Agora, o processamento de linguagem natural não é usado, exceto em setores muito conservadores. Na maioria das soluções tecnológicas, o reconhecimento e o processamento de linguagens "humanas" são introduzidos há muito tempo: é por isso que a URA usual com opções de resposta codificadas está gradualmente se tornando uma coisa do passado, os chatbots estão começando a se comunicar de forma mais adequada sem a participação de um operador ativo, os filtros de email funcionam com um estrondo, etc. Como é o reconhecimento da fala gravada, ou seja, texto? Ou melhor, qual será a base das modernas técnicas de reconhecimento e processamento? A tradução adaptada de hoje responde bem a isso - sob o corte, você encontrará uma longa distância que fechará as lacunas no básico da PNL. Boa leitura!
O que é processamento de linguagem natural?
Processamento de linguagem natural (doravante denominado PNL) - o processamento de linguagem natural é uma subseção da ciência da computação e da IA dedicada à maneira como os computadores analisam as linguagens naturais (humanas). A PNL permite o uso de algoritmos de aprendizado de máquina para texto e fala.
Por exemplo, podemos usar a PNL para criar sistemas como reconhecimento de fala, generalização de documentos, tradução automática, detecção de spam, reconhecimento de entidades nomeadas, respostas a perguntas, preenchimento automático, entrada de texto previsto, etc.
Hoje, muitos de nós temos smartphones de reconhecimento de fala - eles usam a PNL para entender nossa fala. Além disso, muitas pessoas usam laptops com reconhecimento de fala embutido no sistema operacional.
Exemplos
Cortana
O Windows possui um assistente virtual da Cortana que reconhece a fala. Com a Cortana, você pode criar lembretes, abrir aplicativos, enviar cartas, jogar, descobrir o clima etc.
Siri
Siri é assistente do sistema operacional da Apple: iOS, watchOS, macOS, HomePod e tvOS. Muitas funções também funcionam com o controle de voz: ligar / escrever para alguém, enviar um e-mail, definir um temporizador, tirar uma foto etc.
Gmail
Um serviço de e-mail conhecido sabe como detectar spam para que não entre na caixa de entrada da sua caixa de entrada.
Fluxo de Diálogo
Uma plataforma do Google que permite criar bots de PNL. Por exemplo, você pode fazer um bot de pedidos de pizza
que não precise de uma URA antiquada para aceitar seu pedido .
Biblioteca Python NLTK
O NLTK (Natural Language Toolkit) é uma plataforma líder para a criação de programas de PNL em Python. Possui interfaces fáceis de usar para muitos
grupos de idiomas , além de bibliotecas para processamento de texto para classificação, tokenização,
stemming ,
marcação , filtragem e
raciocínio semântico . Bem, e este é um projeto de código aberto gratuito que está sendo desenvolvido com a ajuda da comunidade.
Usaremos essa ferramenta para mostrar o básico da PNL. Para todos os exemplos subseqüentes, presumo que o NLTK já esteja importado; isso pode ser feito com o
import nltkNoções básicas de PNL para texto
Neste artigo, abordaremos tópicos:
- Tokenização por ofertas.
- Tokenização por palavras.
- Lematização e carimbo do texto.
- Pare de palavras.
- Expressões regulares.
- Saco de palavras .
- TF-IDF .
1. Tokenização por ofertas
Tokenização (às vezes segmentação) de sentenças é o processo de dividir uma linguagem escrita em sentenças componentes. A ideia parece bem simples. Em inglês e em alguns outros idiomas, podemos isolar uma frase sempre que encontrarmos um determinado sinal de pontuação - um ponto.
Mas mesmo em inglês essa tarefa não é trivial, pois o ponto também é usado em abreviações. A tabela de abreviaturas pode ajudar bastante durante o processamento de texto para evitar extraviar os limites das frases. Na maioria dos casos, as bibliotecas são usadas para isso, então você não precisa se preocupar com detalhes da implementação.
Um exemplo:Faça um texto breve sobre o jogo de tabuleiro de gamão:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Para fazer tokenização de ofertas usando o NLTK, você pode usar o método
nltk.sent_tokenize | text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
Na saída, temos 3 frases separadas:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2. Tokenização de acordo com as palavras
Tokenização (às vezes segmentação) de acordo com as palavras é o processo de dividir sentenças em palavras componentes. Em inglês e em muitos outros idiomas que usam uma ou outra versão do alfabeto latino, um espaço é um bom separador de palavras.
No entanto, podem surgir problemas se usarmos apenas um espaço - em inglês, os substantivos compostos são escritos de maneira diferente e às vezes separados por espaços. E aqui as bibliotecas nos ajudam novamente.
Um exemplo:Vamos pegar as frases do exemplo anterior e aplicar o método
nltk.word_tokenize a elas
| for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
Conclusão:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3. Lematização e carimbo do texto
Geralmente, os textos contêm diferentes formas gramaticais da mesma palavra, e também podem ocorrer palavras de uma raiz. A lematização e a derivação visam trazer todas as formas de palavras que ocorrem para uma única forma de vocabulário normal.
Exemplos:Trazendo diferentes formas de palavras para um:
dog, dogs, dog's, dogs' => dog
O mesmo, mas com referência a toda a frase:
the boy's dogs are different sizes => the boy dog be differ size
Lematização e stemming são casos especiais de normalização e diferem.
O stemming é um processo heurístico grosseiro que corta o “excesso” da raiz das palavras, geralmente isso leva à perda de sufixos de construção de palavras.
A lematização é um processo mais sutil que utiliza análise morfológica e de vocabulário para finalmente trazer a palavra para sua forma canônica - o lema.
A diferença é que o stemmer (uma implementação específica do algoritmo stemming - comentário do tradutor) opera sem conhecer o contexto e, portanto, não entende a diferença entre palavras que têm significados diferentes, dependendo da parte da fala. No entanto, os Stemmers têm suas próprias vantagens: são mais fáceis de implementar e trabalham mais rapidamente. Além disso, menor "precisão" pode não ser importante em alguns casos.
Exemplos:- A palavra bom é um lema para a palavra melhor. O Stemmer não verá essa conexão, pois aqui você precisa consultar o dicionário.
- O jogo de palavras é a forma básica do jogo de palavras. Aqui, tanto a stemming quanto a lematização irão lidar.
- A palavra reunião pode ser uma forma normal de um substantivo ou uma forma do verbo, dependendo do contexto. Ao contrário do stemming, a lematização tentará escolher o lema certo com base no contexto.
Agora que sabemos qual é a diferença, vejamos um exemplo:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
Conclusão:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4. Pare de palavras
Palavras de parada são aquelas que são jogadas fora do texto antes / após o processamento do texto. Quando aplicamos o aprendizado de máquina aos textos, essas palavras podem adicionar muito ruído, portanto, você precisa se livrar de palavras irrelevantes.
As palavras de parada são geralmente entendidas por artigos, interjeições, uniões etc., que não carregam uma carga semântica. Deve-se entender que não existe uma lista universal de palavras de parada, tudo depende do caso em particular.
O NLTK possui uma lista predefinida de palavras de parada. Antes do primeiro uso, você precisará fazer o download:
nltk.download(“stopwords”) . Após o download, você pode importar o pacote
stopwords e examinar as próprias palavras:
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
Conclusão:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Considere como você pode remover palavras de parada de uma frase:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
Conclusão:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
Se você não estiver familiarizado com a compreensão de listas, poderá descobrir mais
aqui . Aqui está outra maneira de obter o mesmo resultado:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
No entanto, lembre-se de que a compreensão da lista é mais rápida porque é otimizada - o intérprete revela um padrão preditivo durante o loop.
Você pode perguntar por que convertemos a lista para
muitos . Um conjunto é um tipo de dados abstrato que pode armazenar valores exclusivos em uma ordem indefinida. A pesquisa por conjunto é muito mais rápida do que a pesquisa em uma lista. Para um pequeno número de palavras, isso não importa, mas se estamos falando de um grande número de palavras, é altamente recomendável usar conjuntos. Se você quiser saber um pouco mais sobre o tempo necessário para executar várias operações, veja
esta maravilhosa folha de dicas .
5. Expressões regulares.
Uma expressão regular (regex, regexp, regex) é uma sequência de caracteres que define um padrão de pesquisa. Por exemplo:
- . - qualquer caractere, exceto o avanço de linha;
- \ w é uma palavra;
- \ d - um dígito;
- \ s - um espaço;
- \ W é uma NÃO-Palavra;
- \ D - um não dígito;
- \ S - um não-espaço;
- [abc] - encontra qualquer um dos caracteres especificados que correspondem a qualquer um de a, b ou c;
- [^ abc] - encontra qualquer caractere, exceto os especificados;
- [ag] - localiza um caractere no intervalo de a a g.
Trecho da
documentação do
Python :
Expressões regulares usam a barra invertida (\) para indicar formas especiais ou para permitir o uso de caracteres especiais. Isso contradiz o uso da barra invertida no Python: por exemplo, para denotar literalmente a barra invertida, você deve escrever '\\\\' como um padrão de pesquisa, porque a expressão regular deve se parecer com \\ , onde cada barra invertida deve ser escapada.
A solução é usar a notação de cadeia bruta para padrões de pesquisa; as barras invertidas não serão processadas especialmente se usadas com o prefixo 'r' . Assim, r”\n” é uma sequência com dois caracteres ('\' 'n') e “\n” é uma sequência com um caractere (avanço de linha).
Podemos usar regulares para filtrar ainda mais nosso texto. Por exemplo, você pode remover todos os caracteres que não são palavras. Em muitos casos, a pontuação não é necessária e é fácil de remover com a ajuda de regulares.
O módulo
re no Python representa operações de expressão regular. Podemos usar a função
re.sub para substituir tudo o que se ajusta ao padrão de pesquisa pela string especificada. Portanto, você pode substituir todas as não palavras por espaços:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
Conclusão:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
Os regulares são uma ferramenta poderosa que pode ser usada para criar padrões muito mais complexos. Se você quiser saber mais sobre expressões regulares, recomendo esses 2 aplicativos da web:
regex ,
regex101 .
6. Saco de palavras
Os algoritmos de aprendizado de máquina não podem trabalhar diretamente com o texto bruto, portanto, você precisa converter o texto em conjuntos de números (vetores). Isso é chamado de
extração de recurso .
Um saco de palavras é uma técnica popular e simples de extração de recursos usada ao trabalhar com texto. Descreve as ocorrências de cada palavra no texto.
Para usar o modelo, precisamos:
- Defina um dicionário de palavras conhecidas (tokens).
- Escolha o grau de presença de palavras famosas.
Qualquer informação sobre a ordem ou estrutura das palavras é ignorada. É por isso que é chamado de SACO de palavras. Este modelo tenta entender se uma palavra familiar aparece em um documento, mas não sabe onde exatamente ocorre.
A intuição sugere que
documentos semelhantes tenham
conteúdo semelhante . Além disso, graças ao conteúdo, podemos aprender algo sobre o significado do documento.
Um exemplo:Considere as etapas para criar este modelo. Usamos apenas quatro frases para entender como o modelo funciona. Na vida real, você encontrará mais dados.
1. Baixar dados
Imagine que esses são nossos dados e queremos carregá-los como uma matriz:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Para fazer isso, basta ler o arquivo e dividir por linha:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
Conclusão:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2. Defina um dicionário
Coletaremos todas as palavras exclusivas de 4 frases carregadas, ignorando maiúsculas e minúsculas, pontuação e tokens de um caractere. Este será o nosso dicionário (palavras famosas).
Para criar um dicionário, você pode usar a classe CountVectorizer da biblioteca sklearn. Vá para o próximo passo.
3. Crie vetores de documentos
Em seguida, precisamos avaliar as palavras no documento. Nesta etapa, nosso objetivo é transformar o texto bruto em um conjunto de números. Depois disso, usamos esses conjuntos como entrada para o modelo de aprendizado de máquina. O método de pontuação mais simples é observar a presença de palavras, ou seja, colocar 1 se houver uma palavra e 0 se estiver ausente.
Agora podemos criar um conjunto de palavras usando a classe CountVectorizer mencionada acima.
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
Conclusão:
Estas são as nossas sugestões. Agora vemos como o modelo "saco de palavras" funciona.
Algumas palavras sobre o saco de palavras
A complexidade desse modelo é como determinar o dicionário e como contar a ocorrência de palavras.
Quando o tamanho do dicionário aumenta, o vetor do documento também aumenta. No exemplo acima, o comprimento do vetor é igual ao número de palavras conhecidas.
Em alguns casos, podemos ter uma quantidade incrivelmente grande de dados e o vetor pode consistir em milhares ou milhões de elementos. Além disso, cada documento pode conter apenas uma pequena parte das palavras do dicionário.
Como resultado, haverá muitos zeros na representação vetorial. Vetores com muitos zeros são chamados vetores esparsos, eles requerem mais memória e recursos computacionais.
No entanto, podemos reduzir o número de palavras conhecidas quando usamos esse modelo para reduzir a demanda por recursos de computação. Para fazer isso, você pode usar as mesmas técnicas que já consideramos antes de criar um conjunto de palavras:
- ignorando o caso das palavras;
- ignorando pontuação;
- ejetar palavras de parada;
- redução de palavras às suas formas básicas (lematização e stemming);
- correção de palavras com erros ortográficos.
Outra maneira mais complicada de criar um dicionário é usar palavras agrupadas. Isso redimensionará o dicionário e fornecerá mais detalhes sobre o documento. Essa abordagem é chamada de "
N-grama ".
N-grama é uma sequência de qualquer entidade (palavras, letras, números, números, etc.). No contexto dos corpos linguísticos, o N-grama é geralmente entendido como uma sequência de palavras. Um unigrama é uma palavra, um bigram é uma sequência de duas palavras, um trigrama é três palavras e assim por diante. O número N indica quantas palavras agrupadas estão incluídas no N-grama. Nem todos os N-gramas possíveis se enquadram no modelo, mas apenas os que aparecem no gabinete.
Um exemplo:Considere a seguinte frase:
The office building is open today
Aqui estão seus bigrams:
- o escritório
- edifício de escritórios
- edifício é
- está aberto
- aberto hoje
Como você pode ver, um pacote de bigrams é uma abordagem mais eficaz do que um pacote de palavras.
Avaliação (pontuação) de palavrasQuando um dicionário é criado, a presença de palavras deve ser avaliada. Já consideramos uma abordagem simples e binária (1 - existe uma palavra, 0 - não há palavra).
Existem outros métodos:
- Quantidade. É calculado quantas vezes cada palavra aparece no documento.
- Frequência É calculado com que frequência cada palavra ocorre no texto (em relação ao número total de palavras).
7. TF-IDF
A pontuação de frequência tem um problema: as palavras com a frequência mais alta têm, respectivamente, a classificação mais alta. Nessas palavras, pode não haver tanto
ganho informacional para o modelo quanto em palavras menos frequentes. Uma maneira de corrigir a situação é diminuir a pontuação da palavra, que geralmente é encontrada
em todos os documentos semelhantes . Isso é chamado de
TF-IDF .
TF-IDF (abreviação de frequência de termo - frequência inversa de documento) é uma medida estatística para avaliar a importância de uma palavra em um documento que faz parte de uma coleção ou corpus.
A pontuação pelo TF-IDF cresce proporcionalmente à frequência de ocorrência de uma palavra em um documento, mas isso é compensado pelo número de documentos que contêm essa palavra.
Fórmula de pontuação para a palavra X no documento Y:
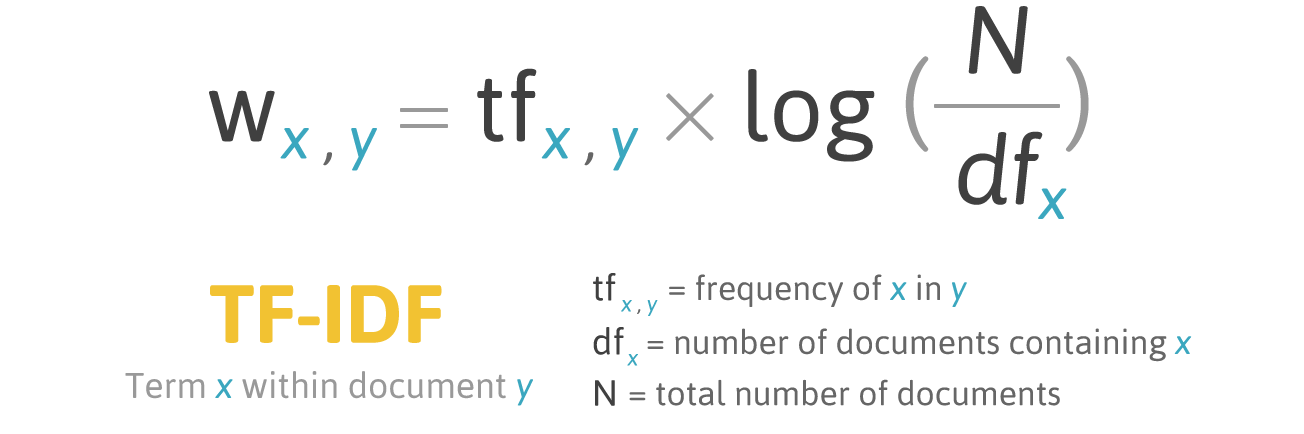 Fórmula TF-IDF. Fonte: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
Fórmula TF-IDF. Fonte: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF (termo frequência) é a razão entre o número de ocorrências de uma palavra e o número total de palavras em um documento.
IDF (frequência inversa do documento) é o inverso da frequência com que uma palavra ocorre nos documentos de coleção.
Como resultado, TF-IDF para o
termo palavra pode ser calculado da seguinte maneira:
Um exemplo:Você pode usar a classe TfidfVectorizer da biblioteca sklearn para calcular o TF-IDF. Vamos fazer isso com as mesmas mensagens que usamos no exemplo de saco de palavras.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Código:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
Conclusão:
Conclusão
Este artigo abordou os conceitos básicos da PNL para texto, a saber:
- A PNL permite o uso de algoritmos de aprendizado de máquina para texto e fala;
- NLTK (Natural Language Toolkit) - uma plataforma líder para a criação de programas de PNL em Python;
- a tokenização da proposta é o processo de dividir uma linguagem escrita em frases componentes;
- a tokenização de palavras é o processo de dividir sentenças em palavras componentes;
- A lematização e a derivação visam trazer todas as formas de palavras encontradas para uma única forma de vocabulário normal;
- palavras de parada são aquelas que são jogadas fora do texto antes / após o processamento do texto;
- regex (regex, regexp, regex) é uma sequência de caracteres que define um padrão de pesquisa;
- um pacote de palavras é uma técnica popular e simples de extração de recursos usada ao trabalhar com texto. Descreve as ocorrências de cada palavra no texto.
Ótimo! Agora que você conhece o básico da extração de recursos, pode usá-los como entrada para algoritmos de aprendizado de máquina.
Se você deseja ver todos os conceitos descritos em um grande exemplo,
aqui está você .