Na semana passada, escrevi um artigo sobre a inutilidade do modelo de repositório para entidades eloquentes , mas prometi dizer como usá-lo parcialmente com benefícios. Para fazer isso, tentarei analisar como esse modelo geralmente é usado em projetos. O conjunto mínimo de métodos necessário para o repositório:
<?php interface PostRepository { public function getById($id): Post; public function save(Post $post); public function delete($id); }
No entanto, em projetos reais, se foi decidido usar repositórios, eles geralmente adicionam métodos para selecionar registros:
<?php interface PostRepository { public function getById($id): Post; public function save(Post $post); public function delete($id); public function getLastPosts(); public function getTopPosts(); public function getUserPosts($userId); }
Esses métodos podem ser implementados por meio de escopos Eloquent, mas sobrecarregar classes de entidades com responsabilidades de buscar a si mesmas não é uma boa idéia e colocar essa responsabilidade em classes de repositório parece lógico. É isso mesmo? Eu especificamente dividi visualmente essa interface em duas partes. A primeira parte dos métodos será usada em operações de gravação.
As operações de gravação padrão são:
- construindo um novo objeto e chamando PostRepository :: save
- PostRepository :: getById , manipulação de entidade e chamada PostRepository :: save
- chame PostRepository :: delete
Não há métodos de amostragem nas operações de gravação. Nas operações de leitura, apenas os métodos get * são usados. Se você ler sobre o Princípio de Segregação de Interface (letra I no SOLID ), ficará claro que nossa interface é muito grande e cumpre pelo menos duas responsabilidades diferentes. É hora de dividi-lo em dois. O método getById é necessário em ambos, mas se o aplicativo se tornar mais complicado, sua implementação será diferente. Isso veremos um pouco mais tarde. Eu escrevi sobre a inutilidade da parte de gravação em um artigo anterior, portanto, apenas esqueço isso.
Leia a parte não me parece tão inútil, porque mesmo para Eloquent pode haver várias implementações. Como nomear uma classe? Você pode ReadPostRepository , mas ele já tem pouca relação com o modelo de repositório . Você pode simplesmente PostQueries :
<?php interface PostQueries { public function getById($id): Post; public function getLastPosts(); public function getTopPosts(); public function getUserPosts($userId); }
Sua implementação usando o Eloquent é bastante simples:
<?php final class EloquentPostQueries implements PostQueries { public function getById($id): Post { return Post::findOrFail($id); } public function getLastPosts() { return Post::orderBy('created_at', 'desc') ->limit() ->get(); } public function getTopPosts() { return Post::orderBy('rating', 'desc') ->limit() ->get(); } public function getUserPosts($userId) { return Post::whereUserId($userId) ->orderBy('created_at', 'desc') ->get(); } }
A interface deve estar associada à implementação, por exemplo, no AppServiceProvider :
<?php final class AppServiceProvider extends ServiceProvider { public function register() { $this->app->bind(PostQueries::class, EloquentPostQueries::class); } }
Esta classe já é útil. Ele realiza sua responsabilidade descarregando controladores ou uma classe de entidade. No controlador, ele pode ser usado assim:
<?php final class PostsController extends Controller { public function lastPosts(PostQueries $postQueries) { return view('posts.last', [ 'posts' => $postQueries->getLastPosts(), ]); } }
O método PostsController :: lastPosts simplesmente solicita alguma implementação do PostsQueries e trabalha com ele. No provedor, associamos o PostQueries à classe EloquentPostQueries e essa classe será substituída no controlador.
Vamos imaginar que nosso aplicativo se tornou muito popular. Milhares de usuários por minuto abrem a página com as últimas publicações. As publicações mais populares também são lidas com muita frequência. Os bancos de dados não lidam muito bem com essas cargas, portanto, eles usam a solução padrão - cache. Além do banco de dados, um certo número de dados é armazenado em um repositório otimizado para determinadas operações - armazenadas em cache ou redis .
A lógica de armazenamento em cache geralmente não é tão complicada, mas sua implementação no EloquentPostQueries não é muito correta (pelo menos por causa do Princípio de Responsabilidade Única ). É muito mais natural usar o modelo Decorator e implementar o cache como decoração da ação principal:
<?php use Illuminate\Contracts\Cache\Repository; final class CachedPostQueries implements PostQueries { const LASTS_DURATION = 10; private $base; private $cache; public function __construct( PostQueries $base, Repository $cache) { $this->base = $base; $this->cache = $cache; } public function getLastPosts() { return $this->cache->remember('last_posts', self::LASTS_DURATION, function(){ return $this->base->getLastPosts(); }); }
Ignore a interface do repositório no construtor. Por alguma razão, eles decidiram chamar a interface para armazenamento em cache no Laravel.
A classe CachedPostQueries implementa apenas o cache. $ this-> cache-> remember verifica se a entrada fornecida está no cache e, se não, chama o retorno de chamada e grava o valor retornado no cache. Resta apenas implementar essa classe no aplicativo. Precisamos de todas as classes que no aplicativo solicitam a implementação da interface PostQueries para receber uma instância da classe CachedPostQueries . No entanto, o próprio CachedPostQueries deve receber a classe EloquentPostQueries como um parâmetro no construtor, pois não pode funcionar sem uma implementação "real". Altere AppServiceProvider :
<?php final class AppServiceProvider extends ServiceProvider { public function register() { $this->app->bind(PostQueries::class, CachedPostQueries::class); $this->app->when(CachedPostQueries::class) ->needs(PostQueries::class) ->give(EloquentPostQueries::class); } }
Todos os meus desejos são descritos naturalmente no provedor. Assim, implementamos o cache para nossos pedidos apenas escrevendo uma classe e alterando a configuração do contêiner. O código para o restante do aplicativo não foi alterado.
Obviamente, para a implementação completa do armazenamento em cache, ainda é necessário implementar a invalidação para que o artigo excluído não fique no site por mais algum tempo, mas saia imediatamente (escreveu recentemente um artigo sobre armazenamento em cache , pode ajudar em detalhes).
Conclusão: não usamos um, mas dois padrões inteiros. O modelo CQRS (Segmento de responsabilidade de consulta de comando) oferece uma separação completa das operações de leitura e gravação no nível da interface. Eu vim para ele através do Princípio de Segregação de Interface , o que significa que manipulo habilmente modelos e princípios e deduzo um do outro como um teorema :) É claro que nem todo projeto precisa de uma abstração dessas em amostras de entidades, mas vou compartilhar o foco com você. No estágio inicial do desenvolvimento do aplicativo, você pode simplesmente criar uma classe PostQueries com uma implementação regular através do Eloquent:
<?php final class PostQueries { public function getById($id): Post { return Post::findOrFail($id); }
Quando surgir a necessidade de armazenamento em cache, é possível criar facilmente uma interface (ou uma classe abstrata) no lugar dessa classe PostQueries , copiar sua implementação na classe EloquentPostQueries e ir para o esquema descrito anteriormente. O restante do código do aplicativo não precisa ser alterado.
No entanto, permanece um problema com o uso das mesmas entidades de postagem que podem modificar dados. Isto não é exatamente CQRS.

Ninguém se preocupa em obter a entidade Post do PostQueries , modificá-la e salvar as alterações com um simples -> save () . E vai funcionar.
Depois de um tempo, a equipe mudará para a replicação mestre-escravo no banco de dados e o PostQueries trabalhará com réplicas de leitura. As operações de gravação em réplicas de leitura geralmente são bloqueadas. O erro será aberto, mas você terá que trabalhar duro para corrigir todos esses batentes.
A solução óbvia é separar completamente as partes de leitura e gravação . Você pode continuar usando o Eloquent, mas criando uma classe para modelos somente leitura. Exemplo: https://github.com/adelf/freelance-example/blob/master/app/ReadModels/ReadModel.php Todas as operações de modificação de dados estão bloqueadas. Crie um novo modelo, por exemplo, ReadPost (você pode deixar Post , mas mova-o para outro espaço para nome):
<?php final class ReadPost extends ReadModel { protected $table = 'posts'; } interface PostQueries { public function getById($id): ReadPost; }
Esses modelos podem ser somente leitura e podem ser armazenados em cache com segurança.
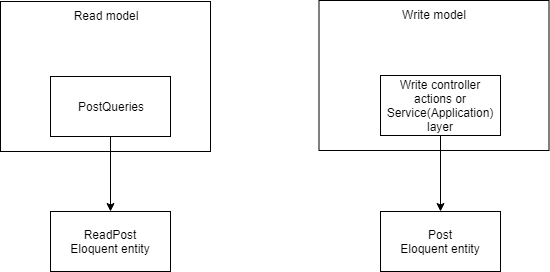
Outra opção: abandonar o Eloquent. Pode haver várias razões para isso:
- Todos os campos da tabela quase nunca são necessários. Para a solicitação lastPosts , apenas os campos id , title e, por exemplo, publish_at são geralmente necessários. Solicitar alguns textos pesados de publicações fornecerá apenas uma carga desnecessária no banco de dados ou no cache. O Eloquent pode selecionar apenas os campos obrigatórios, mas tudo isso é muito implícito. Os clientes do PostQueries não sabem exatamente quais campos são selecionados sem entrar na implementação.
- O armazenamento em cache usa serialização por padrão. As classes eloquentes ocupam muito espaço na forma serializada. Se para entidades simples isso não é particularmente perceptível, então para entidades complexas com relacionamentos isso se torna um problema (como você arrasta objetos do tamanho de megabytes do cache?). Em um projeto, uma classe comum com campos públicos no cache ocupava 10 vezes menos espaço que a opção Eloquent (havia muitas subentidades pequenas). Você pode armazenar em cache atributos apenas ao fazer o cache, mas isso complicará bastante o processo.
Um exemplo simples de como isso pode parecer:
<?php final class PostHeader { public int $id; public string $title; public DateTime $publishedAt; } final class Post { public int $id; public string $title; public string $text; public DateTime $publishedAt; } interface PostQueries { public function getById($id): Post; public function getLastPosts(); public function getTopPosts(); public function getUserPosts($userId); }
Claro, tudo isso parece uma supercomplicação selvagem da lógica. "Pegue os escopos eloquentes e tudo ficará bem. Por que criar tudo isso?" Para projetos mais simples, isso está correto. Não há absolutamente nenhuma necessidade de reinventar os escopos. Mas quando o projeto é grande e vários desenvolvedores estão envolvidos no desenvolvimento, que geralmente mudam (eles param e novos vêm), as regras do jogo se tornam um pouco diferentes. O código deve ser protegido contra gravação para que o novo desenvolvedor, após alguns anos, não possa fazer algo errado. Obviamente, é impossível excluir completamente essa probabilidade, mas é necessário reduzi-la. Além disso, esta é uma decomposição comum do sistema. Você pode coletar todos os decoradores e classes de armazenamento em cache para invalidar o cache em um determinado "módulo de armazenamento em cache", economizando o restante do aplicativo de informações sobre armazenamento em cache. Eu tive que vasculhar grandes pedidos cercados por chamadas de cache. Isso atrapalha. Especialmente se a lógica de armazenamento em cache não for tão simples como descrito acima.