Continuamos a publicar vídeos e transcrições dos melhores relatórios da conferência
PGConf.Russia 2019 . Um relatório de Oleg Bartunov sobre o tópico "Postgres profissionais" abriu a parte plenária da conferência. Ele revela a história do Postgres DBMS, a contribuição da Rússia para o desenvolvimento, os recursos de arquitetura.
Materiais anteriores desta série: “Erros típicos ao trabalhar com o PostgreSQL” de Ivan Frolkov, partes
1 e
2 .

Vou falar sobre o Postgres profissional. Por favor, não confunda com a empresa que represento agora - o Postgres Professional.

Eu realmente vou falar sobre como o Postgres, que começou como um desenvolvimento acadêmico amador, se tornou profissional - da maneira que vemos agora. Expressarei apenas minha opinião pessoal, que não reflete a opinião de nossa empresa ou de nenhum grupo.

Aconteceu que eu uso e não faço trechos do Postgres, mas continuamente desde 1995 até o presente. Toda a sua história passou diante dos meus olhos, sou participante dos principais eventos.
A história
Neste slide, descrevi brevemente os projetos dos quais participei. Muitos deles são familiares para você. E começarei a história do Postgres imediatamente com uma imagem que eu pintei muitos, muitos anos atrás e depois a redigi - o número de versões está aumentando e aumentando. Reflete a evolução dos bancos de dados relacionais. À esquerda, se alguém não souber, esse é
Michael Stonebreaker , que é chamado o pai do Postgres. Abaixo estão nossos primeiros desenvolvedores "nucleares". A pessoa sentada à direita é Vadim Mikheev, de Krasnoyarsk, ele foi um dos primeiros desenvolvedores principais.
Iniciarei a história do modelo relacional com a IBM, que fez uma enorme contribuição para o setor. Foi a IBM que trabalhou para
Edgar Codd , o primeiro white paper sobre o
IBM System R apareceu de suas entranhas - foi o primeiro banco de dados relacional. Mike Stonebreaker trabalhou naquela época em Burkeley. Ele leu este artigo e pegou fogo com seus colegas: precisamos criar um banco de dados.

Naqueles anos - no início dos anos 70 - como você suspeita, não havia muitos computadores. Havia um PDP-11 para todo o departamento de Ciência da Computação em Berkeley, e todos os estudantes e professores lutavam pelo tempo das máquinas. Esta máquina foi usada principalmente para cálculos. Eu mesmo trabalhei assim quando era jovem: você dá uma tarefa ao operador, ele a inicia. Mas estudantes e desenvolvedores queriam trabalho interativo. Era o nosso sonho - sentar no controle remoto, inserir programas, depurá-los. E quando Mike Stonebreaker e seus amigos fizeram a primeira base, eles o chamaram de
Ingres - o Sistema de Recuperação Gráfica Interativa. As pessoas não entendiam: por que interativo? E foi apenas o sonho de seus desenvolvedores que se tornou realidade. Eles tinham um cliente de console com o qual podiam trabalhar com Ingres. Ele deu grande parte da nossa indústria. Você vê quantas flechas existem de Ingres? Esses são os bancos de dados que ele influenciou, o que atrapalhou seu código. Michael Stonebreaker teve muitos estudantes de desenvolvimento que deixaram e desenvolveram
Sybase e
MS SQL ,
NonStop SQL ,
Illustra ,
Informix .
Quando Ingres desenvolveu tanto que se tornou comercialmente interessante, a
Illustra foi formada (este foi o ano de 1992) e o código do DBMS da
Illustra foi comprado pelo
Informix , que mais tarde foi comido pela
IBM e, portanto, o código foi para o
DB2 . Mas o que interessou a
IBM em
Ingres ? Antes de tudo, extensibilidade - aquelas idéias revolucionárias que Michael Stonebreaker colocou desde o início, pensando que o banco de dados deveria estar pronto para resolver qualquer problema de negócios. E para isso é necessário que você possa adicionar seus tipos de dados, métodos de acesso e funções ao banco de dados. Agora, para nós pós-geradores, isso parece natural. Naqueles anos, foi uma revolução. Desde o tempo de Ingres e Postgres, esses recursos, essa funcionalidade se tornou o padrão de fato para todos os bancos de dados relacionais. Agora todos os bancos de dados têm funções de usuário e, quando o Stonebreaker escreveu que as funções de usuário são necessárias, a
Oracle , por exemplo, gritou que era perigoso e que isso não pôde ser feito porque os usuários poderiam prejudicar os dados. Agora vemos que existem funções definidas pelo usuário em todos os bancos de dados, para que você possa criar seus próprios agregados e tipos de dados.

O Postgres se desenvolveu como um desenvolvimento acadêmico, o que significa: existe um professor, ele tem uma bolsa para o desenvolvimento, estudantes e estudantes de pós-graduação que trabalham com ele. Uma base séria, pronta para produção, não pode ser feita assim. No entanto, a versão mais recente de Berkeley -
Postgres95 - já adicionou
SQL . Os desenvolvedores estudantis da época já começaram a trabalhar na Illustra, criaram o Informix e perderam o interesse no projeto. Eles disseram: nós temos o Postgres95, leve quem precisar! Lembro-me muito bem disso porque fui eu mesmo quem recebi essa carta: havia uma lista de discussão e havia menos de 400 assinantes nela. A comunidade do
Postgres95 começou com essas 400 pessoas. Todos nós votamos juntos no projeto. Encontramos um entusiasta que pegou o servidor CVS e arrastamos tudo para o Panamá, já que os servidores estavam lá.
A história do
PostgreSQL [simplesmente o Postgres daqui em diante] começa com a versão 6.0, uma vez que as versões 1, 4, 5 ainda eram o Postgres95. Em 3 de abril de 1997, nosso logotipo apareceu - um elefante. Antes disso, tínhamos animais diferentes. Na minha página, por exemplo,
houve uma chita por um longo tempo , sugerindo que o Postgres é muito rápido. Então uma pergunta foi levantada na lista de discussão: nosso grande banco de dados precisa de um animal sério. E alguém escreveu: que seja um elefante. Todos votaram juntos, então nossos caras de São Petersburgo desenharam esse logotipo. Inicialmente, era um elefante em um diamante - se você se aprofundar em uma máquina do tempo, verá. O elefante foi escolhido porque os elefantes têm uma memória muito boa. Até Agatha Christie tem uma história “Os elefantes podem se lembrar”: o elefante é muito vingativo, ele se lembrou do crime por cerca de cinquenta anos e depois esmagou o agressor. O diamante foi então separado, o padrão vetorizado, e o resultado foi este elefante. Portanto, esta é uma das primeiras contribuições da Rússia para o Postgres.

Cheetah substituiu Elephant no diamante:

Etapas de desenvolvimento do Postgres
A primeira tarefa foi estabilizar seu trabalho. A comunidade adotou o código fonte para desenvolvedores acadêmicos. O que não estava lá! Eles começaram a cavar tudo isso para compilar decentemente. Neste slide, destaquei o ano de 1997, versão 6.1 - a internacionalização apareceu nele. Eu o destaquei não porque eu mesmo fiz (realmente foi meu primeiro patch), mas porque foi uma etapa importante. Você já está acostumado com o fato de o Postgres funcionar com qualquer idioma, em qualquer local - em todo o mundo. E então ele entendeu apenas ASCII, isto é, sem 8 bits, sem idiomas europeus, sem russo. Tendo descoberto isso, seguindo os princípios do código aberto, eu apenas peguei e fiz o suporte para localidades. E, graças a este trabalho, o Postgres foi ao mundo. Depois de mim, o japonês
Tatsuo Ishii fez suporte para codificações multibyte, e o Postgres se tornou verdadeiramente mundial.
Em 2005,
o suporte ao
Windows foi introduzido. Lembro-me desses debates acalorados quando eles discutiam isso na lista de discussão. Todos os desenvolvedores eram pessoas normais, eles trabalhavam no
Unix . Você está aplaudindo agora e da mesma maneira que as pessoas reagiram. E votou contra. Durou anos. Além disso, a
SRA Computers lançou seu
Powergres , uma porta nativa do Windows, alguns anos antes. Mas era um produto puramente japonês. Quando em 2005, na 8ª versão, obtivemos suporte para o Windows, verificou-se que esse era um passo forte: a comunidade estava inchada. Havia muitas pessoas e muitas perguntas estúpidas, mas a comunidade se tornou grande, agarramos usuários vinduzovye.
Em 2010, tivemos replicação integrada. Isso é uma dor. Lembro-me de quantos anos as pessoas lutaram pela replicação no Postgres. No início, todos disseram: não precisamos de replicação, isso não é uma questão de banco de dados, é uma questão de utilitários externos. Se alguém se lembra,
Slony fez Jan Wieck. A propósito, "elefantes" também vieram do idioma russo: Jan me perguntou quantos "elefantes" haveriam em russo, e eu respondi: "elefantes". Então ele fez Slony. Esses elefantes funcionavam como replicação lógica em gatilhos, configurá-los era um pesadelo - lembram-se os veteranos. Além disso, todos ouviram por muito tempo
Tom Lane , que, lembro-me, gritava desesperadamente: por que deveríamos complicar o código com a replicação se isso pode ser feito fora da base? Mas, como resultado, a replicação em linha ainda apareceu. Isso gerou imediatamente um grande número de usuários corporativos, porque antes disso, esses usuários diziam: como podemos viver sem replicação? Isso é impossível!
Em 2014, o jsonb apareceu. Este é o meu trabalho,
Fedor Sigaev e
Alexander Korotkov . E também o povo gritou: por que precisamos disso? Em geral, já tínhamos o hstore, que fabricamos em 2003, e em 2006 ele entrou no Postgres. As pessoas o usavam lindamente em todo o mundo, adoravam e, se você digitar
hstore no google, uma enorme quantidade de documentos era exibida. Extensão muito popular. E promovemos fortemente a ideia de dados não estruturados no Postgres. Desde o início do meu trabalho, eu estava interessado nisso e, quando fizemos o
jsonb , recebi muitas cartas de agradecimento e perguntas. E a comunidade tem usuários
NoSQL ! Antes do jsonb, as pessoas zumbificadas pelo hype passavam para o valor-chave do banco de dados. Ao mesmo tempo, eles foram forçados a sacrificar a integridade, a identidade
ACID . E nós demos a eles a oportunidade, sem sacrificar nada, de trabalhar com seu belo json. A comunidade cresceu acentuadamente novamente.
Em 2016, obtivemos a execução de consultas paralelas. Se alguém não souber, é claro que isso não é para
OLTP. Se você possui uma máquina carregada, todos os kernels já estão ocupados. A execução simultânea de consultas é valiosa para usuários
OLAP . E eles gostaram, ou seja, um certo número de usuários
OLAP começou a chegar à comunidade.
Em seguida vieram os processos cumulativos. Em 2017, recebemos replicação lógica e particionamento declarativo - também foi um passo grande e sério, porque a replicação lógica tornou possível a criação de sistemas muito, muito interessantes, as pessoas obtiveram liberdade ilimitada para sua imaginação e começaram a criar agrupamentos. Usando o particionamento declarativo, tornou-se possível não criar partições manualmente, mas usando o SQL.
Em 2018, na 11ª versão, obtivemos o
JIT . Quem não sabe, este é o compilador Just In Time: você compila solicitações e pode realmente acelerar muito a execução. Isso é importante para acelerar as consultas lentas, porque as consultas rápidas já são rápidas e a sobrecarga para compilação ainda é significativa.
Em 2019, a coisa mais básica que esperamos é o
armazenamento conectável, uma API para que os desenvolvedores possam criar seus próprios repositórios, um exemplo do que é
zheap - o repositório que o
EnterpriseDB está desenvolvendo.
E aqui está o nosso desenvolvimento: SQL / JSON. Eu realmente esperava que
Sasha Korotkov o comprometesse antes da conferência, mas havia alguns problemas lá, e agora esperamos que, do mesmo modo, tenhamos
SQL / JSON este ano. As pessoas esperam por isso há dois anos [uma parte significativa do patch SQL / JSON: jsonpath foi confirmada agora, isso é descrito em detalhes
aqui ].

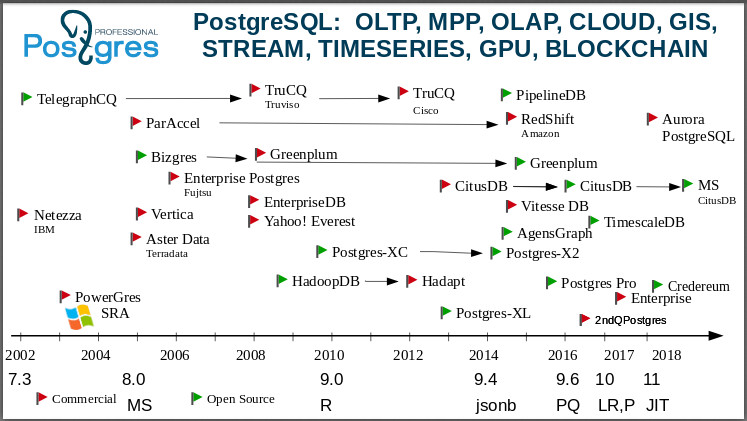
A seguir, passo para um slide que mostra: O Postgres é um banco de dados universal. Você pode estudar essa imagem por horas, contar várias histórias sobre o surgimento de empresas, a aquisição, a morte de empresas. Vou começar no ano de 2000. Um dos primeiros garfos do Postgres é o IBM
Netezza . Imagine: o “Gigante Azul” pegou o código do Postgres e construiu uma base para o OLAP suportar seu BI!
Aqui está uma bifurcação do
TelegraphCQ : já em 2000, as pessoas criaram um banco de dados de streaming baseado no Postgres em Berkeley. Se alguém não souber, esse é um banco de dados que não está interessado nos dados em si, mas em seus agregados. Agora, existem muitas tarefas nas quais você não precisa conhecer cada valor, por exemplo, a temperatura em algum momento, mas precisa de um valor médio nessa região. E no TelegraphCQ eles pegaram essa ideia (também surgida em Berkeley), uma das idéias mais avançadas da época, e desenvolveram uma base baseada no Postgres. Ele evoluiu ainda mais e, em 2008, com base em um produto comercial, foi lançado - a base
TruCQ , agora sua proprietária é a
Cisco .
Esqueci de dizer que nem todos os garfos estão nesta página, há o dobro deles. Eu escolhi o mais importante e interessante, para não confundir a imagem. A
página wiki do postgresql lista todos os garfos. Quem conhece um banco de dados de código aberto que teria tantos garfos? Não existem tais bases.
O Postgres difere de outros bancos de dados não apenas em sua funcionalidade, mas também em
uma comunidade muito interessante, normalmente aceita garfos. No mundo do código aberto, geralmente é aceito: fiz uma bifurcação porque fiquei ofendido - você não me apoiou, então decidi conduzir meu próprio desenvolvimento. No mundo pós-grego, a aparência de um garfo significa: algumas pessoas ou alguma empresa decidiram fazer algum protótipo e testar a funcionalidade que inventaram, para experimentar. E se você tiver sorte, crie uma base comercial que possa ser vendida aos clientes, forneça-lhes serviços e assim por diante. Ao mesmo tempo, em regra, os desenvolvedores de todos esses garfos retornam suas conquistas e patches à comunidade. O produto da nossa empresa também é de garfo e é claro que devolvemos vários patches de volta à comunidade. Na última versão 11, retornamos mais de 100 patches para a comunidade. Se você olhar as notas de versão dela, haverá 25 nomes de nossos funcionários. Esse é um comportamento normal da comunidade. Usamos a versão da comunidade e fazemos o garfo para testar nossas idéias ou oferecer funcionalidade aos clientes antes que a comunidade amadureça para sua adoção. Forks na comunidade Postgres são muito bem-vindos.
O famoso
Vertica veio da
C-Store - também cresceu do Postgres. Algumas pessoas afirmam que o Vertica não possuía o código-fonte do Postgres, mas apenas o suporte ao protocolo do postgres. No entanto, é habitual classificá-lo como garfos pós-gregos.
Greenplum . Agora você pode baixá-lo e usá-lo como um cluster. Ele se originou do
Bizgres , um banco de dados paralelo em massa. Depois foi comprado pela Greenplum, tornou-se e por muito tempo permaneceu comercial. Mas você vê que, por volta de 2015, eles perceberam que o mundo mudou: o mundo está se movendo em direção a protocolos abertos, comunidades abertas, bancos de dados abertos. E eles abriram os códigos Greenplum. Agora eles estão atualizando ativamente o Postgres porque ficaram para trás, é claro, muito. Eles mudaram para 8,2 e agora dizem que alcançaram 9,6.
Todos nós amamos e não gostamos da
Amazônia . Você sabe como isso aconteceu. Isso aconteceu diante dos meus olhos. Havia uma empresa, o
ParAccel com processamento vetorial, também no Postgres - um produto comunitário, aberto. Em 2012, a esperta Amazon comprou o código-fonte e, literalmente, seis meses depois anunciou que agora temos
RDS na Amazon. Nós então perguntamos a eles, eles hesitaram por um longo tempo, mas depois descobriu-se que era o Postgres. O RDS ainda vive, e este é um dos serviços mais populares da Amazon, eles têm cerca de 7.000 bases girando por lá. Mas eles não se acalmaram e, em 2010, o Amazon Aurora apareceu - o Postgres 10 com uma história reescrita que é costurada diretamente na infraestrutura da Amazon, em seu armazenamento distribuído.
Dê uma olhada agora no
Teradata . Uma grande e boa empresa de análise antiga, a
OLAP . Após o G8 [PostgreSQL 8.0], o
Aster Data surgiu.
Hadoop : temos o Postgres no Hadoop -
HadoopDB . Depois de um tempo, tornou-se uma base
Hadapt fechada de propriedade da
Teradata . Se você vir o Hadapt, saiba o que há no Postgres.
Um destino muito interessante com o
Citus . Todo mundo sabe que este é o Postgres distribuído para análises online. Não suporta transações.
O Citus Data era uma startup e o Citus era de código fechado, um banco de dados separado. Depois de algum tempo, as pessoas perceberam que era melhor viver com a comunidade, se abrir. E eles fizeram muito para se tornar apenas uma extensão do Postgres. Além disso, eles começaram a fazer negócios já no fornecimento de seus serviços em nuvem. Todos vocês já sabem: o
MS Citus foi escrito aqui porque a
Microsoft os comprou, literalmente, há duas semanas. Provavelmente, para oferecer suporte ao Postgres em seu
Azure , ou seja, a Microsoft também joga esses jogos. Eles têm o Postgres em execução no Azure, e a equipe de desenvolvimento do Citus se juntou aos desenvolvedores da MS.
Em geral, recentemente, os processos de compra de empresas pós-gráficas foram intensamente. Logo após a Microsoft comprar a Citus, outra empresa de
pós-venda ,
credativ , comprou a
OmniTI para fortalecer sua presença no mercado. Essas são duas empresas sólidas e bem conhecidas. E a Amazon comprou o
OpenSCG . O mundo do postgres está mudando agora, e eu mostrarei a você por que há tanto interesse no Postgres.
O
aclamado TimescaleDB também
era um banco de dados separado, mas agora é uma extensão: você pega o Postgres e instala o timescaledb como uma extensão e obtém um banco de dados que quebra todos os tipos de bancos de dados especializados.
Há também o Postgres XL, existem clusters em desenvolvimento.
Aqui em 2015, eu montei nosso garfo:
Postgres Pro . Temos o
Postgres Pro Enterprise , existe uma versão certificada, suportamos o
1C imediatamente e somos reconhecidos pelo
1C . Se alguém quiser experimentar o Postgres Pro Enterprise, você pode pegar o kit de distribuição gratuitamente e, se precisar dele para trabalhar, pode comprá-lo.
Criamos o
Credereum , um banco de dados protótipo com suporte a blockchain. Agora estamos aguardando o amadurecimento das pessoas para começar a usá-lo.
Veja quão grande e interessante é a imagem. Eu nem estou falando do
Yahoo! Everest com armazenamento em coluna, com petabytes de dados no Yahoo! - foi o ano de 2008. Eles até patrocinaram nossa conferência no Canadá, chegaram lá, em algum lugar eu até tenho uma camisa de lá :)
Há também o
PipelineDB . Também começou como um banco de dados de código fechado, mas agora também é apenas uma extensão. Vemos que Citus, TimescaleDB e PipelineDB são como bancos de dados separados, mas ao mesmo tempo eles existem como extensões, ou seja, você pega o Postgres padrão e compila a extensão. O PipelineDB é uma continuação da ideia de bancos de dados de fluxo.
Deseja trabalhar com fluxos? Faça o Postgres, faça o PipelineDB e você poderá trabalhar.Além disso, existem extensões que permitem trabalhar com a GPU . Veja o título? Eu mostrei que existe um ecossistema que abrange um grande número de diferentes tipos de dados e cargas. Portanto, dizemos que o Postgres é um banco de dados universal.Base de pessoas favoritas
 O próximo slide tem grandes nomes. Todas as nuvens mais famosas do mundo suportam o Postgres. Na Rússia, o Postgres é suportado por grandes empresas estatais. Eles o usam e nós os servimos como nossos clientes.
O próximo slide tem grandes nomes. Todas as nuvens mais famosas do mundo suportam o Postgres. Na Rússia, o Postgres é suportado por grandes empresas estatais. Eles o usam e nós os servimos como nossos clientes. Já existem muitas extensões e muitos aplicativos, portanto o Postgres é bom como o banco de dados a partir do qual o projeto inicia. Eu sempre digo para as startups: pessoal, você não precisa usar o banco de dados NoSQL . Entendo que você realmente deseja, mas comece com o Postgres. Se você não tiver o suficiente, sempre poderá soltar um serviço e entregá-lo a um banco de dados especializado. Além da universalidade, o Postgres tem mais uma vantagem: uma licença BSD muito liberal, que permite que você faça qualquer coisa com seu banco de dados.Tudo o que você vê neste slide é acessível devido ao fato de o Postgres ser um banco de dados extensível e essa extensibilidade estar embutida na arquitetura do banco de dados. Quando Michael Stonebreaker escreveu sobre o Postgres em seu primeiro artigo sobre ele (foi escrito por ele em 1984, aqui cito um artigo de 1987), ele já falava sobre extensibilidade como o componente mais importante da funcionalidade do banco de dados. E isso, como se costuma dizer, já foi testado pelo tempo. Você pode adicionar suas próprias funções, tipos de dados, operadores, acessos ao índice (ou seja, métodos de acesso otimizados), você pode escrever seus procedimentos em um número muito grande de idiomas. Temos um Foreign Data Wrapper ( FDW ), ou seja, interfaces para trabalhar com diferentes repositórios, arquivos, que você pode conectar ao Oracle , MySQLe outras bases.Eu quero dar um exemplo da minha própria experiência pessoal. Eu trabalhei com o Postgres e quando algo estava faltando no Postgres, meus colegas e eu simplesmente adicionamos essa funcionalidade. Precisávamos trabalhar, por exemplo, com o idioma russo e criamos um código de idioma de 8 bits. Foi um projeto Rambler . Aliás, ele estava no top 5. Ramblerfoi o primeiro grande projeto global a ser lançado no Postgres. As matrizes no Postgres foram desde o início, mas eram de tal ordem que nada podia ser feito com elas; era apenas uma linha de texto na qual as matrizes eram armazenadas. Adicionamos operadores, criamos índices e agora as matrizes são parte integrante da funcionalidade do Postgres, e muitos de vocês as usam sem se preocupar com a rapidez com que trabalham - e isso é bom. Eles costumavam dizer que matrizes não são mais um modelo relacional tradicional, não satisfazem as formas normais clássicas. Agora as pessoas já estão acostumadas a usar matrizes.
Já existem muitas extensões e muitos aplicativos, portanto o Postgres é bom como o banco de dados a partir do qual o projeto inicia. Eu sempre digo para as startups: pessoal, você não precisa usar o banco de dados NoSQL . Entendo que você realmente deseja, mas comece com o Postgres. Se você não tiver o suficiente, sempre poderá soltar um serviço e entregá-lo a um banco de dados especializado. Além da universalidade, o Postgres tem mais uma vantagem: uma licença BSD muito liberal, que permite que você faça qualquer coisa com seu banco de dados.Tudo o que você vê neste slide é acessível devido ao fato de o Postgres ser um banco de dados extensível e essa extensibilidade estar embutida na arquitetura do banco de dados. Quando Michael Stonebreaker escreveu sobre o Postgres em seu primeiro artigo sobre ele (foi escrito por ele em 1984, aqui cito um artigo de 1987), ele já falava sobre extensibilidade como o componente mais importante da funcionalidade do banco de dados. E isso, como se costuma dizer, já foi testado pelo tempo. Você pode adicionar suas próprias funções, tipos de dados, operadores, acessos ao índice (ou seja, métodos de acesso otimizados), você pode escrever seus procedimentos em um número muito grande de idiomas. Temos um Foreign Data Wrapper ( FDW ), ou seja, interfaces para trabalhar com diferentes repositórios, arquivos, que você pode conectar ao Oracle , MySQLe outras bases.Eu quero dar um exemplo da minha própria experiência pessoal. Eu trabalhei com o Postgres e quando algo estava faltando no Postgres, meus colegas e eu simplesmente adicionamos essa funcionalidade. Precisávamos trabalhar, por exemplo, com o idioma russo e criamos um código de idioma de 8 bits. Foi um projeto Rambler . Aliás, ele estava no top 5. Ramblerfoi o primeiro grande projeto global a ser lançado no Postgres. As matrizes no Postgres foram desde o início, mas eram de tal ordem que nada podia ser feito com elas; era apenas uma linha de texto na qual as matrizes eram armazenadas. Adicionamos operadores, criamos índices e agora as matrizes são parte integrante da funcionalidade do Postgres, e muitos de vocês as usam sem se preocupar com a rapidez com que trabalham - e isso é bom. Eles costumavam dizer que matrizes não são mais um modelo relacional tradicional, não satisfazem as formas normais clássicas. Agora as pessoas já estão acostumadas a usar matrizes. Quando precisávamos de uma pesquisa de texto completo, fizemos. Quando precisávamos armazenar dados de natureza diferente, fizemos a extensão hstore e muitas pessoas começaram a usá-lo: tornou possível criar esquemas flexíveis de banco de dados para que cada vez mais rápido. Criamos um índice GIN para fazer com que a pesquisa de texto completo funcione rapidamente. Criamos trigramas ( pg_trgm ). Feito NoSQL. E tudo isso está na minha memória, todas as minhas próprias necessidades.
Quando precisávamos de uma pesquisa de texto completo, fizemos. Quando precisávamos armazenar dados de natureza diferente, fizemos a extensão hstore e muitas pessoas começaram a usá-lo: tornou possível criar esquemas flexíveis de banco de dados para que cada vez mais rápido. Criamos um índice GIN para fazer com que a pesquisa de texto completo funcione rapidamente. Criamos trigramas ( pg_trgm ). Feito NoSQL. E tudo isso está na minha memória, todas as minhas próprias necessidades. A extensibilidade faz do Postgres um banco de dados exclusivo, um banco de dados universal com o qual você pode começar a trabalhar e não ter medo de ficar sem suporte. Veja quantas pessoas aqui temos - este já é um mercado! Apesar do fato de que agora hype - bancos de dados gráficos, bancos de dados de documentos, séries temporais e assim por diante -, a maioria ainda usa bancos de dados relacionais. Eles dominam, isso representa 75% do mercado de bancos de dados e o restante são bancos de dados exóticos, um pouco em comparação aos relacionais.
A extensibilidade faz do Postgres um banco de dados exclusivo, um banco de dados universal com o qual você pode começar a trabalhar e não ter medo de ficar sem suporte. Veja quantas pessoas aqui temos - este já é um mercado! Apesar do fato de que agora hype - bancos de dados gráficos, bancos de dados de documentos, séries temporais e assim por diante -, a maioria ainda usa bancos de dados relacionais. Eles dominam, isso representa 75% do mercado de bancos de dados e o restante são bancos de dados exóticos, um pouco em comparação aos relacionais. Se você observar a proporção entre bancos de dados de código aberto e comerciais, então, de acordocom o DB-Engines, veremos que o número de bancos de dados de código aberto é quase igual ao número de bancos de dados comerciais. E vemos que os bancos de dados de código aberto (linha azul) estão crescendo e os comerciais (vermelho) estão caindo. Essa é a direção do desenvolvimento de toda a comunidade de TI, a direção da abertura. Agora, é claro, é indecente se referir ao Gartner , mas vou dizer assim mesmo: eles prevêem que até 2022 70% usarão bancos de dados abertos e até 50% dos sistemas existentes migrarão para o código aberto.Veja este pomoomer: vemos que o Postgres é chamado de banco de dados de 2018. No ano passado, ela também foi a primeira estimativa de especialistas independentes da DB-Engines. A classificação mostra que o Postgres está realmente à frente do resto. Está em termos absolutos em 4º lugar, mas veja como cresce. Claro que bom No slide, essa é uma linha azul. O restante - MySQL, Oracle, MS SQL - se equilibra em seu nível ou começa a se curvar.
Se você observar a proporção entre bancos de dados de código aberto e comerciais, então, de acordocom o DB-Engines, veremos que o número de bancos de dados de código aberto é quase igual ao número de bancos de dados comerciais. E vemos que os bancos de dados de código aberto (linha azul) estão crescendo e os comerciais (vermelho) estão caindo. Essa é a direção do desenvolvimento de toda a comunidade de TI, a direção da abertura. Agora, é claro, é indecente se referir ao Gartner , mas vou dizer assim mesmo: eles prevêem que até 2022 70% usarão bancos de dados abertos e até 50% dos sistemas existentes migrarão para o código aberto.Veja este pomoomer: vemos que o Postgres é chamado de banco de dados de 2018. No ano passado, ela também foi a primeira estimativa de especialistas independentes da DB-Engines. A classificação mostra que o Postgres está realmente à frente do resto. Está em termos absolutos em 4º lugar, mas veja como cresce. Claro que bom No slide, essa é uma linha azul. O restante - MySQL, Oracle, MS SQL - se equilibra em seu nível ou começa a se curvar. Notícias sobre hackers - todos vocês provavelmente leem ou Y Combinator- pesquisas são realizadas periodicamente no local, as empresas publicam suas vagas no país e, há algum tempo, realizam estatísticas. Você vê que a partir de 2014, o Postgres está à frente de todos. Foi o primeiro MySQL, mas o Postgres cresceu lentamente, e agora entre toda a comunidade de hackers (no bom sentido da palavra) também prevalece e cresce ainda mais.
Notícias sobre hackers - todos vocês provavelmente leem ou Y Combinator- pesquisas são realizadas periodicamente no local, as empresas publicam suas vagas no país e, há algum tempo, realizam estatísticas. Você vê que a partir de 2014, o Postgres está à frente de todos. Foi o primeiro MySQL, mas o Postgres cresceu lentamente, e agora entre toda a comunidade de hackers (no bom sentido da palavra) também prevalece e cresce ainda mais. O Stack Overflow , também, cada conduta de ano levantamentos. Por mais usado, nosso Postgres está em um bom terceiro lugar. Por mais amado - no segundo. Este é um banco de dados favorito. O Redis não é um banco de dados relacional, mas o Postgres relacional é o favorito. Não dei aqui a foto mais temida- o banco de dados mais terrível, mas você provavelmente adivinha quem vem primeiro. "Base X", como eles gostam de chamar na Rússia.
O Stack Overflow , também, cada conduta de ano levantamentos. Por mais usado, nosso Postgres está em um bom terceiro lugar. Por mais amado - no segundo. Este é um banco de dados favorito. O Redis não é um banco de dados relacional, mas o Postgres relacional é o favorito. Não dei aqui a foto mais temida- o banco de dados mais terrível, mas você provavelmente adivinha quem vem primeiro. "Base X", como eles gostam de chamar na Rússia. Há uma revisão na Rússia, uma pesquisa realizada por todos nós na respeitada conferência HighLoad ++ . Não foi conduzido por nós, foi feito por Oleg Bunin . Descobriu-se: no banco de dados da Rússia Postgres No. 1. Pela
Há uma revisão na Rússia, uma pesquisa realizada por todos nós na respeitada conferência HighLoad ++ . Não foi conduzido por nós, foi feito por Oleg Bunin . Descobriu-se: no banco de dados da Rússia Postgres No. 1. Pela segunda vez, estamos pedindo ao HH.ru que compartilhe as estatísticas do trabalho do Postgres. Há 9 anos, o Postgres estava 10 vezes atrás da Oracle, todos gritaram: dê-nos oracleistas. E vemos que no ano passado nos alcançamos e, em 2018, houve crescimento. E se você está preocupado sobre onde encontrar um emprego, consulte: 2 mil vagas no HH.ru é o Postgres. Não se preocupe, trabalho suficiente.
segunda vez, estamos pedindo ao HH.ru que compartilhe as estatísticas do trabalho do Postgres. Há 9 anos, o Postgres estava 10 vezes atrás da Oracle, todos gritaram: dê-nos oracleistas. E vemos que no ano passado nos alcançamos e, em 2018, houve crescimento. E se você está preocupado sobre onde encontrar um emprego, consulte: 2 mil vagas no HH.ru é o Postgres. Não se preocupe, trabalho suficiente. Para facilitar a visualização, tirei uma foto em que mostrava as vagas do Postgres em relação às vagas da Oracle. Havia menos, a partir de 2018, eles já estão no mesmo nível, e agora o Postgres já se tornou um pouco mais. Até agora, é um pouco deprimente que o número absoluto de vagas da Oracle também esteja crescendo, o que em princípio não deveria ser. Mas, como eles dizem, estamos sentados perto da margem do rio e observando: quando o cadáver do inimigo irá flutuar. Estamos apenas fazendo nosso trabalho.
Para facilitar a visualização, tirei uma foto em que mostrava as vagas do Postgres em relação às vagas da Oracle. Havia menos, a partir de 2018, eles já estão no mesmo nível, e agora o Postgres já se tornou um pouco mais. Até agora, é um pouco deprimente que o número absoluto de vagas da Oracle também esteja crescendo, o que em princípio não deveria ser. Mas, como eles dizem, estamos sentados perto da margem do rio e observando: quando o cadáver do inimigo irá flutuar. Estamos apenas fazendo nosso trabalho.
Comunidade russa do Postgres
Esta é a comunidade mais organizada da Rússia, nunca conheci pessoas assim. Muitos recursos, bate-papos, onde todos nos comunicamos sobre negócios. Realizamos conferências - duas grandes conferências: em São Petersburgo e Moscou, prédios de apartamentos, participamos de todas as principais conferências internacionais, conduzimos cursos. De fato, esses são cursos da comunidade. Eles foram preparados por nossa empresa, mas estão disponíveis gratuitamente para qualquer um de vocês, consulte o canal no youtube ou acesse nosso site na seção "Educação", existem cursos DBA1 , DBA2 , DBA3 , cursos de desenvolvimento para download gratuito .E agora estamos lançando a certificação - é o que as empresas estão pedindo, elas querem ter especialistas certificados. E o empregador saberá: você é um especialista certificado.
De fato, esses são cursos da comunidade. Eles foram preparados por nossa empresa, mas estão disponíveis gratuitamente para qualquer um de vocês, consulte o canal no youtube ou acesse nosso site na seção "Educação", existem cursos DBA1 , DBA2 , DBA3 , cursos de desenvolvimento para download gratuito .E agora estamos lançando a certificação - é o que as empresas estão pedindo, elas querem ter especialistas certificados. E o empregador saberá: você é um especialista certificado. Eles costumam perguntar: quanto Postgres russo? A questão é um pouco equivocada: o Postgres é internacional. Mas vou falar um pouco sobre a bandeira russa. Você vê no slide o que Vadim Mikheev fez . Quem conhece o Postgres entende que MVCC , WAL , VACUUM e assim por diante significam para esta base . Essa é toda a contribuição da Rússia. Agora, existem três principais desenvolvedores do Postgres, dos quais dois são confirmadores. No slide, você vê que muito já foi feito. Se você observar os principais recursos das notas de versão, verá nossa contribuição. A contribuição russa é substancial o suficiente. Trabalhamos desde o início e continuamos a trabalhar com a comunidade - já no nível da campanha.
Eles costumam perguntar: quanto Postgres russo? A questão é um pouco equivocada: o Postgres é internacional. Mas vou falar um pouco sobre a bandeira russa. Você vê no slide o que Vadim Mikheev fez . Quem conhece o Postgres entende que MVCC , WAL , VACUUM e assim por diante significam para esta base . Essa é toda a contribuição da Rússia. Agora, existem três principais desenvolvedores do Postgres, dos quais dois são confirmadores. No slide, você vê que muito já foi feito. Se você observar os principais recursos das notas de versão, verá nossa contribuição. A contribuição russa é substancial o suficiente. Trabalhamos desde o início e continuamos a trabalhar com a comunidade - já no nível da campanha. E a contribuição da empresa são livros. Temos 2 cursos universitários no Postgres. Você pode ir à loja e comprar esses livros, pode ensinar nesses cursos, fazer exames e assim por diante. Temos livros para iniciantes que são distribuídos, inclusive aqui. Bom livro muito útil. Nós até traduzimos para o inglês.
E a contribuição da empresa são livros. Temos 2 cursos universitários no Postgres. Você pode ir à loja e comprar esses livros, pode ensinar nesses cursos, fazer exames e assim por diante. Temos livros para iniciantes que são distribuídos, inclusive aqui. Bom livro muito útil. Nós até traduzimos para o inglês.Postgres profissionais
Vamos para o principal. O Postgres acadêmico, quando começou, foi projetado para várias dezenas de usuários. A comunidade do Postgres95 tinha menos de 400 pessoas. A comunidade consistia principalmente de desenvolvedores e mais alguns usuários. Ao mesmo tempo - um detalhe interessante - os desenvolvedores eram principalmente clientes e contratados. Por exemplo, quando eu precisava, desenvolvi para mim e, ao mesmo tempo, compartilhei com todos. Ou seja, a comunidade estava se desenvolvendo para a comunidade.
A partir do ano 2000, um pouco antes, começaram a aparecer as primeiras empresas pós-brutas:
GreatBridge ,
2ndQuadrant ,
EDB . Eles já contrataram desenvolvedores em período integral que trabalhavam para a comunidade. Os primeiros garfos da empresa e os primeiros personalizadores da empresa apareceram. Isso levou ao fato de que em 2015 o número principal - e quase todos os principais desenvolvedores - já estava organizado em algumas empresas. Em 2015, nossa empresa foi formada: nós éramos os últimos desenvolvedores freelancers gratuitos. Agora praticamente não existem pessoas assim. A comunidade do postgres mudou, tornou-se uma empresa e agora essas empresas estão impulsionando o desenvolvimento. Isso é bom porque essas empresas realizam o que a empresa precisa. A comunidade é um freio em um bom sentido: testa recursos, condena ou aceita novos recursos, une todos nós. E o Postgres tornou-se
pronto para empresas , grandes empresas estão felizes em usá-lo, tornou-se profissional.

Este slide é sobre o futuro, a meu ver. Com o advento do
armazenamento conectável , novos armazenamentos aparecerão:
armazenamento de colunas somente leitura ,
somente leitura - o que você quiser (por exemplo, eu sonho com parquet). Haverá suporte para operações de vetor. Hoje, a propósito, haverá um relatório sobre eles. Blockchain será suportado. Não há como fugir disso, já que estamos migrando para a economia digital, para tecnologias sem papel. Você precisará usar assinaturas eletrônicas e precisará autenticar seu banco de dados, certificar-se de que ninguém mudou nada e o blockchain é muito adequado para isso.


Próximo:
Postgres adaptável . Este é um tópico um pouco triste para você, mas ainda está longe de você. O fato é que o DBA, de um modo geral, é um recurso caro e, em breve, os bancos de dados não precisarão deles. As bases serão suficientemente inteligentes e irão se configurar e se ajustar. Mas será daqui a mais dez anos, provavelmente. Ainda temos muito tempo.

E é claro que no Postgres haverá suporte nativo para nuvens, armazenamento em nuvem - sem isso, simplesmente não podemos sobreviver. E, claro, aqui está, o último slide:
TUDO QUE VOCÊ PRECISA É POSTGRES!

Obrigado pela atenção.