 Postado por Denis Tsyplakov , arquiteto de soluções, DataArt
Postado por Denis Tsyplakov , arquiteto de soluções, DataArtDeclaração do problema
Um dos problemas ao criar arquiteturas de microsserviços e, especialmente, ao migrar uma arquitetura monolítica para microsserviços, geralmente são transações. Cada microsserviço é responsável por seu próprio grupo de funções, possivelmente controla os dados associados a esse grupo e pode atender solicitações de usuários de forma autônoma ou enviando solicitações para outros microsserviços. Tudo isso funciona bem até precisarmos garantir a consistência dos dados controlados por diferentes microsserviços.
Por exemplo, nosso aplicativo funciona em algumas grandes lojas online. Entre outras coisas, temos três áreas de negócios separadas e pouco interconectadas:
- Armazém - o que, onde, como e por quanto tempo está armazenado, quantas mercadorias de um determinado tipo estão atualmente em estoque, etc.
- Envio de mercadorias - embalagem, remessa, rastreamento de entrega, análise de reclamações sobre atraso, etc.
- Realização de relatórios alfandegários sobre a movimentação de mercadorias se as mercadorias forem enviadas para o exterior (na verdade, não sei se, nesse caso, é necessário elaborar algo especialmente, mas ainda assim ligarei os serviços do estado ao processo para adicionar drama).
Cada uma dessas três áreas inclui muitas funções independentes e pode ser representada como vários microsserviços.
Há um problema. Suponha que uma pessoa comprou um produto, empacotou e enviou por correio. Entre outras coisas, precisamos indicar que há menos uma unidade de mercadorias no armazém, para observar que o processo de entrega de mercadorias foi iniciado e se as mercadorias são enviadas, por exemplo, para a China, para cuidar dos papéis da alfândega. Se o aplicativo travar (por exemplo, um nó travar) no segundo ou terceiro estágio do processo, nossos dados chegarão a um estado inconsistente e apenas algumas dessas falhas poderão levar a problemas bastante desagradáveis para os negócios (por exemplo, uma visita dos funcionários da alfândega).
Em uma arquitetura monolítica clássica desse tipo, o problema é simples e elegantemente resolvido por transações no banco de dados. Mas e se usarmos microsserviços? Mesmo se usarmos o mesmo banco de dados de todos os serviços (o que não é muito elegante, mas, no nosso caso, é possível), trabalhar com esse banco de dados provém de diferentes processos, e não conseguiremos esticar a transação entre os processos.
Soluções
O problema tem várias soluções:
- Curiosamente, às vezes o problema pode ser ignorado. Se sabemos que uma falha não ocorre mais de uma vez por mês e a eliminação manual das consequências custa dinheiro aceitável para os negócios, você não pode prestar atenção ao problema, por mais feio que seja. Não sei se é possível ignorar as reivindicações do serviço aduaneiro, mas pode-se presumir que, mesmo sob certas circunstâncias, isso é possível.
- Compensação (não se trata de compensação monetária para a alfândega, por exemplo, você pagou uma multa) é um grupo de várias etapas que complicam a sequência de processamento, mas permitem detectar e processar um processo com falha. Por exemplo, antes de iniciar a operação, escrevemos para um serviço especial que estamos iniciando a operação de remessa e, no final, marcamos que tudo terminou bem. Em seguida, verificamos periodicamente se existem operações pendentes e, se houver, observando os três bancos de dados, tentamos levar os dados a um estado consistente. Este é um método completamente funcional, mas complica significativamente a lógica de processamento, e fazer isso para cada operação é bastante doloroso.
- Transações de duas fases, estritamente falando, a especificação XA +, que permite criar transações distribuídas em relação a aplicativos, é um mecanismo muito pesado que poucas pessoas gostam e, mais importante, poucas pessoas podem configurar. Além disso, com microsserviços leves, é ideologicamente fracamente compatível.
- Em princípio, uma transação é um caso especial do problema de consenso, e vários sistemas de consenso distribuídos podem ser usados para resolver o problema (grosso modo, tudo o que é google com as palavras-chave paxos, jangada, tratador, etcd, consul). Mas, na aplicação prática de dados extensos e ramificados da atividade do armazém, tudo isso parece ainda mais complicado do que transações em duas fases.
- Filas e eventual consistência (consistência a longo prazo) - dividimos a tarefa em três tarefas assíncronas, processamos os dados sequencialmente, passando-os entre os serviços da fila para a fila e usamos o mecanismo de confirmação de entrega. Nesse caso, o código não é muito complicado, mas há alguns pontos a serem lembrados:
- A fila garante a entrega "uma ou mais vezes", ou seja, ao entregar a mesma mensagem, o serviço deve lidar corretamente com essa situação e não enviar as mercadorias duas vezes. Isso pode ser feito, por exemplo, através do UUID exclusivo do pedido.
- Os dados a qualquer momento serão ligeiramente inconsistentes. Ou seja, as mercadorias desaparecerão primeiro do depósito e somente com um pequeno atraso será criado um pedido para enviá-lo. Mais tarde, os dados aduaneiros serão processados. Em nosso exemplo, isso é completamente normal e não causa problemas para os negócios, mas há casos em que esse comportamento de dados pode ser muito desagradável.
- Se, como resultado, o primeiro serviço precisar retornar alguns dados ao usuário, a sequência de chamadas que finalmente entrega os dados ao navegador do usuário poderá ser bastante trivial. O principal problema é que o navegador envia solicitações de forma síncrona e geralmente espera uma resposta síncrona. Se você executar o processamento de solicitações assíncronas, precisará criar entrega assíncrona da resposta para o navegador. Classicamente, isso é feito por meio de soquetes da web ou por solicitações periódicas de novos eventos do navegador para o servidor. Existem mecanismos, como o SocksJS, por exemplo, que simplificam alguns aspectos da construção desse link, mas ainda haverá complexidade adicional.
Na maioria dos casos, a última opção é mais aceitável. Isso não complica muito a solicitação de processamento, embora funcione várias vezes mais, mas, como regra, isso é aceitável para esse tipo de operação. Também requer uma organização de dados um pouco mais complexa para eliminar solicitações repetidas, mas também não há nada de super complicado.
Esquematicamente, uma das opções para processar transações usando filas e consistência Eventual pode ser assim:
- O usuário fez uma compra, uma mensagem sobre isso é enviada para a fila (por exemplo, um cluster RabbitMQ ou, se trabalharmos no Google Cloud Platform - Pub / Sub). A fila é persistente, garante a entrega uma ou mais vezes e é transacional, ou seja, se o serviço que processa a mensagem cair repentinamente, a mensagem não será perdida, mas será entregue para uma nova instância do serviço novamente.
- A mensagem chega ao serviço, que marca as mercadorias no armazém como sendo preparadas para envio e, por sua vez, envia a mensagem "As mercadorias estão prontas para envio" para a fila.
- Na próxima etapa, o serviço responsável pela expedição recebe uma mensagem sobre a disponibilidade para expedição, cria uma tarefa de expedição e envia a mensagem "a expedição da mercadoria está planejada".
- O próximo serviço, depois de receber a mensagem de que o despacho está planejado, inicia o processo de documentação para alfândega.
Além disso, cada mensagem recebida pelo serviço é verificada quanto à exclusividade e, se uma mensagem com esse UUID já tiver sido processada, ela será ignorada.
Aqui, a (s) base (s) do banco de dados em cada momento está em um estado ligeiramente inconsistente, ou seja, as mercadorias no armazém já estão marcadas como estando no processo de entrega, mas a tarefa de entrega em si ainda não está lá, aparecerá em um ou dois segundos. Mas, ao mesmo tempo, temos 99,999% (na verdade, esse número é igual ao nível de confiabilidade do serviço de fila) garante que a tarefa de envio será exibida. Para a maioria das empresas, isso é aceitável.
Qual é o artigo então?
No artigo, quero falar sobre outra maneira de resolver o problema da transacionalidade em aplicativos de microsserviço. Apesar de os microsserviços funcionarem melhor quando cada serviço possui seu próprio banco de dados, para sistemas pequenos e médios, todos os dados, como regra, se encaixam facilmente em um banco de dados relacional moderno. Isso é verdade para quase qualquer sistema corporativo interno. Ou seja, geralmente não temos uma necessidade estrita de compartilhar dados entre diferentes máquinas físicas. Podemos armazenar dados de diferentes microsserviços em grupos não relacionados de tabelas do mesmo banco de dados. Isso é especialmente conveniente se você estiver dividindo um aplicativo antigo e monolítico em serviços e já tiver dividido o código, mas os dados ainda estiverem no mesmo banco de dados. No entanto, o problema da divisão de transações ainda permanece - a transação está rigidamente ligada à conexão de rede e, consequentemente, ao processo que abriu essa conexão, e temos processos separados. Como ser
Acima, descrevi várias maneiras comuns de resolver o problema, mas quero oferecer outra maneira para um caso especial, quando todos os dados estiverem no mesmo banco de dados.
Não recomendo tentar implementar esse método
neste projeto , mas é curioso o suficiente para eu
apresentá- lo no artigo. Bem, de repente, será útil em algum caso especial.
Sua essência é muito simples. Uma transação está associada a uma conexão de rede, e o banco de dados realmente não sabe quem está sentado nessa extremidade da conexão de rede aberta. Ela não se importa, o principal é que os comandos corretos sejam enviados ao soquete. É claro que geralmente um soquete pertence exclusivamente a um processo no lado do cliente, mas vejo pelo menos três maneiras de contornar isso.
1. Altere o código do banco de dados
No nível do código do banco de dados para bancos de dados, cujo código podemos alterar, criando nosso próprio conjunto de banco de dados, implementamos o mecanismo de transferência de transações entre conexões. Como isso pode funcionar do ponto de vista do cliente:
- Começamos a transação, fazemos algumas alterações, é hora de transferir a transação para o próximo serviço.
- Dizemos ao banco de dados que nos forneça o UUID da transação e aguarde N segundos. Se durante esse período não houver outra conexão com este UUID, reverta a transação; caso isso ocorra, transfira todas as estruturas de dados associadas à transação para a nova conexão e continue trabalhando com ela.
- Passamos o UUID para o próximo serviço (ou seja, para outro processo, possivelmente para outra VM).
- Nele, abra uma conexão e dê o comando DB - continue a transação com o UUID especificado.
- Continuamos trabalhando com o banco de dados como parte de uma transação iniciada por outro processo.
Esse método é o mais leve a ser usado, mas requer modificação do código do banco de dados; os programadores de aplicativos geralmente não fazem isso; são necessárias muitas habilidades especiais. Provavelmente, será necessário transferir dados entre os processos do banco de dados e os bancos de dados, cujo código podemos alterar com segurança em geral, um - PostgreSQL. Além disso, isso funcionará apenas para servidores não gerenciados; você não o utilizará no RDS ou no Cloud SQL.
Esquematicamente, fica assim:

2. Manipulação de tomadas
A segunda coisa que vem à mente é a manipulação sutil de conexões de banco de dados por soquetes. Podemos criar um "proxy de soquete reverso", que direciona os comandos provenientes de vários clientes para uma porta específica em um fluxo de comando no banco de dados.
De fato, esse aplicativo é muito semelhante ao pgBouncer, apenas, além de sua funcionalidade padrão, fazendo algumas manipulações com o fluxo de bytes dos clientes e podendo substituir um cliente em vez de outro sob comando.
Não gosto muito desse método, para sua implementação é necessário limpar os pacotes binários que circulam entre o servidor e os clientes. E ainda requer muita programação do sistema. Trouxe-o unicamente por ser completo.
3. Gateway JDBC
Podemos criar um driver JDBC de gateway - tomamos o driver JDBC padrão para um banco de dados específico, seja PostgreSQL. Nós agrupamos a classe e criamos interfaces HTTP para todos os seus métodos externos (não HTTP, mas a diferença é pequena). Em seguida, criamos outro driver JDBC - uma fachada, que redireciona todas as chamadas de método para o gateway JDBC. Na verdade, estamos cortando o driver existente em duas metades e conectando essas metades pela rede. Temos o seguinte diagrama de componentes:
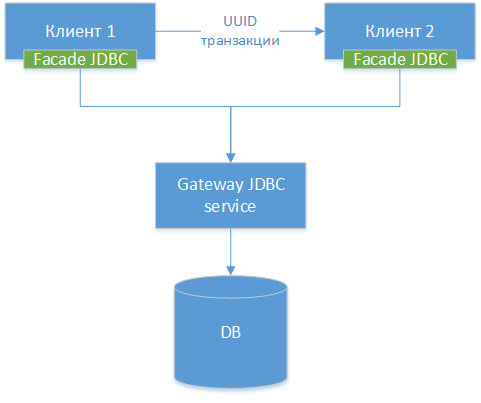 Nota!: Como podemos ver, as três opções são semelhantes, a única diferença é em que nível transferimos a conexão e quais ferramentas usamos para isso.
Nota!: Como podemos ver, as três opções são semelhantes, a única diferença é em que nível transferimos a conexão e quais ferramentas usamos para isso.
Depois disso, ensinamos nosso driver a fazer essencialmente o mesmo truque com a transação UUID descrita no método 1.
No código do aplicativo Java, o uso desse método pode ser assim.
Serviço A - início da transação
Abaixo está o código de algum serviço que inicia uma transação, faz alterações no banco de dados e o passa para outro serviço para concluí-lo. No código, usamos o trabalho direto com classes JDBC. Obviamente, ninguém faz isso em 2019, mas por uma questão de simplicidade, o código é simplificado.
Serviço B - conclusão da transação
Interação com outros componentes e estruturas
Considere os possíveis efeitos colaterais de uma solução arquitetônica desse tipo.
Pool de conexão
Como, na realidade, teremos um pool de conexão real dentro do gateway JDBC - é melhor desativar os pools de conexão nos serviços, pois eles capturam e mantêm uma conexão dentro do serviço que poderia ser usado por outro serviço.
Além disso, após receber o UUID e aguardar a transferência para outro processo, a conexão se torna essencialmente inoperante e, do ponto de vista do JDBC do frontend, fecha automaticamente e, do ponto de vista do JDBC do gateway, deve ser realizada sem dar a ninguém que não seja quem virá com o UUID desejado.
Em outras palavras, o gerenciamento duplo do conjunto de conexões no Gateway JDBC e em cada um dos serviços pode produzir erros sutis e desagradáveis.
Jpa
Com o JPA, vejo dois problemas possíveis:
- Gerenciamento de transações. Ao confirmar uma JPA, o mecanismo pode pensar que salvou todos os dados, enquanto não foi salvo. Provavelmente, o gerenciamento manual de transações e o flush () antes de transferir a transação devem resolver o problema.
- É provável que o cache de segundo nível funcione incorretamente, mas em sistemas distribuídos seu uso é limitado em qualquer caso.
Transações de primavera
O mecanismo de gerenciamento de transações Spring, talvez, não possa ser ativado e você precisará gerenciá-los manualmente. Tenho quase certeza de que ele pode ser expandido (por exemplo, para escrever um escopo personalizado), mas para ter certeza, precisamos estudar como a extensão de transações da primavera está organizada lá, mas ainda não a procurei.
Prós e contras
Prós
- Praticamente não requer modificação do código monolítico existente ao serrar.
- Você pode escrever transações complexas entre servidores sem praticamente nenhuma complexidade de código.
- Permite fazer o rastreamento entre serviços da execução da transação.
- A solução é bastante flexível, você pode usar transações clássicas em que a distribuição não é necessária e compartilhar a transação apenas nas operações em que a interação entre serviços é necessária.
- A equipe do projeto não é obrigada a dominar forçosamente as novas tecnologias. As novas tecnologias são, obviamente, boas, mas a tarefa - é imperativa e urgente (até ontem!) Ensinar a 20 desenvolvedores o conceito de construção de sistemas reativos - pode ser muito trivial. No entanto, não há garantia de que todas as 20 pessoas concluam o treinamento a tempo.
Contras
- Não escalonável e, de fato, não modular no nível do banco de dados, em contraste com uma solução em fila. Você ainda tem um banco de dados no qual todas as consultas e toda a carga convergem. Nesse sentido, a solução é sem saída: se você desejar aumentar a carga posteriormente ou tornar a solução modular de acordo com os dados, precisará refazer tudo.
- Você deve ter muito cuidado ao transferir uma transação entre processos, especialmente processos escritos em estruturas. As sessões têm suas próprias configurações e, para várias estruturas, uma mudança repentina na conexão com o banco de dados pode levar à operação incorreta. Veja, por exemplo, configurações de sessão e transações para o PostgreSQL.
- Quando contei a idéia no bate-papo de nosso arquiteto local sobre DataArt, a primeira coisa que meus colegas me perguntaram foi se eu estava bebendo (não, não estou bebendo!). Mas admito que a idéia, digamos, não é a mais comum, e se você a implementar em seu projeto, parecerá muito incomum para os outros participantes.
- Requer um driver JDBC customizado. Escrever leva tempo, você precisa depurá-lo, procurar erros, incluindo aqueles causados por erros de comunicação na rede, etc.
Advertência
Eu os aviso mais uma vez:
não tente repetir esse truque em casa neste projeto, a menos que você tenha uma explicação muito clara do porquê você precisa dele e evidências convincentes de que não há outra maneira.
Tudo desde o primeiro de abril!