
Fonte da imagem: www.nikonsmallworld.com
O anti-plágio é um mecanismo de pesquisa especializado, que já foi escrito anteriormente . E qualquer mecanismo de pesquisa, o que quer que se diga, para trabalhar rapidamente, precisa de seu próprio índice, que leva em consideração todos os recursos da área de pesquisa. No meu primeiro artigo sobre Habr, falarei sobre a implementação atual do nosso índice de pesquisa, o histórico de seu desenvolvimento e as razões para a escolha de uma ou outra solução. Algoritmos .NET eficazes não são um mito, mas uma realidade difícil e produtiva. Vamos mergulhar no mundo do hash, da compressão bit a bit e dos caches de prioridade em vários níveis. E se você precisar de uma pesquisa mais rápida que O (1) ?
Se alguém não souber onde estão as telhas nesta foto, seja bem-vindo ...
Telhas, índice e por que procurá-las
Uma telha é um pedaço de texto com algumas palavras em tamanho. As telhas se sobrepõem, daí o nome (inglês, telhas - escamas, lado a lado). Seu tamanho específico é um segredo aberto - 4 palavras. Ou 5? Bem, isso depende. No entanto, mesmo esse valor fornece pouco e depende da composição das palavras de parada, do algoritmo para normalizar as palavras e de outros detalhes que não são significativos na estrutura deste artigo. No final, calculamos o hash de 64 bits com base nessa telha, que chamaremos de telha no futuro.
De acordo com o texto do documento, você pode criar muitas telhas, cujo número é comparável ao número de palavras no documento:
texto: string → telhas: uint64 []
Se várias telhas coincidem em dois documentos, assumimos que os documentos se cruzam. Quanto mais telhas coincidirem, mais texto idêntico estará nesse par de documentos. O índice procura documentos que tenham o maior número de interseções com o documento que está sendo verificado.

Fonte da imagem: Wikipedia
O índice Shingles permite executar duas operações principais:
Indexar as telhas dos documentos com seus identificadores:
index.Add (docId, telhas)
Pesquise e exiba uma lista classificada de identificadores para documentos sobrepostos:
index.Search (shingles) → (docId, score) []
O algoritmo de classificação, acredito, é digno de um artigo separado em geral, portanto não escreveremos sobre isso aqui.
O índice de telhas é muito diferente dos conhecidos de texto completo, como Sphinx, Elastic ou maior: Google, Yandex, etc. ... Por um lado, não requer PNL e outras alegrias da vida. Todo o processamento de texto é retirado e não afeta o processo, bem como a sequência de telhas no texto. Por outro lado, a consulta de pesquisa não é uma palavra ou frase de várias palavras, mas até várias centenas de milhares de hashes , que são importantes no conjunto, e não separadamente.
Hipoteticamente, você pode usar o índice de texto completo como substituto do índice de telhas, mas as diferenças são muito grandes. A maneira mais fácil de usar algum armazenamento conhecido de valor-chave, isso será mencionado abaixo. Estamos vendo nossa implementação de bicicleta , chamada ShingleIndex.
Por que nos incomodamos? Mas porque
- Volumes :
- Existem muitos documentos. Agora, temos cerca de 650 milhões deles, e este ano obviamente haverá mais;
- O número de telhas únicas está crescendo aos trancos e barrancos e já está chegando a centenas de bilhões. Estamos à espera de um trilhão.
- Velocidade :
- Durante o dia, durante a sessão de verão, mais de 300 mil documentos são verificados através do sistema anti-plágio . Isso é um pouco para os padrões dos mecanismos de pesquisa populares, mas mantém o tom;
- Para uma verificação bem-sucedida dos documentos quanto à exclusividade, o número de documentos indexados deve ter ordens de magnitude maiores que os documentos que estão sendo verificados. A versão atual do nosso índice, em média, pode ser preenchida a uma velocidade de mais de 4000 documentos médios por segundo.
E está tudo em uma máquina! Sim, podemos replicar , estamos nos aproximando gradualmente do sharding dinâmico em um cluster, mas de 2005 até hoje, o índice em uma máquina com cuidado foi capaz de lidar com todas as dificuldades acima.
Estranha experiência
No entanto, agora somos tão experientes. Goste ou não, mas nós também crescemos e tentamos coisas diferentes no decorrer do crescimento, das quais é divertido lembrar agora.
Fonte da imagem: Wikipedia
Primeiro de tudo, um leitor inexperiente gostaria de usar um banco de dados SQL. Vocês não são os únicos que pensam assim, a implementação do SQL nos serviu bem por vários anos para implementar coleções muito pequenas. No entanto, o foco foi imediatamente em milhões de documentos, então tive que ir mais longe.
Como você sabe, ninguém gosta de bicicletas, e o LevelDB ainda não era de domínio público, então em 2010 nossos olhos se voltaram para o BerkeleyDB. Tudo é legal - uma base persistente de valores-chave incorporada com métodos adequados de acesso a btree e hash e uma longa história. Tudo com ela foi maravilhoso, mas:
- No caso de uma implementação de hash, quando atingiu um volume de 2 GB, simplesmente caiu. Sim, ainda estávamos trabalhando no modo de 32 bits;
- A implementação da árvore B + funcionou de maneira estável, mas com volumes de mais de alguns gigabytes, a velocidade da pesquisa começou a cair significativamente.
Temos que admitir que nunca encontramos uma maneira de ajustá-lo à nossa tarefa. Talvez o problema esteja nas ligações .net, que ainda precisavam ser concluídas. A implementação do BDB acabou sendo usada como um substituto para o SQL como um índice intermediário antes de preencher o principal.
O tempo passou. Em 2014, eles tentaram o LMDB e o LevelDB, mas não o implementaram. Os funcionários do Departamento de Pesquisa Anti-Plágio usaram o RocksDB como índice. À primeira vista, foi um achado. Mas a reposição lenta e a velocidade medíocre de busca, mesmo em pequenos volumes, nada deram em nada.
Fizemos tudo isso acima, enquanto desenvolvíamos nosso próprio índice personalizado. Como resultado, ele se tornou tão bom em resolver nossos problemas que abandonamos os “plugues” anteriores e focamos em melhorá-lo, que agora usamos na produção em qualquer lugar.
Camadas de índice
No final, o que temos agora? De fato, o índice de telhas consiste em várias camadas (matrizes) com elementos de comprimento constante - de 0 a 128 bits - que depende não apenas da camada e não é necessariamente um múltiplo de oito.
Cada uma das camadas desempenha um papel. Alguns tornam a pesquisa mais rápida, outros economizam espaço e outros nunca são usados, mas são realmente necessários. Vamos tentar descrevê-los para aumentar sua eficiência total na pesquisa.

Fonte da imagem: Wikipedia
1. Matriz de índice
Sem perda de generalidade, consideraremos agora que uma única telha é atribuída ao documento,
(docId → cascalho)
Trocaremos os elementos do par (inverter, porque o índice é realmente "invertido"!),
(cascalho → docId)
Classifique pelos valores das telhas e forme uma camada. Porque os tamanhos da telha e o identificador do documento são constantes, agora qualquer pessoa que entenda a pesquisa binária pode encontrar um par além das leituras O (logn) do arquivo. Quanta, muita coisa. Mas isso é melhor do que apenas O (n) .
Se o documento tiver várias telhas, haverá vários pares desse documento. Se houver vários documentos com a mesma telha, isso também não mudará muito - haverá vários pares seguidos com a mesma telha. Nos dois casos, a pesquisa durará um tempo comparável.
2. Matriz de grupos
Dividimos cuidadosamente os elementos do índice da etapa anterior em grupos de qualquer maneira conveniente. Por exemplo, para que eles se ajustem ao setor de cluster, o bloco da unidade de alocação (leitura, 4096 bytes), levando em consideração o número de bits e outros truques, formará um dicionário eficaz. Temos uma matriz simples de posições de tais grupos:
group_map (hash (shingle)) -> group_position.
Ao procurar uma telha, agora vamos primeiro procurar a posição do grupo neste dicionário e, em seguida, descarregar o grupo e pesquisar diretamente na memória. Toda a operação requer duas leituras.
O dicionário de posições de grupo ocupa várias ordens de magnitude menos espaço do que o próprio índice, geralmente pode ser simplesmente descarregado na memória. Assim, não haverá duas leituras, mas uma. Total, O (1) .
3. Filtro Bloom
Nas entrevistas, os candidatos geralmente resolvem problemas emitindo soluções únicas com O (n ^ 2) ou mesmo O (2 ^ n) . Mas nós não fazemos coisas estúpidas. Existe O (0) no mundo, eis a questão? Vamos tentar sem muita esperança para um resultado ...
Vamos voltar para a área de assunto. Se o aluno for bem-sucedido e escreveu o trabalho, ele próprio, ou simplesmente não houver texto, mas lixo, uma parte significativa de suas telhas será única e não será encontrada no índice. Uma estrutura de dados como o filtro Bloom é bem conhecida no mundo. Antes de pesquisar, verifique a telha nela. Se não houver telha no índice, você não poderá procurar mais, caso contrário, vá mais longe.
O filtro Bloom em si é bastante simples, mas não faz sentido usar um vetor hash com nossos volumes. É suficiente usar uma: +1 na leitura do filtro Bloom. Isso fornece leituras -1 ou -2 dos estágios subseqüentes, caso a telha seja única e não haja falso positivo no filtro. Cuidado com as mãos!
A probabilidade de um erro do filtro Bloom é definida durante a construção; a probabilidade de uma telha desconhecida é determinada pela honestidade do aluno. Cálculos simples podem chegar à seguinte dependência:
- Se confiarmos na honestidade das pessoas (ou seja, na verdade, o documento é original), a velocidade da pesquisa diminuirá;
- Se o documento estiver claramente costurado, a velocidade da pesquisa aumentará, mas precisamos de muita memória.
Com a confiança nos alunos, temos o princípio de "confiar, mas verificar", e a prática mostra que ainda há lucro com o filtro Bloom.
Dado que essa estrutura de dados também é menor que o próprio índice e pode ser armazenada em cache, na melhor das hipóteses, permite remover a telha sem nenhum acesso ao disco.
4. caudas pesadas
Existem telhas que são encontradas em quase toda parte. Sua participação no número total é escassa, mas ao construir o índice na primeira etapa, na segunda, grupos de dezenas e centenas de MB podem ser obtidos. Nós os lembraremos separadamente e os descartamos imediatamente da consulta de pesquisa.
Quando essa etapa trivial foi usada pela primeira vez em 2011, o tamanho do índice caiu pela metade e a própria pesquisa foi acelerada.
5. Outras caudas
Mesmo assim, uma telha pode ter muitos documentos. E isso é normal. Dezenas, centenas, milhares ... Mantendo-os dentro do índice principal se torna inútil, eles também não podem se encaixar em um grupo, a partir do qual o volume do dicionário de posições de grupo é inflado. Coloque-os em uma sequência separada com armazenamento mais eficiente. Segundo as estatísticas, essa decisão é mais do que justificada. Além disso, vários pacotes bit a bit podem reduzir o número de acessos ao disco e o volume do índice.
Como resultado, para facilitar a manutenção, imprimimos todas essas camadas em um grande bloco de arquivos. Existem dez dessas camadas nele. Mas parte não é usada na pesquisa, parte é muito pequena e sempre é armazenada na memória, parte é ativamente armazenada em cache conforme necessário / possível.
Na batalha, na maioria das vezes a busca por uma telha se resume a uma ou duas leituras aleatórias de arquivos. Na pior das hipóteses, você tem que fazer três. Todas as camadas são efetivamente (às vezes bit a bit) matrizes de elementos de comprimento constante. Tal é normalização. O tempo para descompactar é insignificante em comparação com o preço do volume total durante o armazenamento e a capacidade de armazenar em cache melhor.
Na construção, os tamanhos das camadas são calculados principalmente com antecedência, gravados sequencialmente, portanto esse procedimento é bastante rápido.
Como você chegou lá, não sabia onde
2010 , . , . , .

Fonte da imagem: Wikipedia
Inicialmente, nosso índice consistia em duas partes - uma constante, descrita acima, e uma temporária, cuja função era SQL, ou BDB, ou seu próprio log de atualização. Ocasionalmente, por exemplo, uma vez por mês (e algumas vezes por ano), o temporário é classificado, filtrado e mesclado com o principal. O resultado foi unido e os dois antigos foram removidos. Se o temporário não couber na RAM, o procedimento passou por uma classificação externa.
Esse procedimento foi bastante problemático, foi iniciado no modo semi-manual e exigiu a reescrita de todo o arquivo de índice do zero. Reescrevendo centenas de gigabytes para alguns milhões de documentos - bem, prazer, eu lhe digo ...
Memórias do passado ...SSD. , 31 SSD wcf- . , . , .
Para que o SSD não seja particularmente tenso e o índice seja atualizado com mais frequência, em 2012, envolvemos uma cadeia de várias partes, partes de acordo com o seguinte esquema:

Aqui, o índice consiste em uma cadeia do mesmo tipo de pedaços, exceto o primeiro. O primeiro, addon, era um log somente de acréscimo com um índice na RAM. Os pedaços subsequentes aumentaram de tamanho (e idade) até o último (zero, principal, raiz, ...).
Nota para ciclistas ...Às vezes, você não deve escrever um código e nem pensar, mas apenas pesquisá-lo no Google. Até a notação, o diagrama é semelhante ao do artigo de 1996
“A árvore de mesclagem estruturada em log” :
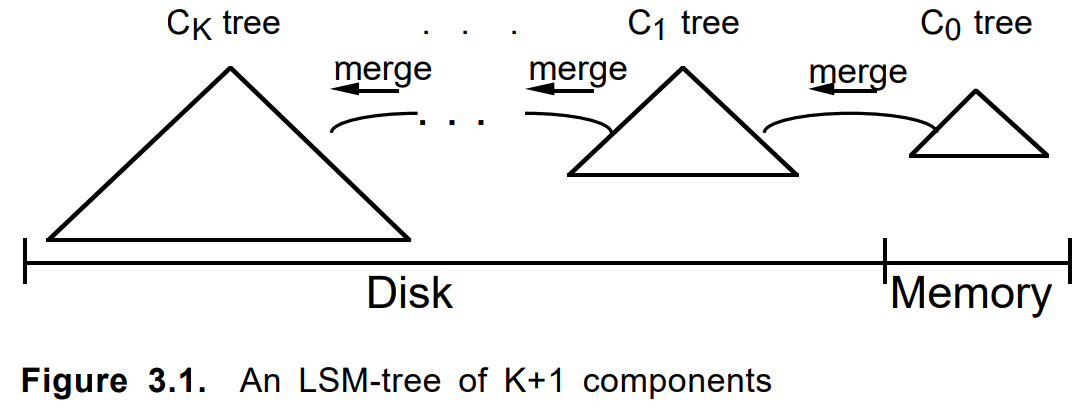
Ao adicionar um documento, ele foi primeiro dobrado em um complemento. Quando estava cheio ou por outros critérios, um pedaço permanente foi construído sobre ele. Os vários pedaços vizinhos, se necessário, se fundiram em um novo e os originais foram excluídos. Atualizar um documento ou excluí-lo funcionou da mesma maneira.
Critérios de mesclagem, comprimento da cadeia, algoritmo de desvio, contabilização de itens e atualizações excluídos e outros parâmetros foram ajustados. A abordagem em si estava envolvida em várias tarefas semelhantes e tomou forma como uma estrutura LSM interna separada em um .net limpo. Na mesma época, o LevelDB se tornou popular.
Pequena observação sobre a árvore LSMO LSM-Tree é um algoritmo bastante interessante, com boa justificativa. Mas, IMHO, houve alguma confusão no significado do termo Árvore. No
artigo original
, tratava-se de uma cadeia de árvores com a capacidade de transferir galhos. Nas implementações modernas, esse nem sempre é o caso. Portanto, nossa estrutura acabou sendo nomeada como LsmChain, ou seja, a cadeia de blocos lsm.
O algoritmo LSM no nosso caso possui recursos muito adequados:
- inserção / exclusão / atualização instantânea,
- carga reduzida nos SSDs durante a atualização,
- formato de pedaços simplificados,
- pesquisa seletiva apenas em partes antigas / novas,
- backup trivial
- o que mais a alma quer.
- ...
Em geral, às vezes é útil inventar bicicletas para o autodesenvolvimento.
Otimização macro, micro e nano
E, finalmente, compartilharemos dicas técnicas sobre como fazemos no Antiplagiarism essas coisas no .Net (e não apenas nele).
Observe com antecedência que muitas vezes tudo depende muito do seu hardware, dados ou modo de uso específico. Tendo torcido em um lugar, voamos para fora do cache da CPU, em outro - nos deparamos com a largura de banda da interface SATA, no terceiro - começamos a travar no GC. E em algum lugar a ineficiência da implementação de uma chamada de sistema específica.

Fonte da imagem: Wikipedia
Trabalhar com arquivo
O problema com o acesso ao arquivo não é exclusivo para nós. Há um arquivo grande de terabyte de exabyte , cujo volume é muitas vezes maior que a quantidade de RAM. A tarefa é ler os milhões espalhados ao redor de alguns pequenos valores aleatórios. E fazê-lo de forma rápida, eficiente e barata. Temos que apertar, comparar e pensar muito.
Vamos começar com um simples. Para ler o byte estimado, você precisa:
- Abrir arquivo (novo FileStream);
- Mova para a posição desejada (posição ou busca, sem diferença);
- Leia a matriz de bytes desejada (leitura);
- Feche o arquivo (Dispose).
E isso é ruim, porque é longo e triste. Por tentativa, erro e repetidas etapas no rake, identificamos o seguinte algoritmo de ações:
Leitura única aberta e múltipla
Se essa sequência for feita na testa, para todas as solicitações no disco, então nos curvaremos rapidamente. Cada um desses itens entra em uma solicitação ao kernel do SO, o que é caro.
Obviamente, você deve abrir o arquivo uma vez e ler sequencialmente todos os milhões de nossos valores, o que fazemos
Nada extra
Obtendo o tamanho do arquivo, a posição atual nele também é operações bastante difíceis. Mesmo que o arquivo não tenha sido alterado.
Qualquer consulta, como obter o tamanho do arquivo ou a posição atual, deve ser evitada.
Filestreampool
Próximo. Infelizmente, o FileStream é essencialmente de thread único. Se você quiser ler um arquivo em paralelo, precisará criar / fechar novos fluxos de arquivos.
Até criar algo como aiosync, você deve inventar suas próprias bicicletas.
Meu conselho é criar um pool de fluxos de arquivos por arquivo. Isso evitará perder tempo abrindo / fechando um arquivo. E se você combiná-lo com o ThreadPool e levar em conta que o SSD emite seus megaIOPSs com multithreading forte ... Bem, você me entende.
Unidade de alocação
Próximo. Os dispositivos de armazenamento (HDD, SSD, Optane) e o sistema de arquivos operam com arquivos no nível do bloco (cluster, setor, unidade de alocação). Eles podem não corresponder, mas agora são quase sempre 4096 bytes. A leitura de um ou dois bytes na borda de dois desses blocos em um SSD é cerca de uma vez e meia mais lenta do que dentro do próprio bloco.
Você deve organizar seus dados para que os elementos subtraídos fiquem dentro dos limites do bloco do setor de cluster .
Sem buffer.
Próximo. O FileStream, por padrão, usa um buffer de 4096 bytes. E a má notícia é que você não pode desligá-lo. No entanto, se você estiver lendo mais dados que o tamanho do buffer, o último será ignorado.
Para leitura aleatória, você deve definir o buffer como 1 byte (não funcionará menos) e depois considerar que não é usado.
Use buffer.
Além de leituras aleatórias, há também sequenciais. Aqui, o buffer já pode se tornar útil se você não quiser ler tudo de uma vez. Eu aconselho você a começar com este artigo . Qual o tamanho do buffer a ser configurado depende se o arquivo está no HDD ou no SSD. No primeiro caso, 1 MB será ideal; no segundo, 4kB padrão será suficiente. Se o tamanho da área de dados a ser lida for comparável a esses valores, é melhor subtraí-lo de uma vez, ignorando o buffer, como no caso de leitura aleatória. Buffers grandes não trarão lucro em velocidade, mas começarão a atingir o GC.
Ao ler seqüencialmente grandes partes do arquivo, você deve definir o buffer como 1 MB para HDD e 4kB para SSD. Bem, isso depende.
MMF vs FileStream
Em 2011, uma dica chegou ao MemoryMappedFile, pois esse mecanismo foi implementado desde o .Net Framework v4.0. Primeiro, eles o usavam ao armazenar em cache o filtro Bloom, que já era inconveniente no modo de 32 bits devido à limitação de 4 GB. Mas ao me mudar para o mundo de 64 bits, eu queria mais. Os primeiros testes foram impressionantes. Armazenamento em cache gratuito, velocidade anormal, interface de leitura conveniente da estrutura. Mas houve problemas:
- Primeiro, curiosamente, velocidade. Se os dados já estiverem armazenados em cache, tudo está bem. Mas, se não, a leitura de um byte do arquivo era acompanhada de uma "elevação" de uma quantidade muito maior de dados do que seria com uma leitura regular.
- Em segundo lugar, curiosamente, memória. Quando aquecida, a memória compartilhada aumenta, funciona - não, o que é lógico. Mas então os processos vizinhos começam a se comportar não muito bem. Eles podem entrar em uma troca ou acidentalmente cair da OoM. O volume ocupado pelo MMF na RAM, infelizmente, não pode ser controlado. E o lucro do cache no caso em que o arquivo legível é um par de ordens de magnitude maior que a memória fica sem sentido.
O segundo problema ainda poderia ser combatido. Ele desaparece se o índice funcionar na janela de encaixe ou em uma máquina virtual dedicada. Mas o problema da velocidade foi fatal.
Como resultado, o FMM foi abandonado um pouco mais do que completamente. O armazenamento em cache no antiplágio começou a ser feito de forma explícita, se possível mantendo na memória as camadas mais usadas nas prioridades e limites.

Fonte da imagem: Wikipedia
Bits / bytes
Não bytes, o mundo é um. Às vezes você precisa descer para o nível de bit.
Por exemplo: suponha que você tenha um trilhão de números parcialmente pedidos, ansiosos para salvar e ler com freqüência. Como trabalhar com tudo isso?
- BinaryWriter.Write simples? - rápido, mas lento. Tamanho importa. A leitura a frio depende principalmente do tamanho do arquivo.
- Outra variação do VarInt? - rápido, mas lento. A consistência é importante. O volume começa a depender dos dados, o que requer memória adicional para o posicionamento.
- Bit embalagem? - rápido, mas lento. Você precisa controlar suas mãos com mais cuidado.
Não existe uma solução ideal, mas no caso específico, basta comprimir o intervalo de 32 bits ao necessário para armazenar as caudas economizadas 12% mais (dezenas de GB!) Do que o VarInt (economizando apenas a diferença das vizinhas, é claro), e isso é várias vezes opção básica.
Outro exemplo Você tem um link em um arquivo para alguma matriz de números. Link de 64 bits, arquivo por terabyte. Tudo parece bem. Às vezes, existem muitos números na matriz, às vezes poucos. Muitas vezes um pouco. Com muita frequência Em seguida, basta pegar e armazenar toda a matriz no próprio link. Lucro Faça as malas com cuidado, mas não esqueça.
Estruturas, inseguras, lotes, microopções
Bem e outras micro otimizações. Não escreverei aqui sobre o banal "vale a pena salvar o comprimento da matriz em um loop" ou "o que é mais rápido, para ou foreach".
Existem duas regras simples, e vamos segui-las: 1. "compare tudo", 2. "mais benchmark".
Struct . Usado em qualquer lugar. Não envie GC. E, como está na moda hoje, também temos nossa própria ValueList mega-rápida.
Inseguro . Permite mapit (e unmap) estruturas para uma matriz de bytes quando usado. Portanto, não precisamos de meios separados de serialização. É verdade que existem perguntas para fixar e desfragmentar a pilha, mas até agora ela não foi mostrada. Bem, isso depende.
Dosagem . O trabalho com muitos elementos deve ser feito por pacotes / grupos / blocos. Arquivo de leitura / gravação, transferência entre funções. Um problema separado é o tamanho desses pacotes. Geralmente, existe um ótimo, e seu tamanho geralmente varia de 1kB a 8MB (tamanho do cache da CPU, tamanho do cluster, tamanho da página, tamanho de outra coisa). Tente bombear a função IEnumerable <byte> ou IEnumerable <byte [1024]> e sinta a diferença.
Pooling . Toda vez que você escreve "novo", um gatinho morre em algum lugar. Uma vez novo byte [ 85000 ] - e o trator montou uma tonelada de gansos. Se não for possível usar o stackalloc, crie um conjunto de objetos e reutilize-o novamente.
Inlining . Como criar duas funções em vez de uma pode acelerar tudo dez vezes? Simples. Quanto menor o tamanho do corpo da função (método), maior a probabilidade de ela estar alinhada. Infelizmente, no mundo das dotnet ainda não há como fazer inlining parcial; portanto, se você tiver uma função quente que, em 99% dos casos, sai após o processamento das primeiras linhas, e as centenas de linhas restantes processam o 1% restante, divida-o com segurança em dois (ou três), carregando a cauda pesada em uma função separada.
O que mais?
Span <T> , Memory <T> - prometidamente. O código será mais simples e talvez um pouco mais rápido. Estamos aguardando o lançamento do .Net Core v3.0 e Std v2.1 para mudar para eles, porque nosso kernel no .Net Std v2.0, que normalmente não suporta extensões.
Assíncrono / aguardar - até agora controverso. Os benchmarks de leitura aleatória mais simples mostraram que o consumo da CPU está realmente caindo, mas a velocidade de leitura também está diminuindo. Deve assistir. Ainda não o estamos usando no índice.
Conclusão
Espero que meu afastamento lhe dê prazer em entender a beleza de algumas decisões. Nós realmente gostamos do nosso índice. É um código eficiente e bonito, funciona muito bem. Uma solução altamente especializada no núcleo do sistema, o local crítico de seu trabalho, é melhor que o geral. Nosso sistema de controle de versão lembra as inserções do assembler no código C ++. Agora, existem quatro vantagens - apenas C # puro, apenas .Net. Nela, escrevemos até os algoritmos de pesquisa mais complexos e não nos arrependemos. Com o advento do .Net Core, a transição para o Docker, o caminho para um futuro brilhante do DevOps se tornou mais fácil e claro. A frente é a solução do problema de fragmentação e replicação dinâmicas sem reduzir a eficácia e a beleza da solução.
Obrigado a todos que leram até o fim. Para todas as discrepâncias e outras inconsistências, escreva comentários. Ficarei feliz em receber qualquer conselho razoável e refutá-lo nos comentários.