Desde 1999, nosso banco utiliza o sistema bancário integrado BISKVIT na plataforma Progress OpenEdge para atender o back office, amplamente utilizado em todo o mundo, inclusive no setor financeiro. O desempenho deste DBMS permite ler até um milhão ou mais registros por segundo em um banco de dados (DB). Nosso Progress OpenEdge atende cerca de 1,5 milhão de depósitos de pessoas físicas e cerca de 22,2 milhões de contratos de produtos ativos (empréstimos para automóveis e hipotecas) e também é responsável por todos os acordos com o regulador (CB) e SWIFT.

Usando o Progress OpenEdge, somos confrontados com o fato de que precisamos fazer amizade com o Oracle DBMS. Inicialmente, esse pacote foi o "gargalo" da nossa infraestrutura - até a instalação e configuração do Pro2 CDC - um produto Progress que permite enviar dados do Progress DBMS para o Oracle DBMS diretamente, on-line. Neste post, explicaremos em detalhes, com todas as armadilhas, como efetivamente fazer amizade com o OpenEdge e Oracle.
Como foi: upload de dados para o QCD através do compartilhamento de arquivos
Primeiro, alguns fatos sobre nossa infraestrutura. O número de usuários ativos do banco de dados é de aproximadamente 15 mil. O volume de todos os bancos de dados produtivos, incluindo réplica e espera, é de 600 TB, o maior banco de dados é de 16,5 TB. Ao mesmo tempo, os bancos de dados são constantemente reabastecidos: somente no último ano, foram adicionados cerca de 120 TB de dados produtivos. O sistema fornece 150 servidores front-end na plataforma x86. Os bancos de dados estão hospedados em 21 servidores da plataforma IBM.
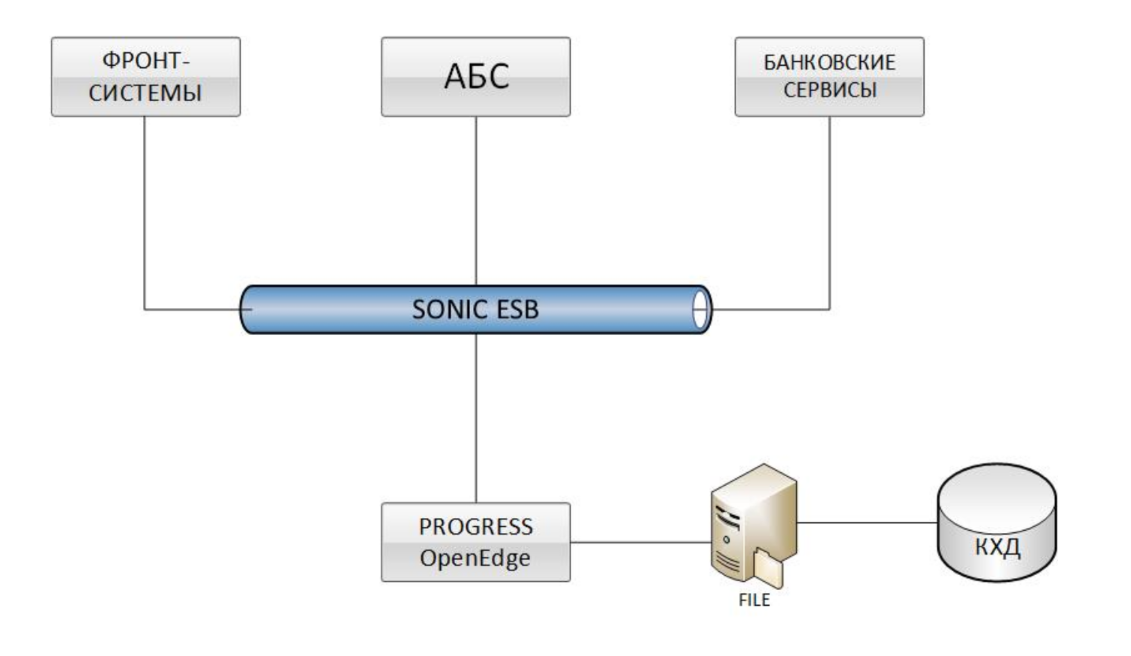
Os sistemas frontais, vários serviços bancários e de ABS são integrados ao OpenEdge Progress (IBS BISQUIT) por meio do barramento Sonic ESB. Os dados são carregados no QCD através da troca de arquivos. Essa solução, até um determinado momento, imediatamente teve dois grandes problemas - o baixo desempenho do upload de informações para o data warehouse corporativo (QCD) e o tempo necessário para reconciliar os dados (reconciliação) com outros sistemas.
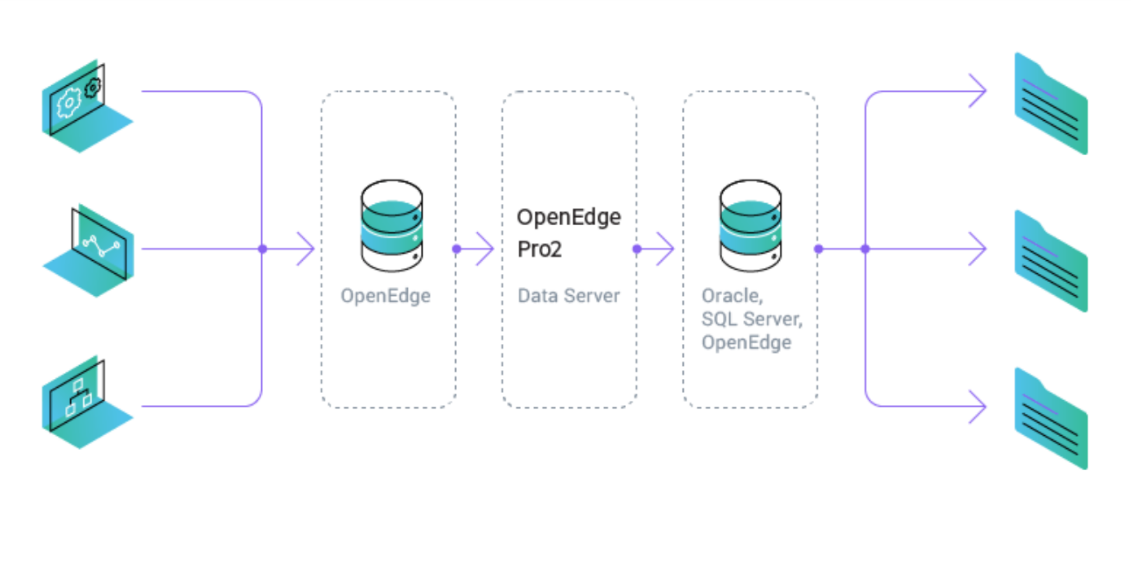
Portanto, começamos a procurar uma ferramenta que pudesse acelerar esses processos. A solução para ambos os problemas foi precisamente o novo produto Progress OpenEdge - Pro2 CDC (Change Data Capture). Então, vamos começar.
Instalar Progress OpenEdge e Pro2Oracle
Para executar o Pro2 Oracle no computador Windows de um administrador, basta instalar o Progress OpenEdge Developer Kit Classroom Edition, que pode ser
baixado gratuitamente. Diretórios de instalação padrão do OpenEdge:
DLC: C: \ Progresso \ OpenEdge
WRK: C: \ OpenEdge \ WRKOs processos de ETL requerem licenças Progress OpenEdge versão 11.7+ - ou seja, OE DataServer para Oracle e 4GL Development System. Essas licenças estão incluídas no Pro2. Para operação completa do DataServer for Oracle com um banco de dados Oracle remoto, o Full Oracle Client está instalado.
No servidor Oracle, você precisa instalar a versão do Oracle Database 12+, criar um banco de dados vazio e adicionar o usuário (vamos chamá-lo de
cdc ).
Para instalar o Pro2Oracle, baixe o pacote de distribuição mais recente no centro de download da
Progress Software . Descompacte o arquivo no diretório
C: \ Pro2 (o mesmo kit de distribuição é usado para configurar o Pro2 no Unix e os mesmos princípios de configuração são aplicados).
Criando um banco de dados de replicação cdc
O banco de dados de replicação
cdc (repl) é usado pelo Pro2 para armazenar informações de configuração, incluindo o mapa de replicação, os nomes dos bancos de dados replicados e suas tabelas. Ele também contém uma fila de replicação que consiste em anotações sobre o fato de a linha da tabela no banco de dados de origem ter sido alterada. Os dados da fila de replicação são usados pelos processos ETL para identificar as linhas que precisam ser copiadas para o Oracle a partir do banco de dados de origem.
Crie um banco de dados cdc separado.
Procedimento para criar um banco de dados- No servidor de banco de dados, crie um diretório para o banco de dados cdc - por exemplo, em / database / cdc / server.
- Crie um manequim para a base do cdc: procopy $ DLC / cdc vazio
- Ativar suporte a arquivos grandes: proutil cdc -C EnableLargeFiles
- Preparamos o script para iniciar o banco de dados cdc. Os parâmetros de início devem ser semelhantes aos parâmetros de início do banco de dados replicado.
- Iniciamos o banco de dados cdc.
- Nós nos conectamos ao banco de dados cdc e carregamos o diagrama Pro2 a partir do arquivo cdc.df , incluído no pacote Pro2.
- No banco de dados cdc, crie os seguintes usuários:
pro2adm - para conectar a partir do painel de administração do Pro2;
pro2etl - para conectar processos ETL (ReplBatch);
pro2cdc - para conectar processos do CDC (CDCBatch); Ativando o OpenEdge Change Data Capture
Agora, vamos ativar o próprio mecanismo do CDC, através do qual os dados serão replicados para uma área tecnológica adicional. Em cada banco de dados de origem Progress OpenEdge, você precisa adicionar áreas de armazenamento separadas nas quais os dados de origem serão duplicados e ativar o próprio mecanismo usando o
comando proutil .
Procedimento de exemplo para o banco de dados bisquit- Copie o arquivo cdcadd.st do diretório C: \ Pro2 \ db para o diretório do banco de dados de origem bisquit .
- Descrevemos em extensões de extensão fixa cdcadd.st para as áreas ReplCDCArea e ReplCDCArea_IDX . Você pode adicionar novas áreas de armazenamento on-line: prostrct addonline bisquit cdcadd.st
- Ative o OpenEdge CDC:
proutil bisquit -C enablecdc area "ReplCDCArea" indexarea "ReplCDCArea_IDX"
- Os seguintes usuários devem ser criados no banco de dados de origem para identificar os processos em execução:
a. pro2adm - para conectar no painel de administração do Pro2.
b. pro2etl - para conectar processos ETL (ReplBatch).
c. pro2cdc - para conectar processos do CDC (CDCBatch).
Criando um suporte de esquema para o DataServer for Oracle
Em seguida, precisamos criar o titular do esquema do banco de dados no servidor em que os dados do DBMS Progress para o DBMS Oracle serão replicados. O DataServer Schema Holder é um banco de dados Progress OpenEdge vazio, sem usuários ou dados do aplicativo, contendo um mapa de correspondência entre as tabelas de origem e as tabelas externas do Oracle.
O banco de dados do Titular do Esquema do Progress OpenEdge DataServer para Oracle para Pro2 deve estar localizado no servidor de processo ETL, criado separadamente para cada filial.
Como criar um titular de esquema- Descompacte a distribuição do Pro2 no diretório / pro2
- Crie e acesse o diretório / pro2 / dbsh
- Crie o banco de dados Titular do Esquema usando o comando procopy $ DLC / empty bisquitsh
- Convertemos bisquitsh na codificação necessária - por exemplo, em UTF-8, se os bancos de dados Oracle estiverem codificados em UTF-8: proutil bisquitsh -C convchar converter UTF-8
- Depois de criar um banco de dados bisquitsh vazio, nos conectamos a ele no modo de usuário único: pro bisquitsh
- Vá para o Dicionário de dados: Ferramentas -> Dicionário de dados -> DataServer -> Utilitários ORACLE -> Criar esquema do DataServer
- Iniciar titular do esquema
- Configure o Oracle DataServer broker:
a. Inicie AdminServer.
proadsv -start
b. Início do Oracle DataServer Broker
oraman -name orabroker1 -start
Configurar o painel de administração e o esquema de replicação
O painel de administração do Pro2 define as configurações do Pro2, incluindo a configuração do esquema de replicação e a geração de programas de processo ETL (Processor Library), programas principais de sincronização (Bulk-Copy Processor), gatilhos de replicação e políticas do OpenEdge CDC. Existem também ferramentas principais para monitorar e gerenciar processos ETL e CDC. Primeiro, configuramos os arquivos de parâmetros.
Como configurar arquivos de parâmetros- Vá para o diretório C: \ Pro2 \ bprepl \ Scripts
- Abra o arquivo replProc.pf para edição
- Adicione os parâmetros para conectar-se ao banco de dados de replicação cdc:
# Banco de dados de replicação
-db cdc -ld repl -H <nome do host do banco de dados principal> -S <porta do broker do banco de dados cdc>
-U pro2admin -P <senha>
- Adicione os parâmetros para conectar-se aos bancos de dados de origem e ao Schema Holder na forma de arquivos de parâmetros para replProc.pf . O nome do arquivo de parâmetro deve corresponder ao nome do banco de dados de origem a ser conectado.
# Conecte-se a todos os BISQUIT de origem replicada
-pf bprepl \ scripts \ bisquit.pf
- Adicione os parâmetros para conectar-se ao titular do esquema no replProc.pf.
Titular do esquema do #Darget Pro DB
-db bisquitsh -ld bisquitsh
-H <nome do host dos processos ETL>
-S <porta do broker biskuitsh>
-db bisquitsql
-ld bisquitsql
-dt ORACLE
-S 5162 -H <nome do host do broker Oracle>
-DataService orabroker1
- Salve o arquivo de parâmetro replProc.pf
- Em seguida, é necessário criar e abrir para editar os arquivos de parâmetros para cada banco de dados de origem conectado no diretório C: \ Pro2 \ bprepl \ Scripts: bisquit.pf . Cada arquivo pf contém parâmetros para conectar-se ao banco de dados correspondente, por exemplo:
-db bisquit -ld bisquit -H <nome do host> -S <porta do broker>
-U pro2admin -P <senha>
Para configurar os atalhos do Windows, vá para o
diretório C: \ Pro2 \ bprepl \ Scripts e edite o atalho “Pro2 - Administração”. Para fazer isso, abra as propriedades do atalho e, na linha
Iniciar, indique o diretório de instalação Pro2. Uma operação semelhante precisa ser feita para os rótulos “Pro2 - Editor” e “RunBulkLoader”.
Configurando a administração do Pro2: baixando a configuração principal
Lançamos o console.
Vá para o "DB Map".

Para vincular os bancos de dados no Pro2 - Administration, vá para a guia
DB Map . Adicionamos o mapeamento de bancos de dados de origem -
Schema Holder - Oracle .

Vá para a guia
Mapeamento . Na lista
Banco de Dados de Origem , o primeiro banco de dados de origem conectado é selecionado por padrão. À direita da lista deve estar
Todos os bancos de dados conectados - os bancos de dados selecionados estão conectados. Uma lista de tabelas Progress do bisquit deve estar visível abaixo, à esquerda. À direita, há uma lista de tabelas do banco de dados Oracle.
Criando esquemas e bancos de dados SQL no Oracle
Para criar um mapa de replicação, você deve primeiro gerar o
esquema SQL no Oracle. Na Administração do Pro2, execute o item de menu
Ferramentas -> Gerar código -> Esquema de destino e , na caixa de diálogo
Selecionar banco de dados,
selecione um ou mais bancos de dados de origem e transfira-os para a direita.

Clique em OK e selecione o diretório para salvar os esquemas SQL.
Em seguida, criamos a base. Isso pode ser feito, por exemplo, através do
Oracle SQL Developer . Para fazer isso, conecte-se ao banco de dados Oracle e carregue o esquema para adicionar tabelas. Após alterar a composição das tabelas Oracle, é necessário atualizar os esquemas SQL no Titular do Esquema.

Após o download ser concluído com êxito, saia do banco de dados bisquitsh e abra o painel de administração do Pro2. As tabelas do banco de dados Oracle devem aparecer na guia Mapeamento à direita.
Tabelas de mapeamento
Para criar um mapa de replicação no painel de administração do Pro2, vá para a guia Mapeamento, selecione o banco de dados de origem. Clicamos em Mapear tabelas, selecionamos à esquerda as tabelas Selecionar alterações que devem ser replicadas para Oracle, transferimos para a direita e confirmamos a seleção. Um mapa será criado automaticamente para as tabelas selecionadas. Repita a operação para criar um mapa de replicação para outros bancos de dados de origem.
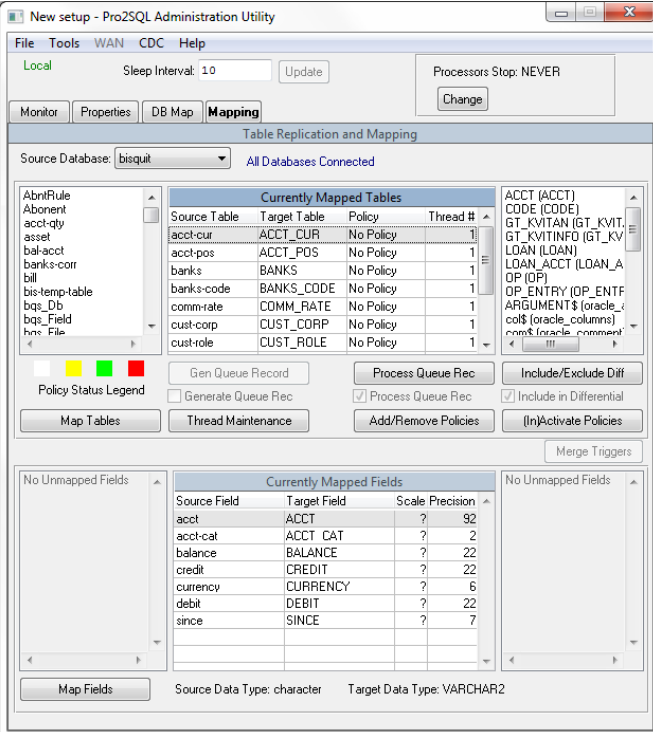
Geração dos programas da biblioteca do processador de replicação Pro2 e do processador de cópia em massa
A Biblioteca do processador foi projetada para ETLs (processos especiais de replicação) que processam a fila de replicação Pro2 e enviam as alterações para o banco de dados Oracle. Após a geração, os programas da biblioteca do processador de replicação são salvos automaticamente no
diretório bprepl / repl_proc (parâmetro PROC_DIRECTORY) . Para gerar a biblioteca do processador de replicação, acesse
Ferramentas -> Gerar código -> Biblioteca do processador. Após a conclusão da geração, os programas aparecerão no
diretório bprepl / repl_proc .
Os programas de processador em massa são usados para sincronizar os bancos de dados Progress de origem com o banco de dados Oracle de destino com base na linguagem de programação Progress ABL (4GL). Para gerá-los, vá para o item de menu
Ferramentas -> Gerar código -> Processador de cópia em massa . Na caixa de diálogo Selecionar banco de dados, selecione o banco de dados de origem, transfira-o para o lado direito da janela e clique em
OK . Após a conclusão da geração, os programas aparecerão no
diretório bprepl \ repl_mproc .
Configurando processos de replicação no Pro2
Dividir as tabelas em conjuntos atendidos por um thread de replicação separado pode melhorar o desempenho e a eficiência do Oracle Pro2. Por padrão, todas as conexões criadas no mapa de replicação para novas tabelas de replicação são vinculadas ao fluxo número 1. É recomendável que as tabelas sejam divididas em fluxos diferentes.
As informações sobre o status dos fluxos de replicação são exibidas na tela Administração do Pro2 na guia Monitor na seção Status da replicação. Uma descrição detalhada dos valores dos parâmetros pode ser encontrada na documentação do Pro2 (diretório C: \ Pro2 \ Docs).
Criar e ativar políticas do CDC
Políticas são um conjunto de regras para o mecanismo OpenEdge CDC, de acordo com o qual as alterações nas tabelas são rastreadas. No momento da redação deste artigo, o Pro2 suporta apenas políticas CDC com nível 0, ou seja, apenas o fato de
uma alteração de registro é rastreado.
Para criar uma política do CDC no painel administrativo, vá para a guia Mapeamento, selecione o banco de dados de origem e clique no botão Adicionar / Remover Políticas. Na janela Selecionar Alterações que se abre, selecione no lado esquerdo e transfira para a tabela direita para a qual você precisa criar ou excluir uma política do CDC.
Para ativar, abra a guia Mapeamento novamente, selecione o banco de dados de origem e clique no botão
(In) Ativar Políticas . Selecione e transfira para o lado direito da tabela cujas políticas você precisa ativar, clique em OK. Depois disso, eles são marcados em verde. Usando
(In) Ativar Políticas , você também pode desativar as políticas do CDC. Todas as operações são realizadas online.

Após ativar a política do CDC, as notas sobre os registros alterados são salvas na área de armazenamento
“ReplCDCArea” , de acordo com o banco de dados original. Essas notas serão processadas por um processo especial do
CDCBatch , que, com base nas mesmas, criará notas na fila de replicação do Pro2 no banco de dados
cdc (repl) .
Portanto, temos duas filas para replicação. O primeiro estágio é o CDCBatch: do banco de dados original, os dados vão primeiro para o banco de dados intermediário do CDC. O segundo estágio é quando os dados são derramados do banco de dados do CDC no Oracle. Esse é um recurso da arquitetura atual e do próprio produto - até o momento, os desenvolvedores não conseguiram estabelecer a replicação direta.
Sincronização primária
Depois de ativar o mecanismo CDC e configurar o servidor de replicação Pro2, precisamos iniciar a sincronização principal. Comando de início da sincronização primária:
/pro2/bprepl/Script/replLoad.sh bisquit nome-da-tabelaApós a conclusão da sincronização inicial, os processos de replicação podem ser iniciados.
Iniciar processos de replicação
Para iniciar os processos de replicação, você precisa executar o script
replbatch.sh . Antes de iniciar, verifique se há scripts replbatch para todos os threads - replbatch1, replbatch2, etc. Se tudo estiver no lugar, abra a linha de comandos (por exemplo,
proenv) , acesse o
diretório / bprepl / scripts e inicie o script. No painel administrativo, verificamos que o processo correspondente recebeu o status EXECUTANDO.

Resultados
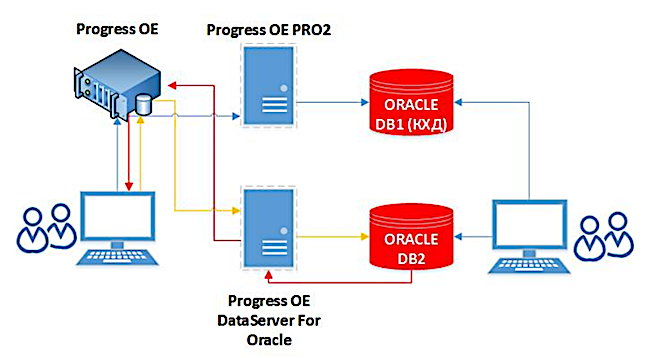
Após a implementação, aceleramos bastante o upload de informações para o data warehouse corporativo. Os dados em si vão para o Oracle online. Não é necessário gastar tempo em algumas consultas de longa duração para coletar dados de diferentes sistemas. Além disso, nesta solução, o processo de replicação pode compactar dados, o que também tem um efeito positivo na velocidade. Agora, a reconciliação diária do sistema BISKVIT com outros sistemas começou a levar de 15 a 20 minutos, em vez de 2 a 2,5 horas, e a reconciliação total - várias horas, em vez de dois dias.