas salva o ID, a partir do qual continua lendo. O ID no qual você está parando é chamado de deslocamento, e o mecanismo é o deslocamento de confirmação.
Assim, diferentes lógicas podem ser implementadas. Por exemplo, temos o BOB em 4 instâncias para diferentes países - Lamoda está na Rússia, Cazaquistão, Ucrânia, Bielorrússia. Como são implantados separadamente, eles têm um pouco de suas próprias configurações e lógica de negócios. Na mensagem, indicamos a que país se refere. Cada consumidor de BOB em cada país lê com groupId diferente e, se a mensagem não se aplicar a ele, pule-a, ou seja, confirme imediatamente o deslocamento +1. Se o mesmo tópico for lido pelo nosso Serviço de pagamento, ele fará isso com um grupo separado e, portanto, o deslocamento não se sobrepõe.
Requisitos do evento:- Completude dos dados. Eu gostaria que houvesse dados suficientes no evento para que pudessem ser processados.
- Integridade Delegamos o barramento de eventos para verificar se o evento é consistente e que ele pode lidar com isso.
- A ordem é importante. No caso de um retorno, somos forçados a trabalhar com a história. Com as notificações, o pedido não é importante; se forem notificações homogêneas, o e-mail será o mesmo, independentemente do pedido recebido primeiro. No caso de uma devolução, existe um processo claro; se você alterar o pedido, haverá exceções, o reembolso não será criado ou processado - acabaremos com um status diferente.
- Coerência. Temos um repositório e agora, em vez da API, criamos eventos. Precisamos de uma maneira rápida e barata de transferir informações sobre novos eventos e alterações nos existentes para nossos serviços. Isso é alcançado usando uma especificação comum em um repositório git e geradores de código separados. Portanto, clientes e servidores em diferentes serviços são coordenados conosco.
Kafka em Lamoda
Temos três instalações Kafka:
- Logs
- P&D;
- Ônibus de eventos.
Hoje estamos apenas falando sobre o último ponto. No barramento de eventos, não temos instalações muito grandes - 3 corretores (servidores) e um total de 27 tópicos. Como regra, um tópico é um processo. Mas este é um momento delicado, e agora vamos tocá-lo.
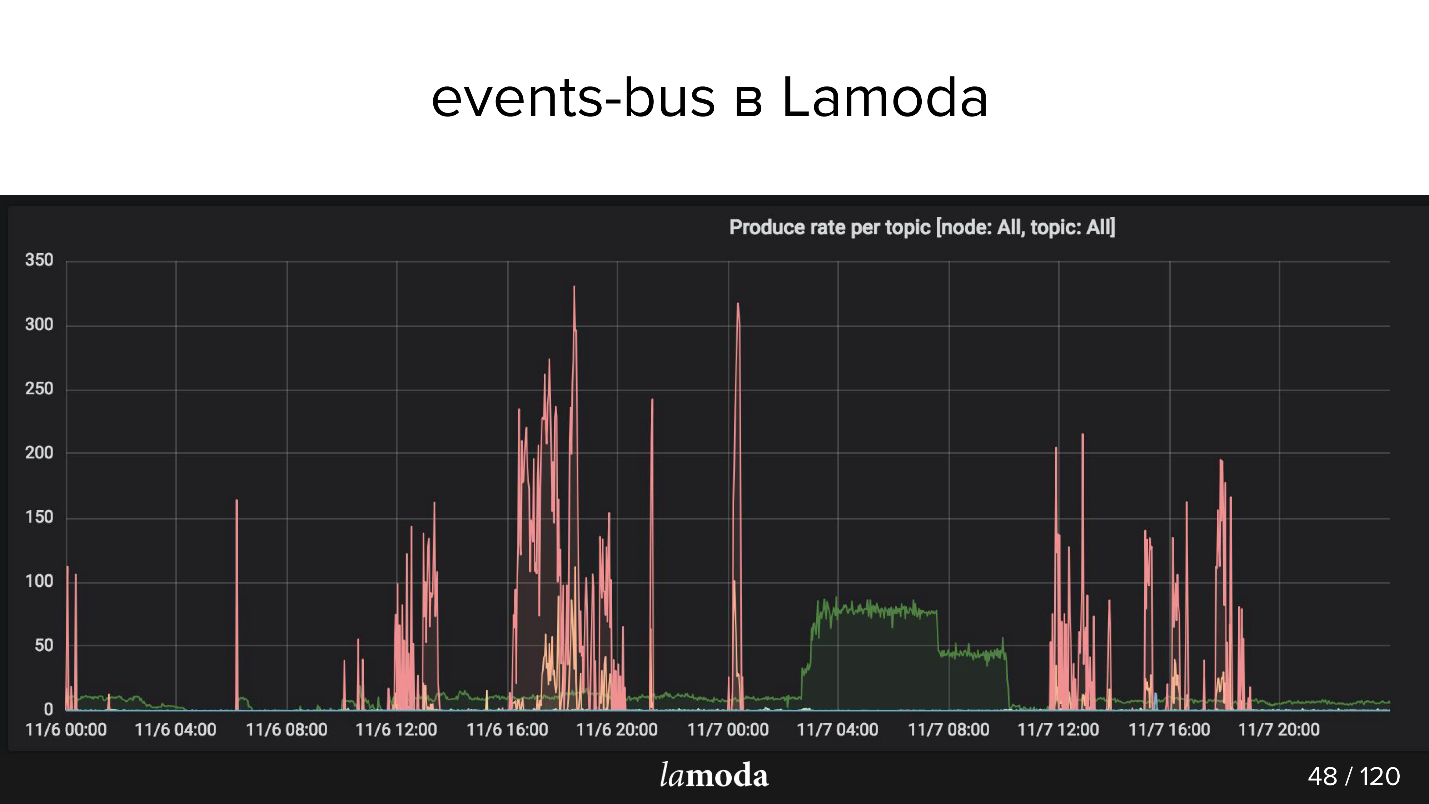
Acima está o gráfico rps. O processo de reembolso é marcado com uma linha turquesa (sim, a que está no eixo X) e rosa é o processo de atualização de conteúdo.
O catálogo da Lamoda contém milhões de produtos, com dados sendo atualizados o tempo todo. Algumas coleções saem de moda, novas são lançadas em vez delas, novos modelos aparecem constantemente no catálogo. Tentamos prever o que será interessante para nossos clientes amanhã, para comprar constantemente coisas novas, fotografá-las e atualizar a janela.
Os picos rosa são uma atualização do produto, ou seja, alterações nos produtos. Pode-se ver que os caras tiraram fotos, tiraram fotos e depois novamente! - baixou um pacote de eventos.
Casos de uso de Eventos Lamoda
Usamos a arquitetura construída para tais operações:
- Rastreamento de status de retorno : call to action e rastreamento de status de todos os sistemas envolvidos. Pagamento, status, fiscalização, notificações. Aqui, testamos a abordagem, criamos as ferramentas, coletamos todos os bugs, escrevemos a documentação e dissemos aos colegas como usá-la.
- Atualizando cartões do produto: configuração, metadados, características. Um sistema lê (que é exibido) e vários escrevem.
- E-mail, push e sms : o pedido é coletado, o pedido chegou, a devolução foi aceita, etc., muitos deles.
- Atualização de estoque, depósito - uma atualização quantitativa dos itens, apenas números: recebimento no depósito, devolução. É necessário que todos os sistemas relacionados à reserva de mercadorias operem com os dados mais relevantes. Agora o sistema de atualização de drenos é bastante complicado, o Kafka o simplificará.
- Análise de dados (departamento de P&D), ferramentas ML, análises, estatísticas. Queremos que as informações sejam transparentes - pois esse Kafka é adequado.
Agora, a parte mais interessante é sobre cones empalhados e descobertas interessantes que ocorreram ao longo de seis meses.
Problemas de design
Suponha que desejemos fazer algo novo - por exemplo, transfira todo o processo de entrega para Kafka. Parte do processo agora está sendo implementada no Processamento de pedidos no BOB. Por trás da transferência do pedido para o serviço de entrega, transferência para um depósito intermediário, etc., existe um modelo de status. Há um monólito inteiro, até dois, além de várias APIs de entrega. Eles sabem muito mais sobre entrega.
Essas áreas parecem ser semelhantes, mas para o Processamento de pedidos no BOB e para o sistema de entrega, os status são diferentes. Por exemplo, alguns serviços de correio não enviam status intermediários, mas apenas finais: "entregues" ou "perdidos". Outros, pelo contrário, relatam detalhadamente a circulação de mercadorias. Todo mundo tem suas próprias regras de validação: para alguém, o email é válido, portanto será processado; para outros, não é válido, mas o pedido ainda será processado, porque existe um telefone para comunicação e alguém dirá que esse pedido não será processado.
Fluxo de dados
No caso de Kafka, surge a questão de organizar o fluxo de dados. Esta tarefa está relacionada com a escolha da estratégia para vários pontos, vamos passar por todos eles.
Em um tópico ou em diferente?
Temos uma especificação de evento. No BOB, escrevemos que esse pedido deve ser entregue e indicamos: o número do pedido, sua composição, alguns códigos de barra e SKU, etc. Quando as mercadorias chegarem ao depósito, a entrega poderá receber status, registros de data e hora e tudo o que for necessário. Além disso, queremos receber atualizações sobre esses dados no BOB. Estamos diante do processo inverso de obter dados da entrega. É o mesmo evento? Ou é uma troca separada que merece um tópico separado?
Provavelmente, eles serão muito parecidos, e a tentação de criar um tópico não é irracional, porque um tópico separado é consumidores separados, configurações separadas, uma geração separada de tudo isso. Mas não é um fato.
Novo campo ou novo evento?
Mas se você usar os mesmos eventos, surgirá outro problema. Por exemplo, nem todos os sistemas de entrega podem gerar um DTO que pode gerar BOBs. Enviamos a eles um ID, mas eles não os salvam, porque não precisam deles e, do ponto de vista de iniciar o processo de barramento de eventos, esse campo é obrigatório.
Se introduzirmos uma regra para o barramento de eventos em que esse campo é obrigatório, seremos forçados a definir regras de validação adicionais no BOB ou no manipulador de eventos de início. A validação começa a aparecer no serviço - não é muito conveniente.
— . , - , , , , . — . — , . JSON .
refunds . -, refund update, type, , update . «» , , type.
Kafka
Avro , Confluent. . replication log, «». , , : , . , , , .
partitions
Kafka partitions. , , , .
Kafka . partition, . . , , , . , , , Kafka partition, Kafka — , .
Kafka ? ( JSON) key. -, , partition .
refunds , partition, , . - , partition.
Events vs commands
, . Event — : , - - (something_happened), , item refund. - , «item » refund , « refund» - .
, , — , - . something_happened (item_canceled, refund_refunded), something_should_be_done. , item .
, , . , . , do_something. , - ; , ; , -, - . , do_something, , .

RabbitMQ, , http, response — , . Kafka, , Kafka, , , .
, - , - . , , - . , «item_ready_to_refund», , refund , , «money_refunded». , .
Nuances
: , - , , .
, offset , .
, , . , events-bus, , PostgreSQL, MySQL UNSIGNED INT, PostgreSQL INT. , Id . Symfony . , , , , offset, , . , Symfony , offset.
- — , Kafka , . . .
Kafka tooling offset. , — , , redeployments. Kafka tooling offset, .
—
replication log vs rdkafka.so — . PHP, PHP, , , Kafka rdkafka.so, - . , , , - . , .
partitions,
consumers >= topic partitions . , . , partitions. , partition, 20 , , . , , partitions.
Monitoramento
, , , , .
, , , , , , . Kafka , . , .

, , , events-bus , . , Refund Tool , BOB - ( ).

consumer-group lag. , . , 0, . Kafka , .
Burrow , Kafka. API consumer-group , . Failed warning, , — , . , .
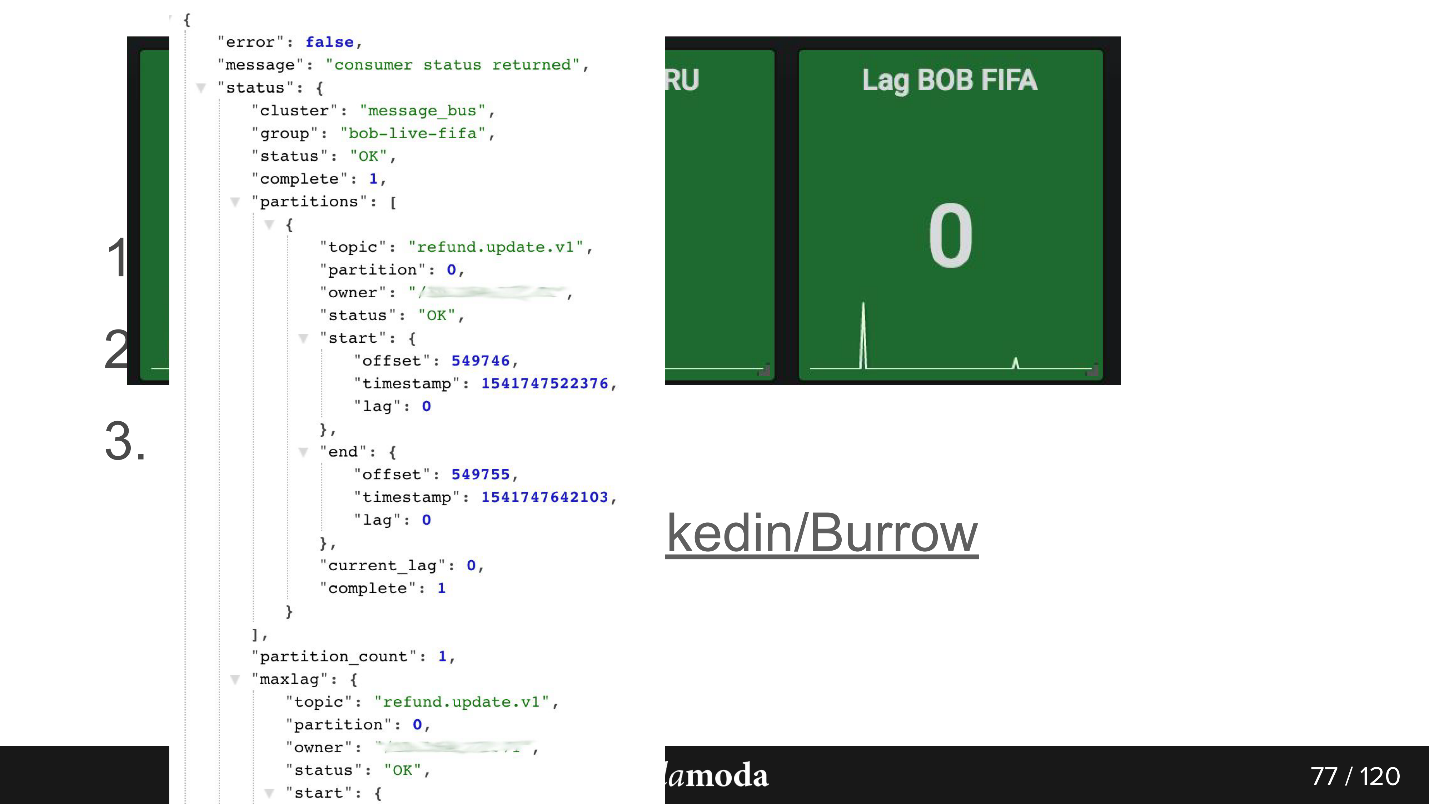
API. bob-live-fifa, partition refund.update.v1, , lag 0 — offset -.
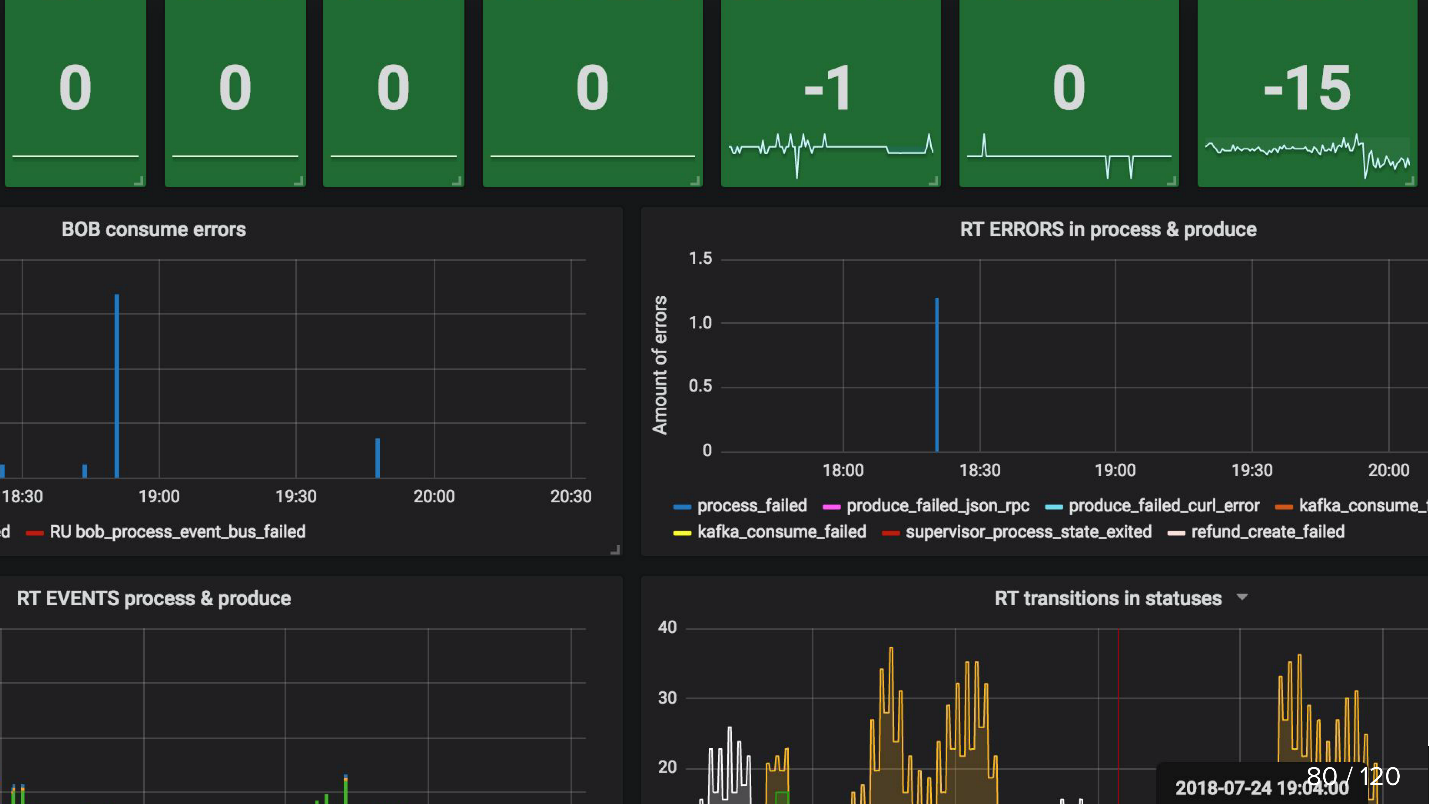 updated_at SLA (stuck)
updated_at SLA (stuck) . , , . Cron, , 5 refund ( ), - , . Cron, , 0, .
, , :
, — API Kafka, .
-, HighLoad++ , , .
-, KnowledgeConf . , 26 , .
PHP Russia ++ ( DevOpsConf ) — , .