Anúncio
Colegas, no meio do verão, planejo lançar outra série de artigos sobre o design de sistemas de filas: “VTrade Experiment” - uma tentativa de escrever uma estrutura para sistemas de negociação. O ciclo analisará a teoria e a prática de construção de uma troca, leilão e loja. No final do artigo, proponho votar nos tópicos que mais lhe interessam.

Este é o artigo final do ciclo de aplicativos reativos distribuídos Erlang / Elixir. No primeiro artigo, você encontra os fundamentos teóricos da arquitetura reativa. O segundo artigo ilustra os padrões e mecanismos básicos para a construção de tais sistemas.
Hoje, levantaremos questões sobre o desenvolvimento da base de código e dos projetos em geral.
Organização de Serviço
Na vida real, ao desenvolver um serviço, você geralmente precisa combinar vários padrões de interação em um controlador. Por exemplo, o serviço de usuários, que resolve as tarefas de gerenciamento de perfis de usuário para um projeto, deve responder a solicitações de solicitação de solicitação e relatar atualizações de perfil por meio de pub-sub. Este caso é bastante simples: por trás das mensagens, há um controlador que implementa a lógica do serviço e publica atualizações.
A situação é complicada quando precisamos implementar um serviço distribuído tolerante a falhas. Suponha que os requisitos dos usuários tenham mudado:
- agora o serviço deve processar solicitações em 5 nós do cluster,
- ser capaz de executar tarefas de processamento em segundo plano,
- e poder gerenciar dinamicamente suas listas de assinaturas de atualização de perfil.
Nota: Não consideramos a questão do armazenamento e replicação consistentes de dados. Suponha que esses problemas tenham sido resolvidos anteriormente e que o sistema já tenha uma camada de armazenamento confiável e escalável, e os manipuladores tenham mecanismos para interagir com ele.
A descrição formal do serviço de usuários tornou-se mais complicada. Do ponto de vista de um programador, o uso de alterações nas mensagens é mínimo. Para satisfazer o primeiro requisito, precisamos ajustar o equilíbrio no ponto de troca req-resp.
O requisito para lidar com tarefas em segundo plano geralmente surge. Nos usuários, isso pode ser verificar documentos do usuário, processar multimídia baixada ou sincronizar dados com serviços sociais. redes. Essas tarefas precisam ser distribuídas de alguma forma no cluster e controlar o progresso. Portanto, temos duas soluções: use o modelo de distribuição de tarefas do artigo anterior ou, se não couber, escreva um agendador de tarefas personalizado que será necessário para gerenciarmos o conjunto de manipuladores.
O ponto 3 requer uma extensão para o modelo pub-sub. E para implementação, depois de criar o ponto de troca pub-sub, precisamos iniciar adicionalmente o controlador desse ponto como parte de nosso serviço. Assim, parecemos levar a lógica do processamento de assinaturas e cancelamentos de assinatura da camada de mensagens para a implementação dos usuários.
Como resultado, a decomposição da tarefa mostrou que, para atender aos requisitos, precisamos executar 5 instâncias de serviço em nós diferentes e criar uma entidade adicional - o controlador pub-sub responsável pela assinatura.
Para executar 5 manipuladores, você não precisa alterar o código de serviço. A única ação adicional é configurar regras de balanceamento no ponto de troca, sobre as quais falaremos mais adiante.
Também havia complexidade adicional: o controlador pub-sub e o planejador de tarefas personalizado devem funcionar em uma única cópia. Novamente, o serviço de mensagens, como fundamental, deve fornecer um mecanismo para selecionar um líder.
Escolha do Líder
Em sistemas distribuídos, a escolha de um líder é o processo de nomear o único processo responsável pelo planejamento do processamento distribuído de uma carga.
Em sistemas que não são propensos à centralização, são utilizados algoritmos de consenso universal, como paxos ou jangada.
Como o sistema de mensagens é um corretor e um elemento central, ele conhece todos os controladores de serviço - candidatos à liderança. As mensagens podem nomear um líder sem voto.
Após iniciar e conectar-se ao ponto de troca, todos os serviços recebem a mensagem do sistema #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} . Se o LeaderPid corresponder ao pid processo atual, ele será atribuído como líder e a lista Servers incluirá todos os nós e seus parâmetros.
Quando um novo nó de cluster aparece e é desconectado, todos os controladores de serviço recebem #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} e #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} respectivamente.
Assim, todos os componentes estão cientes de todas as alterações e no cluster, a qualquer momento, um líder é garantido.
Intermediários
Para a implementação de processos complexos de processamento distribuído, bem como para a otimização de uma arquitetura existente, é conveniente usar intermediários.
Para não alterar o código dos serviços e resolver, por exemplo, as tarefas de processamento adicional, roteamento ou registro de mensagens, você pode ativar um processador proxy antes do serviço, que executará todo o trabalho adicional.
Um exemplo clássico de otimização pub-sub é um aplicativo distribuído com um kernel de negócios que gera eventos de atualização, por exemplo, uma alteração no preço de mercado e uma camada de acesso - servidores N que fornecem APIs de soquete da web para clientes da web.
Se você decidir "testa", o atendimento ao cliente será o seguinte:
- o cliente estabelece conexões com a plataforma. No lado do servidor, encerrando o tráfego, o processo que atende a essa conexão é iniciado.
- No contexto do processo do serviço, ocorre a autorização e a assinatura das atualizações. O processo chama o método de inscrição para tópicos.
- depois que o evento é gerado no kernel, ele é entregue aos processos que atendem às conexões.
Imagine que temos 50.000 assinantes do tópico "notícias". Os assinantes são distribuídos igualmente por 5 servidores. Como resultado, cada atualização, chegando ao ponto de troca, será replicada 50.000 vezes: 10.000 vezes para cada servidor, de acordo com o número de assinantes. Não é um esquema muito eficaz, é?
Para melhorar a situação, introduzimos um proxy com o mesmo nome com o ponto de troca. O registrador global de nomes deve poder retornar o processo mais próximo pelo nome, isso é importante.
Execute esse proxy nos servidores da camada de acesso e todos os nossos processos que atendem à API do soquete da Web se inscreverão nele, e não no ponto de troca pub-sub original no kernel. O proxy assina o kernel apenas no caso de uma assinatura exclusiva e replica a mensagem recebida para todos os seus assinantes.
Como resultado, 5 mensagens serão enviadas entre o kernel e os servidores de acesso, em vez de 50.000.
Roteamento e balanceamento
Req-resp
Na implementação atual do sistema de mensagens, existem 7 estratégias de distribuição de consultas:
default . A solicitação é passada para todos os controladores.round-robin . Repete e distribui ciclicamente solicitações entre controladores.consensus . Os controladores que servem o serviço são divididos em líderes e seguidores. As solicitações são passadas apenas ao líder.consensus & round-robin . Há um líder no grupo, mas os pedidos são distribuídos entre todos os membros.sticky . A função hash é calculada e atribuída a um manipulador específico. Solicitações subsequentes com esta assinatura vão para o mesmo manipulador.sticky-fun . Quando o ponto de troca é inicializado, a função de cálculo de hash para balanceamento de sticky é transferida adicionalmente.fun . É semelhante ao pegajoso, mas além disso, você pode redirecionar, rejeitar ou pré-processá-lo.
A estratégia de distribuição é definida quando o ponto de troca é inicializado.
Além do balanceamento de mensagens, você pode marcar entidades. Considere os tipos de tags no sistema:
- Etiqueta de conexão. Permite que você entenda por qual conexão os eventos vieram. Usado quando o processo do controlador se conecta ao mesmo ponto de troca, mas com chaves de roteamento diferentes.
- Etiqueta de serviço. Permite que um único serviço agrupe processadores e expanda os recursos de roteamento e balanceamento. Para o padrão req-resp, o roteamento é linear. Enviamos uma solicitação ao ponto de troca e depois a envia ao serviço. Porém, se precisarmos dividir os manipuladores em grupos lógicos, a divisão será realizada usando tags. Ao especificar um tag, a solicitação será direcionada para um grupo específico de controladores.
- Solicitar tag. Permite distinguir respostas. Como nosso sistema é assíncrono, para processar respostas de serviço, você deve poder especificar uma RequestTag ao enviar uma solicitação. A partir dele, podemos entender a resposta para a qual o pedido chegou até nós.
Pub sub
Para pub-sub, as coisas são um pouco mais fáceis. Temos um ponto de troca para o qual as mensagens são publicadas. O ponto de troca distribui mensagens entre os assinantes que assinam as chaves de roteamento de que precisam (podemos dizer que isso é análogo a elas).
Escalabilidade e resiliência
A escalabilidade do sistema como um todo depende do grau de escalabilidade das camadas e componentes do sistema:
- Os serviços são dimensionados adicionando nós adicionais ao cluster com manipuladores para este serviço. Durante a operação de teste, você pode escolher a política de balanceamento ideal.
- O próprio serviço de mensagens, em um único cluster, geralmente é escalado movendo pontos de troca especialmente carregados para nós de cluster individuais ou adicionando processos de proxy a zonas especialmente carregadas do cluster.
- A escalabilidade de todo o sistema como uma característica depende da flexibilidade da arquitetura e da possibilidade de combinar clusters individuais em uma entidade lógica comum.
A simplicidade e a velocidade do dimensionamento geralmente determinam o sucesso de um projeto. As mensagens em seu desempenho atual aumentam com o aplicativo. Mesmo se não tivermos um grupo de 50 a 60 carros, podemos recorrer à federação. Infelizmente, o tópico da federação está além do escopo deste artigo.
Reserva
Na análise do balanceamento de carga, já discutimos a reserva de controladores de serviço. No entanto, as mensagens também devem ser reservadas. No caso de uma falha no nó ou na máquina, as mensagens devem se recuperar automaticamente e o mais rápido possível.
Nos meus projetos, uso nós adicionais que captam a carga em caso de queda. Erlang possui uma implementação de modo distribuído padrão para aplicativos OTP. O modo distribuído, de fato, executa a recuperação no caso de uma falha iniciando o aplicativo com falha em outro nó iniciado anteriormente. O processo é transparente, após uma falha, o aplicativo se move automaticamente para o nó de failover. Você pode ler mais sobre esta funcionalidade aqui .
Desempenho
Vamos tentar comparar pelo menos aproximadamente o desempenho do rabbitmq e nossas mensagens personalizadas.
Encontrei os resultados oficiais do teste rabbitmq da equipe openstack.
Na cláusula 6.14.1.2.1.2.2. O documento original apresenta o resultado do RPC CAST:
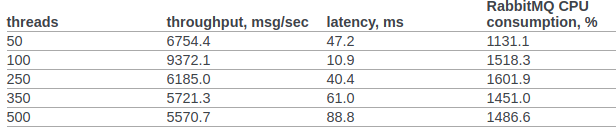
Anteriormente, não faríamos nenhuma configuração adicional no kernel do SO ou na VM erlang. Condições de teste:
- erl opta: + A1 + sbtu.
- O teste em um único nó erlang é executado em um laptop com um i7 antigo em desempenho móvel.
- Os testes de cluster são realizados em servidores com uma rede 10G.
- O código funciona em contêineres de janela de encaixe. Rede no modo NAT.
Código do teste:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok.
Cenário 1: O teste é executado em um laptop com uma execução móvel antiga do i7. Teste, sistema de mensagens e serviço são executados em um nó em um contêiner de docker:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)
Cenário 2 : 3 nós em execução em máquinas diferentes sob a janela de encaixe (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)
Em todos os casos, a utilização da CPU não excedeu 250%
Sumário
Espero que esse ciclo não pareça um despejo de consciência e minha experiência traga benefícios reais tanto para pesquisadores de sistemas distribuídos quanto para profissionais que estão no começo do caminho de construção de arquiteturas distribuídas para seus sistemas de negócios e que olham para Erlang / Elixir com interesse, mas duvidam. vale a pena ...
Foto por @chuttersnap