O artigo é publicado em nome de John Akhaltsev , Jiga
Hoje, o Tinkoff.ru não é apenas um banco, é uma empresa de TI. Ele fornece não apenas serviços bancários, mas também cria um ecossistema em torno deles.
Na Tinkoff.ru, firmamos parceria com vários serviços para melhorar a qualidade do serviço ao cliente e ajudar a tornar-se melhores serviços. Por exemplo, realizamos testes de carga e análise de desempenho de um desses serviços que ajudaram a encontrar gargalos no sistema - incluímos Transparent Huge Pages na configuração do sistema operacional.
Se você quiser saber como conduzir uma análise do desempenho do sistema e o que veio dele conosco, seja bem-vindo ao gato.
Descrição do problema
No momento, a arquitetura de serviço é:
- Servidor web Nginx para lidar com conexões http
- Php-fpm para controle de processos php
- Redis para armazenamento em cache
- PostgreSQL para armazenamento de dados
- Solução completa de compras
O principal problema que encontramos durante a próxima venda sob alta carga foi a alta utilização da CPU, enquanto o tempo do processador no modo kernel (hora do sistema) aumentou e foi maior que o tempo no modo usuário (hora do usuário).
- Tempo do usuário - o tempo que o processador gasta nas tarefas do usuário. Esta é a principal coisa pela qual você paga ao comprar um processador.
- Hora do sistema - a quantidade de tempo que o sistema gasta em paginação, alteração de contextos, inicialização de tarefas agendadas e outras tarefas do sistema.
Determinação das características primárias do sistema
Para começar, coletamos um circuito de carga com recursos quase produtivos e compilamos um perfil de carga correspondente a uma carga normal em um dia típico.
A versão 3 do Gatling foi escolhida como ferramenta de bombardeio, e o bombardeio foi realizado dentro da rede local via gitlab-runner. A localização de agentes e destinos na mesma rede local deve-se à redução dos custos da rede, portanto, nos concentramos em verificar a execução do próprio código, e não no desempenho da infraestrutura em que o sistema está implantado.
Ao determinar as características principais do sistema, é adequado um cenário com uma carga crescente linear com uma configuração http:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
Nesta fase, implementamos um script para abrir a página principal e baixar todos os recursos

Os resultados deste teste mostraram um desempenho máximo de 1.500 rps, um aumento adicional na intensidade da carga levou à degradação do sistema associada ao aumento do tempo de operação.


Softirq é um mecanismo de interrupção atrasada e é descrito no arquivo kernel / softirq.s. Ao mesmo tempo, eles martelam a fila de instruções para o processador, impedindo-os de fazer cálculos úteis no modo de usuário. Os manipuladores de interrupção também podem atrasar o trabalho adicional com pacotes de rede em threads do SO (hora do sistema). Brevemente sobre o trabalho da pilha de rede e otimizações podem ser encontradas em um artigo separado .
A suspeita do problema principal não foi confirmada, porque havia um tempo de sistema muito maior no produto com menos atividade de rede.
Scripts de usuário
O próximo passo foi desenvolver scripts personalizados e adicionar algo mais do que apenas abrir uma página com imagens. O perfil inclui operações pesadas, que envolveram totalmente o código do site e o banco de dados, e não um servidor Web que fornece recursos estáticos.
O teste com carga estável foi iniciado com uma intensidade mais baixa do máximo, uma transição de redirecionamento foi adicionada à configuração:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
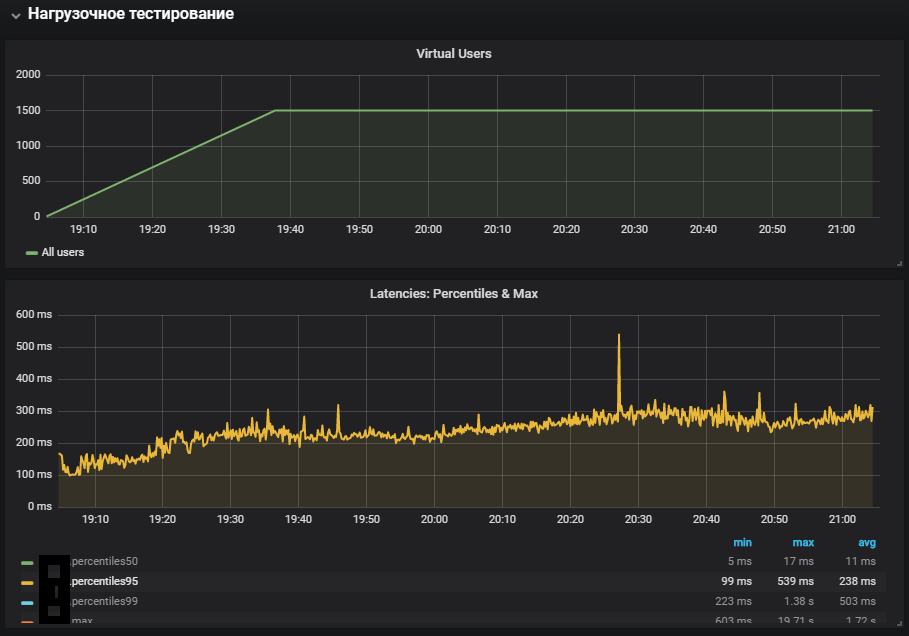

O uso mais completo dos sistemas mostrou um aumento na métrica de tempo do sistema, bem como seu crescimento durante o teste de estabilidade. O problema com o ambiente de produção foi reproduzido.
Rede com Redis
Ao analisar problemas, é muito importante monitorar todos os componentes do sistema para entender como ele funciona e qual o impacto da carga fornecida sobre ele.
Com o advento do monitoramento Redis, tornou-se possível observar não as métricas gerais do sistema, mas seus componentes específicos. O cenário para teste de estresse também foi alterado, o que, juntamente com o monitoramento adicional, ajudou a abordar a localização do problema.

No monitoramento, Redis viu uma imagem semelhante com a utilização da CPU, ou melhor, o tempo do sistema é significativamente maior que o tempo do usuário, enquanto a principal utilização da CPU estava na operação SET, ou seja, na alocação de RAM para armazenar o valor.

Para eliminar o efeito da interação de rede com o Redis, foi decidido testar a hipótese e alternar o Redis para um soquete UNIX em vez de um soquete tcp. Isso foi feito exatamente na estrutura pela qual o php-fpm se conecta ao banco de dados. No arquivo /yiisoft/yii/framework/caching/CRedisCache.php, substituímos a linha do host: port pelo código rígido redis.sock. Leia mais sobre o desempenho do soquete no artigo .
protected function connect() { $this->_socket=@stream_socket_client(
Infelizmente, isso não teve muito efeito. A utilização da CPU estabilizou um pouco, mas não resolveu o nosso problema - a maior parte da utilização da CPU foi na computação no modo kernel.
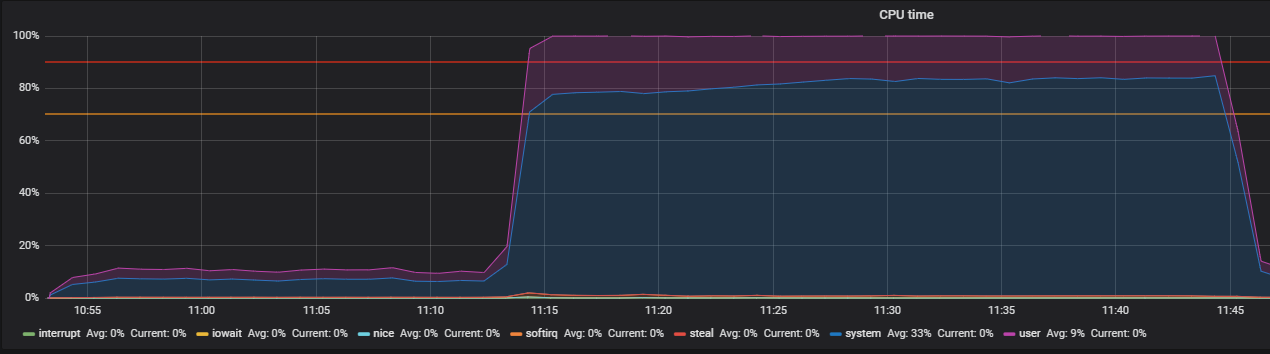
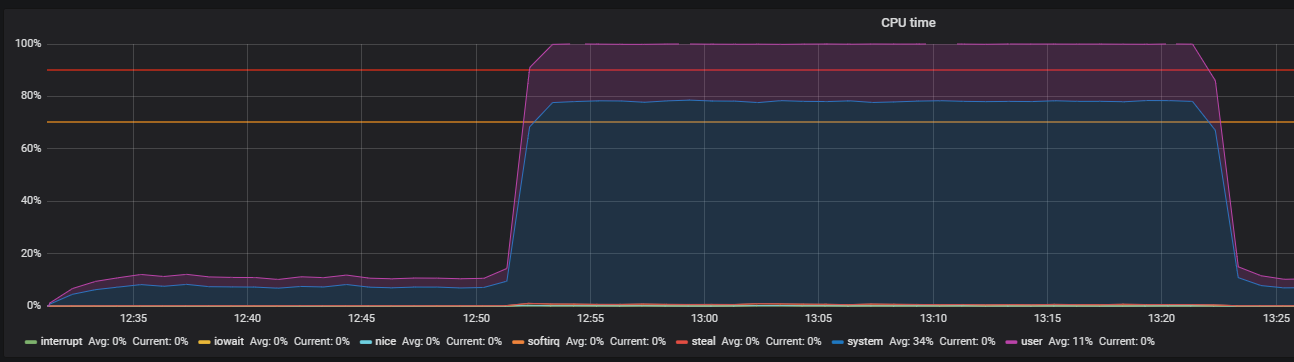
Referência usando estresse e identificando problemas de THP
O utilitário de estresse ajudou a localizar o problema - um simples gerador de carga de trabalho para sistemas POSIX, que pode carregar componentes individuais do sistema, por exemplo, CPU, Memória, E / S.
O teste é suposto na versão do hardware e do sistema operacional:
Ubuntu 18.04.1 LTS
12 CPU Intel® Xeon®
O utilitário é instalado usando o comando:
sudo apt-get install stress
Examinamos como a CPU é utilizada sob carga e executamos um teste que cria trabalhadores para o cálculo de raízes quadradas com duração de 300 segundos:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
O gráfico mostra a utilização completa no modo de usuário - isso significa que todos os núcleos do processador são carregados e cálculos úteis são executados, não as chamadas de serviço do sistema.
O próximo passo é usar recursos ao trabalhar intensivamente com o io. Execute o teste por 300 segundos com a criação de 12 trabalhadores que executam sync (). O comando sync grava dados armazenados em buffer na memória no disco. O kernel armazena dados na memória para evitar operações frequentes (geralmente lentas) de leitura e gravação em disco. O comando sync () garante que tudo o que está armazenado na memória seja gravado no disco.
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd
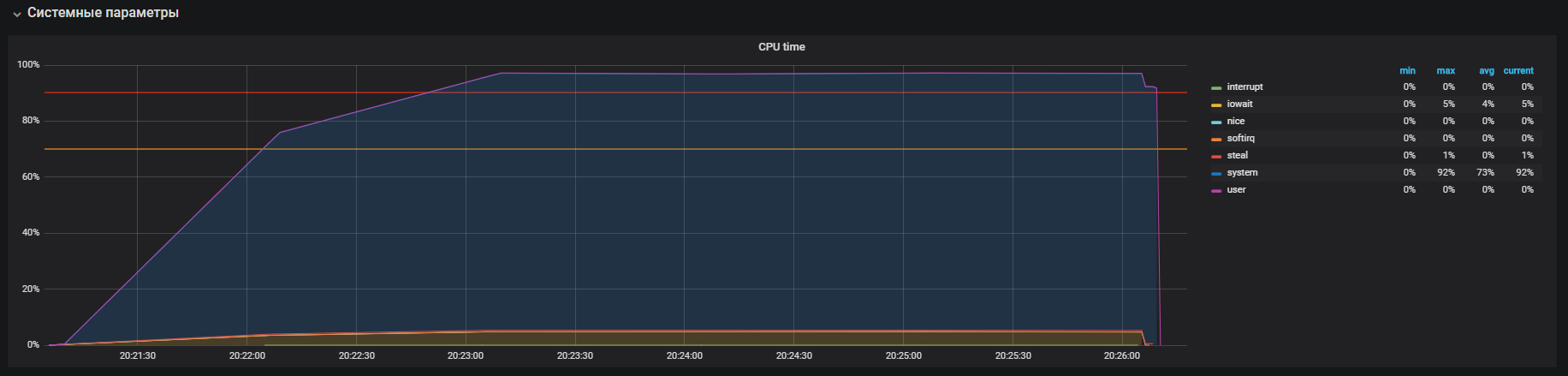

Vimos que o processador está envolvido principalmente no processamento de chamadas no modo kernel e um pouco no iowait. Você também pode ver> 35k ops gravações no disco. Esse comportamento é semelhante a um problema com tempo alto do sistema, cujas causas estamos analisando. Mas aqui existem várias diferenças: estas são iowait e iops são maiores do que no circuito produtivo, respectivamente, isso não se encaixa no nosso caso.
É hora de verificar sua memória. Lançamos 20 trabalhadores que alocam e liberam memória por 300 segundos usando o comando:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
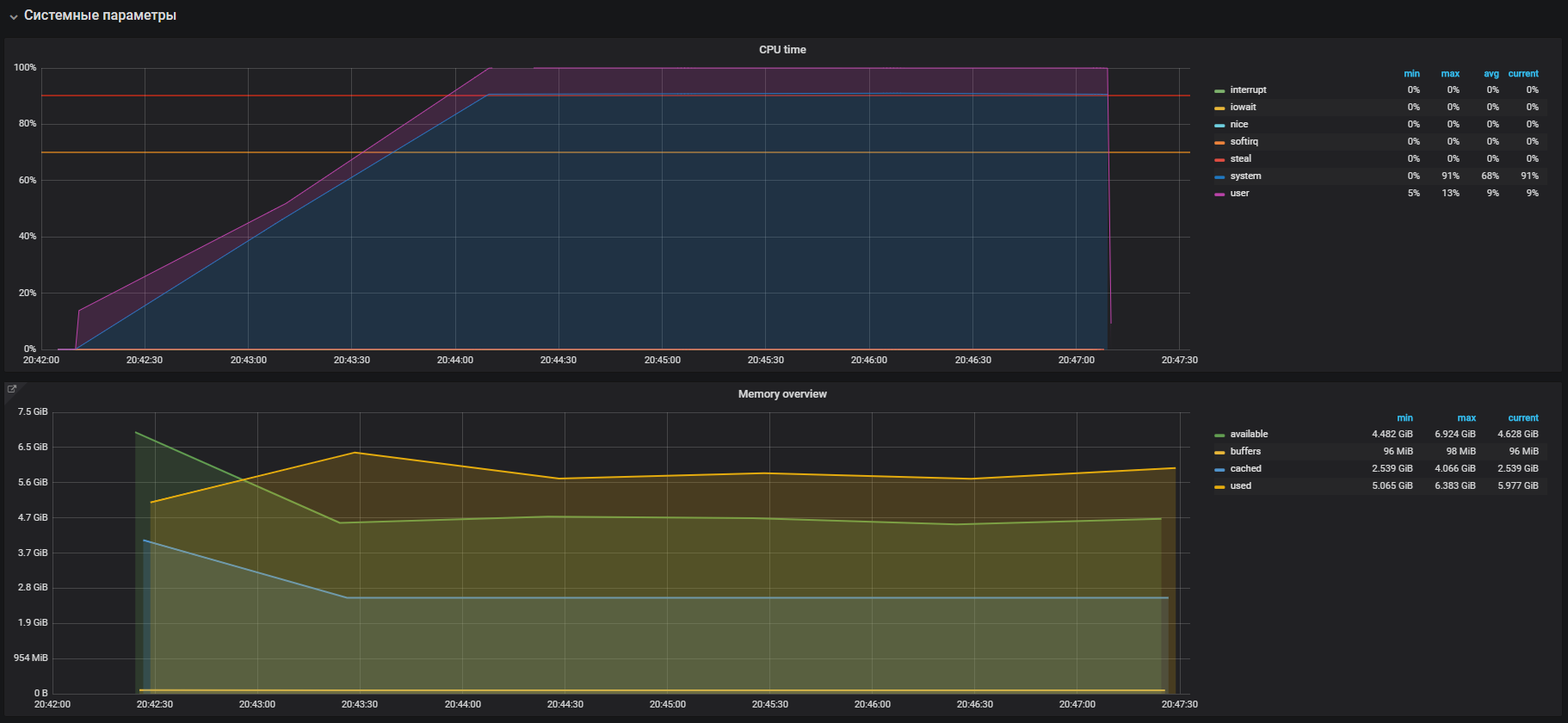
Imediatamente vemos a alta utilização da CPU no modo sistema e um pouco no modo usuário, além do uso de RAM com mais de 2 GB.
Este caso é muito semelhante ao problema com o prod, confirmado pelo grande uso de memória nos testes de carga. Portanto, o problema deve ser procurado na operação de memória. A alocação e liberação de memória ocorrem usando chamadas malloc e chamadas gratuitas, respectivamente, que serão processadas pelas chamadas do sistema do kernel, o que significa que elas serão exibidas na utilização da CPU como hora do sistema.
Na maioria dos sistemas operacionais modernos, a memória virtual é organizada usando paginação, com essa abordagem, toda a área da memória é dividida em páginas de comprimento fixo, por exemplo, 4096 bytes (padrão para muitas plataformas) e, ao alocar, por exemplo, 2 GB de memória, o gerenciador de memória terá que operar mais de 500.000 páginas. Nesta abordagem, existem grandes despesas gerais de gerenciamento e as tecnologias Páginas Enormes e Páginas Enormes Transparentes foram inventadas para reduzi-las. Com sua ajuda, você pode aumentar o tamanho da página, por exemplo, para 2 MB, o que reduzirá significativamente o número de páginas no heap de memória. A diferença tecnológica é apenas que, para páginas Enormes, precisamos configurar explicitamente o ambiente e ensinar o programa a trabalhar com elas, enquanto as Páginas Enormes Transparentes funcionam "de forma transparente" para os programas.
THP e resolução de problemas
Se você pesquisar no Google informações sobre páginas grandes e transparentes, poderá ver nos resultados da pesquisa várias páginas com as perguntas "Como desativar o THP".
Como se viu, esse recurso "legal" foi introduzido pela corporação Red Hat no kernel do Linux, a essência do recurso é que os aplicativos podem funcionar de forma transparente com a memória, como se trabalhassem com a Huge Page real. De acordo com os benchmarks, o THP acelera o aplicativo abstrato em 10%, você pode ver mais detalhes na apresentação, mas, na realidade, tudo é diferente. Em alguns casos, o THP causa um aumento não razoável no consumo de CPU nos sistemas. Para mais informações, consulte as recomendações da Oracle.
Vamos verificar nosso parâmetro. Como se viu, o THP está ativado por padrão, nós o desativamos com o comando:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
Confirmamos com o teste antes de desligar o THP e depois, no perfil de carga:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

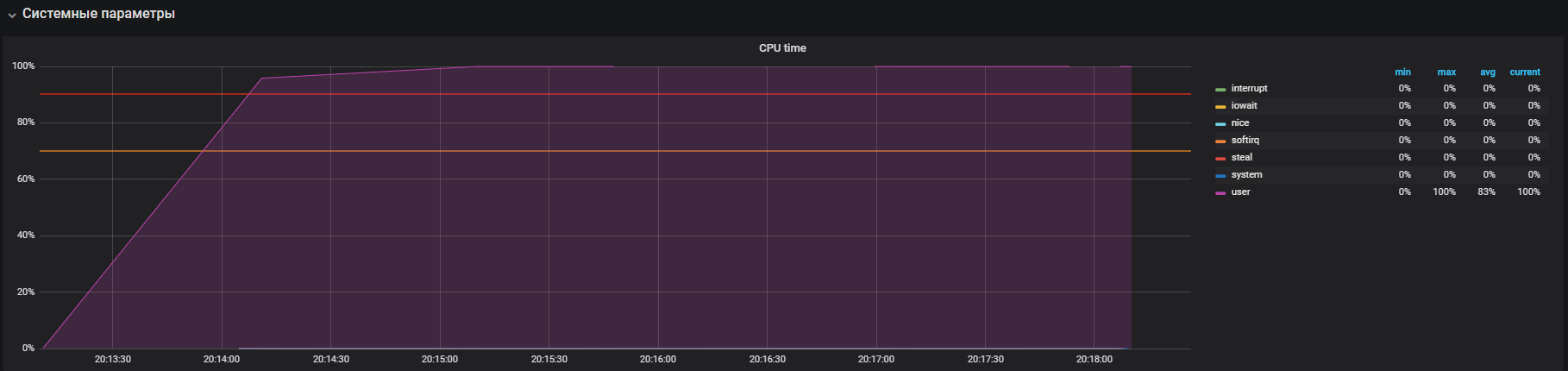
Vimos essa foto antes de desligar o THP

Depois de desativar o THP, podemos observar a utilização de recursos já reduzida.
O principal problema foi localizado. O motivo foi ativado por padrão no sistema operacional
mecanismo de páginas grandes e transparentes. Depois de desativar a opção THP, a utilização da CPU no modo de sistema diminuiu pelo menos 2 vezes, o que liberou recursos para o modo de usuário. Durante a análise do problema principal, também foram encontrados “gargalos” de interação com a pilha de rede do SO e Redis, razão pela qual um estudo mais aprofundado. Mas esta é uma história completamente diferente.
Conclusão
Concluindo, gostaria de dar algumas dicas para procurar com êxito problemas de desempenho:
- Antes de pesquisar o desempenho do sistema, entenda cuidadosamente sua arquitetura e interações com os componentes.
- Configure o monitoramento para todos os componentes do sistema e rastreie, se não houver métricas padrão suficientes, vá mais fundo e expanda.
- Leia os manuais sobre os sistemas usados.
- Verifique as configurações padrão nos arquivos de configuração do SO e dos componentes do sistema.