Prefácio
Este artigo não é muito semelhante ao que foi publicado anteriormente sobre a varredura na Internet de certos países, porque eu não persegui os objetivos de varrer em massa um segmento específico da Internet em busca de portas abertas e a presença das vulnerabilidades mais populares por ser ilegal.
Eu preferia ter um interesse um pouco diferente - tentar identificar todos os sites relevantes na zona de domínio BY usando métodos diferentes, determinar a pilha de tecnologias usadas, através de serviços como Shodan, VirusTotal, etc. para realizar reconhecimento passivo por IP e portas abertas e, no apêndice, coletar um pouco mais de utilidade. informações para a formação de algumas estatísticas gerais sobre o nível de segurança de sites e usuários.
Introdutório e nosso kit de ferramentas
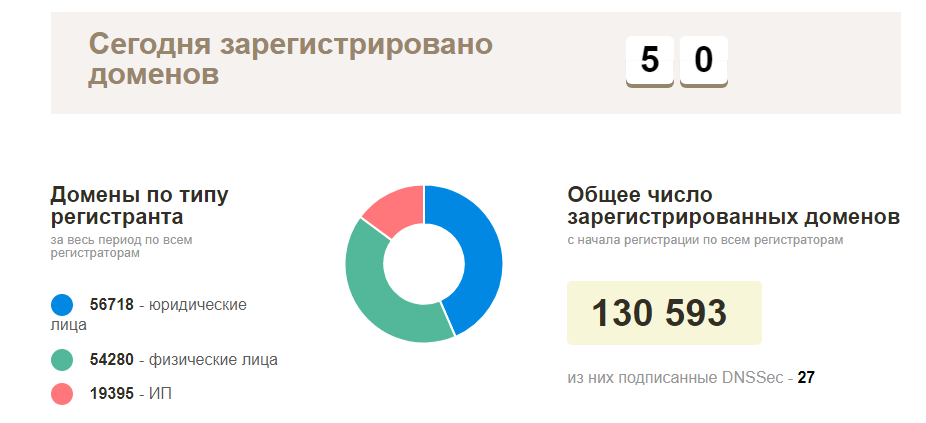
O plano no início era simples - entre em contato com o registrador local para obter uma lista dos domínios registrados atuais, verifique tudo quanto à disponibilidade e comece a explorar os sites em funcionamento. Na realidade, tudo se tornou muito mais complicado - esse tipo de informação era natural, ninguém queria fornecer, com exceção da página oficial de estatísticas dos nomes de domínio registrados reais na zona BY (cerca de 130 mil domínios). Se não houver essas informações, você deverá coletá-las.
Em termos de ferramentas, de fato, tudo é bastante simples - nós olhamos para o código aberto, você sempre pode adicionar algo, terminar algumas muletas mínimas. Das mais populares, as seguintes ferramentas foram usadas:
Início das atividades: ponto de partida
Como introdução, como eu já disse, os nomes de domínio ideais eram adequados, mas onde obtê-los? Precisamos começar de algo mais simples, nesse caso, os endereços IP são adequados para nós, mas novamente - com pesquisas inversas, nem sempre é possível capturar todos os domínios e ao coletar nomes de host - nem sempre é o domínio correto. Nesse estágio, comecei a pensar em possíveis cenários para coletar esse tipo de informação novamente - o fato de que nosso orçamento era de US $ 5 para aluguel de VPS foi levado em consideração, todo o resto deveria ser gratuito.
Nossas fontes potenciais de informação:
- Endereços IP (site ip2location )
- Pesquise domínios pela segunda parte do endereço de e-mail (mas onde obtê-los?
- Alguns registradores / provedores de hospedagem podem nos fornecer essas informações na forma de subdomínios
- Subdomínios e seu subsequente reverso (Sublist3r e Aquatone podem ajudar aqui)
- Bruteforce e entrada manual (longa, sombria, mas possível, embora eu não tenha usado essa opção)
Vou avançar um pouco e dizer que, com essa abordagem, consegui coletar cerca de 50 mil domínios e sites exclusivos, respectivamente (não consegui processar tudo). Se ele continuasse a coletar informações ativamente, com certeza, em menos de um mês de trabalho, minha transportadora dominaria todo o banco de dados, ou a maior parte.
Vamos ao que interessa
Em artigos anteriores, as informações sobre endereços IP foram obtidas do site IP2LOCATION, por razões óbvias, não encontrei esses artigos (já que todas as ações ocorreram muito antes), mas também cheguei a esse recurso. É verdade que, no meu caso, a abordagem foi diferente - decidi não levar o banco de dados localmente para mim e não extrair informações do CSV, mas decidi monitorar as alterações diretamente no site, de forma contínua e como a base principal de onde todos os scripts subsequentes terão objetivos - fiz uma tabela com Endereços IP em diferentes formatos: CIDR, lista "de" e "para", marca do país (apenas no caso), número AS, descrição AS.
O formato não é o ideal, mas fiquei muito feliz com a demonstração e a promoção única e, para não buscar constantemente informações adicionais como a ASN, decidi registrá-las por conta própria. Para obter essas informações, virei-me para o serviço
IpToASN , eles têm uma API conveniente (com restrições), que na verdade você só precisa integrar a si mesmo.
Código de análise de IPfunction ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
Depois que descobrimos o IP, precisamos executar todo o banco de dados através dos serviços de pesquisa inversa, infelizmente, sem nenhuma restrição - isso é impossível, exceto pelo dinheiro.
Dos serviços que são ótimos para isso e convenientes de usar, quero mencionar dois:
- VirusTotal - limite na frequência de chamadas de uma chave de API
- Hackertarget.com (sua API) - limite no número de acessos de um IP
Ignorando os limites, foram obtidas as seguintes opções:
- No primeiro caso, um dos cenários é suportar tempos limite de 15 segundos; no total, teremos 4 chamadas por minuto, o que pode afetar bastante nossa velocidade e, nessa situação, será útil usar 2-3 dessas chaves, enquanto eu recomendaria recorrer ao mesmo para proxy e alterar user-agent.
- No segundo caso, escrevi um script para análise automática do banco de dados proxy com base em informações publicamente disponíveis, sua validação e uso subseqüente (mas depois deixei essa opção porque o VirusTotal também era suficiente em essência)
Vamos mais longe e sem problemas nos endereços de email. Eles também podem ser uma fonte de informações úteis, mas onde coletá-los? Não demorou muito tempo para encontrar uma solução, os usuários detêm pouco em nosso segmento de sites pessoais e a maioria deles são organizações - sites de perfil como diretórios de lojas on-line, fóruns e mercados condicionais nos convêm.
Por exemplo, uma inspeção rápida de um desses sites mostrou que muitos usuários adicionam seus emails diretamente ao perfil público e, portanto, esse negócio pode ser analisado com cuidado para uso futuro.
Não analisarei os detalhes da análise de cada site; em algum lugar é mais conveniente adivinhar o ID do usuário com força bruta; em algum lugar é mais fácil analisar um mapa do site, obter informações sobre as páginas da empresa e coletar endereços deles. Depois de coletar os endereços, resta executar várias operações simples, classificando-as imediatamente pela zona do domínio, preservando as "caudas" e executando-as para excluir duplicatas do banco de dados existente.
Nesta fase, acredito que com a formação do escopo, podemos terminar e avançar para a inteligência. A inteligência, como já sabemos, pode ser de dois tipos - ativa e passiva, no nosso caso - a abordagem passiva será mais relevante. Mas, novamente, acessar o site na porta 80 ou 443 sem carga maliciosa e explorar vulnerabilidades é uma ação bastante legítima. Nosso interesse são as respostas do servidor a uma única solicitação; em alguns casos, pode haver duas solicitações (redirecionamento de http para https); em casos mais raros, até três (quando www é usado).
Inteligência
Usando essas informações como domínio, podemos coletar os seguintes dados:
- Registros DNS (NS, MX, TXT)
- Cabeçalhos de resposta
- Identifique a pilha de tecnologia usada
- Entenda por qual protocolo o site funciona.
- Tente identificar portas abertas (com base no banco de dados Shodan / Censys) sem varredura direta
- Tente identificar vulnerabilidades com base na correlação de informações do Shodan / Censys com o banco de dados Vulners
- Está no banco de dados de malware da Navegação segura do Google
- Colete endereços de e-mail por domínio, bem como correspondências já encontradas e verifique por Já fui Pwned, além disso - link para redes sociais
- Em alguns casos, um domínio não é apenas o rosto da empresa, mas também o produto de suas atividades, endereços de e-mail para registro em serviços etc., respectivamente - é possível procurar informações que estão associadas a eles em recursos como GitHub, Pastebin, Google Dorks (Google CSE )
Você sempre pode seguir em frente e tirar proveito da opção masscan ou nmap, zmap, configurando-os primeiro pelo Tor com o lançamento em um tempo aleatório ou mesmo em várias instâncias, mas temos outros objetivos e o nome implica que eu não fiz verificações diretas.
Coletamos registros DNS, verificamos a possibilidade de amplificação de solicitações e erros de configuração como o AXFR:
Um exemplo de coleta de registros do servidor NS dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
Exemplo de coleção de registros MX (consulte NS, basta substituir 'ns' por 'mx'
Verifique o AXFR (existem muitas soluções aqui, aqui está outra muleta, mas não a segurança, usada para visualizar as saídas) $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
Verifique se há amplificação de DNS dig +short test.openresolver.com TXT @$dns
No meu caso, os servidores NS foram retirados do banco de dados; portanto, no final da variável, é possível substituir qualquer servidor de fato. Com relação à correção dos resultados deste serviço, não posso ter certeza de que tudo funcione sem problemas e que os resultados sejam sempre válidos, mas espero que a maioria dos resultados seja real.
Se, para qualquer finalidade, precisamos manter um URL final completo para o site, usei cURL para isso:
curl -I -L $target | awk '/Location/{print $2}'
Ele próprio passará por todo o redirecionamento e exibirá o final, ou seja, URL do site atual. No meu caso, foi extremamente útil para o uso subsequente de ferramentas como o WhatWeb.
Por que devemos usá-lo? Para determinar o SO, servidor web, site CMS usado, alguns cabeçalhos, módulos adicionais como bibliotecas / estruturas JS / HTML, bem como o título do site pelo qual você pode tentar filtrar posteriormente pelo mesmo campo de atividade.
Uma opção muito conveniente nesse caso é exportar os resultados da operação da ferramenta no formato XML para análise subseqüente e importar para o banco de dados se houver um objetivo de processá-lo posteriormente.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
Para mim, criei JSON como resultado da saída e já o coloquei no banco de dados.
Falando em cabeçalhos, você pode fazer quase o mesmo com o cURL comum executando uma consulta no formulário:
curl -I https://www.mywebsite.com
Nos cabeçalhos, colete informações no CMS e nos servidores da Web usando expressões regulares, por exemplo.
Além da útil, também podemos destacar a possibilidade de coletar informações sobre portas abertas usando Shodan e, em seguida, usar os dados já obtidos, verificar o banco de dados do Vulners usando sua API (os links para os serviços são fornecidos no cabeçalho). Obviamente, pode haver problemas com a precisão nesse cenário, mas isso não é uma verificação direta com validação manual, mas um "malabarismo" banal de dados de fontes de terceiros, mas pelo menos é melhor do que nada.
Função PHP para Shodan function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
Um exemplo dessa análise comparativa nº 1 Sim, desde que começaram a falar sobre a API, os Vulner têm limitações e a melhor solução seria usar o script Python, tudo funcionará bem sem torções de torção, no caso do PHP, encontrei algumas pequenas dificuldades (novamente, acrescente. timeouts salvaram a situação).
Um dos testes mais recentes - estudaremos as informações no firewall usadas com um script como "wafw00f". Ao testar essa ferramenta maravilhosa, notei uma coisa interessante: nem sempre foi a primeira vez que foi possível determinar o tipo de firewall usado.
Para ver quais tipos de firewalls o wafw00f pode detectar potencialmente, você pode inserir o seguinte comando:
wafw00f -l
Para determinar o tipo de firewall, o wafw00f analisa os cabeçalhos de resposta do servidor após enviar uma solicitação padrão para o site; se essa tentativa não for suficiente, gera uma solicitação de teste simples adicional e, se não for suficiente, o terceiro método opera com os dados após as duas primeiras tentativas. .
Porque para as estatísticas, na verdade, não precisamos de toda a resposta, cortamos todo o excesso com uma expressão regular e deixamos apenas o nome firewall:
/is\sbehind\sa\s(.+?)\n/
Bem, como escrevi anteriormente - além das informações sobre o domínio e o site, as informações sobre endereços de email e redes sociais também foram atualizadas no modo passivo:
Estatísticas por email definidas com base no domínio Um exemplo de determinação da ligação de redes sociais ao endereço de email A maneira mais fácil era lidar com a validação de endereços no Twitter (2 vias), com o Facebook (1 via) a esse respeito, acabou sendo um pouco mais complicado devido a um sistema um pouco mais complexo para gerar uma sessão real do usuário.
Vamos passar para as estatísticas secas.
Estatísticas de DNS
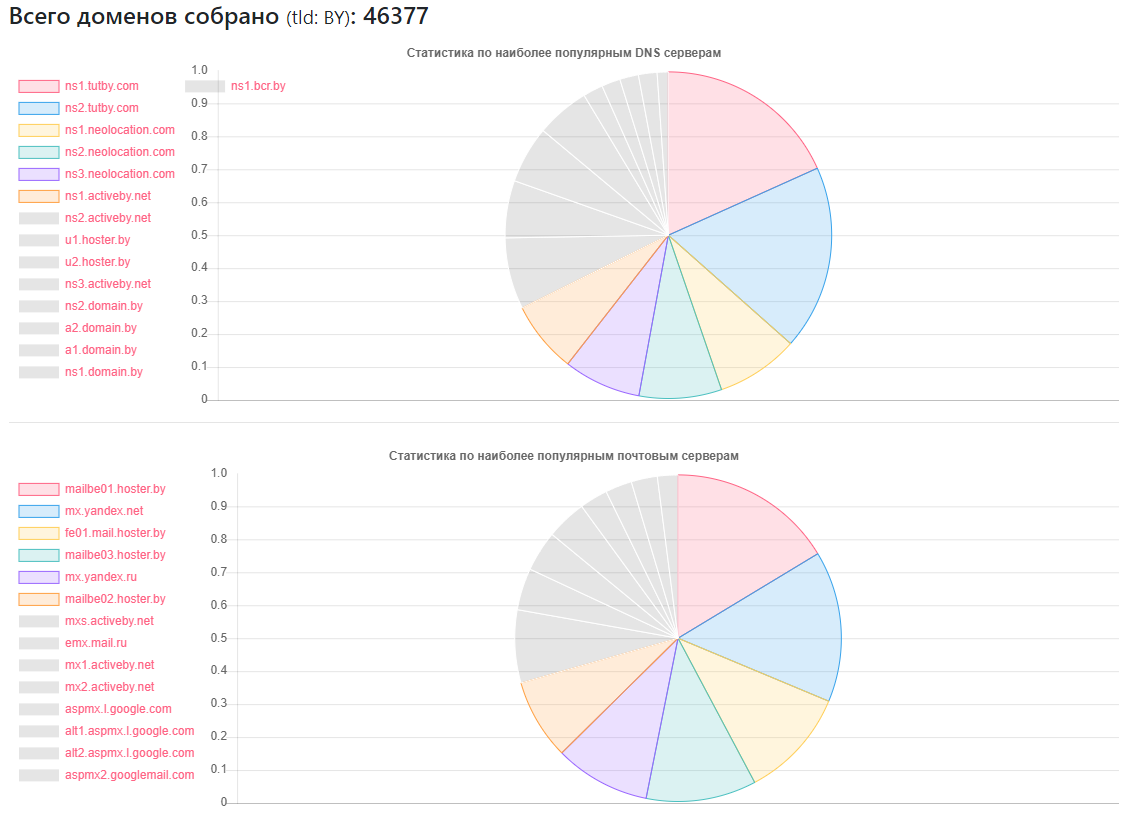 Fornecedor - quantos sites
Fornecedor - quantos sitesns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
DNS único encontrado: 2462
Servidores MX (correio) exclusivos: 9175 (além dos serviços populares, há um número suficiente de administradores que usam seus próprios serviços de correio)
Afetado pela transferência de zona DNS: 1011
Afetado pela amplificação de DNS: 531
Poucos fãs do CloudFlare: 375 (com base nos registros NS usados)
Estatísticas do CMS
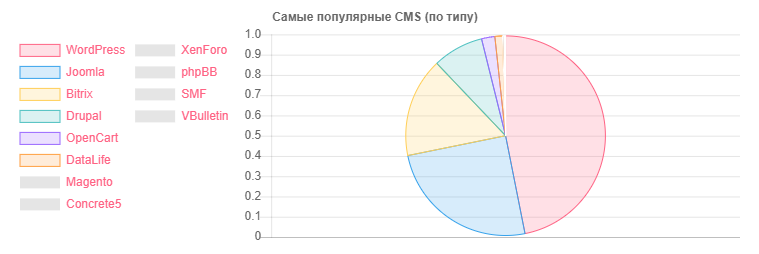 CMS - Quantidade
CMS - QuantidadeWordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Instalações potencialmente vulneráveis do WordPress: 2977
- Instalações potencialmente vulneráveis do Joomla: 212
- Usando o serviço Google SafeBrowsing, foi possível identificar sites potencialmente perigosos ou infectados: cerca de 10.000 (em momentos diferentes, alguém consertou, alguém aparentemente quebrou, as estatísticas não são totalmente objetivas)
- Sobre HTTP e HTTPS - menos da metade dos sites do volume encontrado usa o último, mas levando em consideração o fato de que meu banco de dados não está completo, mas apenas 40% do número total, é bem possível que a maioria da segunda metade dos sites possa se comunicar via HTTPS .
Estatísticas de firewall:
 Firewall - Número
Firewall - NúmeroModSecurity: 4354
IBM Web App Security: 126
Melhor segurança WP: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Estatísticas do servidor Web
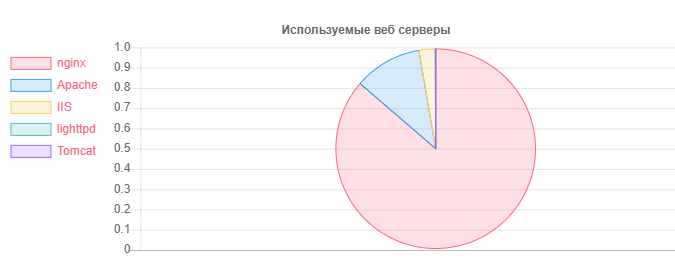 Servidor Web - Número
Servidor Web - NúmeroNginx: 31752
Apache: 4042
IIS: 959
Instalações desatualizadas e potencialmente vulneráveis do Nginx: 20966
Instalações obsoletas e potencialmente vulneráveis do Apache: 995
Apesar do fato de o hoster.by ser o líder em domínios e hospedagem, por exemplo, em geral, o Contato Aberto também foi diferenciado, mas a verdade está no número de sites em um IP:
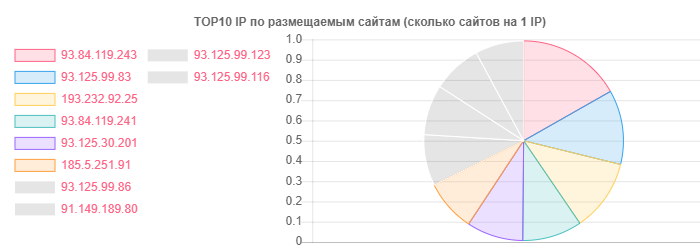 IP - Sites
IP - Sites93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
Por email, as estatísticas detalhadas realmente decidiram não ser extraídas, não classificadas pela zona do domínio; foi interessante ver a localização dos usuários para fornecedores específicos:
- No serviço TUT.BY: 38282
- No serviço Yandex (por | ru): 28127
- No serviço Gmail: 33452
- Amarrado ao Facebook: 866
- Amarrado ao Twitter: 652
- Apresentado nos vazamentos de acordo com o HIBP: 7844
- A inteligência passiva ajudou a identificar mais de 13 mil endereços de email
Como você pode ver, a imagem geral é bastante positiva, especialmente o uso ativo do nginx por parte dos provedores de hospedagem. Talvez isso se deva principalmente ao popular entre usuários comuns - tipo de hospedagem compartilhada.
Pelo fato de eu realmente não gostar, há um número suficiente de provedores de hospedagem de mão intermediária que notaram erros como o AXFR, usaram versões desatualizadas do SSH e Apache e alguns outros problemas menores. Aqui, é claro, mais luz sobre a situação poderia ser lançada pela fase ativa, mas, no momento, em virtude da nossa legislação, parece-me que é impossível, e eu realmente não gostaria de me alistar nas fileiras de pragas para esses assuntos.
A imagem do e-mail geralmente é bastante cor-de-rosa, se você pode chamar assim. Ah, sim, onde o provedor TUT.BY é indicado - isso significa usar o domínio, porque Este serviço funciona com base no Yandex.
Conclusão
Como conclusão, posso dizer uma coisa - mesmo com os resultados disponíveis, você pode entender rapidamente que há uma grande quantidade de trabalho para especialistas envolvidos na limpeza de sites contra vírus, na instalação do WAF e na configuração / adição de CMSs diferentes.
Bem, falando sério, como nos dois artigos anteriores, vemos que os problemas existem em níveis absolutamente diferentes em absolutamente todos os segmentos da Internet e dos países, e alguns deles surgem mesmo quando se estuda remotamente a questão, sem usar métodos ofensivos etc. e usando informações publicamente disponíveis para coletar quais habilidades especiais não são necessárias.