Ao trabalhar com vários clientes ao mesmo tempo, torna-se necessário analisar rapidamente muitas informações em diferentes contas e relatórios. Quando há mais de 10 clientes, o profissional de marketing não tem mais tempo para monitorar constantemente as estatísticas. Mas existe um caminho.
Neste artigo, falarei sobre como monitorar contas de publicidade usando a API e o Python.
Na saída, receberemos uma solicitação para a API Yandex.Direct, com a qual receberemos estatísticas sobre campanhas publicitárias e poderemos processar esses dados.
Para isso, precisamos:
- Obter o token da API do Yandex Direct
- Escreva uma solicitação do servidor
- Importar dados para o DataFrame
Importar bibliotecas
Você precisa importar as bibliotecas usadas na consulta, bem como os pandas e o DataFrame.
Todas as importações terão a seguinte aparência:
import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame
Recebendo token
No momento, não posso dizer melhor do que a documentação da API Yandex.Direct, então deixarei um link.
(
Instruções para obter um token )
Estamos escrevendo uma solicitação para o servidor da API Yandex.Direct
Copie a solicitação da documentação da APIMude a solicitação.- Prescreva seu token e faça o login
Token.
token = 'blaBlaBLAblaBLABLABLAblabla'
Entrar
clientLogin = 'e-66666666'
- Ajustamos o corpo da solicitação por nós mesmos.
A partir disso
body = { "params": { "SelectionCriteria": { "DateFrom": "_", "DateTo": "_" }, "FieldNames": [ "Date", "CampaignName", "LocationOfPresenceName", "Impressions", "Clicks", "Cost" ], "ReportName": u("_"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "CUSTOM_DATE", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO"
Faça
body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": « ", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } }
Em
SelectionCriteria , escrevemos como selecionaremos os dados. Por padrão, duas datas são escritas lá, mas para não precisar alterá-las constantemente, substituiremos o período por "Últimos 5 dias".
Nós configuramos o filtro para dados . Isso é necessário principalmente para não obter valores vazios. O problema é que o Direct mostra os dados ausentes como dois menos, por causa dos quais o tipo de dados de toda a coluna é alterado, após o qual você não pode executar operações matemáticas sem gestos desnecessários.
FieldNames Escrevemos aqui os dados que você precisa. Registrei os campos que utilizo para análise; sua lista pode ser diferente.
ReportType O tipo de relatório é escrito neste campo. Para campanhas, esse relatório é necessário.
Você deve obter algo parecido com isto.
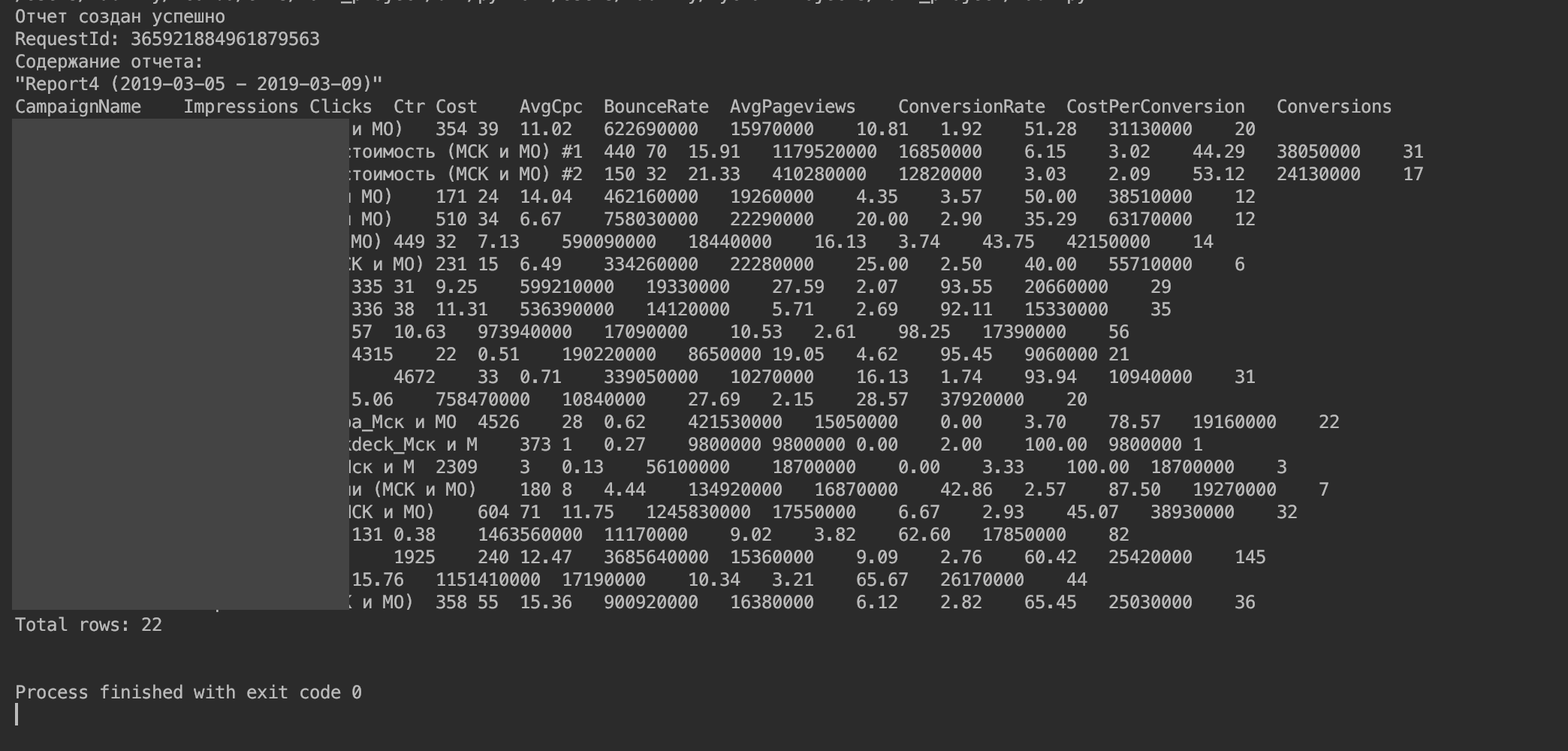
5. Importe os dados para um DataFrame.
(Um DataFrame é provavelmente a maneira mais apropriada de trabalhar com esses dados.)
Consegui implementar essa função escrevendo e lendo um arquivo csv.
Encontramos na consulta a parte responsável pela saída das estatísticas - este é "req.text".
Excluímos a saída padrão do programa para gravar no arquivo. Para fazer isso, altere todas as conclusões no código 200.
print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print(" : \n{}».format(u(req.text)))
Ativado:
format(u(req.text))
Agora importe a resposta do servidor para o DataFrame.
file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,)
Passo a passo:
- Abra (e crie automaticamente) o arquivo cashe.csv para gravar
- Nós escrevemos a resposta do servidor nele
- Feche o arquivo
- Abra o arquivo como um DataFrame (especifique o nome do arquivo, em que linha estão os cabeçalhos da tabela, qual é o divisor entre os dados e em que coluna está o índice)
O resultado foi o seguinte:
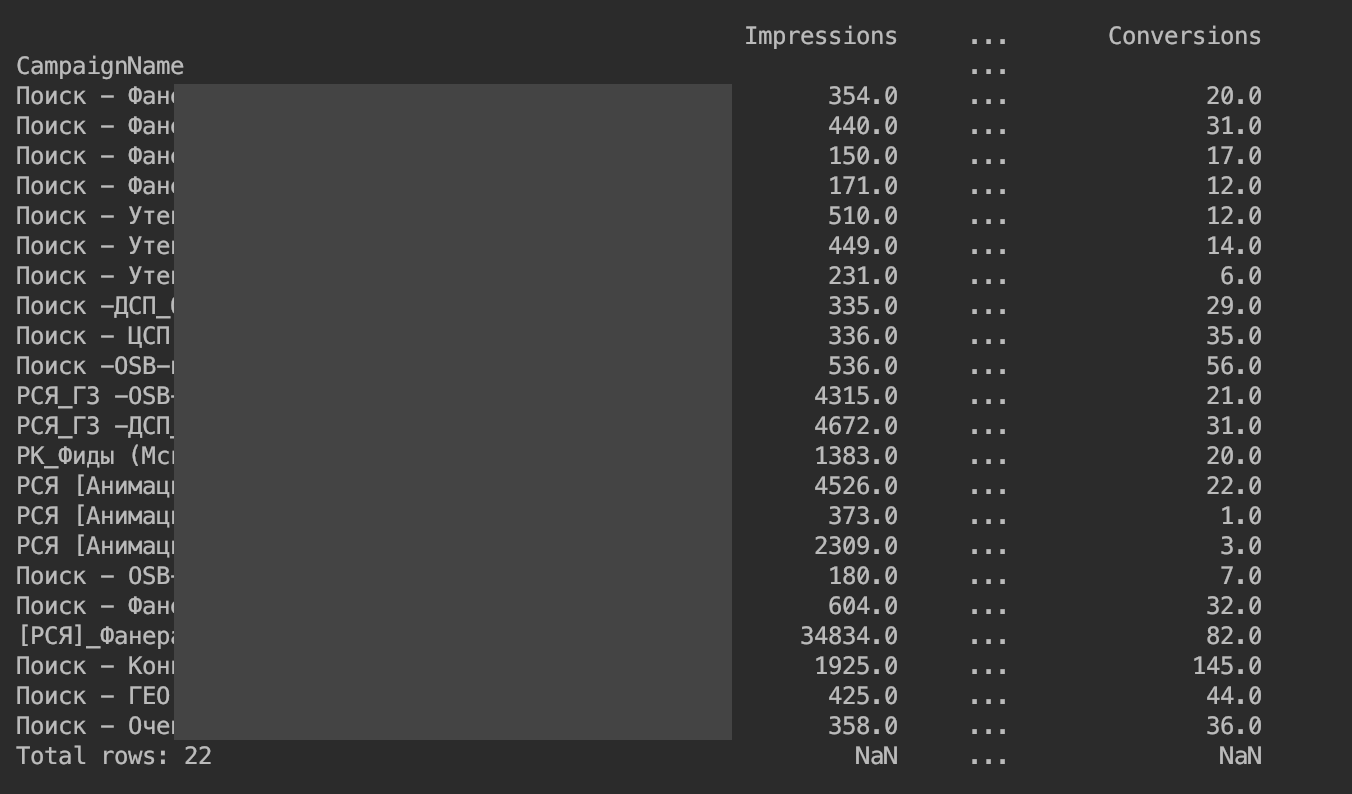
Removemos a restrição na saída das colunas:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1)
Agora tudo é mostrado:
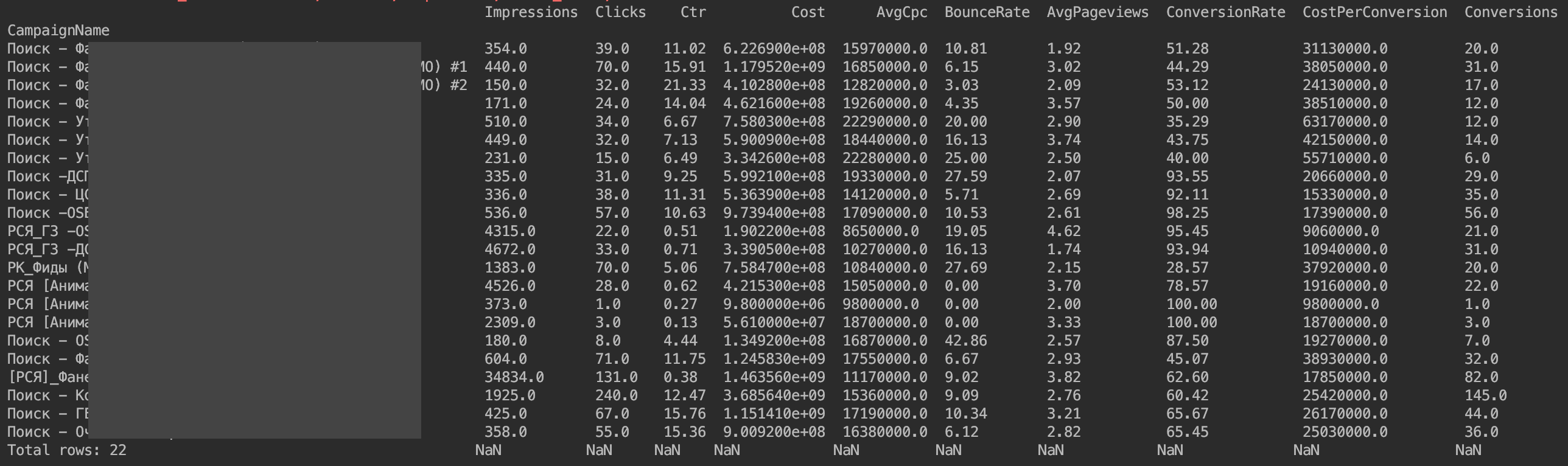
O único problema é que os valores monetários não são mostrados como gostariam. Esses são os recursos da implementação da API Yandex.Direct. Só precisamos dividir os valores monetários por 1.000.000.
f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000
Também sugiro classificar imediatamente pelo número de cliques
f=f.sort_values(by=['Clicks'], ascending=False)
Então, preparamos o DataFrame para análise
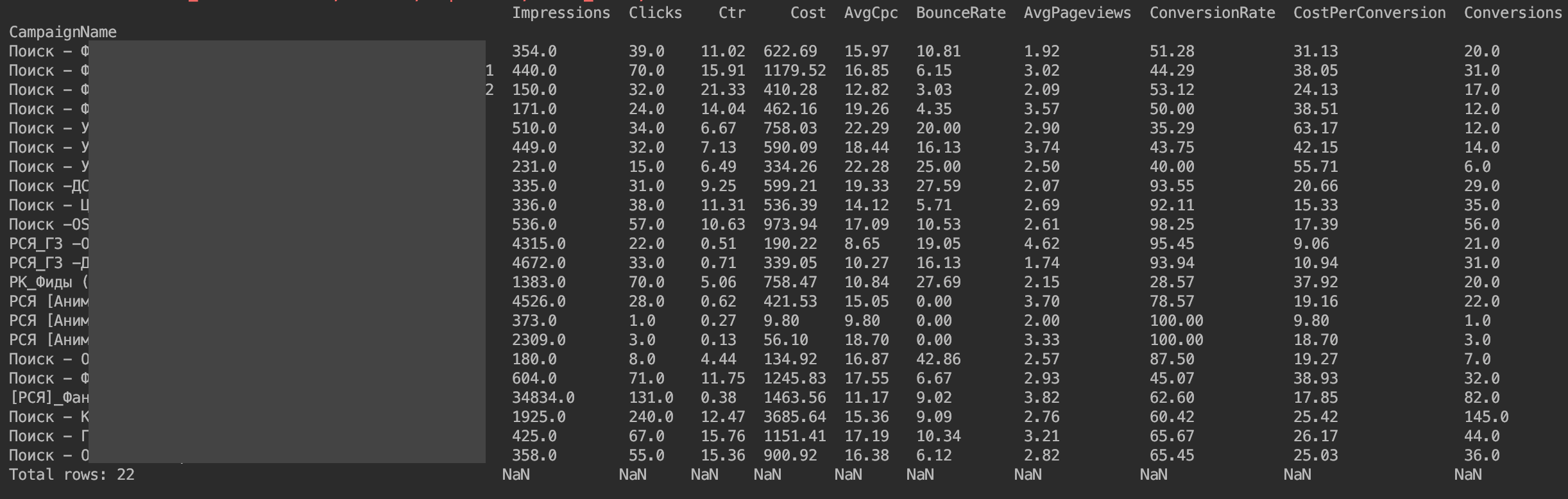
Para mim, escrevi solicitações semelhantes de estatísticas por dia e por campanha, para estar sempre atento aos desvios de tráfego e entender onde o desvio ocorreu aproximadamente.
Obrigado pela atenção.
Código final: import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) # UTF-8 Python 3, Python 2 import sys if sys.version_info < (3,): def u(x): try: return x.encode("utf8") except UnicodeDecodeError: return x else: def u(x): if type(x) == type(b''): return x.decode('utf8') else: return x # --- --- # Reports JSON- () ReportsURL = 'https://api.direct.yandex.com/json/v5/reports' # OAuth- , token = ' ' # # , clientLogin = ' ' # --- --- # HTTP- headers = { # OAuth-. Bearer "Authorization": "Bearer " + token, # "Client-Login": clientLogin, # "Accept-Language": "ru", # "processingMode": "auto" # # "returnMoneyInMicros": "false", # # "skipReportHeader": "true", # # "skipColumnHeader": "true", # # "skipReportSummary": "true" } # body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } } # JSON body = json.dumps(body, indent=4) # --- --- # HTTP- 200, # HTTP- 201 202, while True: try: req = requests.post(ReportsURL, body, headers=headers) req.encoding = 'utf-8' # UTF-8 if req.status_code == 400: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(u(body))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 200: format(u(req.text)) break elif req.status_code == 201: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 202: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 500: print(" . , ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 502: print(" .") print(", - .") print("JSON- : {}".format(body)) print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break else: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(body)) print("JSON- : \n{}".format(u(req.json()))) break # , API except ConnectionError: # print(" API") # break # - except: # print(" ") # break file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,) f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000 f=f.sort_values(by=['Clicks'], ascending=False) print(f)