
Em nossos projetos, usamos a arquitetura de microsserviço. Se surgirem gargalos de desempenho, muito tempo será gasto no monitoramento e análise de logs. Ao registrar o tempo de operações individuais em um arquivo de log, geralmente é difícil entender o que levou à chamada dessas operações, rastrear a sequência de ações ou o deslocamento de tempo de uma operação em relação a outra em serviços diferentes.
Para minimizar o trabalho manual, decidimos usar uma das ferramentas de rastreamento. Sobre como e para o que é possível usar o rastreamento e como fizemos isso, discutiremos este artigo.
Quais problemas podem ser resolvidos com rastreamento
- Encontre gargalos de desempenho em um único serviço e em toda a árvore de execução entre todos os serviços participantes. Por exemplo:
- Muitas chamadas curtas e consecutivas entre serviços, por exemplo, para geocodificação ou para um banco de dados.
- Longa espera pela entrada de entrada, por exemplo, transferência de dados em uma rede ou leitura do disco.
- Análise de dados longos.
- Operações longas que exigem CPU.
- Partes de código que não são necessárias para obter o resultado final e podem ser excluídas ou executadas com atraso.
- Entenda claramente em qual sequência o que é chamado e o que acontece quando a operação é executada.
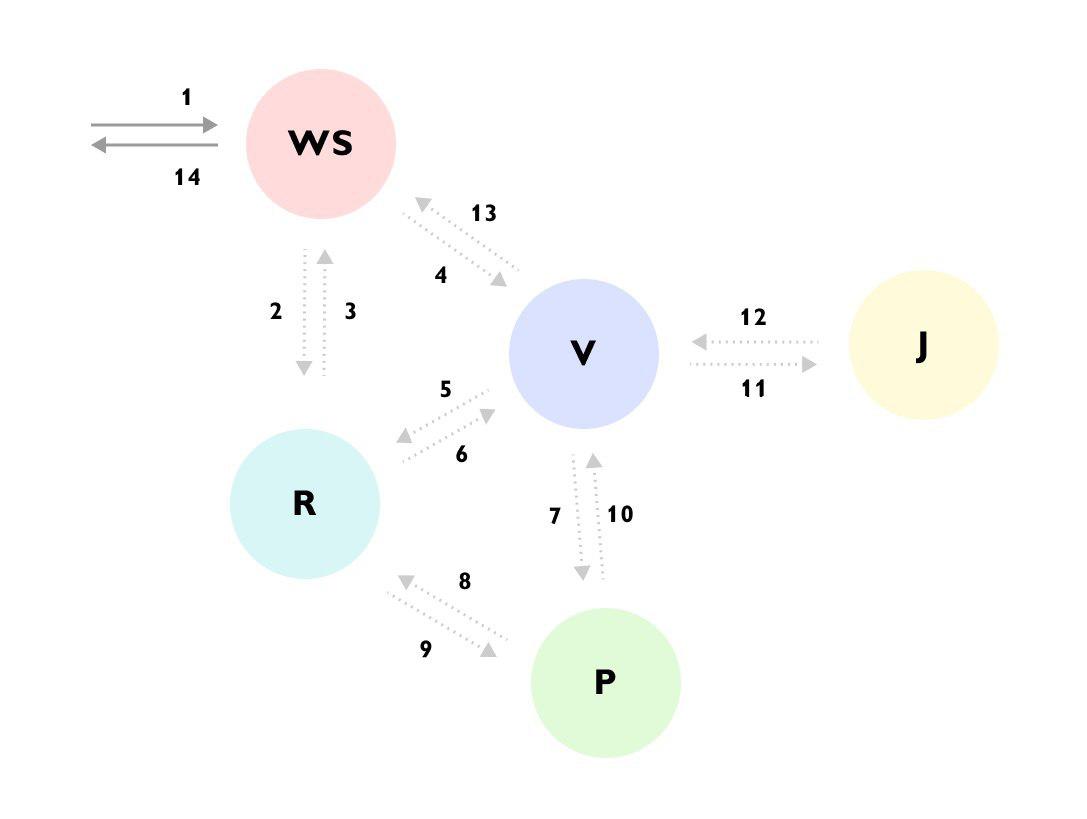
Pode-se observar que, por exemplo, a Solicitação chegou ao serviço WS -> o serviço WS suplementou os dados através do serviço R -> enviou a solicitação ao serviço V -> o serviço V carregou muitos dados do serviço R -> foi ao serviço P -> o serviço P foi desligado novamente para o serviço R -> o serviço V ignorou o resultado e foi para o serviço J -> e só então retornou a resposta ao serviço WS, enquanto continuava a calcular outra coisa em segundo plano.
Sem esse rastreamento ou documentação detalhada para todo o processo, é muito difícil entender o que está acontecendo na primeira vez em que você analisa o código, e o código está espalhado por diferentes serviços e oculto por várias caixas e interfaces.
- Coleta de informações sobre a árvore de execução para posterior análise pendente. Em cada estágio de execução, você pode adicionar informações ao rastreamento que está disponível nesse estágio e, em seguida, descobrir quais dados de entrada levaram a um cenário semelhante. Por exemplo:
- ID do usuário
- Direitos
- Tipo de método selecionado
- Erro de log ou execução
- Transforme rastreamentos em um subconjunto de métricas e mais análises como métricas.
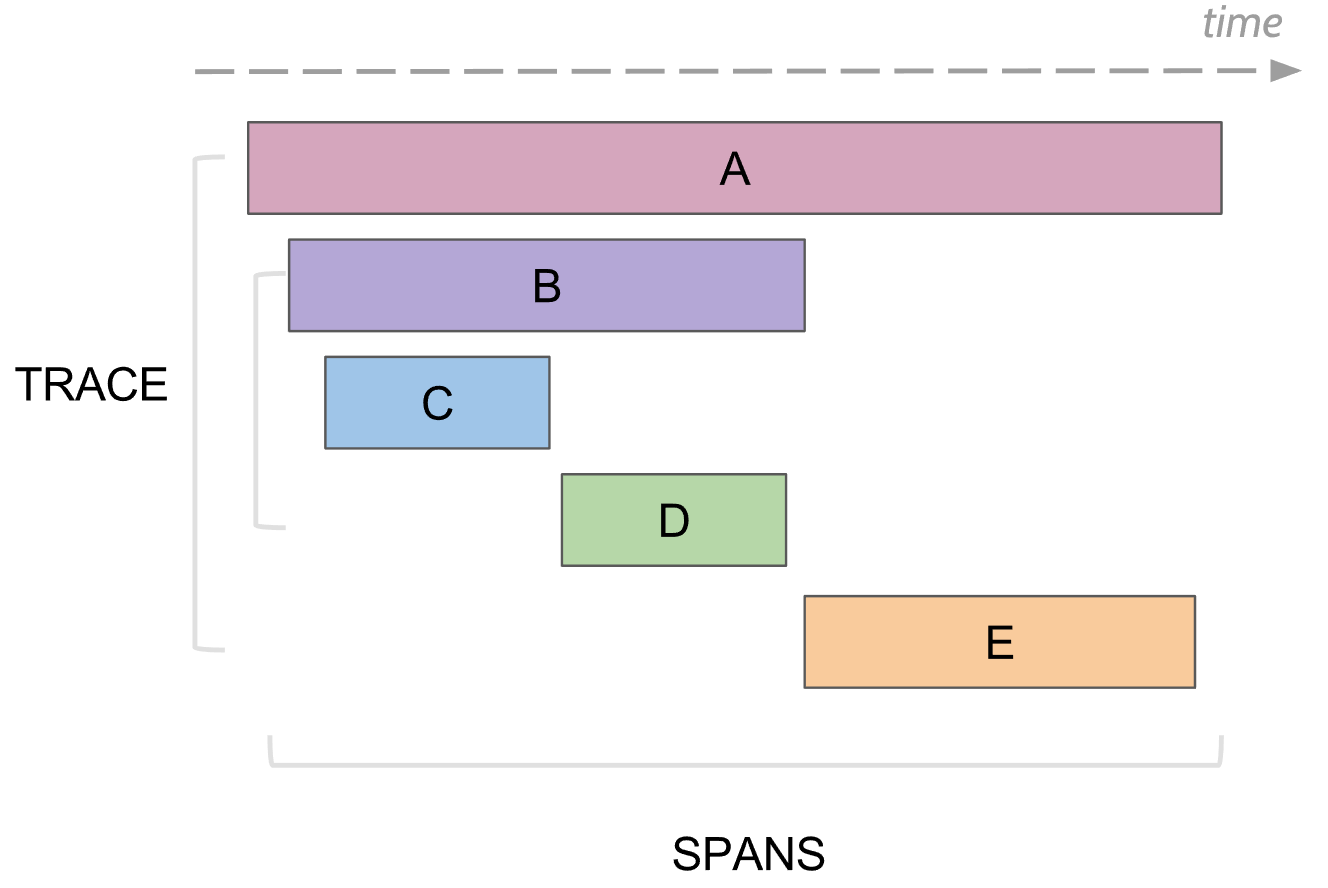
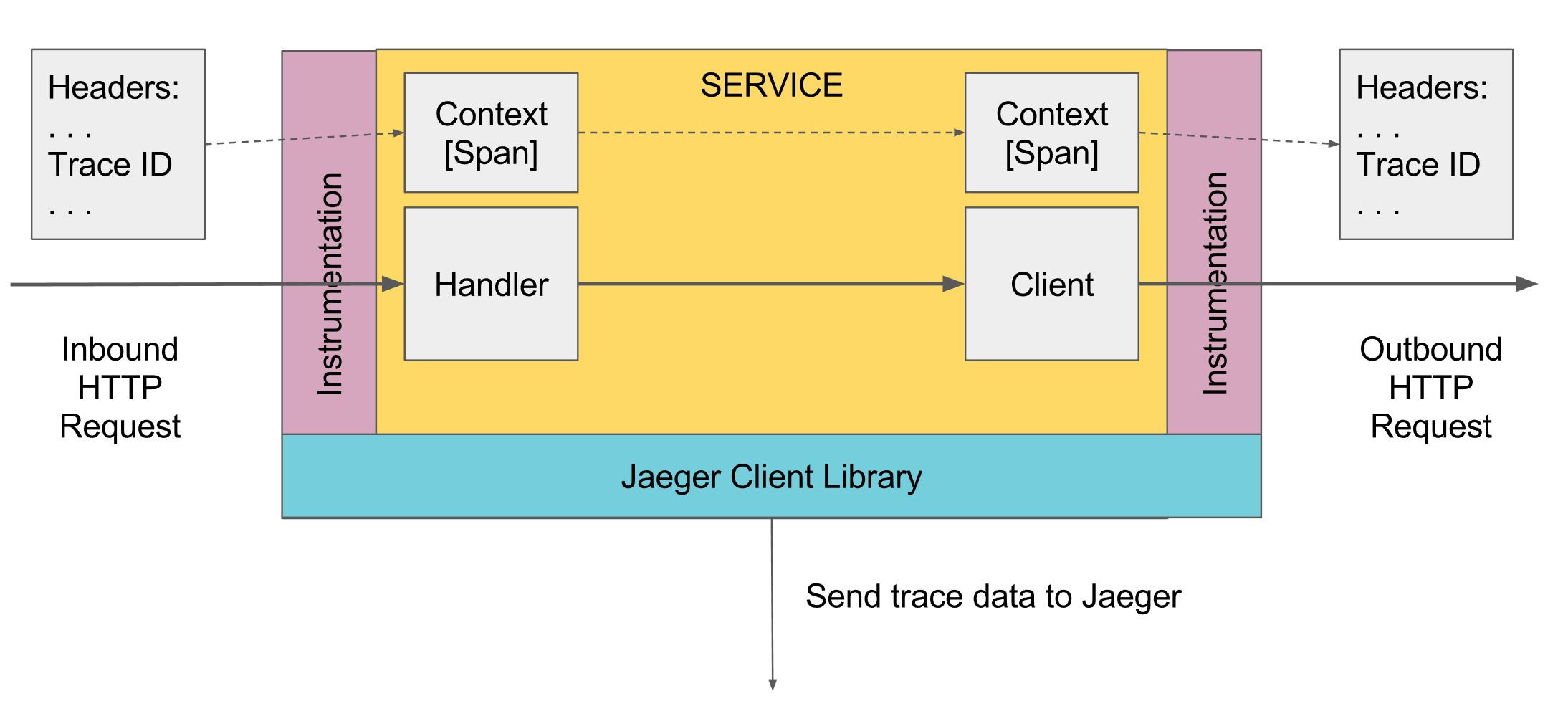
O que pode rastrear o log. Span
No rastreamento, existe o conceito de extensão, este é um análogo de um log para o console. O período possui:
- O nome, geralmente o nome do método que foi executado
- O nome do serviço no qual o período foi gerado
- ID exclusivo próprio
- Alguma informação meta na forma de chave / valor, que foi prometida a ela. Por exemplo, os parâmetros do método ou o método terminaram com um erro ou não
- Os horários de início e término desse período
- ID do período pai
Cada span é enviado ao coletor de span para salvar no banco de dados para visualização posterior assim que sua execução for concluída. No futuro, você pode construir uma árvore de todos os períodos, conectando-se pelo ID pai. Na análise, é possível encontrar, por exemplo, todos os períodos em algum serviço que levou mais de um tempo. Além disso, indo para um período específico, veja a árvore inteira acima e abaixo desse período.
Opentracing, Jagger e como a implementamos em nossos projetos
Existe um padrão geral do
Opentracing que descreve como e o que deve ser montado sem estar vinculado a uma implementação específica em qualquer idioma. Por exemplo, em Java, todo o trabalho com rastreios é feito por meio da API geral do Opentracing e, por exemplo, Jaeger ou uma implementação padrão vazia que não faz nada pode ser ocultada.
Usamos o
Jaeger como uma implementação do Opentracing. Consiste em vários componentes:
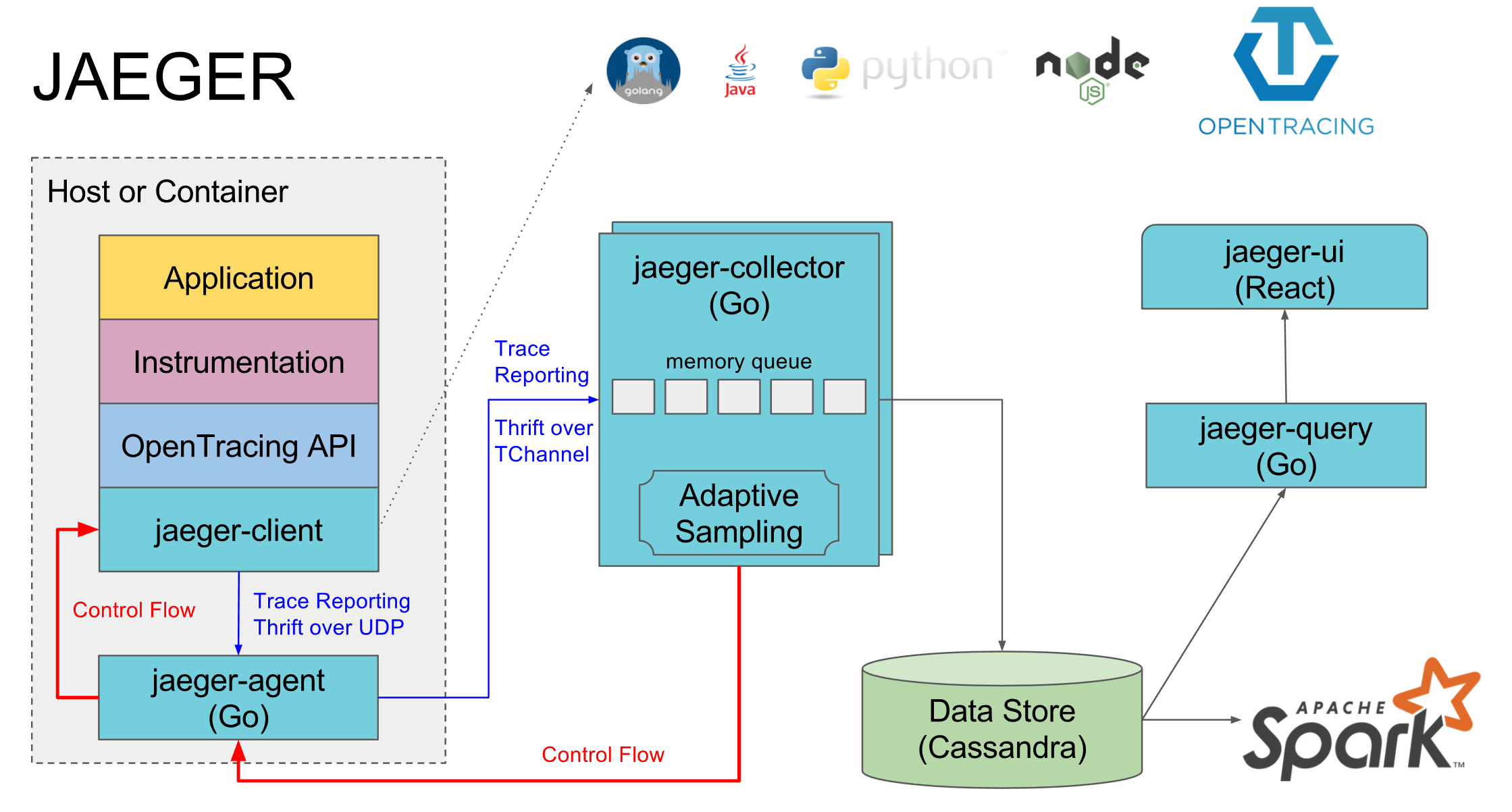
- O Jaeger-agent é um agente local que geralmente fica em cada máquina e os serviços são registrados na porta padrão local. Se não houver agente, os rastreamentos de todos os serviços nesta máquina geralmente estão desativados
- Jaeger-coletor - todos os agentes enviam rastros coletados para ele, e ele os coloca no banco de dados selecionado
- O banco de dados é sua cassandra preferida, mas usamos a elasticsearch, existem implementações para alguns outros bancos de dados e uma implementação na memória que não salva nada no disco
- Jaeger-query é um serviço que vai para o banco de dados e fornece rastreamentos já coletados para análise
- O Jaeger-ui é uma interface da web para pesquisar e visualizar rastros; ele acessa o jaeger-query
Um componente separado é a implementação do opentracing jaeger para idiomas específicos, através dos quais os spans são enviados para o jaeger-agent.
Conectar o Jagger em Java resume-se a simular a interface io.opentracing.Tracer, após a qual todos os rastreamentos passam para o agente real.
Você também pode conectar o
opentracing-spring-cloud-starter e uma implementação do Jaeger
opentracing-spring-jaeger-cloud-starter, que configura o rastreio automático para tudo o que passa por esses componentes, por exemplo, solicitações HTTP para controladores, solicitações de banco de dados via jdbc etc.
Rastreando o log em Java
Em algum lugar no nível mais alto, o primeiro Span deve ser criado, isso pode ser feito automaticamente, por exemplo, pelo controlador de mola quando uma solicitação é recebida ou manualmente, se não houver. Além disso, é transmitido através do escopo abaixo. Se algum método abaixo quiser adicionar Span, ele pega o activeSpan atual do Scope, cria um novo Span e diz que seu pai recebeu activeSpan e ativa o novo Span. Quando serviços externos são chamados, o período ativo atual é transferido para eles e esses serviços criam novos períodos com referência a esse período.
Todo o trabalho passa pela instância do Tracer, você pode obtê-lo pelo mecanismo de DI ou GlobalTracer.get () como uma variável global se o mecanismo de DI não funcionar. Por padrão, se o rastreador não foi inicializado, o NoopTracer retornará, o que não fará nada.
Além disso, o escopo atual é obtido do rastreador via ScopeManager, um novo escopo é criado a partir do atual com a ligação do novo período e, em seguida, o escopo criado é fechado, o que fecha o período criado e retorna o escopo anterior ao estado ativo. O escopo está vinculado a um fluxo, portanto, quando a programação multiencadeada, não se esqueça de transferir o período ativo para outro fluxo, para ativação adicional do Escopo de outro fluxo com referência a esse período.
io.opentracing.Tracer tracer = ...;
Para a programação multithread, também existe um TracedExecutorService e wrappers semelhantes que encaminham automaticamente o período atual para o fluxo ao iniciar tarefas assíncronas:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
Para solicitações http externas, existe
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
Os problemas que estamos enfrentando
- Beans e DI nem sempre funcionam se o rastreador não for usado em um serviço ou componente; o Autowired Tracer pode não funcionar e você terá que usar o GlobalTracer.get ().
- As anotações não funcionam se não for um componente ou serviço ou se uma chamada de método vier de um método vizinho da mesma classe. Você precisa ter cuidado, verificar o que funciona e usar a criação manual do rastreio se @Traced não funcionar. Você também pode danificar um compilador adicional para anotações em java; elas devem funcionar em qualquer lugar.
- Na antiga mola e bota de mola, a configuração automática da nuvem de mola opentraing não funciona devido a erros no DI; se você quiser que os rastreamentos nos componentes da mola funcionem automaticamente, faça isso por analogia com github.com/opentracing-contrib/java-spring-jaeger/blob/ master / opentracing-spring-jaeger-starter / src / main / java / io / opentracing / contrib / java / spring / jaeger / starter / JaegerAutoConfiguration.java
- Tente com recursos não funciona no groovy, você deve usar o try finalmente.
- Cada serviço deve ter seu próprio nome spring.application.name sob o qual os rastreamentos serão registrados. O que faz um nome separado para venda e teste, para não interferir com eles juntos.
- Se você usar o GlobalTracer e o tomcat, todos os serviços em execução neste tomcat terão um GlobalTracer, portanto todos terão o mesmo nome de serviço.
- Ao adicionar rastreamentos a um método, você precisa ter certeza de que ele não é chamado no loop muitas vezes. É necessário adicionar um rastreamento comum para todas as chamadas, o que garante o tempo total de trabalho. Caso contrário, excesso de carga será criado.
- Uma vez em jaeger-ui, fizeram pedidos muito grandes para um grande número de rastreamentos e, como não esperaram por uma resposta, fizeram-no novamente. Como resultado, o jaeger-query começou a consumir muita memória e desacelerar o elástico. Ajudou a reiniciar o jaeger-query
Amostragem, armazenamento e visualização de traços
Existem três tipos de
amostragem de
rastreio :
- Const que envia e salva todos os rastreamentos.
- Probabilístico que filtra traços com certa probabilidade.
- Limitação de taxa que limita o número de rastreamentos por segundo. Você pode configurar essas opções no cliente, no jaeger-agent ou no coletor. Agora, temos const 1 na pilha de avaliadores, pois não há muitas solicitações, mas elas levam muito tempo. No futuro, se isso exercer uma carga excessiva no sistema, você poderá limitá-la.
Se você usar o cassandra, por padrão, ele armazenará rastreamentos em apenas dois dias. Usamos
elasticsearch e os rastreamentos são armazenados o tempo todo e não são excluídos. Um índice separado é criado para cada dia, por exemplo, jaeger-service-2019-03-04. No futuro, você precisará configurar a limpeza automática de rastreamentos antigos.
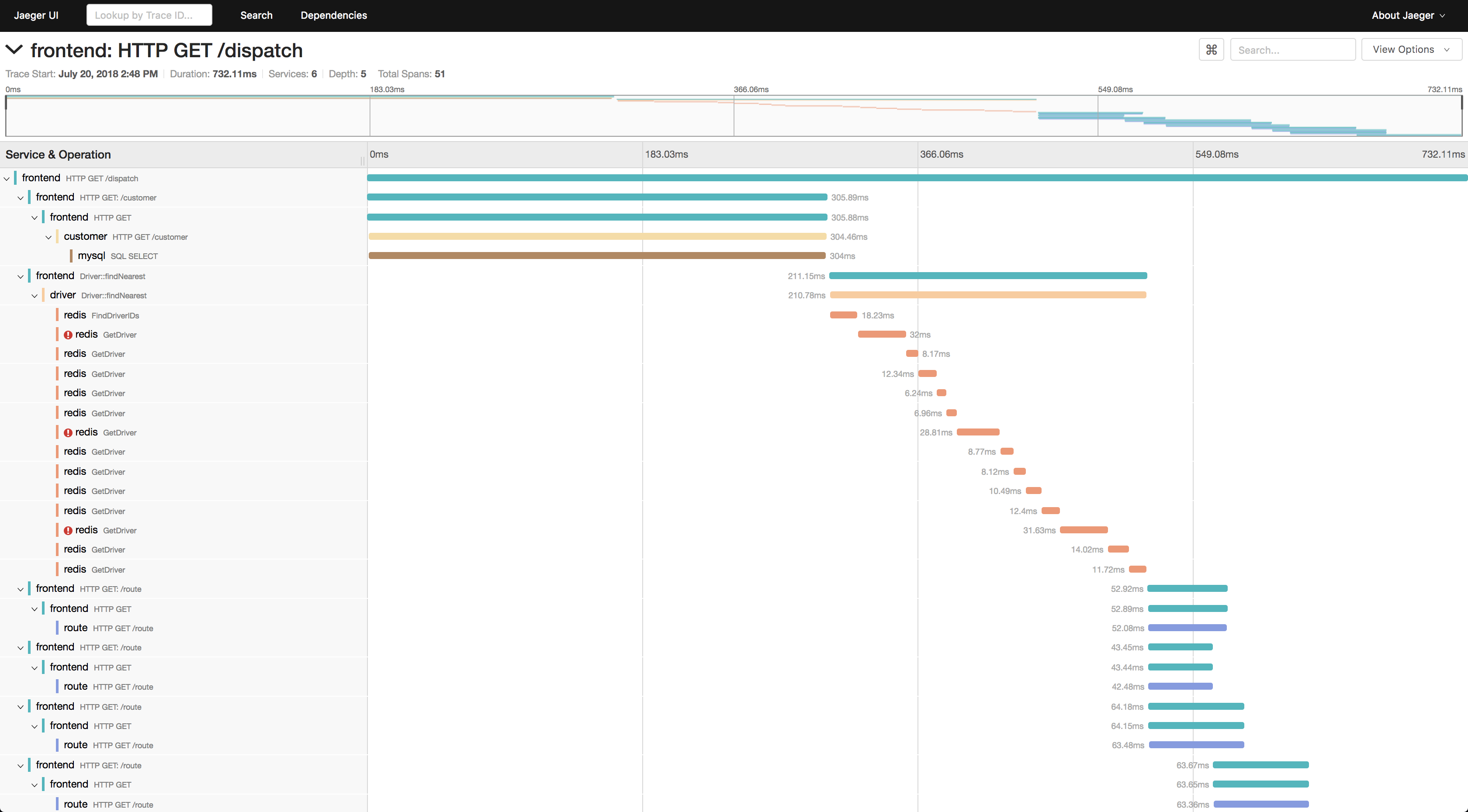
Para assistir aos cursos, você precisa:
- Escolha um serviço pelo qual deseja filtrar os rastreamentos, por exemplo tomcat7-default para um serviço que está sendo executado em um tomate e não pode ter um nome.
- Em seguida, selecione a operação, o intervalo de tempo e o tempo mínimo de operação, por exemplo, de 10 segundos, para fazer apenas longas tiragens.
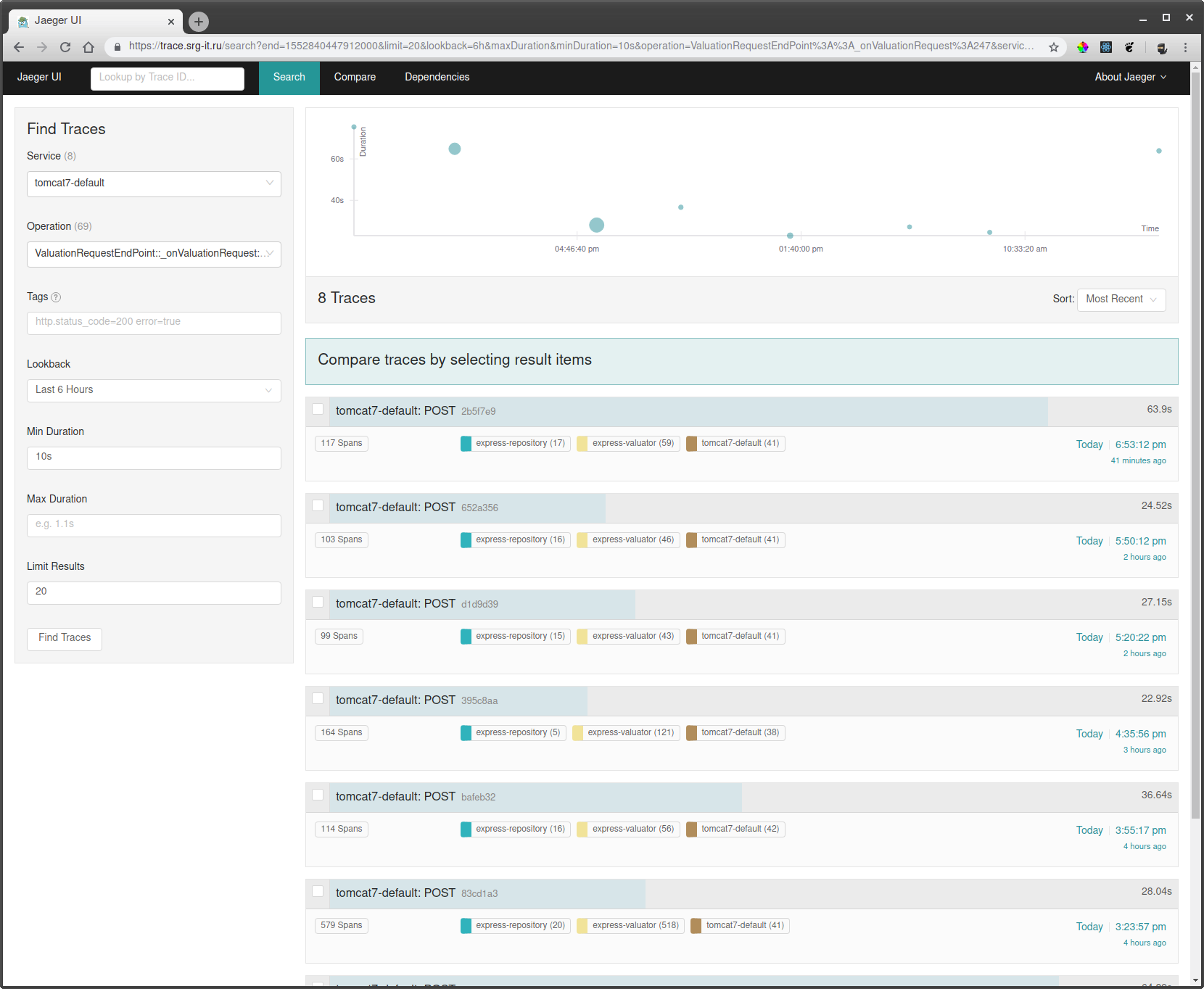
- Vá para uma das faixas e veja o que estava desacelerando por lá.

Além disso, se algum ID da solicitação for conhecido, você poderá encontrar um rastreamento por esse ID através de uma pesquisa de tag, se esse ID estiver registrado no período do rastreamento.
A documentação
Artigos
Vídeo