
No último artigo, examinamos os fundamentos teóricos da arquitetura reativa. É hora de falar sobre fluxos de dados, maneiras de implementar sistemas reativos Erlang / Elixir e padrões de mensagens neles:
- Solicitar resposta
- Resposta dividida em solicitação
- Resposta com solicitação
- Publicar-assinar
- Assinatura de publicação invertida
- Distribuição de tarefas
SOA, MSA e sistema de mensagens
SOA, MSA - arquiteturas de sistema que definem as regras para a construção de sistemas, enquanto o sistema de mensagens fornece primitivas para sua implementação.
Não quero promover essa ou aquela arquitetura de construção de sistemas. Sou a favor do uso das práticas mais eficazes e úteis para um projeto e negócio em particular. Qualquer que seja o paradigma que escolhermos, é melhor criar blocos de sistema de olho no caminho Unix: componentes com conectividade mínima que são responsáveis por entidades individuais. Os métodos de API executam as ações mais simples com entidades.
Mensagens - como o nome indica, é um intermediário de mensagens. Seu principal objetivo é receber e enviar mensagens. Ele é responsável pelas interfaces para o envio de informações, a formação de canais lógicos para transmissão de informações no sistema, roteamento e balanceamento e o processamento de falhas no nível do sistema.
As mensagens que estão sendo desenvolvidas não estão tentando competir ou substituir o rabbitmq. Suas principais características:
- Distribuição
Os pontos de troca podem ser criados em todos os nós do cluster, o mais próximo possível do código que os utiliza. - Simplicidade.
Concentre-se em minimizar o código padrão e a usabilidade. - O melhor desempenho.
Não estamos tentando repetir a funcionalidade do rabbitmq, mas apenas destacamos a camada de arquitetura e transporte, o mais simples possível no OTP, minimizando os custos. - Flexibilidade.
Cada serviço pode combinar muitos modelos de intercâmbio. - Tolerância a falhas inerente ao design.
- Escalabilidade.
As mensagens aumentam com o aplicativo. À medida que a carga aumenta, você pode mover os pontos de troca para máquinas individuais.
Observação. Do ponto de vista da organização do código, os metaprojetos são adequados para sistemas complexos com o Erlang / Elixir. Todo o código do projeto está em um repositório - um projeto abrangente. Ao mesmo tempo, os microsserviços são tão isolados quanto possível e executam operações simples que são responsáveis por uma entidade separada. Com essa abordagem, é fácil oferecer suporte à API de todo o sistema, basta fazer alterações, é conveniente escrever unidades e testes de integração.
Os componentes do sistema interagem diretamente ou através de um broker. Do ponto de vista de mensagens, cada serviço tem várias fases da vida:
- Inicialização de serviço.
Nesta fase, a configuração e o lançamento do processo e dependências de execução do serviço ocorrem. - Criando um ponto de troca.
O serviço pode usar o ponto de troca estático especificado na configuração do nó ou criar pontos de troca dinamicamente. - Registro de serviço.
Para que o serviço possa atender a solicitações, ele deve ser registrado no ponto de troca. - Funcionamento normal.
Serviço produz um trabalho útil. - Desligamento.
Existem 2 tipos de desligamento: regular e de emergência. Com um serviço regular, ele se desconecta do ponto de troca e para. Em casos de emergência, o sistema de mensagens executa um dos cenários de failover.
Parece bastante complicado, mas nem tudo é tão assustador no código. Exemplos de código com comentários serão dados na análise de modelos um pouco mais tarde.
Trocas
Um ponto de troca é um processo de mensagens que implementa a lógica de interação com componentes dentro de um modelo de mensagens. Em todos os exemplos abaixo, os componentes interagem por meio de pontos de troca, cuja combinação forma mensagens.
Padrões de troca de mensagens (MEPs)
Globalmente, os padrões de compartilhamento podem ser divididos em dois sentidos e um caminho. O primeiro implica uma resposta à mensagem recebida, o segundo não. Um exemplo clássico de um padrão bidirecional em uma arquitetura cliente-servidor é o padrão Solicitação-resposta. Considere o modelo e suas modificações.
Pedido - resposta ou RPC
O RPC é usado quando precisamos obter uma resposta de outro processo. Esse processo pode ser iniciado no mesmo site ou localizado em um continente diferente. Abaixo está um diagrama da interação do cliente e servidor através de mensagens.
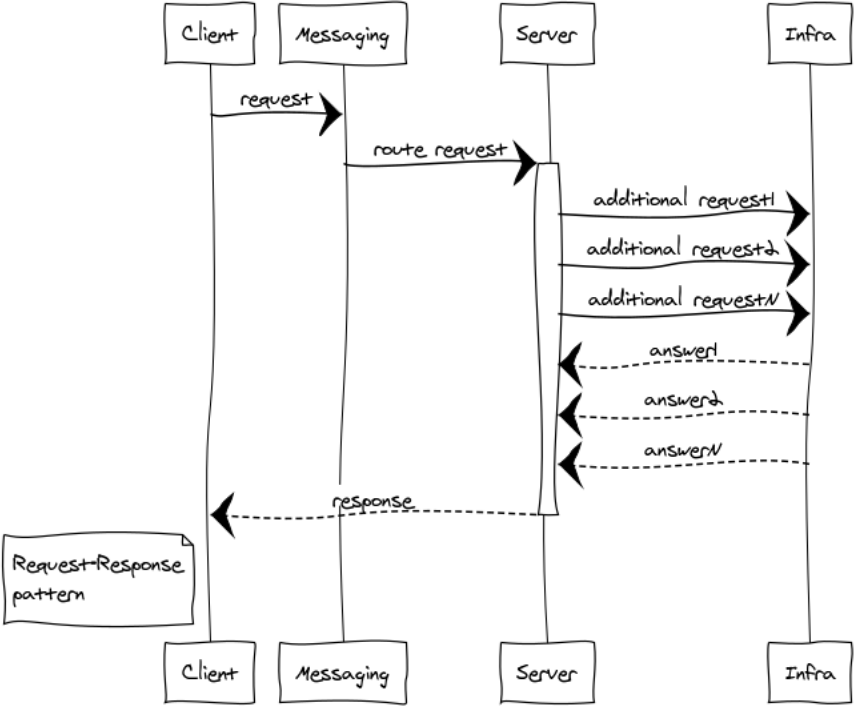
Como o sistema de mensagens é completamente assíncrono, para o cliente, a troca é dividida em 2 fases:
Solicitar envio
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).
Troca - um nome exclusivo para o ponto de troca
ResponseMatchingTag - o rótulo local para lidar com a resposta. Por exemplo, no caso de enviar várias solicitações idênticas pertencentes a usuários diferentes.
RequestDefinition - corpo da solicitação
HandlerProcess - manipulador de PID. Este processo receberá uma resposta do servidor.
Processamento de resposta
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)
ResponsePayload - resposta do servidor.
Para o servidor, o processo também consiste em 2 fases:
- Inicialização do Exchange Point
- Processando solicitações recebidas
Vamos ilustrar este modelo com código. Suponha que precisamos implementar um serviço simples que forneça o único método de tempo exato.
Código do servidor
Retire a definição da API de serviço em api.hrl:
Defina um controlador de serviço em time_controller.erl
Código do cliente
Para enviar uma solicitação a um serviço, você pode chamar a API de solicitação de mensagens em qualquer lugar do cliente:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of ok -> ok; _ ->
Em um sistema distribuído, a configuração dos componentes pode ser muito diferente e, no momento da solicitação, o sistema de mensagens ainda não pode ser iniciado ou o controlador de serviço não estará pronto para atender à solicitação. Portanto, precisamos verificar a resposta do sistema de mensagens e lidar com o caso de falha.
Após o envio bem-sucedido, o cliente receberá uma resposta ou erro do serviço.
Manipule os dois casos em handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) -> ?debugVal(Utime), {noreply, State}; handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) -> ?debugVal({error, ErrorCode}), {noreply, State};
Resposta dividida em solicitação
Melhor não permitir a transmissão de grandes mensagens. A capacidade de resposta e a operação estável de todo o sistema dependem disso. Se a resposta à solicitação consumir muita memória, uma divisão em partes é obrigatória.
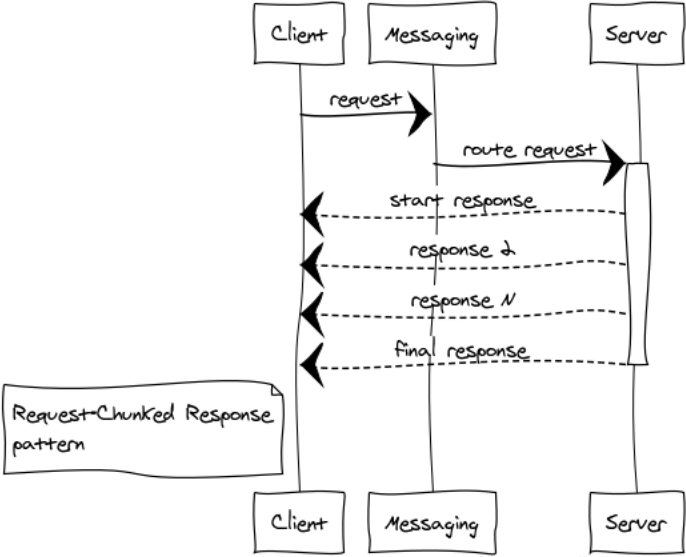
Aqui estão alguns exemplos desses casos:
- Os componentes trocam dados binários, como arquivos. A divisão da resposta em pequenas partes ajuda a trabalhar eficientemente com arquivos de qualquer tamanho e a não captar estouros de memória.
- Listagens. Por exemplo, precisamos selecionar todos os registros de uma grande tabela no banco de dados e transferi-los para outro componente.
Eu chamo essas respostas de locomotiva. De qualquer forma, 1024 mensagens de 1 MB são melhores que uma única mensagem de 1 GB.
No cluster Erlang, obtemos um ganho adicional - reduzindo a carga no ponto de troca e na rede, já que as respostas são enviadas imediatamente ao destinatário, ignorando o ponto de troca.
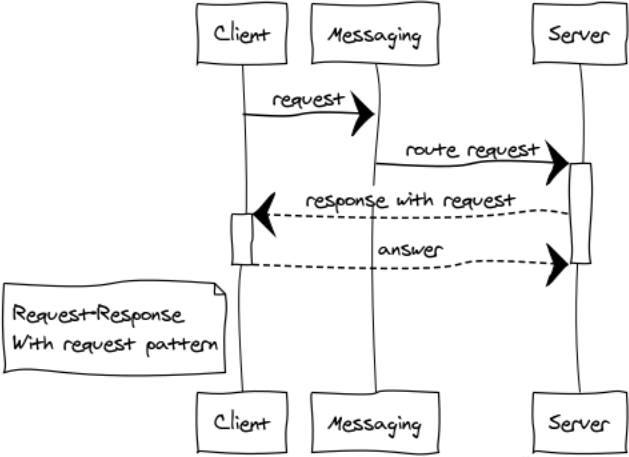
Resposta com solicitação
Essa é uma modificação bastante rara do padrão RPC para a construção de sistemas interativos.
Publicar-assinar (árvore de distribuição de dados)
Os sistemas orientados a eventos entregam dados aos consumidores, à medida que os dados estão disponíveis. Assim, os sistemas são mais propensos a empurrar modelos do que puxar ou pesquisar. Esse recurso permite que você não desperdice recursos consultando e aguardando dados constantemente.
A figura mostra o processo de distribuição de uma mensagem aos consumidores inscritos em um tópico específico.
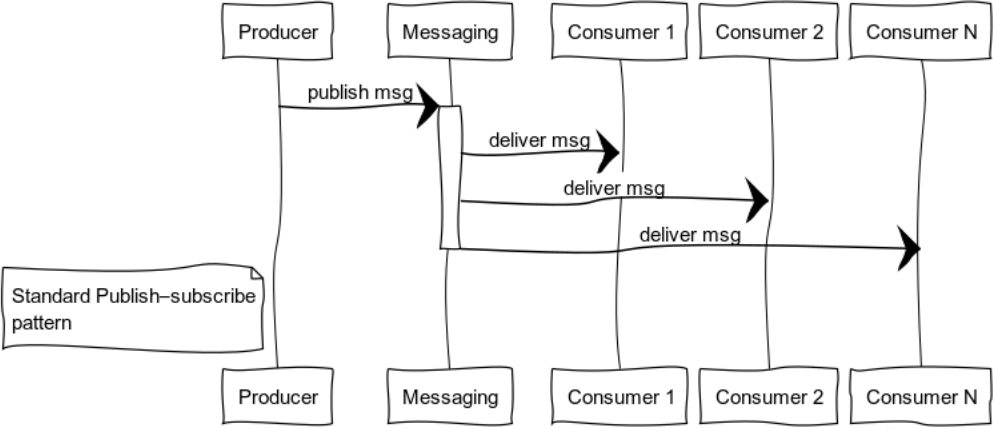
Exemplos clássicos do uso desse modelo são a distribuição do estado: o mundo dos jogos em jogos de computador, dados de mercado em trocas, informações úteis em feeds de dados.
Considere o código do assinante:
init(_Args) ->
A fonte pode chamar a função de publicação posterior em qualquer local conveniente:
messaging:publish_message(Exchange, Key, Message).
Troca - o nome do ponto de troca,
Chave - chave de roteamento
Mensagem - carga útil
Assinatura de publicação invertida
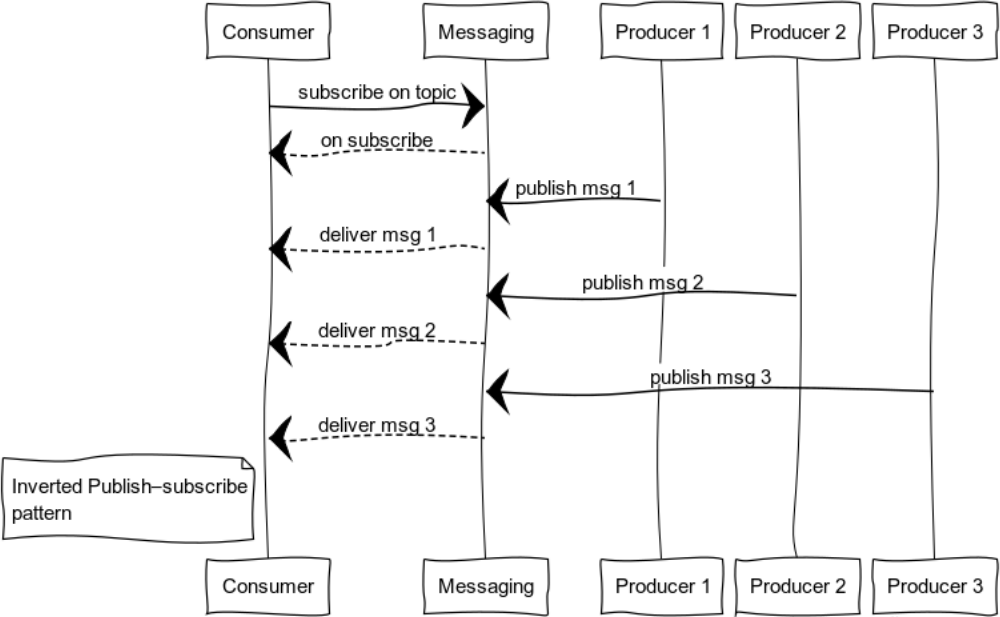
Ao expandir pub-sub, você pode obter um padrão conveniente para o log. O conjunto de fontes e consumidores pode ser completamente diferente. A figura mostra um caso com um consumidor e muitas fontes.
Padrão de distribuição de tarefas
Em quase todos os projetos, surgem tarefas de processamento diferido, como gerar relatórios, entregar notificações, receber dados de sistemas de terceiros. A taxa de transferência de um sistema que executa essas tarefas é facilmente escalável, adicionando manipuladores. Tudo o que resta para nós é formar um cluster de manipuladores e distribuir uniformemente tarefas entre eles.
Considere as situações que surgem com o exemplo de 3 manipuladores. Mesmo no estágio de distribuição de tarefas, surge a questão da imparcialidade da distribuição e do excesso de processadores. A distribuição round-robin será responsável pela justiça e, para evitar uma situação de excesso de manipuladores, introduzimos a restrição prefetch_limit . Nos modos transitórios, o prefetch_limit impedirá que um manipulador receba todas as tarefas.
O sistema de mensagens gerencia filas e prioridade de processamento. Os manipuladores recebem tarefas assim que ficam disponíveis. A tarefa pode ter êxito ou falhar:
messaging:ack(Tack) - chamado em caso de processamento bem-sucedido de mensagensmessaging:nack(Tack) - chamado em todas as situações de emergência. Depois que a tarefa retornar, o sistema de mensagens a transferirá para outro manipulador.
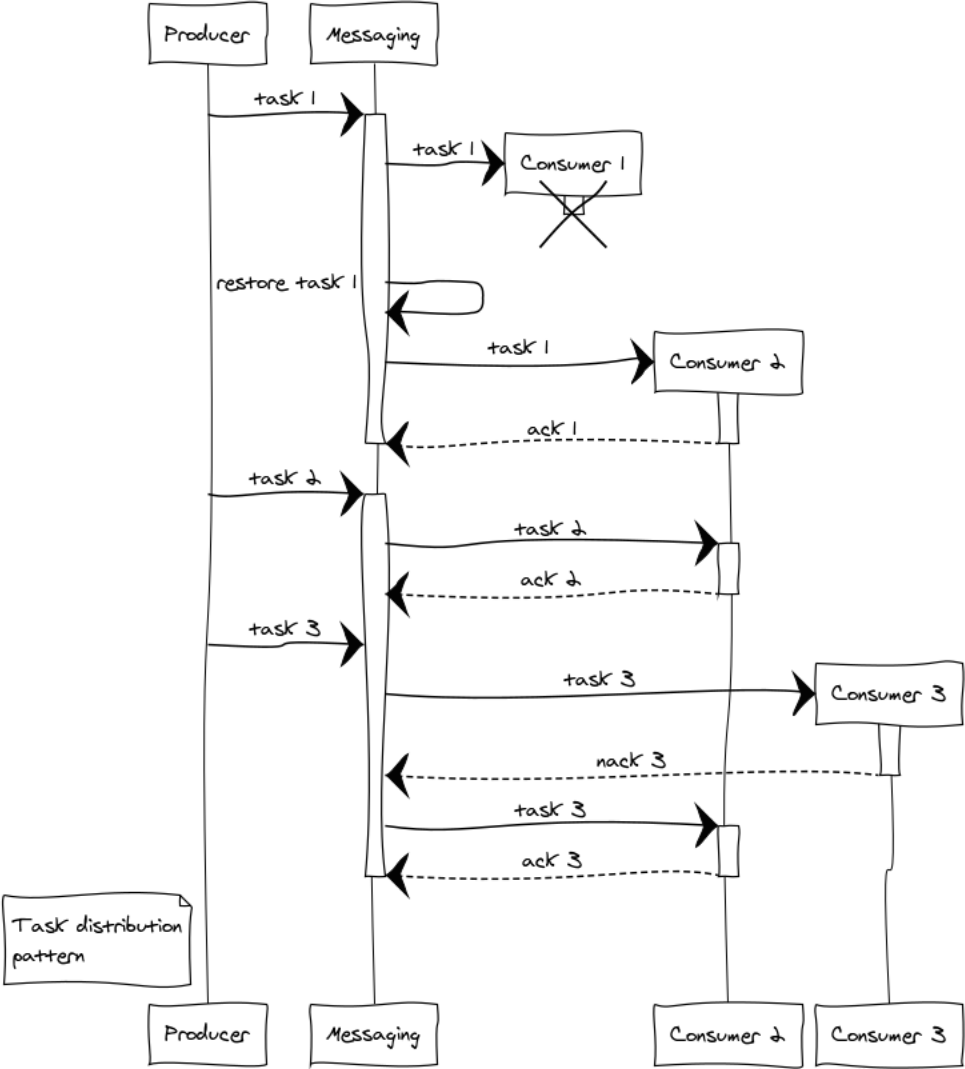
Suponha que ocorreu uma falha complexa durante o processamento de três tarefas: o manipulador 1, depois de receber a tarefa, travou antes que pudesse se comunicar com o ponto de troca. Nesse caso, o ponto de troca após o tempo limite de confirmação expirar transferirá o trabalho para outro manipulador. O manipulador 3, por algum motivo, abandonou a tarefa e enviou nack, como resultado, a tarefa também passou para outro manipulador que a concluiu com êxito.
Resultado preliminar
Separamos os componentes básicos dos sistemas distribuídos e obtivemos um entendimento básico de sua aplicação no Erlang / Elixir.
Ao combinar padrões básicos, você pode criar paradigmas complexos para resolver problemas emergentes.
Na parte final do ciclo, consideraremos as questões gerais da organização de serviços, roteamento e balanceamento, e também falaremos sobre o lado prático da escalabilidade e tolerância a falhas dos sistemas.
O fim da segunda parte.
Foto Marius Christensen
Ilustrações preparadas por websequencediagrams.com