Sobre o que falaremos:Como implantar rapidamente o armazenamento compartilhado para dois servidores com base nas soluções drbd + ocfs2.
Para quem será útil:O tutorial será útil para administradores de sistema e para qualquer pessoa que escolher um método de implementação de armazenamento ou quiser tentar uma solução.
Que decisões recusamos e por que
Geralmente, nos deparamos com uma situação em que precisamos implementar um repositório comum em um pequeno cluster da web com bom desempenho de leitura e gravação. Tentamos várias opções para implementar um repositório comum para nossos projetos, mas pouco foi capaz de nos satisfazer imediatamente para vários indicadores. Agora vamos explicar o porquê.
- O Glusterfs não nos convinha com o desempenho de leitura e gravação, havia problemas com a leitura simultânea de um grande número de arquivos, havia uma alta carga na CPU. O problema com a leitura de arquivos pode ser resolvido aplicando-os diretamente no bloco, mas isso nem sempre é aplicável e geralmente incorreto.
- O Ceph não gostou da complexidade excessiva, que pode ser prejudicial em projetos com 2 a 4 servidores, principalmente se o projeto for atendido posteriormente. Novamente, existem sérias limitações de desempenho que o forçam a criar clusters de armazenamento separados, como no glusterfs.
- O uso de um servidor nfs para implementar o armazenamento compartilhado gera problemas de tolerância a falhas.
- O s3 é uma excelente solução popular para uma certa variedade de tarefas, mas não é um sistema de arquivos que restringe o escopo.
- lsyncd. Se já começamos a falar sobre "sistemas que não são arquivos", vale a pena analisar essa solução popular. Além de não ser adequado para trocas bidirecionais (mas se você realmente deseja, pode), também não funciona de maneira estável em um grande número de arquivos. Uma boa adição a tudo será que ele é de thread único. O motivo está na arquitetura do programa: ele usa o inotify para monitorar os objetos de trabalho pendurados na inicialização e durante a nova verificação. Rsync é usado como meio de transmissão.
Tutorial: como implantar armazenamento compartilhado com base em drbd + ocfs2
Uma das soluções mais convenientes para nós foi um monte de
ocfs2 + drbd . Agora, mostraremos como implantar rapidamente o armazenamento compartilhado para dois servidores com base em um banco de dados de soluções. Mas primeiro, um pouco sobre os componentes:
DRBD é o sistema de armazenamento padrão do Linux que permite que os dados sejam replicados entre os blocos do servidor. A principal aplicação é a criação de armazenamento tolerante a falhas.
O OCFS2 é um sistema de arquivos que fornece uso compartilhado do mesmo armazenamento por vários sistemas. Incluído na distribuição do Linux, há um módulo do kernel e ferramentas de espaço do usuário para trabalhar com o FS. O OCFS2 pode ser usado não apenas na parte superior do DRBD, mas também na parte superior do iSCSI com várias conexões. No nosso exemplo, usamos DRBD.
Todas as ações são executadas no servidor ubuntu 18.04 em uma configuração mínima.
Etapa 1. Configure o DRBD:
No arquivo /etc/drbd.d/drbd0.res, descrevemos nosso dispositivo de bloco virtual / dev / drbd0:
resource drbd0 { syncer { rate 1000M; } net { allow-two-primaries; after-sb-0pri discard-zero-changes; after-sb-1pri discard-secondary; after-sb-2pri disconnect; } startup { become-primary-on both; } on drbd1 { meta-disk internal; device /dev/drbd0; disk /dev/vdb1; address 10.10.10.192:7789; } on drbd2 { meta-disk internal; device /dev/drbd0; disk /dev/vdb1; address 10.10.10.193:7789; } }
meta-disco interno - use os mesmos dispositivos de bloco para armazenar metadados
device / dev / drbd0 - use / dev / drbd0 como o caminho para o volume drbd.
disk / dev / vdb1 - use / dev / vdb1
sincronizador {taxa de 1000 milhões; } - use largura de banda do canal gigabit
allow-two-primaries - uma opção importante para permitir a aceitação de alterações em dois servidores principais
after-sb-0pri, after-sb-1pri, after-sb-2pri - opções responsáveis pelas ações do nó quando o splitbrain é detectado. Veja a documentação para mais detalhes.
torne-primário-em ambos - define os dois nós como primário.
No nosso caso, temos duas VMs absolutamente idênticas, com uma largura de banda de rede virtual dedicada de 10 gigabits.
No nosso exemplo, os nomes de rede de dois nós do cluster são drbd1 e drbd2. Para uma operação adequada, você deve mapear os nomes e endereços IP dos nós em / etc / hosts.
10.10.10.192 drbd1 10.10.10.193 drbd2
Etapa 2. Configure os nós:Nos dois servidores, executamos:
drbdadm create-md drbd0
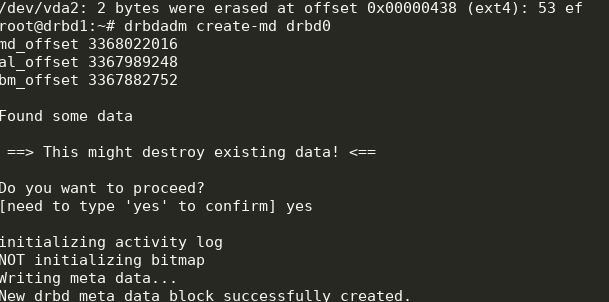
modprobe drbd drbdadm up drbd0 cat /proc/drbd
Temos o seguinte:

Você pode iniciar a sincronização. No primeiro nó, você precisa fazer:
drbdadm primary --force drbd0
Nós olhamos para o status:
cat /proc/drbd

Ótimo, a sincronização começou. Estamos aguardando o fim e veja a foto:
 Etapa 3. Iniciamos a sincronização na segunda nota:
Etapa 3. Iniciamos a sincronização na segunda nota: drbdadm primary --force drbd0
Temos o seguinte:

Agora podemos escrever no drbd a partir de dois servidores.
Etapa 4. Instale e configure o ocfs2.Usaremos uma configuração bastante trivial:
cluster: node_count = 2 name = ocfs2cluster node: number = 1 cluster = ocfs2cluster ip_port = 7777 ip_address = 10.10.10.192 name = drbd1 node: number = 2 cluster = ocfs2cluster ip_port = 7777 ip_address = 10.10.10.193 name = drbd2
Ele precisa ser escrito em
/etc/ocfs2/cluster.conf nos dois nós.
Crie FS no drbd0 em qualquer nó:
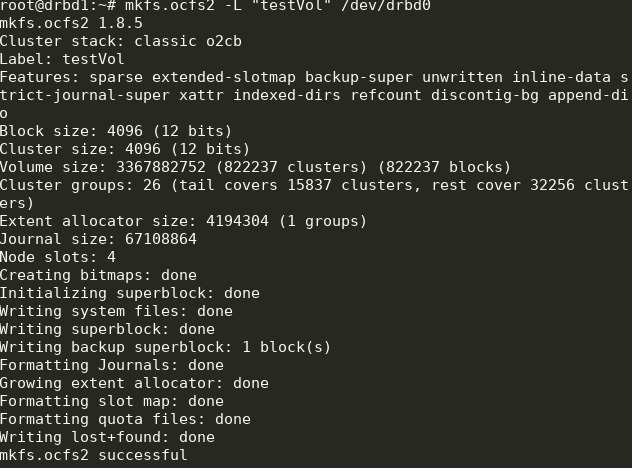
mkfs.ocfs2 -L "testVol" /dev/drbd0
Aqui, criamos um sistema de arquivos chamado testVol em drbd0 usando as configurações padrão.
Em / etc / default / o2cb deve ser definido (como em nosso arquivo de configuração)
O2CB_ENABLED=true O2CB_BOOTCLUSTER=ocfs2cluster
e execute em cada nó:
o2cb register-cluster ocfs2cluster
Depois disso, ligue e adicione à inicialização todas as unidades que precisamos:
systemctl enable drbd o2cb ocfs2 systemctl start drbd o2cb ocfs2
Parte disso já estará em execução durante o processo de instalação.
Etapa 5. Adicione pontos de montagem ao fstab nos dois nós: /dev/drbd0 /media/shared ocfs2 defaults,noauto,heartbeat=local 0 0
O diretório
/ media / shared deve ser criado com antecedência.
Aqui, usamos as opções noauto, o que significa que o FS não será montado na inicialização (eu prefiro montar o FS da rede via systemd) e o heartbeat = local, o que significa usar o serviço de heartbeat em cada nó. Há também um batimento cardíaco global, mais adequado para clusters grandes.
Em seguida, você pode montar
/ media / shared e verificar a sincronização do conteúdo.
Feito! Como resultado, obtemos um armazenamento mais ou menos tolerante a falhas com escalabilidade e desempenho decente.