Algumas empresas, incluindo nosso cliente, desenvolvem o produto por meio de uma rede afiliada. Por exemplo, grandes lojas online são integradas a um serviço de entrega - você solicita mercadorias e logo recebe um número de rastreamento para a encomenda. Outro exemplo - junto com uma passagem aérea, você compra um seguro ou uma passagem Aeroexpress.
Para isso, é usada uma API, que deve ser emitida aos parceiros por meio da API do Gateway. Nós resolvemos esse problema. Este artigo fornecerá detalhes.
Dado: portal do ecossistema e API com uma interface onde os usuários são registrados, recebem informações, etc. Precisamos criar uma API de gateway conveniente e confiável. No processo, precisávamos fornecer
- Registo
- Controle de conexão API
- Monitorando como os usuários usam o sistema final
- contabilidade de indicadores de negócios.
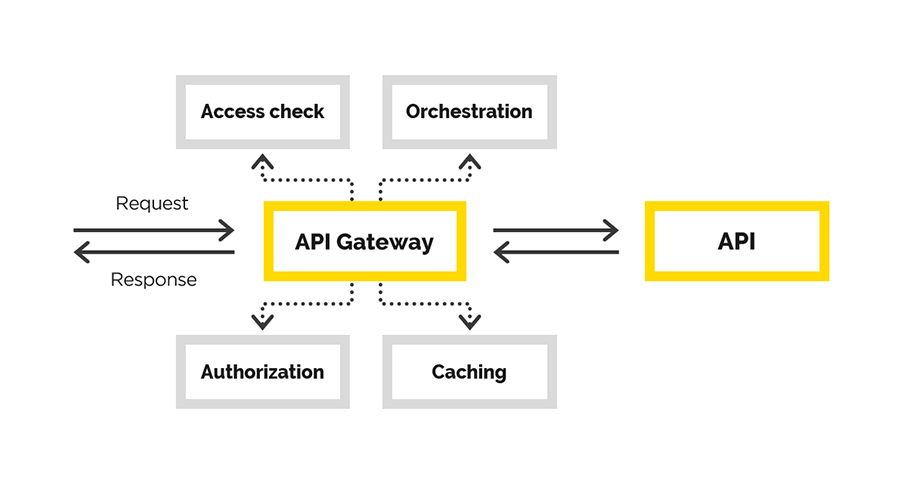
No artigo, falaremos sobre nossa experiência na criação da API do Gateway, durante a qual resolvemos as seguintes tarefas:
- autenticação de usuário
- autorização do usuário
- modificação do pedido original,
- solicitar proxy
- pós-processamento da resposta.
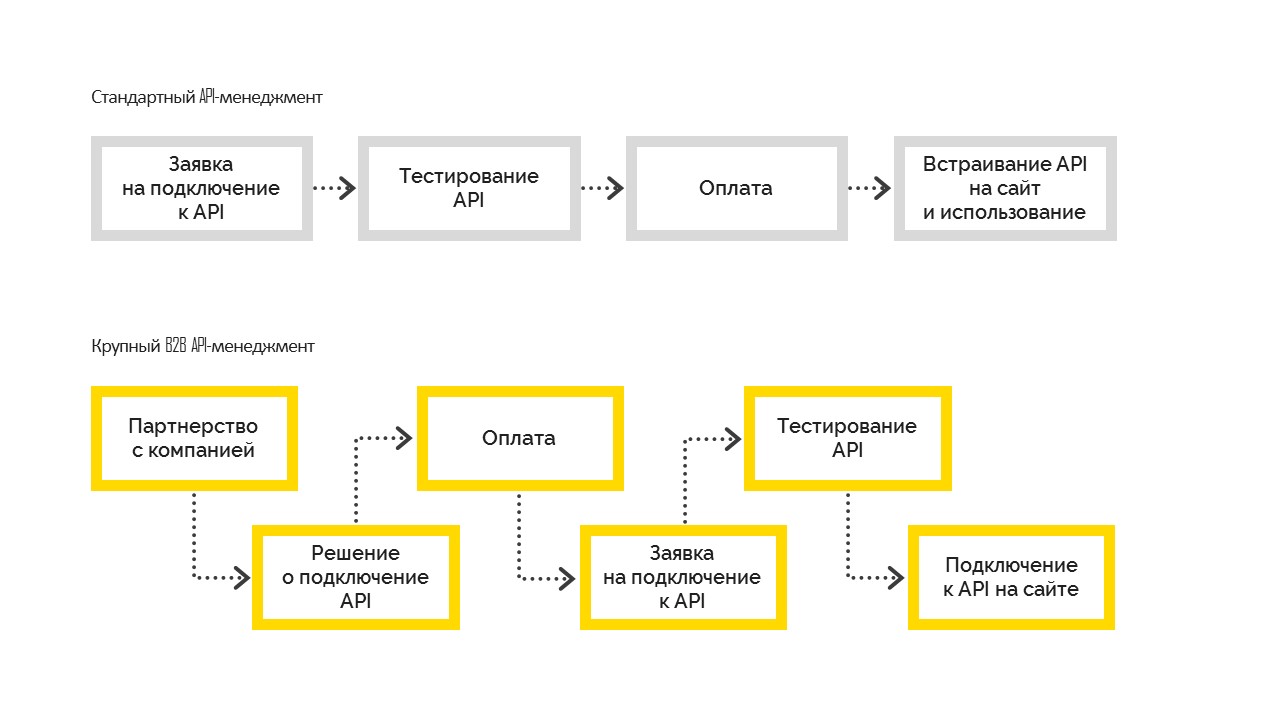
Existem dois tipos de gerenciamento de API:
1. Padrão, que funciona da seguinte maneira. Antes de conectar, o usuário testa as possibilidades, paga e incorpora em seu site. Na maioria das vezes, é usado em pequenas e médias empresas.
2. Um grande gerenciamento de API B2B, quando a empresa toma uma decisão comercial sobre a conexão, torna-se uma empresa parceira com uma obrigação contratual e, em seguida, se conecta à API. E depois de acertar todas as formalidades, a empresa obtém acesso aos testes, passa nos testes e entra nas vendas. Mas isso não é possível sem uma decisão de gerenciamento para se conectar.
Nossa decisão
Nesta parte, falaremos sobre a criação da API do gateway.
Os usuários finais do gateway criado para a API são os parceiros de nossos clientes. Para cada um deles, já temos os contratos necessários. Só precisamos expandir a funcionalidade, observando o acesso concedido ao gateway. Consequentemente, é necessário um processo controlado de conexão e controle.
Obviamente, pode-se usar uma solução pronta para resolver a tarefa de Gerenciamento de API e criar o API Gateway em particular. Por exemplo, esse poderia ser o
Gerenciamento de API do Azure . Não nos convinha, porque no nosso caso já tínhamos um portal de API e um enorme ecossistema construído em torno dele. Todos os usuários já foram registrados, já entenderam onde e como podem obter as informações necessárias. As interfaces necessárias já existiam no portal da API, apenas precisávamos do API Gateway. Na verdade, começamos a desenvolvê-lo.
O que chamamos de API do Gateway é um tipo de proxy. Aqui, novamente, tivemos uma escolha - você pode escrever seu proxy ou escolher algo pronto. Nesse caso, seguimos o segundo caminho e escolhemos o pacote nginx + Lua. Porque Precisávamos de um software confiável e testado que suporte o dimensionamento. Após a implementação, não queremos verificar a correção da lógica de negócios e a correção do proxy.
Qualquer servidor da web possui um pipeline de processamento de solicitações. No caso do nginx, fica assim:

(diagrama do
GitHub Lua Nginx )
Nosso objetivo era integrar esse pipeline no momento em que podemos modificar a solicitação original.
Queremos criar um proxy transparente para que a solicitação permaneça funcional como veio. Controlamos apenas o acesso à API final, ajudamos a solicitação a acessá-la. Caso a solicitação esteja incorreta, a API final deve mostrar o erro, mas não nós. A única razão pela qual podemos rejeitar a solicitação é devido à falta de acesso ao cliente.
Para nginx, uma
extensão já existe em
Lua . Lua é uma linguagem de script, é muito leve e fácil de aprender. Assim, implementamos a lógica necessária usando Lua.
A configuração do nginx (analogia à rota do aplicativo), onde todo o trabalho é realizado, é compreensível. Digno de nota aqui é a última diretiva - post_action.
location /middleware { more_clear_input_headers Accept-Encoding; lua_need_request_body on; rewrite_by_lua_file 'middleware/rewrite.lua'; access_by_lua_file 'middleware/access.lua'; proxy_pass https://someurl.com; body_filter_by_lua_file 'middleware/body_filter.lua'; post_action /process_session; }
Considere o que acontece nesta configuração:
more_clear_input_headers - limpa o valor dos cabeçalhos especificados após a diretiva.
lua_need_request_body - controla se o corpo da solicitação original deve ser lido antes de executar as diretivas reescrever / acesso / acesso_por_lua ou não. Por padrão, o nginx não lê o corpo da solicitação do cliente e, se você precisar acessá-lo, esta diretiva deve estar ativada.
rewrite_by_lua_file - o caminho para os scripts, que descreve a lógica para modificar a solicitação
access_by_lua_file - o caminho para o script, que descreve a lógica que verifica o acesso ao recurso.
proxy_pass - URL para o qual a solicitação será
enviada por proxy.
body_filter_by_lua_file - o caminho para o script, que descreve a lógica para filtrar a solicitação antes de retornar ao cliente.
E, finalmente,
post_action é uma diretiva oficialmente não documentada que pode ser usada para executar qualquer outra ação após a resposta ser dada ao cliente.
A seguir, descreveremos em ordem como resolvemos nossos problemas.
Autorização / autenticação e modificação de solicitação
EntrarCriamos autorização e autenticação usando acessos a certificados. Existe um certificado raiz. Cada novo cliente do cliente gera seu certificado pessoal com o qual ele pode acessar a API. Este certificado está configurado na seção do servidor de configurações do nginx.
ssl on; ssl_certificate /usr/local/openresty/nginx/ssl/cert.pem; ssl_certificate_key /usr/local/openresty/nginx/ssl/cert.pem; ssl_client_certificate /usr/local/openresty/nginx/ssl/ca.crt; ssl_verify_client on;
ModificaçãoUma pergunta justa pode surgir: o que fazer com um cliente certificado, se de repente queremos desconectá-lo do sistema? Não emita novamente certificados para todos os outros clientes.
Então, sem problemas, abordamos a próxima tarefa - modificação da solicitação original. A solicitação original do cliente, de um modo geral, não é válida para o sistema final. Uma das tarefas é adicionar as partes ausentes à solicitação para torná-la válida. O ponto é que os dados ausentes são diferentes para cada cliente. Sabemos que o cliente chega até nós com um certificado a partir do qual podemos obter uma impressão digital e extrair os dados necessários do cliente do banco de dados.
Se em algum momento você precisar desconectar o cliente do nosso serviço, os dados dele desaparecerão do banco de dados e ele não poderá fazer nada.
Trabalhar com dados do cliente
Precisávamos garantir alta disponibilidade da solução, especialmente como obtemos dados do cliente. A dificuldade é que a fonte desses dados é um serviço de terceiros que não garante velocidade ininterrupta e razoavelmente alta.
Portanto, precisávamos garantir alta disponibilidade dos dados do cliente. Como ferramenta, escolhemos o
Hazelcast , que fornece:
- acesso rápido aos dados
- a capacidade de organizar um cluster de vários nós com dados replicados em nós diferentes.
Adotamos a estratégia mais simples de entrega de cache:
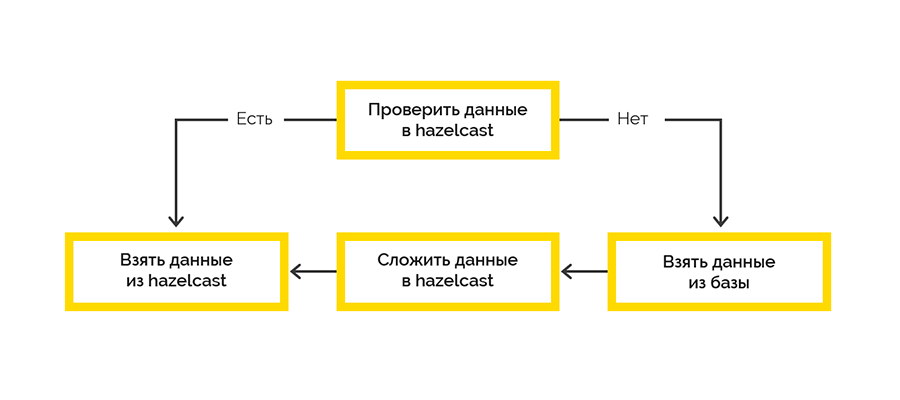
O trabalho com o sistema final ocorre dentro da estrutura das sessões e há um limite no número máximo. Se o cliente não encerrou a sessão, teremos que fazer isso.
Os dados da sessão aberta são provenientes do sistema de destino e são processados inicialmente no lado Lua. Decidimos usar o Hazelcast para salvar esses dados com um gravador .NET. Então, em alguns intervalos, verificamos o direito à vida de sessões abertas e encerramos a falta.
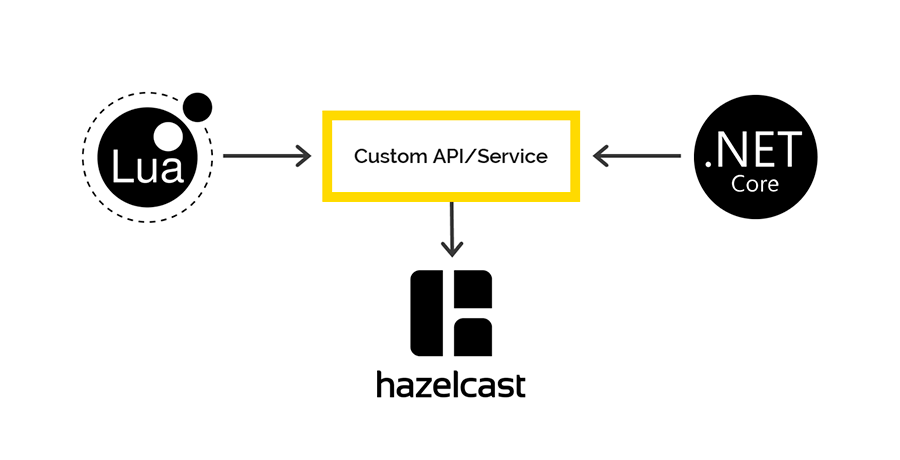
Acesso ao Hazelcast de Lua e .NET
Não há clientes em Lua para trabalhar com o Hazelcast, mas o Hazelcast possui uma API REST, que decidimos usar. Para o .NET, existe um
cliente através do qual planejamos acessar os dados do Hazelcast no lado do .NET. Mas lá estava.

Ao salvar dados via REST e recuperar através do cliente .NET, diferentes serializadores / desserializadores são usados. Portanto, é impossível colocar dados no REST, mas passar pelo cliente .NET e vice-versa.
Se você estiver interessado, falaremos mais sobre esse problema em um artigo separado. Spoiler - no shemka.
Registro e Monitoramento
Nosso padrão corporativo para fazer logon no .NET é Serilog, todos os logs terminam no Elasticsearch e os analisamos no Kibana. Eu queria fazer algo semelhante neste caso. O único
cliente a trabalhar com o Elastic em Lua encontrado foi quebrado na primeira solicitação. E usamos o Fluentd.
Fluentd é uma solução de código aberto para fornecer uma única camada de registro de aplicativo. Permite coletar logs de diferentes camadas do aplicativo e depois convertê-los em uma única fonte.
A API do Gateway funciona no K8S, por isso decidimos adicionar o contêiner com fluentd ao mesmo subtipo para gravar logs na porta tcp aberta existente existente fluentd.
Também examinamos como o fluente se comportaria se ele não tivesse conexão com o Elasticsearch. Por dois dias, as solicitações foram enviadas continuamente ao gateway, os logs foram enviados ao fluentd, mas o IP Elastic foi banido do fluentd. Após a reconexão, o fluentd superou perfeitamente todos os logs do Elastic.
Conclusão
A abordagem escolhida para a implementação nos permitiu entregar um produto realmente funcional ao ambiente de combate em apenas 2,5 meses.
Se alguma vez você fizer essas coisas, recomendamos que você entenda claramente qual problema está resolvendo e quais recursos você já possui. Esteja ciente das complexidades da integração com os sistemas de gerenciamento de API existentes.
Entenda por si mesmo o que exatamente você desenvolverá - apenas a lógica comercial do processamento de solicitações ou, como pode ser o caso no nosso caso, todo o proxy. Lembre-se de que tudo o que você faz deve ser cuidadosamente testado posteriormente.