TL; DR: há quatro anos, deixei o Google com a ideia de uma nova ferramenta para monitorar servidores. A idéia era combinar as funções geralmente isoladas de
coletar e analisar logs, coletar métricas,
alertas e um painel em um serviço. Um dos princípios - o serviço deve ser muito
rápido , oferecendo aos desenvolvedores um trabalho fácil, interativo e agradável. Isso requer o processamento de conjuntos de dados de vários gigabytes em uma fração de segundo, sem exceder o orçamento. As ferramentas existentes para trabalhar com logs geralmente são lentas e desajeitadas, por isso enfrentamos uma boa tarefa: desenvolver corretamente uma ferramenta para dar aos usuários novas sensações do trabalho.
Este artigo descreve como nós da Scalyr resolvemos esse problema aplicando os métodos da velha escola, a abordagem de força bruta, eliminando camadas redundantes e evitando estruturas de dados complexas. Você pode aplicar essas lições às suas próprias tarefas de engenharia.
A força da velha escola
A análise de log geralmente começa com uma pesquisa: encontre todas as mensagens correspondentes a um determinado modelo. No Scalyr, são dezenas ou centenas de gigabytes de logs de muitos servidores. As abordagens modernas, em regra, envolvem a construção de uma estrutura de dados complexa otimizada para pesquisa. Claro, eu vi isso no Google, onde eles são muito bons em tais coisas. Mas decidimos por uma abordagem muito mais severa: verificação linear de logs. E funcionou - fornecemos uma interface com pesquisa em uma ordem de magnitude mais rápida que a dos concorrentes (veja a animação no final).
O principal insight é que os processadores modernos são realmente muito rápidos em operações simples e diretas. Isso é facilmente esquecido em sistemas complexos e multicamadas que dependem da velocidade de E / S e das operações de rede, e esses sistemas são muito comuns hoje em dia. Assim, desenvolvemos um design que minimiza o número de camadas e o excesso de lixo. Com vários processadores e servidores em paralelo, a velocidade da pesquisa atinge 1 TB por segundo.
Principais conclusões deste artigo:
- A pesquisa aproximada é uma abordagem viável para solucionar problemas reais em larga escala.
- A força bruta é uma técnica de design, não a libertação do trabalho. Como qualquer técnica, é mais adequada para alguns problemas do que para outras, e pode ser implementada mal ou bem.
- A força bruta é especialmente boa para desempenho estável .
- O uso efetivo da força bruta requer otimização do código e o uso oportuno de recursos suficientes. É adequado se seus servidores estiverem sob cargas de trabalho pesadas para não usuários e as operações do usuário continuarem sendo uma prioridade.
- O desempenho depende do design de todo o sistema, e não apenas do algoritmo de loop interno.
(Este artigo descreve como procurar dados na memória. Na maioria dos casos, quando um usuário pesquisa logs, os servidores Scalyr já os armazenaram em cache. No próximo artigo, discutiremos a pesquisa de logs não armazenados em cache. Os mesmos princípios se aplicam: código eficiente, método de força bruta com grande número computacional recursos).
Método da força bruta
Tradicionalmente, uma pesquisa em um grande conjunto de dados é feita usando um índice de palavras-chave. Conforme aplicado aos logs do servidor, isso significa procurar por cada palavra exclusiva no log. Para cada palavra, você precisa fazer uma lista de todas as inclusões. Isso facilita a localização de todas as mensagens com essa palavra, por exemplo, 'erro', 'firefox' ou 'transaction_16851951' - basta olhar no índice.
Eu usei essa abordagem no Google e funcionou bem. Mas no Scalyr, procuramos nos logs byte a byte.
Porque De um ponto de vista algorítmico abstrato, os índices de palavras-chave são muito mais eficazes do que uma pesquisa bruta. No entanto, não vendemos algoritmos, vendemos desempenho. E o desempenho não é apenas algoritmos, mas também engenharia de sistemas. Devemos considerar tudo: a quantidade de dados, o tipo de pesquisa, o hardware disponível e o contexto do software. Decidimos que, para o nosso problema específico, uma opção como 'grep' é melhor que um índice.
Os índices são ótimos, mas têm limitações. É fácil encontrar uma palavra. Mas encontrar mensagens com algumas palavras, como 'googlebot' e '404', já é muito mais complicado. A pesquisa de frases como 'exceção não capturada' exige um índice mais complexo que não apenas registra todas as mensagens com essa palavra, mas também o local específico da palavra.
A verdadeira dificuldade surge quando você não está procurando palavras. Suponha que você queira ver quanto tráfego vem dos bots. O primeiro pensamento é procurar nos logs a palavra 'bot'. Então você encontrará alguns bots: Googlebot, Bingbot e muitos outros. Mas aqui 'bot' não é uma palavra, mas parte dela. Se procurarmos por 'bot' no índice, não encontraremos mensagens com a palavra 'Googlebot'. Se você verificar cada palavra no índice e depois varrer o índice em busca das palavras-chave encontradas, a pesquisa diminuirá bastante. Como resultado, alguns programas para trabalhar com logs não permitem pesquisar partes de uma palavra ou (na melhor das hipóteses) permitem o uso de sintaxe especial com desempenho inferior. Queremos evitar isso.
Outro problema é a pontuação. Deseja encontrar todos os pedidos de
50.168.29.7 ? E os logs de depuração que contêm
[error] ? Os índices geralmente ignoram a pontuação.
Finalmente, os engenheiros adoram ferramentas poderosas e, às vezes, um problema só pode ser resolvido com uma expressão regular. O índice de palavras-chave não é muito adequado para isso.
Além disso, os índices
são complexos . Cada mensagem deve ser adicionada a várias listas de palavras-chave. Essas listas devem sempre ser mantidas em um formato amigável para pesquisa. As consultas com frases, fragmentos de palavras ou expressões regulares devem ser convertidas em operações com várias listas e os resultados verificados e combinados para obter um conjunto de resultados. No contexto de um serviço multiusuário em larga escala, essa complexidade cria problemas de desempenho que não são visíveis ao analisar os algoritmos.
Os índices de palavras-chave também ocupam muito espaço, e o armazenamento é o principal item de custo no sistema de gerenciamento de logs.
Por outro lado, muito poder de computação pode ser gasto em cada pesquisa. Nossos usuários valorizam pesquisas de alta velocidade para consultas exclusivas, mas essas consultas são relativamente raras. Para consultas de pesquisa típicas, por exemplo, para o painel, usamos técnicas especiais (as descreveremos no próximo artigo). Como outras consultas são muito raras, você raramente precisa processar mais de uma por vez. Mas isso não significa que nossos servidores não estejam ocupados: eles estão ocupados com o trabalho de receber, analisar e compactar novas mensagens, avaliar alertas, compactar dados antigos e assim por diante. Portanto, temos um fornecimento bastante substancial de processadores que podem ser usados para atender solicitações.
A força bruta funciona se você tiver um problema de força bruta (e muita força)
A força bruta funciona melhor em tarefas simples com pequenos loops internos. Muitas vezes, você pode otimizar o loop interno para trabalhar em velocidades muito altas. Se o código é complexo, é muito mais difícil otimizá-lo.
Inicialmente, nosso código de pesquisa tinha um loop interno bastante grande. Armazenamos mensagens em páginas 4K; cada página contém algumas mensagens (em UTF-8) e metadados para cada mensagem. Metadados é uma estrutura na qual o comprimento do valor, o ID da mensagem interna e outros campos são codificados. O loop de pesquisa ficou assim:

Esta é uma opção simplificada em comparação com o código real. Mas mesmo aqui você pode ver vários posicionamentos de objetos, cópias de dados e chamadas de função. A JVM otimiza bastante as chamadas de função e aloca objetos efêmeros; portanto, esse código funcionou melhor do que merecíamos. Durante o teste, os clientes o usaram com bastante sucesso. Mas no final, passamos para um novo nível.
(Você pode perguntar por que armazenamos mensagens nesse formato com páginas 4K, texto e metadados, em vez de trabalhar diretamente com os logs. Há muitas razões pelas quais o mecanismo interno Scalyr é mais um banco de dados distribuído do que sistema de arquivos A pesquisa de texto geralmente é combinada com filtros de estilo DBMS nos campos após a análise de logs. Podemos pesquisar muitos milhares de logs ao mesmo tempo, e arquivos de texto simples não são adequados para nosso controle transacional, replicado e distribuído dados).
Inicialmente, parecia que esse código não era muito adequado para otimização pelo método da força bruta. O "trabalho real" em
String.indexOf() nem dominou o perfil da CPU. Ou seja, a otimização apenas desse método não traria um efeito significativo.
Aconteceu que armazenamos metadados no início de cada página e o texto de todas as mensagens em UTF-8 é compactado na outra extremidade. Aproveitando isso, reescrevemos o loop de pesquisa em toda a página de uma vez:
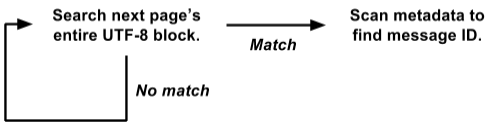
Esta versão funciona diretamente na visualização de
raw byte[] e pesquisa todas as mensagens de uma só vez em toda a página de 4K.
É muito mais fácil otimizar a força bruta. O ciclo de pesquisa interno é chamado simultaneamente para toda a página 4K e não separadamente para cada mensagem. Não há cópia de dados, nem seleção de objetos. E operações mais complexas com metadados são chamadas apenas com um resultado positivo, e não para cada mensagem. Assim, eliminamos uma tonelada de sobrecarga e o restante da carga é concentrado em um pequeno ciclo de pesquisa interno, adequado para otimização adicional.
Nosso algoritmo de busca atual é baseado na
grande ideia de Leonid Volnitsky . É semelhante ao algoritmo de Boyer-Moore, com pular o comprimento da cadeia de pesquisa em cada etapa. A principal diferença é que ele verifica dois bytes por vez para minimizar correspondências falsas.
Nossa implementação requer a criação de uma tabela de pesquisa de 64K para cada pesquisa, mas isso não faz sentido comparado aos gigabytes de dados que estamos procurando. O loop interno processa vários gigabytes por segundo em um único núcleo. Na prática, o desempenho estável é de cerca de 1,25 GB por segundo em cada núcleo, e há potencial para melhorias. Você pode eliminar parte da sobrecarga fora do loop interno, e planejamos experimentar o loop interno em C em vez de Java.
Aplicar força
Discutimos que as pesquisas de log podem ser implementadas "aproximadamente", mas quanto "poder" temos? Muito.
1 núcleo : quando usado corretamente, um núcleo de um processador moderno é bastante poderoso por si só.
8 núcleos : atualmente estamos trabalhando nos servidores SSD Amazon hi1.4xlarge e i2.4xlarge, cada um com 8 núcleos (16 threads). Como mencionado acima, geralmente esses kernels estão ocupados com operações em segundo plano. Quando o usuário realiza uma pesquisa, as operações em segundo plano são pausadas, liberando todos os 8 núcleos para a pesquisa. A pesquisa geralmente é concluída em uma fração de segundo, após a qual o trabalho em segundo plano é retomado (o programa do controlador garante que uma enxurrada de consultas de pesquisa não interfira em importantes trabalhos em segundo plano).
16 núcleos : para confiabilidade, organizamos servidores em grupos mestre / escravo. Cada mestre possui um servidor SSD e um EBS subordinado. Se o servidor principal travar, o servidor no SSD substituirá imediatamente. Quase o tempo todo, o mestre e o escravo funcionam bem, de modo que cada bloco de dados pode ser pesquisado em dois servidores diferentes (o servidor EBS escravo tem um processador fraco, então não o consideramos). Dividimos a tarefa entre eles, para que tenhamos um total de 16 núcleos disponíveis.
Muitos núcleos : em um futuro próximo, distribuiremos os dados entre os servidores para que todos participem do processamento de cada solicitação não trivial. Cada núcleo irá funcionar. [Nota:
implementamos o plano e aumentamos a velocidade de pesquisa para 1 TB / s, veja a nota no final do artigo ].
Simplicidade fornece confiabilidade
Outra vantagem da força bruta é seu desempenho relativamente estável. Como regra, a pesquisa não é muito sensível aos detalhes da tarefa e do conjunto de dados (acho que é por isso que é chamado de "rude").
Às vezes, o índice de palavras-chave produz resultados incrivelmente rápidos, mas em outros casos não. Suponha que você tenha 50 GB de logs nos quais o termo 'customer_5987235982' ocorra exatamente três vezes. Uma pesquisa por esse termo conta três locais diretamente do índice e termina instantaneamente. Porém, uma pesquisa curinga complexa pode digitalizar milhares de palavras-chave e levar muito tempo.
Por outro lado, as pesquisas de força bruta para qualquer consulta são realizadas mais ou menos na mesma velocidade. A busca por palavras longas é melhor, mas mesmo a busca por um único caractere é rápida o suficiente.
A simplicidade do método da força bruta significa que sua produtividade está próxima do máximo teórico. Há menos opções para sobrecarga inesperada de disco, conflito de bloqueio, perseguição de ponteiros e milhares de outros motivos para falhas. Acabei de analisar as solicitações feitas pelos usuários de Scalyr na semana passada em nosso servidor mais ocupado. Houve 14.000 pedidos. Exatamente oito deles levaram mais de um segundo; 99% foram executados em 111 milissegundos (se você não tiver usado as ferramentas de análise de log, acredite:
isso é rápido ).
Um desempenho estável e confiável é importante para a conveniência de usar o serviço. Se ele diminuir periodicamente, os usuários o perceberão como não confiável e relutam em usá-lo.
Pesquisa de log em ação
Aqui está uma pequena animação que mostra Scalyr pesquisando em ação. Temos uma conta demo em que importamos todos os eventos em todos os repositórios públicos do Github. Nesta demonstração, estudo os dados da semana: aproximadamente 600 MB de logs brutos.
O vídeo foi gravado ao vivo, sem preparação especial, na minha área de trabalho (a cerca de 5.000 quilômetros do servidor). O desempenho que você verá é em grande parte devido à
otimização do Web client , bem como ao back-end rápido e confiável. Sempre que houver uma pausa sem o indicador 'loading', eu paro para que você possa ler no que eu clico.

Em conclusão
Ao processar grandes quantidades de dados, é importante escolher um bom algoritmo, mas "bom" não significa "sofisticado". Pense em como seu código funcionará na prática. Alguns fatores que podem ser de grande importância no mundo real caem da análise teórica de algoritmos. Algoritmos mais simples são mais fáceis de otimizar e mais estáveis em situações limítrofes.
Pense também no contexto em que o código será executado. No nosso caso, precisamos de servidores poderosos o suficiente para gerenciar tarefas em segundo plano. Os usuários iniciam uma pesquisa relativamente raramente, para que possamos emprestar um grupo inteiro de servidores pelo curto período necessário para concluir cada pesquisa.
Usando força bruta, implementamos uma pesquisa rápida, confiável e flexível em um conjunto de logs. Esperamos que essas idéias sejam úteis para seus projetos.
Editar: o
título e o texto foram alterados de "Pesquisar a 20 GB por segundo" para "Pesquisar a 1 TB por segundo" para refletir o aumento no desempenho nos últimos anos. Esse aumento na velocidade deve-se principalmente a uma alteração no tipo e número de servidores EC2 que estamos aumentando hoje para atender à maior base de clientes. Num futuro próximo, espera-se mudanças que proporcionem outro aumento acentuado da eficiência do trabalho, e esperamos ansiosamente a oportunidade de falar sobre isso.