Na
primeira parte da história, com base na
apresentação de Dmitry Stogov da Zend Technologies no HighLoad ++, entendemos a estrutura interna do PHP. Aprendemos em detalhes e em primeira mão quais mudanças nas estruturas básicas de dados permitiram que o PHP 7 acelerasse mais de duas vezes. Isso poderia ter sido interrompido, mas já na versão 7.1, os desenvolvedores foram muito mais longe, pois ainda tinham muitas idéias para otimização.
A experiência acumulada trabalhando no JIT antes dos sete agora pode ser interpretada, observando os resultados em 7.0 sem o JIT e os resultados do HHVM com o JIT. No PHP 7.1, foi decidido não trabalhar com o JIT, mas novamente para o intérprete. Se anteriormente a otimização dizia respeito ao intérprete, neste artigo, examinaremos a otimização do bytecode, usando a inferência de tipo que foi implementada para o nosso JIT.
Sob o corte, Dmitry Stogov mostrará como tudo isso funciona, usando um exemplo simples.
Otimização de bytecode
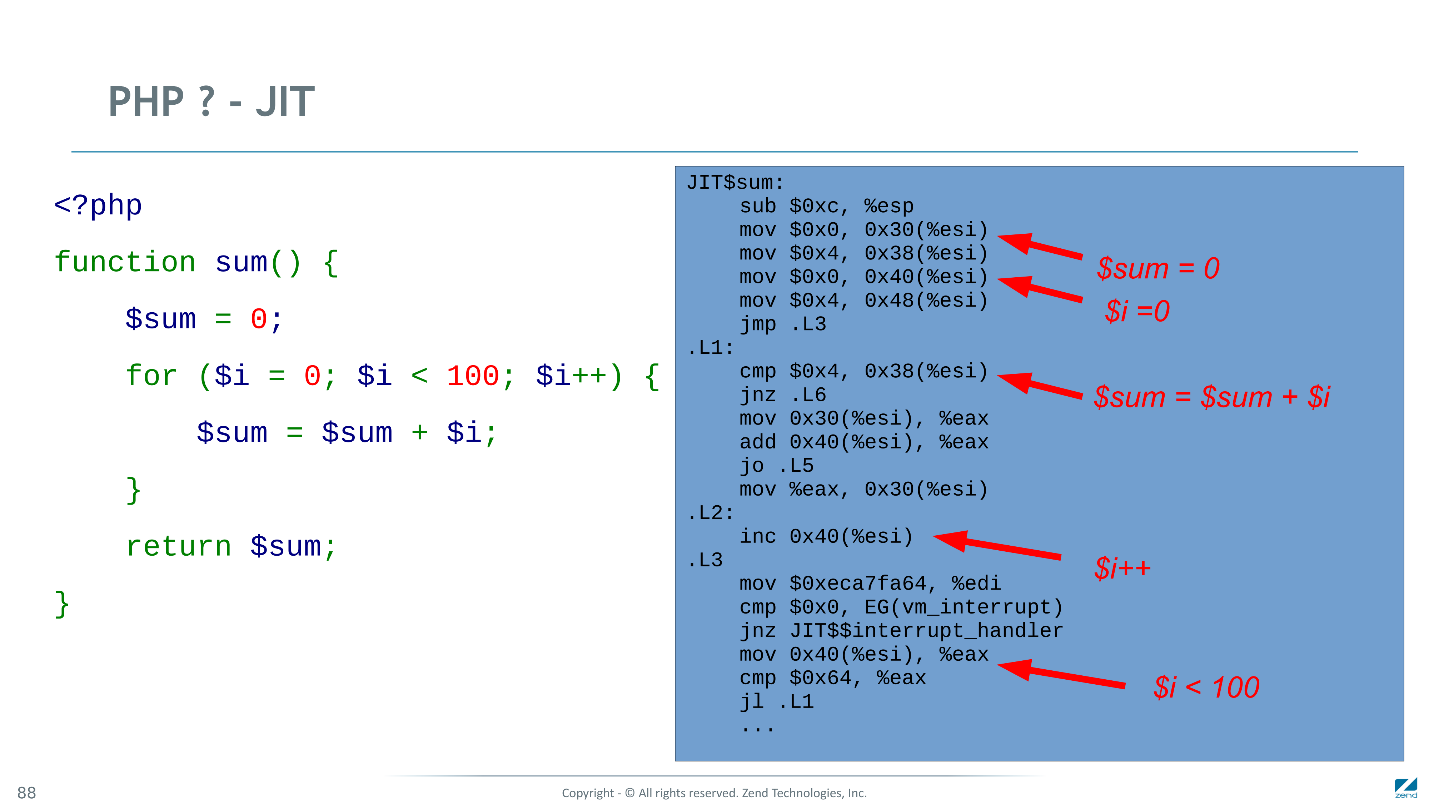
Abaixo está o bytecode no qual o compilador PHP padrão compila a função. É de passagem única - rápido e burro, mas capaz de executar seu trabalho em cada solicitação HTTP novamente (se o OPcache não estiver conectado).

Otimizações do OPcache
Com o advento do OPcache, começamos a otimizá-lo. Alguns métodos de otimização
foram incorporados ao OPcache , por exemplo, métodos de otimização de fendas - quando examinamos o código pelo olho mágico, procuramos padrões familiares e os substituímos por heurísticas. Esses métodos continuam a ser usados no 7.0. Por exemplo, temos duas operações: adição e atribuição.

Eles podem ser combinados em uma operação de atribuição composta, que executa a adição diretamente no resultado:
ASSIGN_ADD $sum, $i . Outro exemplo é uma variável pós-incremento que teoricamente poderia retornar algum tipo de resultado.

Pode não ser um valor escalar e deve ser removido. Para fazer isso, use as instruções
FREE seguir. Mas se você o alterar para um pré-incremento, a instrução
FREE não será necessária.

No final, existem duas instruções
RETURN : a primeira é um reflexo direto da instrução RETURN no texto de origem e a segunda é adicionada por um compilador burro com um colchete de fechamento. Este código nunca será alcançado e pode ser excluído.
Existem apenas quatro instruções restantes no loop. Parece que não há mais nada a otimizar, mas não para nós.
Veja o
$i++ e sua instrução correspondente - o pré-incremento
PRE_INC . Cada vez que é executado:
- precisa verificar que tipo de variável veio;
- se
is_long ; - realizar incremento;
- verifique se há excesso;
- vá para o próximo;
- talvez verifique a exceção.
Mas uma pessoa, apenas observando o código PHP, verá que a variável
$i está no intervalo de 0 a 100, e não pode haver estouro, as verificações de tipo não são necessárias e também não podem haver exceções.
No PHP 7.1, tentamos ensinar o compilador a entender isso .
Otimização do gráfico de fluxo de controle

Para fazer isso, é necessário deduzir tipos e, para inserir tipos, você deve primeiro criar uma representação formal dos fluxos de dados que o computador entende. Mas começaremos criando um gráfico de fluxo de controle, um gráfico de dependência de controle. Inicialmente, dividimos o código em blocos básicos - um conjunto de instruções com uma entrada e uma saída. Portanto, cortamos o código nos locais onde ocorre a transição, ou seja, nos rótulos L0, L1. Também o cortamos após os operadores de ramificação condicional e incondicional e, em seguida, conectamos-o a arcos que mostram as dependências para controle.

Então, nós temos CFG.
Otimização do formulário estático de atribuição única
Bem, agora precisamos de uma dependência de dados. Para fazer isso, usamos o Formulário de atribuição única estática - uma representação popular no mundo da otimização de compiladores. Isso implica que o valor de cada variável pode ser atribuído apenas uma vez.

Para cada variável, adicionamos um índice ou número de reencarnação. Em todos os lugares em que a tarefa ocorre, colocamos um novo índice e os usamos - até os pontos de interrogação, porque nem sempre é conhecido em todos os lugares. Por exemplo, na instrução
IS_SMALLER $ i pode vir tanto do bloco L0 com o número 4 quanto do primeiro bloco com o número 2.
Para resolver esse problema, o SSA introduz
a pseudo-função Phi , que, se necessário, é inserida no início do bloco básico->, pega todos os tipos de índices de uma variável que chegaram ao bloco básico de diferentes lugares e cria uma nova reencarnação da variável. São essas variáveis que são usadas mais tarde para eliminar a ambiguidade.

Substituindo todos os pontos de interrogação dessa maneira, criaremos o SSA.
Otimização de tipo
Agora deduzimos tipos - como se tentássemos executar esse código diretamente no gerenciamento.

No primeiro bloco, as variáveis recebem valores constantes - zeros, e sabemos com certeza que essas variáveis serão do tipo longa. A seguir, a função Phi. Long chega na entrada e não sabemos os valores de outras variáveis que vieram de outros ramos.

Acreditamos que a saída phi () teremos muito tempo.

Distribuímos mais. Chegamos a funções específicas, por exemplo,
ASSIGN_ADD e
PRE_INC . Adicione dois longos. O resultado pode ser longo ou duplo se ocorrer um estouro.

Esses valores caem novamente na função Phi, ocorre a união dos conjuntos de tipos possíveis que chegam em diferentes ramos. Bem e assim por diante, continuamos a nos espalhar até chegar a um ponto fixo e tudo se acalmar.

Temos um conjunto possível de valores de tipo em todos os pontos do programa. Isso já é bom. O computador já sabe que
$i só pode ser longo ou duplo e pode excluir algumas verificações desnecessárias. Mas sabemos que o dobro de
$i não pode ser. Como sabemos? E vemos uma condição que limita o crescimento de
$i no ciclo a um possível estouro. Ensinaremos o computador a ver isso.
Otimização da Propagação de Gama
Na instrução
PRE_INC nunca descobrimos que eu só posso ser um número inteiro - custa muito tempo ou dobro. Isso acontece porque não tentamos inferir possíveis intervalos. Em seguida, poderíamos responder à pergunta se o estouro ocorrerá ou não.
Essa saída dos intervalos é feita de maneira semelhante, mas um pouco mais complexa. Como resultado, obtemos um intervalo fixo de variáveis
$i com os índices 2, 4, 6 7 e agora podemos dizer com segurança que o incremento
$i não levará ao estouro.

Combinando esses dois resultados, podemos dizer com certeza que a variável dupla
$i nunca
$i se tornar.

Tudo o que temos ainda não é otimização, são informações para otimização! Considere a
ASSIGN_ADD . Em termos gerais, o valor antigo da soma que veio a esta instrução pode ser, por exemplo, um objeto. Depois da adição, o valor antigo deveria ter sido removido. Mas, no nosso caso, sabemos com certeza que existe um valor longo ou duplo, ou seja, um valor escalar. Nenhuma destruição é necessária, podemos substituir
ASSIGN_ADD por
ADD - uma instrução mais fácil.
ADD usa a variável
sum como argumento e valor.

Para operações de pré-incremento, sabemos com certeza que o operando é sempre longo e que os estouros não podem ocorrer. Utilizamos um manipulador altamente especializado para esta instrução, que executará apenas as ações necessárias sem nenhuma verificação.

Agora compare a variável no final do loop. Sabemos que o valor da variável será apenas longo - você pode verificar imediatamente esse valor comparando-o com cem. Se anteriormente registramos o resultado da verificação em uma variável temporária e, mais uma vez, verificamos se a variável temporária é verdadeira / falsa, agora isso pode ser feito com uma instrução, ou seja, simplificada.

Resultado de bytecode comparado ao original.

Restam apenas três instruções no ciclo e duas são altamente especializadas. Como resultado, o código à direita é
3 vezes mais rápido que o original.
Manipuladores altamente especializados
Qualquer
manipulador de rastreamento PHP é apenas uma função C. À esquerda, há um manipulador padrão e, no canto superior direito, é altamente especializado. O esquerdo verifica: o tipo do operando, se um estouro ocorreu, se uma exceção ocorreu. O certo apenas adiciona um e é isso. Isso se traduz em 4 instruções da máquina. Se formos além e fizermos o JIT, precisaremos apenas de uma instrução única
incl .

O que vem a seguir?
Continuamos a aumentar a velocidade do ramo 7 do PHP sem o JIT.
O PHP 7.1 será novamente 60% mais rápido em testes sintéticos típicos, mas em aplicativos reais isso quase não dá vitória - apenas 1-2% no WordPress. Isto não é particularmente interessante. Desde agosto de 2016, quando a ramificação 7.1 foi congelada para grandes mudanças, novamente começamos a trabalhar no JIT para PHP 7.2 ou melhor, PHP 8.
Em uma nova tentativa, usamos o
DynAsm para gerar o código, desenvolvido por Mike Paul
para LuaJIT-2 . É bom porque
gera código muito rapidamente : o fato de os minutos terem sido compilados na versão JIT no LLVM agora acontece em 0,1-0,2 s. Hoje, a
aceleração no bench.php no JIT é 75 vezes mais rápida que no PHP 5.
Não há aceleração em aplicativos reais, e este é o próximo desafio para nós. Em parte, obtivemos o código ideal, mas depois de compilar muitos scripts PHP, entupimos o cache do processador, para que não funcionasse mais rápido. E não a velocidade do código foi um gargalo em aplicativos reais ...
Talvez o DynAsm possa ser usado para compilar apenas determinadas funções que serão selecionadas por um programador ou por heurísticas baseadas em contadores - quantas vezes uma função foi chamada, quantas vezes os ciclos se repetem etc.
Abaixo está o código da máquina que nosso JIT gera para o mesmo exemplo. Muitas instruções são idealmente compiladas: incremento em uma instrução da CPU, inicialização variável para constantes em duas. Onde os tipos não são chocados, você precisa se preocupar um pouco mais.
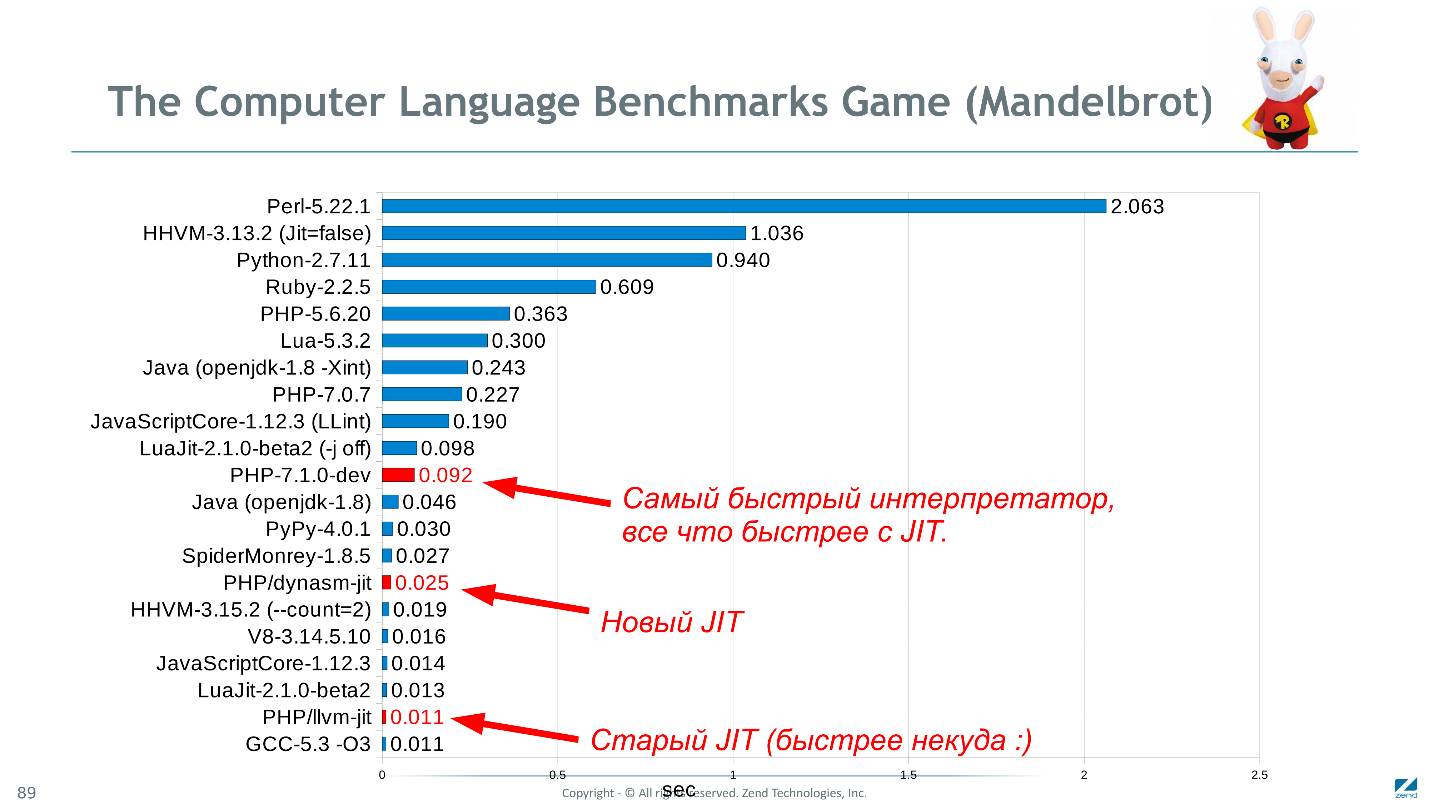
Retornando à imagem do título, o PHP, em comparação com idiomas semelhantes no teste de Mandelbrot, mostra resultados muito bons (embora os dados sejam relevantes no final de 2016).
O diagrama mostra o tempo de execução em segundos, menos é melhor.Talvez
Mandelbrot não seja o melhor teste. É computacional, mas simples e implementado igualmente em todas as línguas. Seria bom saber com que rapidez o Wordpress funcionaria em C ++, mas dificilmente existe uma esquisitice pronta para reescrevê-lo apenas para verificar e até repetir todas as perversões do código PHP. Se você tem idéias para um conjunto de benchmarks mais adequado - sugira.
Nos encontraremos no PHP Rússia em 17 de maio , discutiremos as perspectivas e o desenvolvimento do ecossistema e a experiência de usar o PHP em projetos realmente complexos e interessantes. Já está conosco:
Claro, isso está longe de tudo. E o Call for Papers ainda está fechado. Até 1º de abril, aguardamos aplicativos daqueles que podem aplicar abordagens modernas e práticas recomendadas para implementar serviços PHP legais. Não tenha medo da concorrência com palestrantes eminentes - estamos procurando experiência no uso do que eles fazem em projetos reais e ajudaremos a mostrar os benefícios de seus casos.