
Sou desenvolvedor Java líder no Yandex.Money.
Todas as manhãs de trabalho em 2018, recebi cerca de 30 solicitações pull à espera de uma revisão e não tive tempo suficiente para classificá-las em um dia. No final do verão, saí de férias e, quando voltei, encontrei uma fila de 50 relações públicas atribuídas a mim. Não havia desejo de varrê-los, mas essa era apenas a ponta do iceberg, que eu vi com meus próprios olhos. Naquele dia, decidi que era hora de mudar alguma coisa.
Esta é a história de como aceleramos a revisão de código, descarregamos os principais desenvolvedores e melhoramos as ferramentas que usamos todos os dias.
Revisão de código 1.0. Como foi antes?
No Yandex.Money, uma revisão de código há muito tempo é um estágio obrigatório de desenvolvimento e todo mundo está acostumado a isso. Alguns perceberam que isso era tanto quanto testar; outros consideraram isso um mal necessário, e alguém se deparou com uma revisão de código apenas como o autor de solicitações pull, mas evitou a revisão de código de outra pessoa. Eu acho que muitos viajaram sequencialmente do último ao primeiro, e isso é normal.
Para a revisão do código, usamos o Bitbucket desde o início. Para cada repositório de componentes, foi adicionada uma lista de 3-4 revisores padrão, que foram adicionados a todos os PRs. Geralmente, essa lista era compilada e editada pelo chefe do departamento e, às vezes, voluntários que queriam revisar um componente específico eram adicionados lá. Os repositórios de bibliotecas eram um pouco mais fáceis - a lista de revisores era a mesma para todas as bibliotecas e os desenvolvedores seniores foram incluídos lá.
Como resultado, quase todo o ônus recai sobre os revisores dentre os desenvolvedores seniores, que gradualmente deixaram de ser suficientes, levando em consideração o crescimento do departamento para 60 pessoas, um aumento no número de repositórios (mais de 60 componentes, mais de 100 bibliotecas) e aceleração de nosso CI / CD.
Além da carga de trabalho pesada e da falta de recursos dos revisores, havia outros problemas:
- em alguns componentes, pode-se esperar uma reação dos revisores por mais de um dia,
- alta carga de trabalho dos indicados como revisores em vários componentes,
- difícil atrair novos revisores, inclusive por causa do parágrafo anterior,
- se o revisor principal ficou doente ou de férias, a revisão do código de tempo dos componentes começou a aumentar visivelmente,
- os revisores designados nem sempre tinham experiência real no componente, por causa disso a qualidade da revisão de código sofreu.
Antes de resolver esses problemas, você precisa decidir o que geralmente esperamos de uma revisão de código.
A revisão de código correta é como?
Identificamos quatro pontos que devem estar na revisão de código atualizada:
- Valide a arquitetura da solução . Coisa bastante óbvia. Esperamos isso de desenvolvedores seniores com experiência neste componente.
- Verificação da implementação técnica , que também esperamos de especialistas seniores e médios com experiência neste componente.
- A transferência de conhecimento , que consiste no estudo da lógica de negócios e da base de código para iniciantes e junho por meio de revisões de código.
- Capacidade de avaliar as habilidades dos desenvolvedores . Quero que todo desenvolvedor receba um mentor que avalie o crescimento, determine o vetor de desenvolvimento, observe algumas deficiências, faça comentários e assim por diante. Portanto, o mentor também deve ver o código de suas alas.
Talvez alguém veja outros objetivos ou discorde dos nossos - compartilhe nos comentários. Enquanto isso, passo da formulação de metas para encontrar meios para alcançá-las - decidimos que queremos alcançá-las e (quase) imediatamente.
Revisão de código 2.0. Como é isso?
O que criamos? Começamos a raciocinar passo a passo.
No Yandex.Money, os desenvolvedores trabalham em equipes nas áreas de negócios, geralmente de 2 a 4 desenvolvedores de back-end em uma equipe.
Digamos que vou abrir uma solicitação pull, ou seja, sou o autor dela . Eu tenho minha equipe , cujos desenvolvedores conhecem bem a lógica de negócios do que estou fazendo, porque todos participamos de projetos comuns, geralmente sincronizamos e geralmente interagimos ativamente. Portanto, quero adicioná-los às minhas solicitações de recebimento antes de tudo, para que estejam pelo menos atualizados com o que estou fazendo.
Cada componente do Yandex.Money possui uma equipe responsável e acompanha-o na produção.
Se eu modificar um componente pelo qual outra equipe é responsável, parece lógico adicionar desenvolvedores dessa equipe aos revisores - eles são responsáveis por esse componente e devem monitorar a qualidade de seu código. Mas, para não sobrecarregar os revisores, levamos apenas uma pessoa aleatória dessa equipe - acreditamos que isso é suficiente.
Pode acontecer que a equipe responsável pelo componente não tenha experiência suficiente nele. Isso acontece quando os recém-chegados aparecem na equipe ou são confiados a esse componente apenas recentemente. No entanto, eu sei que temos especialistas reais nesta empresa neste repositório, e seria ótimo se um deles visse meu código! Obviamente, é difícil formalizar meu conhecimento, mas você pode pegar o histórico do repositório e calcular a revisão do código com base no número de PRs e estatísticas, que trabalharam muito nesse código e / ou revisaram muito. Calculamos a métrica de expertise no repositório, selecionamos os principais desenvolvedores para essa métrica, os chamamos de especialistas e adicionamos um especialista aleatório aos revisores.
Em 2018, introduzimos o instituto de orientação na empresa, e agora um mentor entre os desenvolvedores seniores está assistindo a cada equipe. Além disso, cada novato na empresa a princípio tem um mentor pessoal.
Deixe meu mentor assistir meu código! Ele poderá ajudar em caso de problemas na revisão do código e também terá uma idéia dos meus pontos fortes e fracos nas habilidades técnicas.
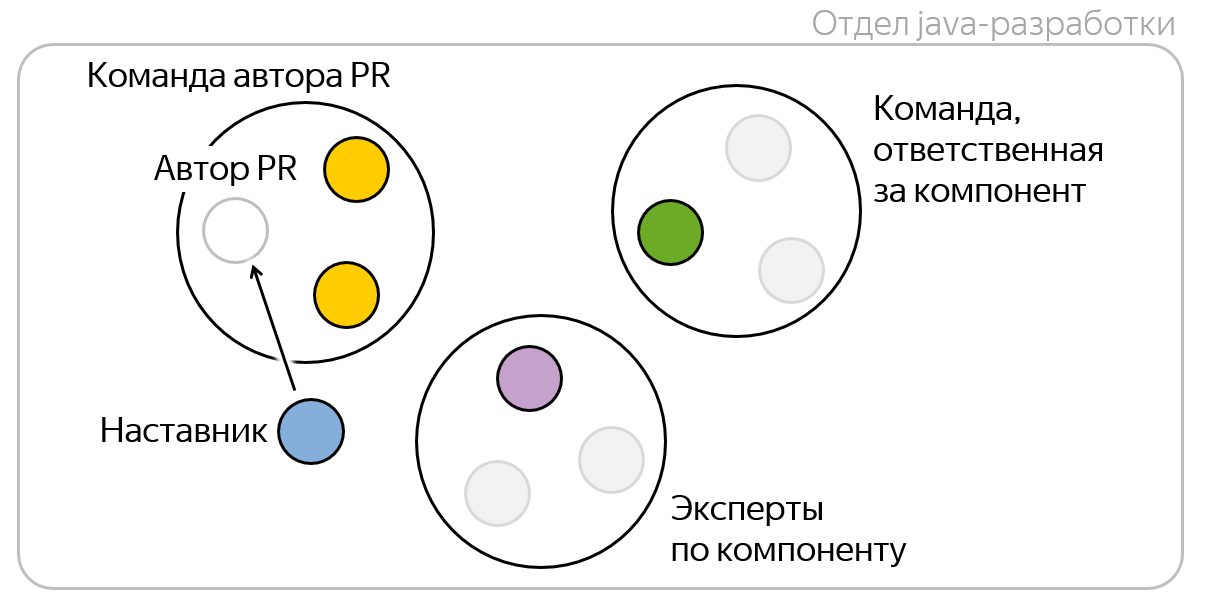
No total, cinco a seis pessoas podem ser adicionadas aos revisores de cada solicitação de recebimento. Mas, na verdade, geralmente são um pouco menores, porque diferentes papéis podem ser combinados em uma pessoa. Meu mentor pode ser um especialista ao mesmo tempo e minha equipe pode ser responsável pelo componente. Subjetivamente, 3-4 revisores seriam ótimos para solicitações de recebimento.
Revisão de código 2.0. O que há sob o capô?
A questão é pequena: faça tudo funcionar. Ajudou aqui que todas as nossas formações já estavam configuradas em um sistema separado que fornece a API REST para recebê-las. Portanto, após algumas semanas de desenvolvimento lento no meu tempo livre, nasceu a primeira versão do plug-in para Bitbucket, que foi gradualmente desenvolvida e adquiriu todo o conjunto necessário de funcionalidades durante o outono.
Como o plugin funciona
Normalmente, ao criar um PR, o Bitbucket preenche os visualizadores especificados nas configurações do projeto ou repositório. Do ponto de vista do usuário, nada mudou aqui - todos os revisores também são preenchidos previamente quando esta página é aberta, exceto que um campo foi adicionado com uma descrição de qual revisor em qual função foi adicionada. E os papéis dos revisores apareceram da seguinte maneira:
- teammate é um membro da equipe do autor do PR, é facilmente adicionado graças à API REST com a composição das equipes,
- proprietário do repositório - um membro aleatório da equipe responsável pelo componente; nas configurações do repositório, foi necessário dar a oportunidade de escolher a equipe responsável,
- especialista em repositório - especialista em repositório aleatório; Vou falar mais sobre isso mais tarde
- mentor - um mentor de uma equipe ou iniciante, também está disponível via API REST em um serviço com composições de equipe.
Especialistas em Repositórios
Vou falar um pouco mais sobre como consideramos especialistas. Todos os dias, o plug-in passa por todos os repositórios, analisa todas as solicitações pull do último ano e considera duas métricas simples:
- o número de solicitações pull criadas pelo desenvolvedor,
- o número de PRs que ele revisou e aprovou precisa de trabalho ou recusa.
Adicionamos pesos a essas métricas com base no fato de que, do ponto de vista da experiência no código, o refinamento desse código é mais importante que a revisão. Primeiro, estimamos o número de solicitações de recebimento criadas uma vez e meia mais importantes que uma revisão e, posteriormente, aumentamos a proporção para três para um. Resumimos as métricas multiplicadas por seus pesos e obtemos a classificação do desenvolvedor.
Em seguida, classificamos todos esses desenvolvedores por classificação, selecionamos os 5 primeiros e, ao longo do caminho, eliminamos aqueles cuja classificação está abaixo do limite para eliminar os transeuntes casuais. E geralmente temos de três a cinco especialistas para cada repositório.
Descrevi acima a abordagem para a seleção de revisores, que escolhemos e implementamos, mas, ao longo do caminho, implementamos várias pequenas melhorias ao mesmo tempo, o que tornou o processo de revisão de código ainda mais rápido, conveniente e agradável.
Banir solicitação pull de mesclagem até a tarefa ser verificada no Jira
Uma coisa tão óbvia e necessária, que, infelizmente, não sai da caixa. Nós só obtemos código estável no dev, que passou não apenas em verificações estáticas e testes de desenvolvedor, mas também em testes de integração junto com outros serviços. O status de tais testes para nós é refletido apenas na tarefa Jira e, portanto, antes, os desenvolvedores tinham que ver manualmente se a tarefa foi verificada para diminuir a solicitação de recebimento.
Solicitação de pull de mesclagem automática
A solicitação de recebimento pode passar uma parte considerável de sua vida em um estado em que nada o impede de levar tempo, mas uma pessoa esquece de fazer isso ou não imediatamente. Um exemplo impressionante é a expectativa de testar uma tarefa, sem a qual não a mantemos em dev. É aqui que uma mesclagem automática é útil, o que funciona de acordo com um princípio simples: se o PR pode ser congelado, nós o fazemos.
Todas as condições necessárias para mesclagem são cobertas por verificações. Verificamos o sucesso da montagem, o nível de cobertura do teste, a ausência de dependências de captura instantânea das bibliotecas, o status da tarefa em Jira e a presença de todas as atualizações necessárias. Ou seja, temos tudo para usar essa funcionalidade e esquecer o PR desde o momento em que passamos na revisão do código e submetemos a tarefa ao teste (a menos que, é claro, o controle de qualidade encontre problemas nela).
E implementamos isso de uma maneira bastante conveniente: introduzimos um bot especial do AutoMergeBot, que precisamos adicionar aos revisores, para que ele possa começar a monitorar essa solicitação e congelá-la quando chegar a hora.
Contabilizando a ausência de revisores
Se o proprietário ou especialista do componente estiver de férias ou em licença médica, ele não será adicionado pelo revisor e seu lugar será ocupado por quem estiver no local de trabalho. Como bônus, uma montanha de pedidos de sugestões de outras pessoas não cairá sobre esse revisor ao sair das férias. Perceber que isso não foi difícil devido ao fato de que toda a falta de funcionários conosco foi registrada em Jira.
Contabilização do emprego de revisores
Alguém revisa dez PRs por dia e cerca de cinco. Alguém já acumulou 20 PRs não vistos, enquanto alguém não tem quase nenhum. Levamos tudo isso em conta para distribuir a carga de maneira mais uniforme nos revisores. Quanto mais carga, menos ela é adicionada aos novos PRs - tudo é simples.
Marcando tamanhos de PR ao criar
Na página de criação da solicitação de recebimento, o autor pode escolher seu tamanho aproximado: S, M ou L. Isso ajuda os revisores a estimar o tempo aproximado que eles gastarão na revisão de código. Por exemplo, tenho 5 minutos grátis e entendo que consigo ver a solicitação pull do tamanho S. Não faz sentido abrir M ou L, porque não tenho tempo para assisti-los e da próxima vez terei que começar do zero.
No futuro, queremos levar esses atributos em consideração ao calcular as estatísticas de relações públicas.
Rotulagem PR urgente
Além disso, ao criar um PR, o autor pode indicar que a tarefa é muito urgente adicionando esse símbolo ao nome PR. Ele será visto imediatamente pelos revisores e tentará ver primeiro. Parece um pouco, mas muito útil e conveniente.
Acompanhamento da revisão do código inicial e final
Se, ao melhorar o processo, é impossível entender o quanto ele melhorou, não faz sentido começar.
O mesmo ocorre com a revisão de código - podemos tentar aprimorá-lo o quanto quisermos, mas como teremos certeza de uma dinâmica positiva sem métricas e estatísticas? No nosso caso, essa não é a tarefa mais fácil - pronto, o Bitbucket e o Jira não deram a oportunidade de rastrear o tempo de revisão do código. Tínhamos apenas a métrica de tempo de vida útil de relações públicas em serviço, o que não nos convinha, porque somente solicitamos por solicitação após a conclusão do teste da tarefa, portanto, indicadores estranhos foram misturados nessa métrica.
O Jira armazena e permite que você faça o upload de todos os pontos de controle do ciclo de vida da tarefa; portanto, achamos correto enriquecer esses dados com dois rótulos adicionais: o horário de início e término da revisão do código. Era apenas necessário ensinar o plugin para o Bitbucket empurrar essas tags no Jira. Assim, Jira foi e continua sendo um ponto único de verdade para a tarefa e, com esse conjunto de dados, podemos separar o tempo da revisão do código do momento do teste da tarefa.
O ponto mais fino aqui é como determinar quando terminar uma revisão de código? Talvez seja a hora de obter o primeiro aplicativo, talvez o último, ou talvez seja a hora das últimas alterações feitas pelo autor do PR? Não tenho uma resposta para esta pergunta, aqui só preciso concordar entre nós e escolher uma coisa ou cobrir todos os três eventos com métricas e seguir os desvios.
Rastreando downloads de revisores
Outra métrica útil é a carga de trabalho dos revisores. Como escrevi acima, levamos isso em consideração ao atribuir revisores a novos PRs, mas também publicamos essas informações para monitorar a dinâmica de equipes, departamentos ou empresas. Às vezes, isso ajuda a detectar anomalias e possíveis problemas: se estiver claro que uma ou mais pessoas em uma equipe penduram 10 ou mais PRs não visualizados todos os dias, há um motivo para descobrir se tudo está em ordem.
Ver métricas em Grafana
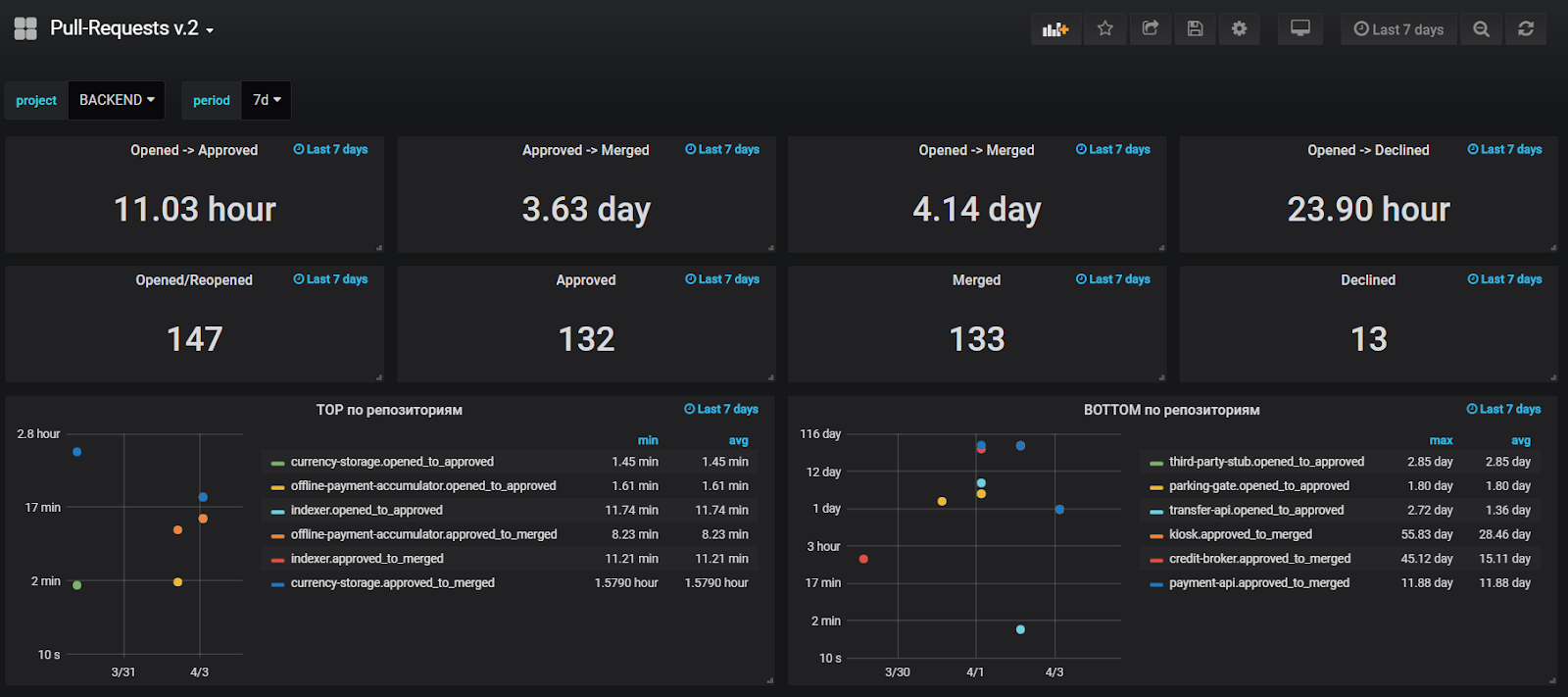
A criação de relatórios sobre dados do Jira é útil, mas não muito conveniente, por isso, também adicionamos o envio de métricas para os principais eventos no StatsD, a fim de criar gráficos sobre os dados operacionais no Grafana. Monitoramos o tempo médio até o primeiro teste, o tempo de vida médio do PR e também analisamos os valores anômalos dessas métricas para encontrar e resolver problemas rapidamente.
No momento da redação deste artigo, nosso painel fica assim:
O que você conseguiu no final?
Infelizmente, somos todos fortes em retrospectiva, portanto, não introduzimos as métricas de revisão de código mencionadas acima antes que o processo em si começasse a mudar (setembro-outubro de 2018), mas já ao longo do caminho, para que possamos rastrear com segurança melhorias ou deteriorações a partir do início de dezembro de 2018 O que conseguimos notar?
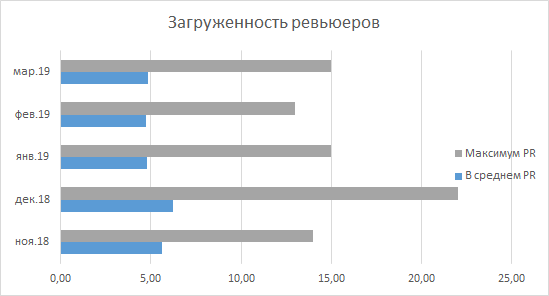
A primeira coisa que chama sua atenção é a redução da carga de revisores seniores, e senti isso pelo meu próprio exemplo. Como mencionei, era normal ver cerca de 30 PRs alinhados pela manhã, mas agora esse número varia entre 10 e 15. As estatísticas do departamento confirmam isso: desde dezembro de 2018, o número máximo de PRs aguardando uma revisão não foi aumentado por ninguém acima de 15. Em média, observamos uma imagem que sugere que, em média, cada desenvolvedor espera 4-5 PRs não visualizados pela manhã, o que parece ser um número bastante adequado.
Quanto à relevância da seleção dos revisores e à qualidade da revisão do código, aqui podemos confiar apenas em indicadores subjetivos. De acordo com as pesquisas de colegas, realmente começamos a ter uma excelente seleção de revisores, agora ninguém precisa adicionar manualmente e nenhum PR é deixado abandonado e esquecido.
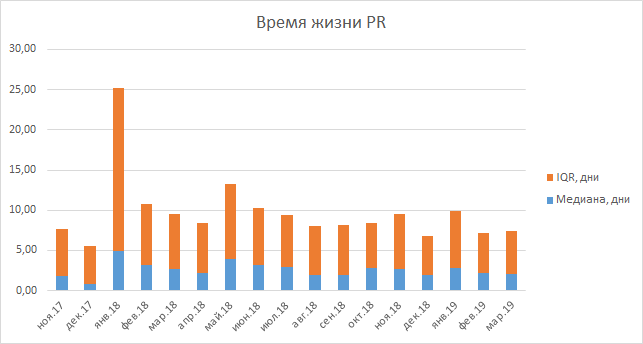
Se falamos sobre o tempo que leva para passar na revisão do código, é muito cedo para calcular as estatísticas desse indicador, porque começamos a coletá-lo recentemente. À nossa disposição, existe apenas o tempo de vida de solicitações pull, que na verdade não aumentaram ou diminuíram. Essa métrica inclui o tempo de teste da tarefa, por isso é difícil tirar conclusões claras sobre ela; além disso, alterando o código de revisão, não demoramos mais.