Já discutimos o
mecanismo de indexação do PostgreSQL,
a interface dos métodos de acesso e três métodos:
índice de hash ,
árvore B e
GiST . Neste artigo, descreveremos o SP-GiST.
SP-GiST
Primeiro, algumas palavras sobre esse nome. A parte "GiST" alude a alguma semelhança com o método de acesso com o mesmo nome. A semelhança existe: ambas são árvores de pesquisa generalizadas que fornecem uma estrutura para a construção de vários métodos de acesso.
"SP" significa particionamento de espaço. O espaço aqui geralmente é exatamente o que costumamos chamar de espaço, por exemplo, um plano bidimensional. Mas veremos que qualquer espaço de pesquisa é destinado, ou seja, realmente qualquer domínio de valor.
O SP-GiST é adequado para estruturas onde o espaço pode ser dividido recursivamente em áreas
sem interseção . Esta classe inclui quadras, árvores k-dimensionais (árvores kD) e árvores de raiz.
Estrutura
Portanto, a idéia do método de acesso SP-GiST é dividir o domínio de valor em subdomínios
não sobrepostos, cada um dos quais, por sua vez, também pode ser dividido. Particionar dessa maneira induz árvores
não balanceadas (ao contrário das árvores B e do GiST comum).
A característica de não interseção simplifica a tomada de decisões durante a inserção e a pesquisa. Por outro lado, como regra, as árvores induzidas são de baixa ramificação. Por exemplo, um nó de um quadtree geralmente possui quatro nós filhos (diferentemente das árvores B, onde os nós somam centenas) e uma profundidade maior. Árvores como essas são adequadas ao trabalho na RAM, mas o índice é armazenado em um disco e, portanto, para reduzir o número de operações de E / S, os nós precisam ser compactados em páginas e não é fácil fazer isso com eficiência. Além disso, o tempo necessário para encontrar diferentes valores no índice pode variar devido a diferenças nas profundidades dos ramos.
Esse método de acesso, da mesma forma que o GiST, cuida de tarefas de baixo nível (acesso e bloqueios simultâneos, log e um algoritmo de pesquisa puro) e fornece uma interface simplificada especializada para permitir adicionar suporte a novos tipos de dados e novos algoritmos de particionamento.
Um nó interno da árvore SP-GiST armazena referências a nós filhos; um
rótulo pode ser definido para cada referência. Além disso, um nó interno pode armazenar um valor chamado
prefixo . Na verdade, esse valor não é um prefixo obrigatório; pode ser considerado como um predicado arbitrário que é atendido para todos os nós filhos.
Os nós folha do SP-GiST contêm um valor do tipo indexado e uma referência a uma linha da tabela (TID). Os dados indexados em si (chave de pesquisa) podem ser usados como valor, mas não obrigatórios: um valor reduzido pode ser armazenado.
Além disso, os nós das folhas podem ser agrupados em listas. Portanto, um nó interno pode referenciar não apenas um valor, mas uma lista inteira.
Observe que prefixos, rótulos e valores nos nós folha têm seus próprios tipos de dados, independentes um do outro.
Da mesma forma que no GiST, a função principal a ser definida para pesquisa é
a função de consistência . Essa função é chamada para um nó da árvore e retorna um conjunto de nós filhos cujos valores "são consistentes" com o predicado de pesquisa (como de costume, no formato "
expressão do operador de campo indexado "). Para um nó folha, a função de consistência determina se o valor indexado nesse nó atende ao predicado de pesquisa.
A pesquisa começa com o nó raiz. A função de consistência permite descobrir quais nós filhos faz sentido visitar. O algoritmo se repete para cada um dos nós encontrados. A pesquisa é aprofundada.
No nível físico, os nós de índice são compactados em páginas para tornar o trabalho eficiente com os nós do ponto de vista das operações de E / S. Observe que uma página pode conter nós internos ou folha, mas não os dois.
Exemplo: quadtree
Um quadtree é usado para indexar pontos em um plano. Uma idéia é dividir recursivamente as áreas em quatro partes (quadrantes) em relação ao
ponto central . A profundidade dos galhos em uma árvore pode variar e depende da densidade de pontos nos quadrantes apropriados.
É assim que parece nas figuras, por exemplo do
banco de dados de demonstração aumentado pelos aeroportos no site
openflights.org . A propósito, recentemente lançamos uma nova versão do banco de dados na qual, entre os demais, substituímos longitude e latitude por um campo do tipo "point".
 Primeiro, dividimos o avião em quatro quadrantes ...
Primeiro, dividimos o avião em quatro quadrantes ...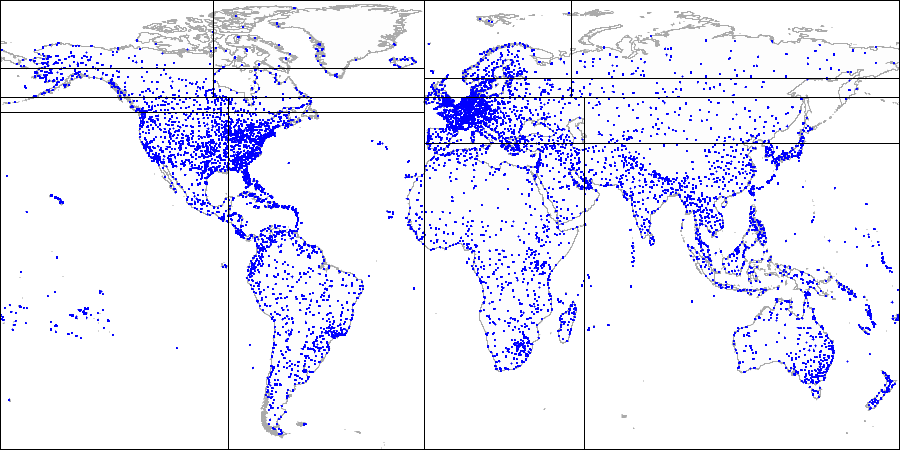 Depois dividimos cada um dos quadrantes ...
Depois dividimos cada um dos quadrantes ...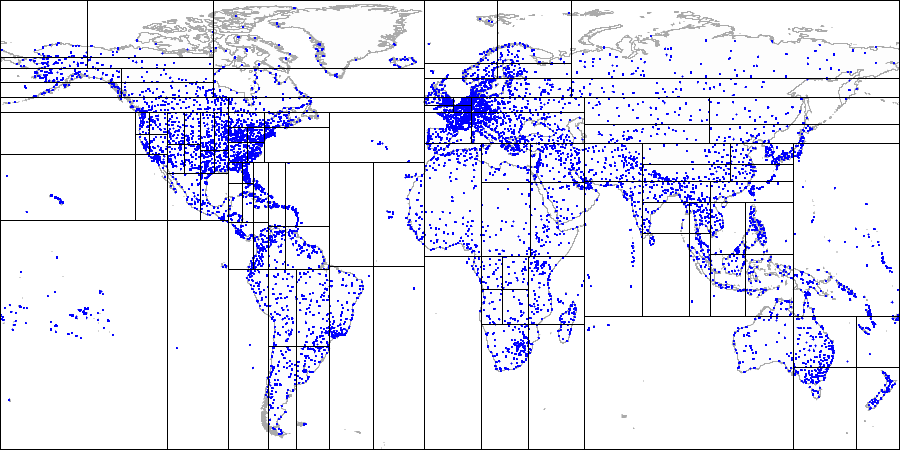 E assim por diante até obtermos o particionamento final.
E assim por diante até obtermos o particionamento final.Vamos fornecer mais detalhes de um exemplo simples que já consideramos no
artigo relacionado ao
GiST . Veja como pode ser o particionamento neste caso:
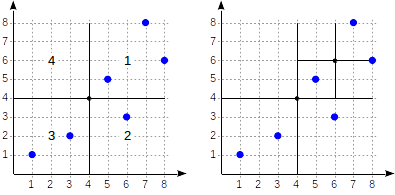
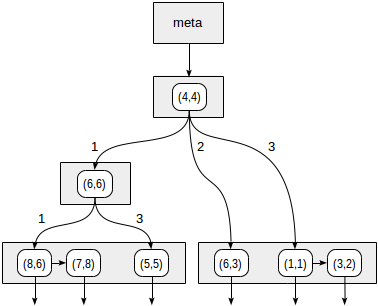
Os quadrantes são numerados conforme mostrado na primeira figura. Para fins de definição, vamos colocar nós filhos da esquerda para a direita exatamente na mesma sequência. Uma possível estrutura de índice, neste caso, é mostrada na figura abaixo. Cada nó interno faz referência a um máximo de quatro nós filhos. Cada referência pode ser rotulada com o número do quadrante, como na figura. Mas não há rótulo na implementação, pois é mais conveniente armazenar uma matriz fixa de quatro referências, algumas das quais podem estar vazias.
Os pontos que estão nos limites estão relacionados ao quadrante com o número menor.
postgres=# create table points(p point); postgres=# insert into points(p) values (point '(1,1)'), (point '(3,2)'), (point '(6,3)'), (point '(5,5)'), (point '(7,8)'), (point '(8,6)'); postgres=# create index points_quad_idx on points using spgist(p);
Nesse caso, a classe de operador "quad_point_ops" é usada por padrão, que contém os seguintes operadores:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'quad_point_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'spgist' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------+-------------- <<(point,point) | 1 strictly left >>(point,point) | 5 strictly right ~=(point,point) | 6 coincides <^(point,point) | 10 strictly below >^(point,point) | 11 strictly above <@(point,box) | 8 contained in rectangle (6 rows)
Por exemplo, vejamos como a consulta
select * from points where p >^ point '(2,7)' será executado (encontre todos os pontos acima do dado).
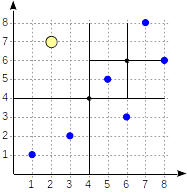
Começamos com o nó raiz e usamos a função de consistência para selecionar para quais nós filhos descender. Para o operador
>^ , essa função compara o ponto (2,7) com o ponto central do nó (4,4) e seleciona os quadrantes que podem conter os pontos buscados, neste caso, o primeiro e o quarto quadrantes.
No nó correspondente ao primeiro quadrante, determinamos novamente os nós filhos usando a função consistency. O ponto central é (6,6), e novamente precisamos examinar o primeiro e o quarto quadrantes.
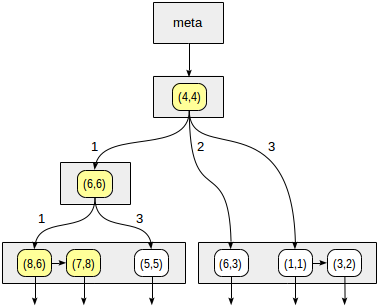
A lista de nós folha (8.6) e (7.8) corresponde ao primeiro quadrante, do qual apenas o ponto (7.8) atende à condição de consulta. A referência ao quarto quadrante está vazia.
No nó interno (4.4), a referência ao quarto quadrante também está vazia, o que completa a pesquisa.
postgres=# set enable_seqscan = off; postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN ------------------------------------------------ Index Only Scan using points_quad_idx on points Index Cond: (p >^ '(2,7)'::point) (2 rows)
Internals
Podemos explorar a estrutura interna dos índices SP-GiST usando a extensão "
gevel ", mencionada anteriormente. A má notícia é que, devido a um erro, esta extensão funciona incorretamente com as versões modernas do PostgreSQL. A boa notícia é que planejamos aumentar a "inspeção de página" com a funcionalidade de "gevel" (
discussão ). E o bug já foi corrigido em "pageinspect".
Novamente, a má notícia é que o patch ficou sem progresso.
Por exemplo, vamos pegar o banco de dados de demonstração estendido, que foi usado para desenhar figuras com o mapa do mundo.
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
Primeiro, podemos obter algumas estatísticas para o índice:
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats ---------------------------------- totalPages: 33 + deletedPages: 0 + innerPages: 3 + leafPages: 30 + emptyPages: 2 + usedSpace: 201.53 kbytes+ usedInnerSpace: 2.17 kbytes + usedLeafSpace: 199.36 kbytes+ freeSpace: 61.44 kbytes + fillRatio: 76.64% + leafTuples: 5993 + innerTuples: 37 + innerAllTheSame: 0 + leafPlaceholders: 725 + innerPlaceholders: 0 + leafRedirects: 0 + innerRedirects: 0 (1 row)
E segundo, podemos gerar a própria árvore de índices:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value from spgist_print('airports_coordinates_quad_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix point,
tid | n | level | tid_ptr | prefix | leaf_value ---------+---+-------+---------+------------------+------------------ (1,1) | 0 | 1 | (5,3) | (-10.220,53.588) | (1,1) | 1 | 1 | (5,2) | (-10.220,53.588) | (1,1) | 2 | 1 | (5,1) | (-10.220,53.588) | (1,1) | 3 | 1 | (5,14) | (-10.220,53.588) | (3,68) | | 3 | | | (86.107,55.270) (3,70) | | 3 | | | (129.771,62.093) (3,85) | | 4 | | | (57.684,-20.430) (3,122) | | 4 | | | (107.438,51.808) (3,154) | | 3 | | | (-51.678,64.191) (5,1) | 0 | 2 | (24,27) | (-88.680,48.638) | (5,1) | 1 | 2 | (5,7) | (-88.680,48.638) | ...
Mas lembre-se de que "spgist_print" gera não todos os valores das folhas, mas apenas o primeiro da lista e, portanto, mostra a estrutura do índice e não o conteúdo completo.
Exemplo: árvores k-dimensionais
Para os mesmos pontos no plano, também podemos sugerir outra maneira de particionar o espaço.
Vamos desenhar
uma linha horizontal através do primeiro ponto a ser indexado. Ele divide o plano em duas partes: superior e inferior. O segundo ponto a ser indexado se enquadra em uma dessas partes. Nesse ponto, vamos desenhar
uma linha vertical , que divide esta parte em duas: direita e esquerda. Novamente desenhamos uma linha horizontal através do próximo ponto e uma linha vertical até o próximo ponto, e assim por diante.
Todos os nós internos da árvore criados dessa maneira terão apenas dois nós filhos. Cada uma das duas referências pode levar ao nó interno que é o próximo na hierarquia ou à lista de nós folha.
Esse método pode ser facilmente generalizado para espaços k-dimensionais e, portanto, as árvores também são chamadas de dimensões k-k (árvores kD) na literatura.
Explicando o método por exemplo de aeroportos:
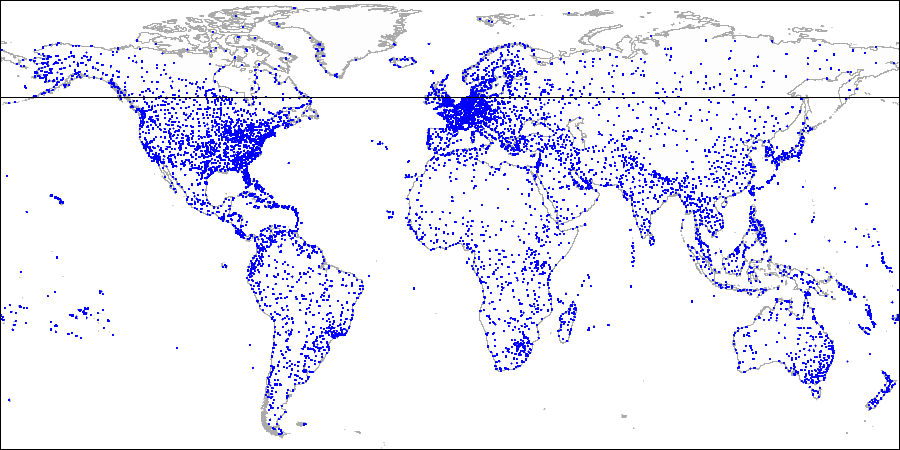 Primeiro dividimos o avião em partes superior e inferior ...
Primeiro dividimos o avião em partes superior e inferior ...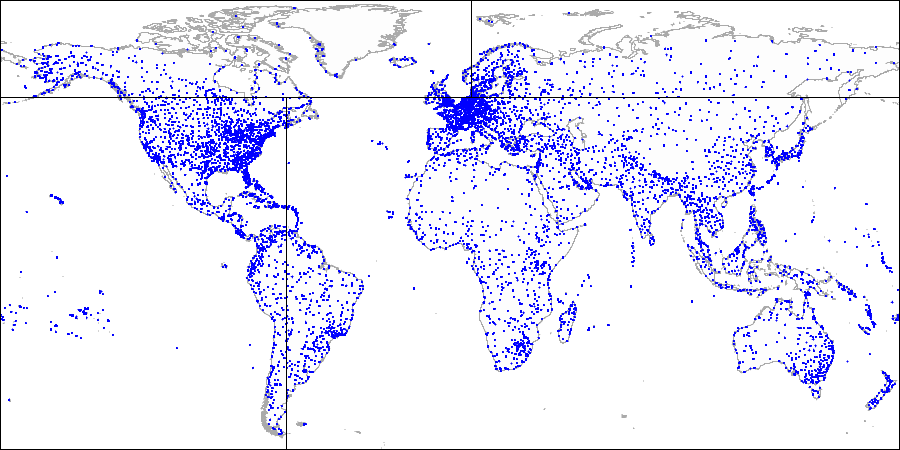 Em seguida, dividimos cada parte em partes esquerda e direita ...
Em seguida, dividimos cada parte em partes esquerda e direita ... E assim por diante até obtermos o particionamento final.
E assim por diante até obtermos o particionamento final.Para usar um particionamento como este, precisamos especificar explicitamente a classe de operador
"kd_point_ops" ao criar um índice.
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
Esta classe inclui exatamente os mesmos operadores que a classe "padrão" "quad_point_ops".
Internals
Ao examinar a estrutura em árvore, precisamos levar em consideração que o prefixo nesse caso é apenas uma coordenada em vez de um ponto:
demo=# select tid, n, level, tid_ptr, prefix, leaf_value from spgist_print('airports_coordinates_kd_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix float,
tid | n | level | tid_ptr | prefix | leaf_value ---------+---+-------+---------+------------+------------------ (1,1) | 0 | 1 | (5,1) | 53.740 | (1,1) | 1 | 1 | (5,4) | 53.740 | (3,113) | | 6 | | | (-7.277,62.064) (3,114) | | 6 | | | (-85.033,73.006) (5,1) | 0 | 2 | (5,12) | -65.449 | (5,1) | 1 | 2 | (5,2) | -65.449 | (5,2) | 0 | 3 | (5,6) | 35.624 | (5,2) | 1 | 3 | (5,3) | 35.624 | ...
Exemplo: árvore radix
Também podemos usar o SP-GiST para implementar uma árvore de raiz para seqüências de caracteres. A idéia de uma árvore de raiz é que uma sequência a ser indexada não é totalmente armazenada em um nó folha, mas é obtida concatenando os valores armazenados nos nós acima deste até a raiz.
Suponha que precisamos indexar os URLs do site: "postgrespro.ru", "postgrespro.com", "postgresql.org" e "planet.postgresql.org".
postgres=# create table sites(url text); postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org'); postgres=# create index on sites using spgist(url);
A árvore terá a seguinte aparência:
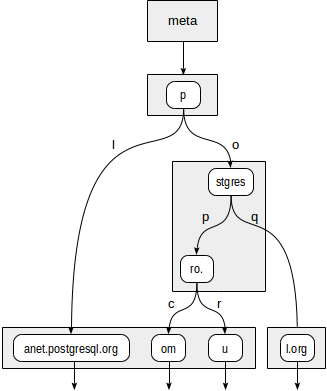
Os nós internos da árvore armazenam prefixos comuns a todos os nós filhos. Por exemplo, nos nós filhos de "stgres", os valores começam com "p" + "o" + "stgres".
Ao contrário dos quadríceps, cada ponteiro para um nó filho também é rotulado com um caractere (mais exatamente, com dois bytes, mas isso não é tão importante).
A classe de operador "Text_ops" suporta operadores do tipo B-tree: "equal", "maior" e "less":
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'text_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'spgist' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------+-------------- ~<~(text,text) | 1 ~<=~(text,text) | 2 =(text,text) | 3 ~>=~(text,text) | 4 ~>~(text,text) | 5 <(text,text) | 11 <=(text,text) | 12 >=(text,text) | 14 >(text,text) | 15 (9 rows)
A distinção de operadores com tildes é que eles manipulam
bytes em vez de
caracteres .
Às vezes, uma representação na forma de uma árvore de raiz pode se tornar muito mais compacta do que a árvore-B, já que os valores não são totalmente armazenados, mas reconstruídos conforme a necessidade que surge enquanto desce pela árvore.
Considere uma consulta:
select * from sites where url like 'postgresp%ru' . Pode ser realizado usando o índice:
postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN ------------------------------------------------------------------------------ Index Only Scan using sites_url_idx on sites Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text)) Filter: (url ~~ 'postgresp%ru'::text) (3 rows)
Na verdade, o índice é usado para encontrar valores maiores ou iguais a "postgresp", mas menores que "postgresq" (Índice Cond), e os valores correspondentes são escolhidos no resultado (Filtro).
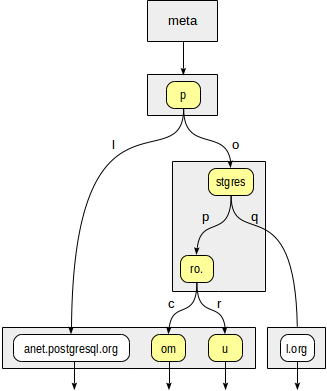
Primeiro, a função de consistência deve decidir para quais nós filhos da raiz "p" precisamos descer. Duas opções estão disponíveis: "p" + "l" (não é necessário descer, o que é claro mesmo sem se aprofundar) e "p" + "o" + "stgres" (continue a descida).
Para o nó "stgres", é necessária uma chamada para a função de consistência novamente para verificar "postgres" + "p" + "ro". (continue a descida) e "postgres" + "q" (não é necessário descer).
Para "ro". nó e todos os seus nós folha filho, a função de consistência responderá "yes", portanto o método index retornará dois valores: "postgrespro.com" e "postgrespro.ru". Um valor correspondente será selecionado deles no estágio de filtragem.
Internals
Ao examinar a estrutura em árvore, precisamos levar em consideração os tipos de dados:
postgres=# select * from spgist_print('sites_url_idx') as t( tid tid, allthesame bool, n int, level int, tid_ptr tid, prefix text,
Propriedades
Vejamos as propriedades do método de acesso SP-GiST (as consultas
foram fornecidas anteriormente ):
amname | name | pg_indexam_has_property --------+---------------+------------------------- spgist | can_order | f spgist | can_unique | f spgist | can_multi_col | f spgist | can_exclude | t
Os índices SP-GiST não podem ser usados para classificação e suporte à restrição exclusiva. Além disso, índices como este não podem ser criados em várias colunas (ao contrário do GiST). Mas é permitido usar esses índices para suportar restrições de exclusão.
As seguintes propriedades da camada de índice estão disponíveis:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | f
A diferença do GiST aqui é que o armazenamento em cluster é impossível.
E, eventualmente, o seguinte são propriedades da camada de coluna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | t search_array | f search_nulls | t
A classificação não é suportada, o que é previsível. Os operadores de distância para procurar vizinhos mais próximos não estão disponíveis no SP-GiST até o momento. Muito provavelmente, esse recurso será suportado no futuro.
Ele é suportado no PostgreSQL 12, o patch de Nikita Glukhov.
O SP-GiST pode ser usado para varredura apenas de índice, pelo menos para as classes de operadores discutidas. Como vimos, em alguns casos, os valores indexados são explicitamente armazenados nos nós das folhas, enquanto nos outros, os valores são reconstruídos parte por parte durante a descida da árvore.
Nulos
Para não complicar, não mencionamos NULLs até agora. Fica claro nas propriedades do índice que NULLs são suportados. Realmente:
postgres=# explain (costs off) select * from sites where url is null;
QUERY PLAN ---------------------------------------------- Index Only Scan using sites_url_idx on sites Index Cond: (url IS NULL) (2 rows)
No entanto, NULL é algo estranho para o SP-GiST. Todos os operadores da classe de operador "spgist" devem ser rigorosos: um operador deve retornar NULL sempre que qualquer um de seus parâmetros for NULL. O método em si garante o seguinte: os NULLs não são passados aos operadores.
Mas, para usar o método de acesso para verificação apenas de índice, os NULLs devem ser armazenados no índice de qualquer maneira. E eles são armazenados, mas em uma árvore separada com sua própria raiz.
Outros tipos de dados
Além de pontos e árvores de raiz para seqüências de caracteres, outros métodos baseados no SP-GiST também são implementados no PostgreSQL:
- A classe de operador Box_ops fornece um quadtree para retângulos.
Cada retângulo é representado por um ponto em um espaço quadridimensional , portanto, o número de quadrantes é igual a 16. Um índice como esse pode superar o GiST no desempenho quando há muitas interseções dos retângulos: no GiST é impossível desenhar limites de modo a separar objetos que se cruzam entre si, embora não haja problemas com pontos (mesmo quadridimensionais).
- A classe de operador "Range_ops" fornece um quadtree para intervalos.
Um intervalo é representado por um ponto bidimensional : o limite inferior se torna a abcissa e o limite superior se torna a ordenada.
Continue lendo .