
Como mencionado no artigo Radar Technology , a Lamoda está se movendo ativamente em direção à arquitetura de microsserviço. A maioria dos nossos serviços é empacotada usando o Helm e implantada no Kubernetes. Essa abordagem atende totalmente às nossas necessidades em 99% dos casos. 1% permanece quando a funcionalidade padrão do Kubernetes não é suficiente, por exemplo, quando você precisa configurar um backup ou atualizar um serviço para um evento específico. Para resolver esse problema, usamos o padrão do operador. Nesta série de artigos, I - Grigory Mikhalkin, desenvolvedor da equipe de P&D da Lamoda - falará sobre as lições que aprendi da minha experiência no desenvolvimento de operadores K8s usando a Estrutura do Operador .
O que é um operador?
Uma maneira de estender a funcionalidade do Kubernetes é criar seus próprios controladores. As principais abstrações no Kubernetes são objetos e controladores. Objetos descrevem o estado desejado do cluster. Por exemplo, um Pod descreve quais contêineres precisam ser iniciados e os parâmetros de inicialização, e o objeto ReplicaSet informa quantas réplicas de um determinado Pod precisam ser iniciadas. Os controladores controlam o estado do cluster com base na descrição dos objetos. No caso descrito acima, o ReplicationController suportará o número de réplicas de Pods especificadas no ReplicaSet. Com a ajuda de novos controladores, você pode implementar lógica adicional, como enviar notificações para eventos, recuperar-se de uma falha ou gerenciar recursos de terceiros .
Um operador é um aplicativo kubernetes que inclui um ou mais controladores que servem um recurso de terceiros. O conceito foi inventado pela equipe do CoreOS em 2016 e, recentemente, a popularidade das operadoras vem crescendo rapidamente. Você pode tentar encontrar o operador desejado na lista no kubedex (mais de 100 operadores publicamente disponíveis estão listados aqui), bem como no OperatorHub . Existem três ferramentas populares para o desenvolvimento do operador: Kubebuilder , Operator SDK e Metacontroller . Em Lamoda, usamos o Operator SDK, portanto falaremos sobre isso mais tarde.
SDK do operador
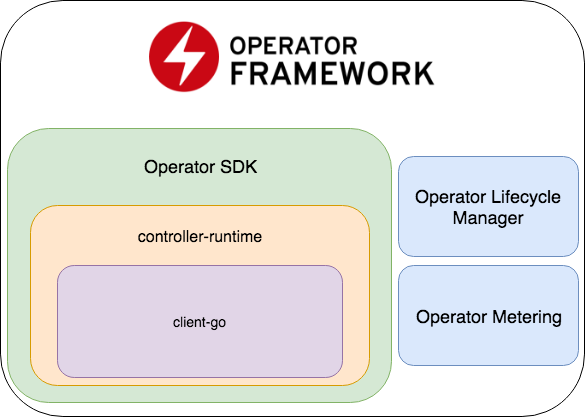
O Operator SDK faz parte da Estrutura do operador, que inclui duas partes mais importantes: Operator Lifecycle Manager e Operator Metering.
- O Operator SDK é um wrapper para controller-runtime , uma biblioteca popular para o desenvolvimento de controladores (que, por sua vez, é um wrapper para o client-go ), um gerador de código + estrutura para a gravação de testes E2E.
- Operator Lifecycle Manager - uma estrutura para gerenciar operadores existentes; resolve situações em que o operador entra no modo zumbi ou uma nova versão é lançada.
- Medição do operador - como o nome indica, ele coleta dados sobre o trabalho do operador e também pode gerar relatórios com base neles.
Crie um novo projeto
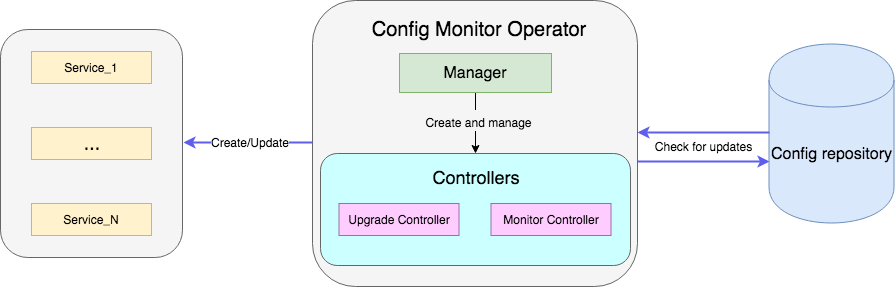
Um exemplo é um operador que monitora um arquivo com configurações no repositório e, quando atualizado, reinicia a implantação do serviço com novas configurações. O código de amostra completo está disponível aqui .
Crie um projeto com um novo operador:
operator-sdk new config-monitor
O gerador de código criará código para o operador que trabalha no espaço para nome alocado. Essa abordagem é preferível a dar acesso a todo o cluster, pois, em caso de erros, os problemas serão isolados no mesmo espaço para nome. O operador em cluster-wide pode ser gerado adicionando --cluster-scoped . Os seguintes diretórios estarão localizados dentro do projeto criado:
- cmd - contém o
main package , no qual o Manager inicializado e lançado; - deploy - contém declarações do operador, CRD e objetos necessários para configurar o operador RBAC;
- pkg - aqui será o nosso código principal para novos objetos e controladores.
Há apenas um arquivo cmd/manager/main.go no cmd/manager/main.go .
Snippet de código // Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) }
Na primeira linha: err = leader.Become(ctx, "config-monitor-lock") - um líder é selecionado. Na maioria dos cenários, apenas uma instância ativa de uma instrução no espaço para nome / cluster é necessária. Por padrão, o Operator SDK usa a estratégia Leader for life - a primeira instância iniciada do operador permanecerá líder até ser removida do cluster.
Após essa instância do operador ter sido nomeada líder, um novo Manager é inicializado - mgr, err := manager.New(...) . Suas responsabilidades incluem:
err := apis.AddToScheme(mgr.GetScheme()) - registro de novos esquemas de recursos;err := controller.AddToManager(mgr) - registro de controladores;err := mgr.Start(signals.SetupSignalHandler()) - inicia e controla os controladores.
No momento, não temos novos recursos nem controladores para registro. Você pode adicionar um novo recurso usando o comando:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService
Este comando incluirá a definição de esquema de recurso MonitoredService no diretório pkg/apis , bem como yaml com a definição de CRD em deploy/crds . De todos os arquivos gerados, você deve alterar manualmente apenas a definição de esquema em monitoredservice_types.go . O tipo MonitoredServiceSpec define o estado desejado do recurso: o que o usuário especifica no yaml com a definição do recurso. No contexto de nosso operador, o campo Size determina o número desejado de réplicas, ConfigRepo indica de onde as configurações atuais podem ser ConfigRepo . MonitoredServiceStatus determina o estado observado do recurso, por exemplo, armazena os nomes dos Pods pertencentes a esse recurso e os Pods de spec atual.
Após editar o esquema, você precisa executar o comando:
operator-sdk generate k8s
Ele atualizará a definição de CRD em deploy/crds .
Agora vamos criar a parte principal do nosso operador, o controlador:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor
O arquivo monitor_controller.go aparecerá no monitor_controller.go pkg/controller , no qual adicionamos a lógica necessária.
Desenvolvimento de Controladores
O controlador é a principal unidade de trabalho do operador. No nosso caso, existem dois controladores:
- O controlador do monitor monitora as alterações na configuração do serviço;
- O controlador de atualização atualiza o serviço e o mantém no estado desejado.
Em sua essência, o controlador é um loop de controle, monitora a fila com os eventos nos quais está inscrito e os processa:
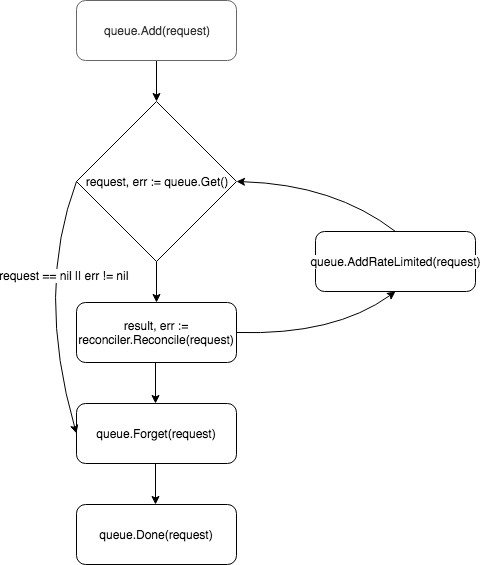
Um novo controlador é criado e registrado pelo gerente no método add :
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})
Usando o método Watch , nós o inscrevemos em eventos relacionados à criação de um novo recurso ou à atualização Spec de um recurso MonitoredService existente:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)
O tipo de evento pode ser configurado usando os parâmetros src e predicates . src aceita objetos do tipo Source .
Informer - pesquisa periodicamente o apiserver em apiserver de eventos que correspondam ao filtro, se houver, coloca-o na fila do controlador. No controller-runtime esse é um wrapper sobre o SharedIndexInformer do client-go .Kind também é um invólucro do SharedIndexInformer , mas, diferentemente do Informer , ele cria independentemente uma instância do informer com base nos parâmetros passados (esquema do recurso monitorado).Channel - aceita o chan event.GenericEvent como parâmetro, os eventos que passam por ele são colocados na fila do controlador.
redicates espera objetos que satisfaçam a interface do Predicate . Na verdade, esse é um filtro adicional para eventos, por exemplo, ao filtrar o UpdateEvent você pode ver exatamente quais alterações foram feitas na spec recurso.
Quando um evento chega, um EventHandler aceita - o segundo argumento do método Watch - que envolve o evento no formato de solicitação que o Reconciler espera:
EnqueueRequestForObject - cria uma solicitação com o nome e o espaço para nome do objeto que causou o evento;EnqueueRequestForOwner - cria uma solicitação com os dados do pai do objeto. Isso é necessário, por exemplo, se o Pod controlado por recursos foi excluído e você precisa iniciar sua substituição;EnqueueRequestsFromMapFunc - usa como parâmetro a função de map que recebe um evento ( MapObject em MapObject ) e retorna uma lista de solicitações. Um exemplo em que esse manipulador é necessário - existe um cronômetro, para cada marca da qual você precisa obter novas configurações para todos os serviços disponíveis.
As solicitações são colocadas na fila do controlador e um dos trabalhadores (por padrão, o controlador possui um) puxa o evento para fora da fila e o passa para o Reconciler .
O reconciliador implementa apenas um método - Reconcile , que contém a lógica básica do processamento de eventos:
método de reconciliação func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil }
O método aceita um objeto Request com o campo NamespacedName , pelo qual o recurso pode ser extraído do cache: r.client.Get(context.TODO(), request.NamespacedName, instance) . No exemplo, é feita uma solicitação ao arquivo com a configuração de serviço referenciada pelo campo ConfigRepo na spec recurso. Se a configuração for atualizada, um novo evento do tipo GenericEvent será GenericEvent e enviado ao canal que o controlador de Upgrade ouve.
Após o processamento da solicitação, Reconcile retorna um objeto do tipo Result e error . Se o campo Result for Requeue: true ou error != nil , o controlador retornará a solicitação de volta para a fila usando o método queue.AddRateLimited . A solicitação será retornada para a fila com um atraso, determinado pelo RateLimiter . Por padrão, ItemExponentialFailureRateLimiter usado, o que aumenta exponencialmente o tempo de atraso com um aumento no número de "retornos" de solicitação. Se o campo Requeue não Requeue definido e nenhum erro ocorreu durante o processamento da solicitação, o controlador chamará o método Queue.Forget , que removerá a solicitação do cache do RateLimiter (redefinindo o número de devoluções). No final do processamento da solicitação, o controlador o remove da fila usando o método Queue.Done .
Lançamento do operador
Os componentes do operador foram descritos acima, e uma pergunta permaneceu: como iniciá-lo. Primeiro, você precisa garantir que todos os recursos necessários estejam instalados (para testes locais, recomendo configurar o minikube ):
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml
Depois que os pré-requisitos forem atendidos, há duas maneiras fáceis de executar a instrução para teste. O mais fácil é iniciá-lo fora do cluster usando o comando:
operator-sdk up local --namespace=default
A segunda maneira é implantar o operador no cluster. Primeiro, você precisa criar uma imagem do Docker com o operador:
operator-sdk build config-monitor-operator:latest
No arquivo deploy/operator.yaml , substitua REPLACE_IMAGE por config-monitor-operator:latest :
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml
Crie a implantação com a instrução:
kubectl create -f deploy/operator.yaml
Agora, na lista de Pod no cluster, deve aparecer o Pod com um serviço de teste e, no segundo caso - outro com um operador.
Em vez de uma conclusão ou melhores práticas
Os principais problemas do desenvolvimento do operador no momento são a documentação fraca das ferramentas e a falta de boas práticas estabelecidas. Quando um novo desenvolvedor começa a desenvolver um operador, ele praticamente não tem onde procurar exemplos da implementação de um requisito específico, de modo que erros são inevitáveis. Abaixo estão algumas lições que aprendemos com nossos erros:
- Se houver dois aplicativos relacionados, evite o desejo de combiná-los com um único operador. Caso contrário, o princípio dos serviços de acoplamento flexível é violado.
- Você precisa se lembrar sobre a separação de preocupações: você não deve tentar implementar toda a lógica em um controlador. Por exemplo, vale a pena espalhar as funções de monitorar configurações e criar / atualizar um recurso.
- O bloqueio de chamadas deve ser evitado no método
Reconcile . Por exemplo, você pode obter configurações de uma fonte externa, mas se a operação for mais longa, crie uma goroutine para isso e envie a solicitação de volta para a fila, indicando na resposta Requeue: true .
Nos comentários, seria interessante ouvir sobre sua experiência no desenvolvimento de operadores. E na próxima parte, falaremos sobre testes de operadores.