No campo do desenvolvimento de aplicativos multithread ou distribuídos altamente carregados, geralmente surgem discussões sobre programação assíncrona. Hoje vamos mergulhar na assincronia em detalhes e estudar o que é quando ocorre, como isso afeta o código e a linguagem de programação que usamos. Vamos descobrir por que são necessários futuros e promessas e tocar em corotinas e sistemas operacionais. Isso tornará as trocas que surgem durante o desenvolvimento de software mais explícitas.
O material é baseado na transcrição de um relatório de Ivan Puzyrevsky, professor da Yandex Data Analysis School.

Gravação de vídeo
1. Conteúdo
2. Introdução
Olá pessoal, meu nome é Ivan Puzyrevsky, trabalho para Yandex. Nos últimos seis anos, estive envolvido na infraestrutura de armazenamento e processamento de dados, agora mudei para o produto - em busca de viagens, hotéis e passagens. Desde que trabalhei por muito tempo na infraestrutura, adquiri bastante experiência em como escrever diferentes aplicativos carregados. Nossa infra-estrutura opera 24*7*365 todos os dias sem parar, continuamente em milhares de máquinas. Naturalmente, você precisa escrever um código para que ele funcione de maneira confiável e eficiente e resolva as tarefas que a empresa coloca.
Hoje vamos falar sobre assincronia. O que é assincronia? É uma incompatibilidade de algo com algo no tempo. A partir dessa descrição, geralmente não está claro o que vou falar hoje. Para esclarecer de alguma forma o problema, preciso de um exemplo como "Olá, mundo!". A assincronia geralmente ocorre no contexto de escrever aplicativos de rede, então terei um análogo de rede de "Olá, mundo!". Este é um aplicativo de pingue-pongue. O código fica assim:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Eu crio um soquete, leio uma linha de lá e verifico se é ping, depois escrevo pong em resposta. Muito simples e claro. O que acontece quando você vê esse código na tela do computador? Pensamos nesse código como uma sequência dessas etapas:
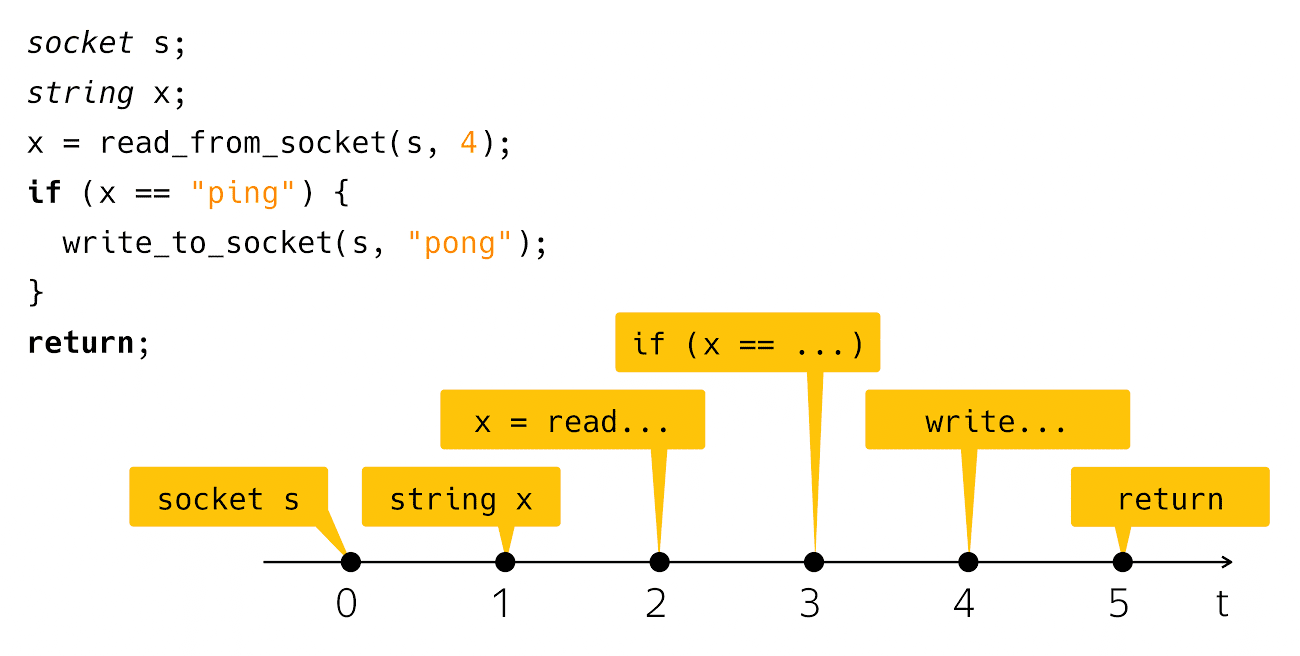
Do ponto de vista do tempo físico real, tudo é um pouco tendencioso.

Aqueles que realmente escreveram e executaram esse código sabem que após a etapa de leitura e após a etapa
write é um intervalo de tempo bastante perceptível quando nosso programa parece não estar fazendo nada do ponto de vista de nosso código, mas, sob o capô, o maquinário opera, que chamamos de "entrada-saída".

Durante a E / S, os pacotes são trocados pela rede e todo o trabalho pesado e de baixo nível. Vamos conduzir um experimento mental: pegue esse programa, execute-o em um processador físico e finja que não temos nenhum sistema operacional, o que acontecerá? O processador não pode parar, continua a tomar medidas sem seguir nenhuma instrução, apenas desperdiçando energia em vão.
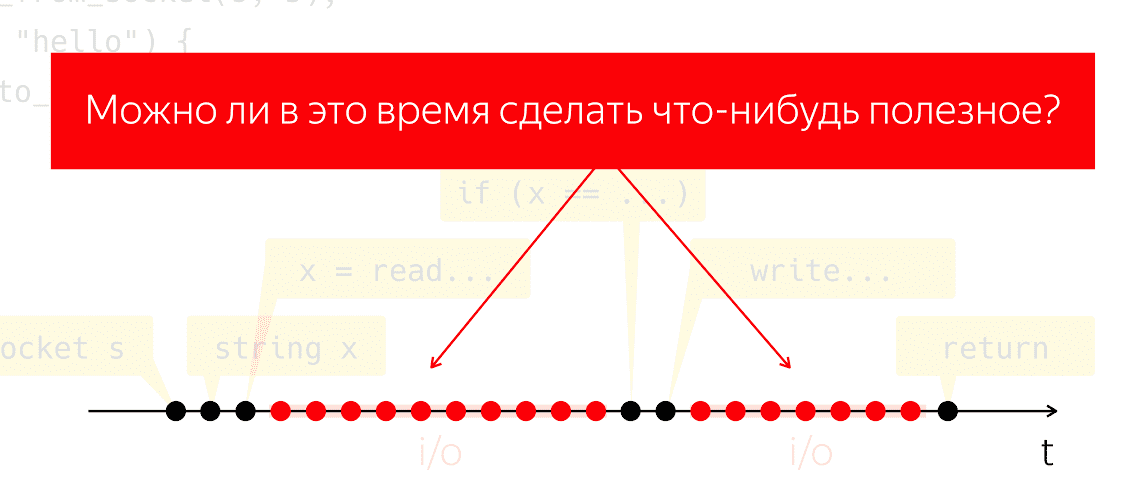
Surge a questão de saber se podemos fazer algo útil durante esse período de tempo. Essa é uma pergunta muito natural, cuja resposta nos permitiria economizar energia do processador e usá-la para algo útil, enquanto nosso aplicativo parece não estar fazendo nada.
3. Conceitos básicos
3.1 Thread de execução
Como podemos abordar essa tarefa? Vamos reconciliar os conceitos. Eu direi "fluxo de execução", referindo-se a uma sequência significativa de operações ou etapas elementares. A significância será determinada pelo contexto em que falo do fluxo de execução. Ou seja, se estamos falando de um algoritmo de thread único (Aho-Korasik, pesquisa de gráfico), então esse algoritmo em si já é um thread de execução. Ele toma algumas medidas para resolver o problema.
Se estou falando de um banco de dados, um segmento de execução pode fazer parte das ações executadas pelo banco de dados para atender a uma solicitação recebida. O mesmo vale para servidores web. Se estou escrevendo algum tipo de aplicativo móvel ou da Web, para atender à operação de um usuário, por exemplo, clicando em um botão, interações de rede, interação com armazenamento local e assim por diante. A sequência dessas ações do ponto de vista do meu aplicativo móvel também será um fluxo de execução significativo separado. Do ponto de vista do sistema operacional, um processo ou encadeamento de processo também é um encadeamento significativo de execução.
3.2 Multitarefa e simultaneidade
A pedra angular da produtividade é a capacidade de fazer esse truque: quando eu tiver um encadeamento de execução que contenha vazios em sua verificação de tempo físico, preencha-os com algo útil - siga as etapas de outros encadeamentos de execução.
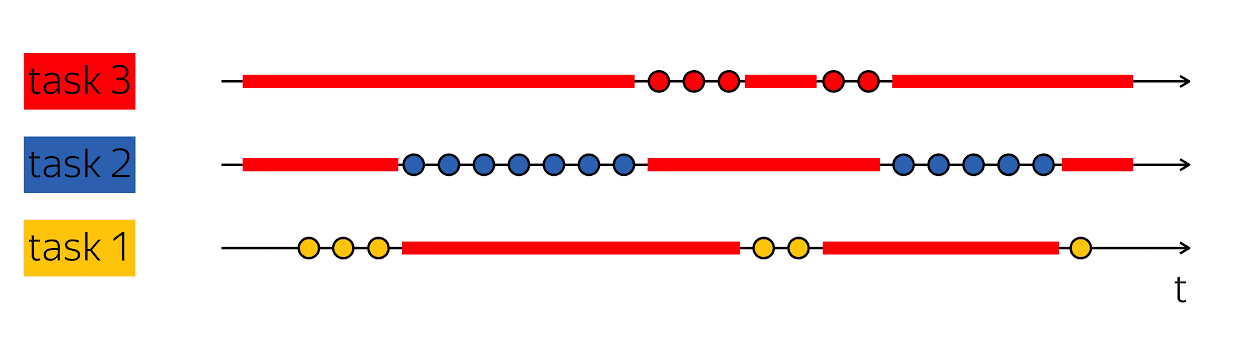
Os bancos de dados geralmente atendem a muitos clientes ao mesmo tempo. Se pudermos combinar o trabalho em vários encadeamentos de execução dentro da estrutura de um encadeamento de execução de nível superior, isso será chamado de multitarefa. Ou seja, a multitarefa é quando eu executo ações na estrutura de um fluxo maior de execução subordinado à solução de tarefas menores.
É importante não confundir o conceito de multitarefa com paralelismo. Simultaneidade -
essas são propriedades do ambiente de tempo de execução, o que possibilita, em uma etapa do tempo, em uma etapa, progredir em diferentes encadeamentos de execução. Se eu tiver dois processadores físicos, em um ciclo de clock eles poderão executar duas instruções. Se o programa estiver sendo executado em um processador, serão necessários dois ciclos de clock para executar as mesmas duas instruções.

É importante não confundir esses conceitos, pois eles se enquadram em diferentes categorias. A multitarefa é um recurso do seu programa que está estruturado internamente como um trabalho variável em diferentes tarefas. A simultaneidade é uma propriedade do ambiente de tempo de execução que permite trabalhar em várias tarefas em um ciclo de clock.
De várias maneiras, o código assíncrono e a gravação de código assíncrono estão gravando o código multitarefa. A principal dificuldade é como codifico tarefas e como gerenciá-las. Portanto, hoje falaremos sobre isso - escrevendo código multitarefa.
4. Bloqueio e espera

Vamos começar com um exemplo simples. De volta ao ping-pong:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Como já discutimos, após as linhas branca e de leitura, o encadeamento de execução adormece, ele é bloqueado. Normalmente dizemos "o fluxo está bloqueado".
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Isso significa que o fluxo de execução atingiu um ponto em que qualquer evento é necessário para continuar. Em particular, no caso de nosso aplicativo de rede, é necessário que os dados cheguem pela rede ou, inversamente, tenhamos um buffer gratuito para gravar dados na rede. Eventos podem ser diferentes. Se estivermos falando sobre aspectos de tempo, podemos esperar que o cronômetro seja acionado ou a conclusão de outro processo. Os eventos aqui são um tipo de coisa abstrata, sobre eles é importante entender que eles podem ser esperados.

Quando escrevemos código simples, atribuímos implicitamente o controle da expectativa de eventos a um nível superior. No nosso caso, o sistema operacional. Ela, como uma entidade de nível superior, é responsável por escolher qual tarefa será executada a seguir e também por controlar a ocorrência de eventos.
Nosso código, que escrevemos como desenvolvedores, é estruturado ao mesmo tempo em relação ao trabalho em uma tarefa. O trecho de código do exemplo lida com uma conexão: lê ping de uma conexão e grava pong em uma conexão.
O código está claro. Você pode lê-lo e entender o que faz, como funciona, qual problema resolve, quais invariantes possui e assim por diante. Ao mesmo tempo, gerenciamos muito mal o planejamento de tarefas nesse modelo. Em geral, os sistemas operacionais têm conceitos de prioridades, mas se você escreveu sistemas suaves em tempo real, sabe que as ferramentas disponíveis no Linux não são suficientes para criar sistemas sãos em tempo real suficientes.
Além disso, o sistema operacional é uma coisa complicada, e alternar o contexto de nosso aplicativo para o kernel custa alguns microssegundos, o que, com alguns cálculos simples, fornece uma estimativa de cerca de 20 a 100 mil alternâncias de contexto por segundo. Isso significa que, se escrevermos um servidor da Web, em um segundo poderemos processar cerca de 20 mil solicitações, assumindo que o processamento das solicitações seja dez vezes mais caro que o sistema.

4.1 Espera sem bloqueio
Se você chegar à situação em que precisa trabalhar com a rede com mais eficiência, começa a procurar ajuda na Internet e passa a usar select / epoll. Na Internet, está escrito que, se você deseja atender milhares de conexões ao mesmo tempo, precisa de epoll, porque é um bom mecanismo e assim por diante. Você abre a documentação e vê algo parecido com isto:
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout); void FD_CLR(int fd, fd_set* set); int FD_ISSET(int fd, fd_set* set); void FD_SET(int fd, fd_set* set); void FD_ZERO(fd_set* set); int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
Funções nas quais a interface contém muitos descritores com os quais você trabalha (no caso de select) ou muitos eventos que passam
além das fronteiras do seu aplicativo, o kernel do sistema operacional que você precisa processar (no caso do epoll).
Também vale a pena acrescentar que você pode optar por não selecionar / epoll, mas para uma biblioteca como o libuv, que não terá nenhum evento na API, mas terá muitos retornos de chamada. A interface da biblioteca diz: "Caro amigo, forneça um retorno de chamada para ler o soquete, que chamarei quando os dados aparecerem".
int uv_timer_start(uv_timer_t* handle, uv_timer_cb cb, uint64_t timeout, uint64_t repeat); typedef void (*uv_timer_cb)(uv_timer_t* handle); int uv_read_start(uv_stream_t* stream, uv_alloc_cb alloc_cb, uv_read_cb read_cb); int uv_read_stop(uv_stream_t*); typedef void (*uv_read_cb)(uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf); int uv_write(uv_write_t* req, uv_stream_t* handle, const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb); typedef void (*uv_write_cb)(uv_write_t* req, int status);
O que mudou em comparação com o nosso código síncrono no capítulo anterior? O código tornou-se assíncrono. Isso significa que inserimos a lógica no aplicativo para determinar o momento em que os eventos são monitorados. Chamadas explícitas de seleção / epoll são os pontos em que solicitamos ao sistema operacional informações sobre os eventos que ocorreram. Também levamos ao código do aplicativo a escolha de qual tarefa trabalhar em seguida.

A partir dos exemplos de interfaces, você pode ver que existem basicamente dois mecanismos para a introdução de multitarefa. Um tipo de "puxão" quando nós
desenhamos muitos dos eventos que estamos esperando e, de alguma forma, reagimos a eles. Nesta abordagem, é fácil amortizar as despesas gerais em um
um evento e, portanto, obtenha alto rendimento na comunicação sobre o conjunto de eventos que ocorreram. Geralmente, todos os elementos de rede, como a interação do kernel com a placa de rede ou a interação de você e o sistema operacional, são construídos sobre mecanismos de pesquisa.
A segunda maneira é um mecanismo "push", quando uma determinada entidade externa entra claramente, interrompe o fluxo de execução e diz: "Agora, processe o evento que acabou de chegar". Esta é uma abordagem com retornos de chamada, com sinais unix, com interrupções no nível do processador, quando uma entidade externa invade claramente seu segmento de execução e diz: "Agora, por favor, estamos trabalhando neste evento." Essa abordagem apareceu para reduzir o atraso entre a ocorrência de um evento e a reação a ele.
Por que desenvolvedores de C ++ que escrevem e resolvem problemas específicos de aplicativos podem querer arrastar um modelo de evento para o nosso código? Se arrastarmos e soltarmos o trabalho de muitas tarefas em nosso código e as gerenciarmos, devido à falta de transição para o kernel e vice-versa, poderemos trabalhar um pouco mais rápido e executar ações mais úteis por unidade de tempo.
O que isso leva a termos de código que escrevemos? Veja o nginx, por exemplo, um servidor HTTP de alto desempenho, muito comum. Se você ler seu código, ele será construído em um modelo assíncrono. O código é bem difícil de ler. Quando você se pergunta o que exatamente acontece ao processar uma única solicitação HTTP, o código tem muitos fragmentos espaçados em arquivos diferentes, em diferentes ângulos da base de código. Cada fragmento realiza uma pequena quantidade de trabalho como parte da veiculação de toda a solicitação HTTP. Por exemplo:
static void ngx_http_request_handler(ngx_event_t *ev) { … if (c->close) { ngx_http_terminate_request(r, 0); return; } if (ev->write) { r->write_event_handler(r); } else { r->read_event_handler(r); } ... } typedef void (*ngx_http_event_handler_pt)(ngx_http_request_t *r); struct ngx_http_request_s { ngx_http_event_handler_pt read_event_handler; }; r->read_event_handler = ngx_http_request_empty_handler; r->read_event_handler = ngx_http_block_reading; r->read_event_handler = ngx_http_test_reading; r->read_event_handler = ngx_http_discarded_request_body_handler; r->read_event_handler = ngx_http_read_client_request_body_handler; r->read_event_handler = ngx_http_upstream_rd_check_broken_connection; r->read_event_handler = ngx_http_upstream_read_request_handler;
Há uma estrutura de solicitação, que é encaminhada para o manipulador de eventos quando o soquete sinaliza acesso de leitura ou gravação. Além disso, esse manipulador alterna constantemente no decorrer do programa, dependendo do estado do processamento da solicitação. Ou lemos os cabeçalhos, ou lemos o corpo da solicitação, ou solicitamos dados a montante - em geral, existem muitos estados diferentes.
Esse código é difícil de ler porque é, em essência, descrito em termos de reação a eventos. Estamos em tal e tal estado e reagimos de certa maneira aos eventos que vieram. Falta uma imagem holística de todo o processo de processamento de uma solicitação HTTP.
Outra opção, que é freqüentemente usada em JavaScript, é criar código baseado em retorno de chamada quando encaminhamos nosso retorno de chamada para a chamada de interface, na qual geralmente há outro retorno de chamada aninhado para o evento e assim por diante.
int LibuvStreamWrap::ReadStart() { return uv_read_start(stream(), [](uv_handle_t* handle, size_t suggested_size, uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(handle->data)->OnUvAlloc(suggested_size, buf); }, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(stream->data)->OnUvRead(nread, buf); }); } for (p=data; p != data + len; p++) { ch = *p; reexecute: switch (CURRENT_STATE()) { case s_start_req_or_res: case s_res_or_resp_H: case s_res_HT: case s_res_HTT: case s_res_HTTP: case s_res_http_major: case s_res_http_dot:
O código está novamente muito fragmentado, não há entendimento do estado atual de como trabalhamos na solicitação. Muitas informações são transmitidas por meio de fechamentos, e você precisa fazer esforços mentais para reconstruir a lógica do processamento de uma única solicitação.
Assim, ao introduzir multitarefa em nosso código (a lógica de escolher tarefas de trabalho e multiplexá-las), obtemos código e controle eficazes sobre a priorização de tarefas, mas perdemos muitos deles em legibilidade. Este código é difícil de ler e difícil de manter.

Porque Suponha que eu tenha um caso simples, por exemplo, leio um arquivo e transfiro-o pela rede. Em uma versão sem bloqueio, este caso corresponderá a uma máquina de estados linear:
- Estado inicial
- Comece a ler um arquivo,
- Aguardando uma resposta do sistema de arquivos,
- Escrevendo um arquivo em um soquete,
- Estado final.
Agora, digamos que eu queira adicionar informações do banco de dados a este arquivo. Uma opção simples:
- estado inicial
- lendo um arquivo
- leia o arquivo
- lendo do banco de dados
- leia do banco de dados,
- Eu trabalho com uma tomada
- escreveu para o soquete.
Parece um código linear, mas o número de estados aumentou.
Então você começa a pensar que seria bom paralelizar as duas etapas - lendo de um arquivo e de um banco de dados. Os milagres da combinatória começam: você está no estado inicial, solicitando a leitura do arquivo e dos dados do banco de dados. Em seguida, você pode chegar a um estado em que há dados do banco de dados, mas não há arquivo, ou vice-versa - há dados do arquivo, mas não do banco de dados. Em seguida, você precisa entrar em um estado em que tenha uma de duas coisas. Novamente, esses são dois estados. Então você precisa entrar em um estado em que tenha os dois ingredientes. Em seguida, escreva-os no soquete e assim por diante.
Quanto mais complexa a aplicação, mais estados, mais fragmentos de código precisam ser combinados em sua cabeça. Inconvenientemente. Ou você está escrevendo macarrão de retorno de chamada, o que é inconveniente para ler. Se um sistema de ramificação é gravado, chega um dia em que você não pode mais tolerá-lo.
5. Futuros / Promessas
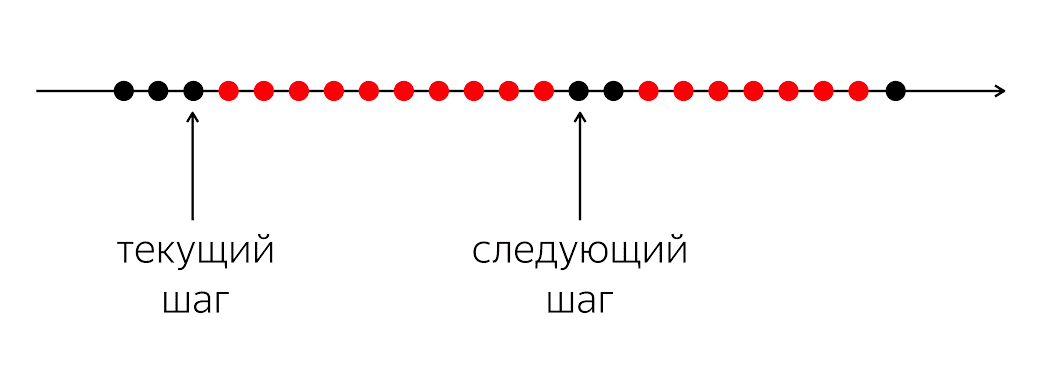
Para resolver o problema, você precisa analisar a situação com mais facilidade.

Existe um programa, tem círculos pretos e vermelhos. Nosso fluxo de execução é círculos pretos; Às vezes, eles são alternados com vermelho quando o fluxo não pode continuar seu trabalho. O problema é que, para o nosso segmento preto de execução, você precisa entrar no próximo círculo preto, que não será conhecido quando.
O problema é que, quando escrevemos código em uma linguagem de programação, explicamos ao computador o que fazer agora. Um computador é uma coisa relativamente simples que espera instruções que escrevemos na linguagem de programação. Ela aguarda instruções para o próximo círculo e, em nossa linguagem de programação, não há dinheiro suficiente para dizer: "No futuro, por favor, quando algo acontecer, faça alguma coisa".

Em uma linguagem de programação, operamos com ações momentâneas compreensíveis: chamar uma função, operações aritméticas, etc. Eles descrevem o próximo passo específico. Ao mesmo tempo, para processar a lógica do aplicativo, é necessário descrever não o próximo passo físico, mas o próximo passo lógico: o que devemos fazer quando os dados do banco de dados aparecerem, por exemplo.
Portanto, precisamos de algum mecanismo para combinar esses fragmentos. No caso em que escrevemos código síncrono, ocultamos completamente a questão e dissemos que o sistema operacional lidaria com isso, permitia que ele interrompesse e reagendasse nossos threads.
No nível 1, abrimos a caixa de Pandora e ela trouxe muitos códigos, casos, condições, ramificações e estados para o código. Eu gostaria de algum compromisso para que o código seja relativamente legível, mas mantenha todas as vantagens do nível 1.
Felizmente para nós, em 1988, as pessoas envolvidas em sistemas distribuídos, Barbara Liskov e Luba Shirir, perceberam o problema e chegaram à necessidade de mudanças linguísticas. É necessário adicionar construtos à linguagem de programação que permitam expressar relações temporais entre eventos - no momento atual e em um momento incerto no futuro.
Estes são chamados promessas. O conceito é legal, mas acumula poeira em uma prateleira há vinte anos. — , Twitter, Ruby on Rails Scala, , , , future . Your Server as a Function. , .
Scala, , ++ ?
, Future. T c : , - .
template <class T> class Future <T>
, , , . , «», , . Future «», Promise — «». ; , JavaScript, Promise — , Java – Future.
, . , , boost::future ( std::future) — , .
5.1. Future & Promise
template <class T> class Future { bool IsSet() const; const T& Get() const; T* TryGet() const; void Subscribe(std::function<void(const T&)> cb); template <class R> Future<R> Then( std::function<R(const T&)> f); template <class R> Future<R> Then( std::function<Future<R>(const T&)> f); }; template <class T> Future<T> MakeFuture(const T& value);
, , - , . , , , . , , — , , . Then, .
template <class T> class Promise { bool IsSet() const; void Set(const T& value); bool TrySet(const T& value); Future<T> ToFuture() const; }; template <class T> Promise<T> NewPromise();
. , . «, , , ».
5.2
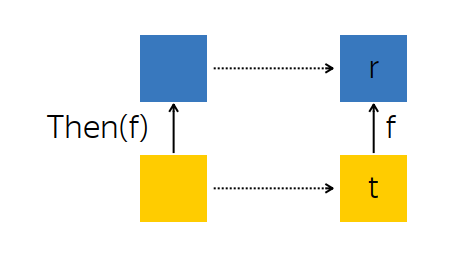
? , . Then — , .
, — future --, - t — . , , , f, - r.
t f. , , r.
: t, , r . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<R(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto r = f(t); promise.Set(r); }); return promise.ToFuture(); }
:
Promise R ,Future<T> t ,- ,
r = f(t) , r Promise ,Promise .
f , R , Future<R> , R . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<Future<R>(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto that = f(t); that.Subscribe([promise] (R r) { promise.Set(r); }); }); return promise.ToFuture(); }
, - t. f, r, . , , .

, Then :
Promise ,Subscribe -,Promise , Future .
, . , , , .
, , , -. , , -, Subscribe. , , , - . , .
5.3 Exemplos
AsyncComputeValue, GPU, . Then, , (2v+1) 2 .
Future<int> value = AsyncComputeValue();
. , : (2v+1) 2 . , .
, , . .
. : , ; ; .
Future<int> GetDbKey(); Future<string> LoadDbValue(int key); Future<void> SendToMars(string message); Future<void> ExploreOuterSpace() { return GetDbKey()
— ExploreOuterSpace. Then; — — , . ( ) . .
5.4 Any-
: Future , , . , , :
template <class T> Future<T> Any(Future<T> f1, Future<T> f2) { auto promise = NewPromise<T>(); f1.Subscribe([promise] (const T& t) { promise.TrySet(t); }); f2.Subscribe([promise] (const T& t) { promise.TrySet(t); }); return promise.ToFuture(); }
, Any-, Future : , . , , .
, , , , , . « DB1, DB2, — - ».
5.5 All-
. , , , ( T1 T2), T1 T2 , , .
template <class T1, class T2> Future<std::tuple<T1, T2>> All(Future<T1> f1, Future<T2> f2) { auto promise = NewPromise<std::tuple<T1, T2>>(); auto result = std::make_shared< std::tuple<T1, T2> >(); auto counter = std::make_shared< std::atomic<int> >(2); f1.Subscribe([promise, result, counter] (const T1& t1) { std::get<0>(*result) = t1; if (--(*counter) == 0) { promise.Set(*result)); } }); f2.Subscribe([promise, result, counter] (const T2& t2) { } return promise.ToFuture(); }
nginx. , , . nginx « », « », « » . All- , . .
5.6
Future Promises — legacy-, . callback- , , : Future, , callback- Future.
: , Future .
6.
, , . .
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp);
. Request, - . , . , , , . , - .
, , . ? — , request payload, — , .
, Java Netty. , , . , , .
, GetRequest, QueryBackend, HandlePayload Reply , Future.
, , Future T — WaitFor.
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future);
:
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor(GetRequest()); auto pld = WaitFor(QueryBackend(req)); auto rsp = WaitFor(HandlePayload(pld)); WaitFor(Reply(req, rsp));
: Future, . . , . .
. . - 0, , , mutex+cvar future. . , .

6.1
, . , , , , - , . , - .
— «» , , . . . : boost::asio boost::fiber.
, . Como fazer isso?
6.2 WaitFor
, , boost::context, : , ; , . x86/64 , , .
, goto: , , , .
, - . Fiber — . +Future. , , Future, .
class Fiber { MachineContext context_; Future<void> future_; };
class Scheduler { void WaitFor(Future<void> future); void Loop(); MachineContext loop_context_; Fiber* current_fiber_; std::deque<Fiber*> run_queue_; };
Future , , , . : Loop, , , , , .
WaitFor?
thread_local Scheduler* ThisScheduler; template <class T> T WaitFor(Future<T> future) { ThisScheduler->WaitFor(future.As<void>()); return future.Get(); } void Scheduler::WaitFor(Future<void> future) { current_fiber_->future_ = future; SwitchContext(¤t_fiber_->context_, &loop_context_); }
: , - , , Future void, . .
Future<void> , , - .
WaitFor : : « Fiber Future», ( ) .
, :
ThisScheduler->WaitFor return future.Get() , .
? , Future, .
6.3
- , , , - , . SwitchContext , 2 — .
void Scheduler::Loop() { while (true) {
? , , , Future, Future, , , .
void Scheduler::Loop() { while (true) {
, . :
WaitFor — .

Switch- .

Future ( ), , . - Fiber.

WaitFor Future , - , Future . :
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor( GetRequest()); auto pld = WaitFor( QueryBackend(req)); auto rsp = WaitFor( HandlePayload(pld)); WaitFor( Reply(req, rsp));
, , , . , , .
6.4 Coroutine TS
? — . Coroutine TS, , WaitFor CoroutineWait, CoroutineTS — - . , - . , Waiter Co, , .
7. ?
. , , , . , , , .
— . , . . , . , , , , .
- , , . , . , , .

, ? , .
. , , , , . . , , , , .
nginx, , , , , . , , , future promises.
, , , , , , , .
futures, promises actors. . , .
: , , , . , , , , . ? , .
Minuto de publicidade. 19-20 C++ Russia 2019. , , Grimm Rainer «Concurrency and parallelism in C++17 and C++20/23» , C++ . , . , , - .