Habr, olá!
Muitas pessoas não sabem como trabalhar com tendências na Internet, onde procurá-las. Antes de iniciar um negócio, eles não sabem onde ver se esse negócio será popular e se é necessário. Portanto, vou escrever um tutorial completo para fechar todas as perguntas sobre este tópico.
Trabalharemos com um serviço especial para coletar consultas de pesquisa de usuários do Yandex pelo
Wordstat , cuja interface é bastante simples e compreensível:
No começo, de acordo com a tradição, estabelecerei metas:
- Compreenda toda a funcionalidade e aprenda a trabalhar com o Wordstat;
- Como coletar semântica com relevância máxima e CTR> 50%;
- Como estamos no Habré, trabalharemos diretamente com a API do Wordstat.
O papel principal do serviço reside no fato de ajudar a avaliar o interesse do usuário em tendências, vários tópicos e selecionar palavras-chave para publicidade contextual.
Familiaridade com o serviço
Para começar a usar o
Wordstat , precisamos fazer login na sua conta Yandex:

Após a autorização, podemos usar o serviço. A visualização de dados de consultas de pesquisa está disponível para nós na guia "De acordo com":
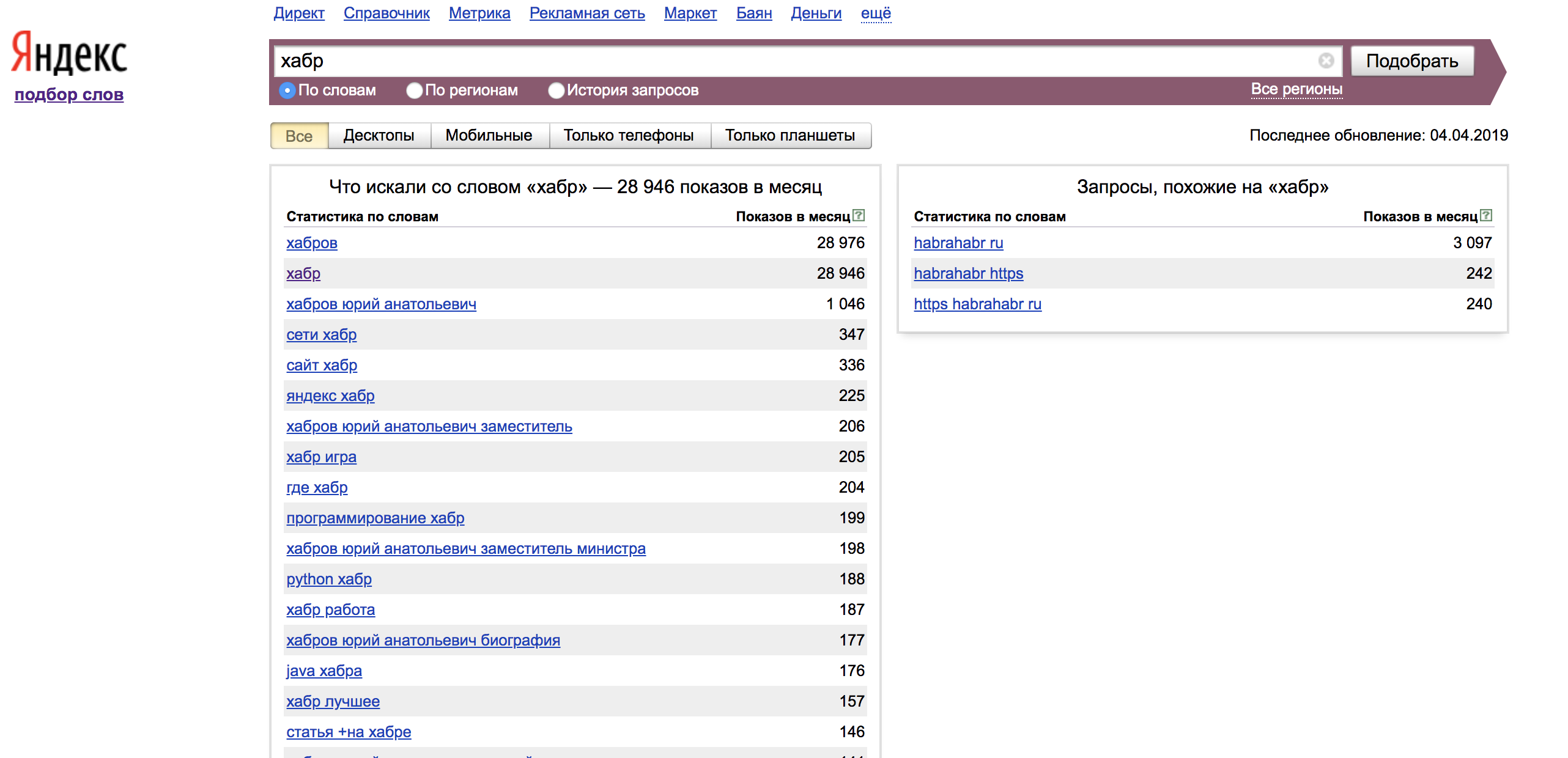
Na coluna da esquerda, vemos estatísticas das palavras
que acompanharam sua consulta de pesquisa e impressões por mês para elas. Para encontrarmos nossa palavra em correspondência exata, precisamos usar
operadores . Na coluna da direita, consultas de significado semelhantes são mostradas para a frase que definimos.
Um bom exemplo de uso de palavras-chave com operadores:
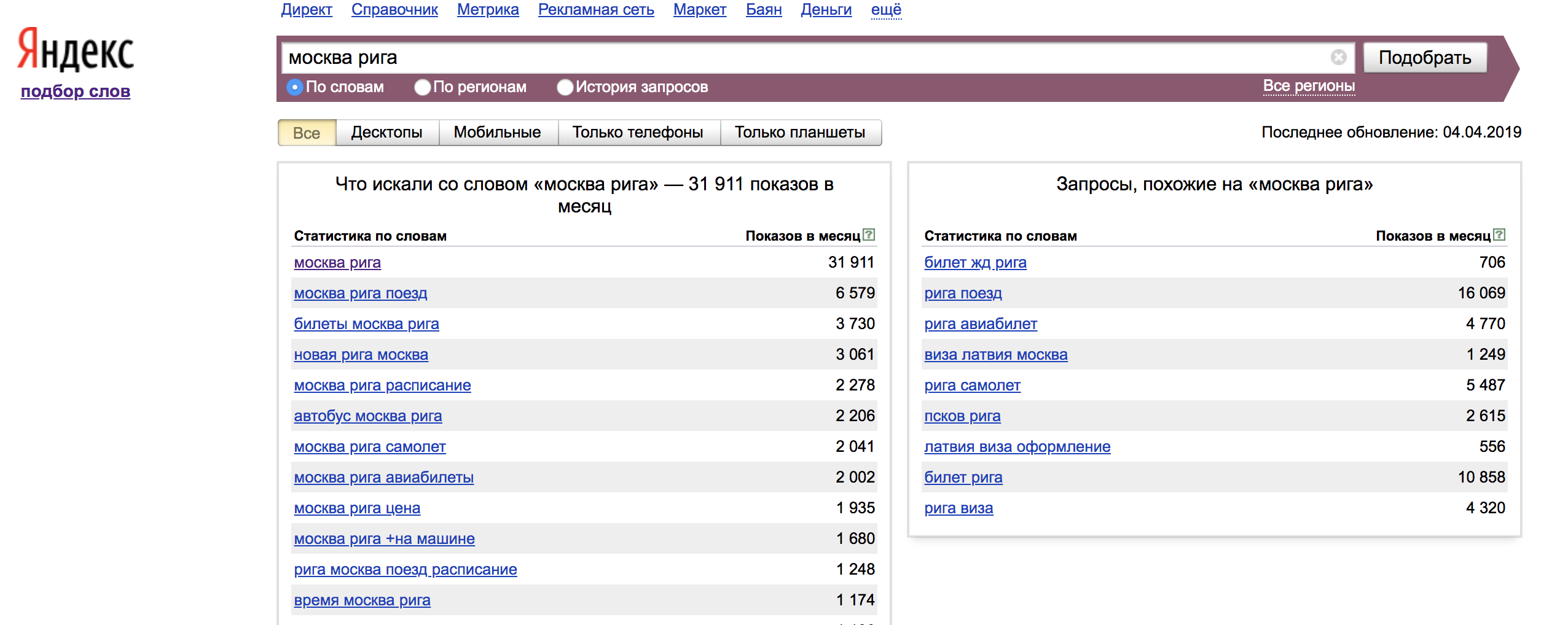
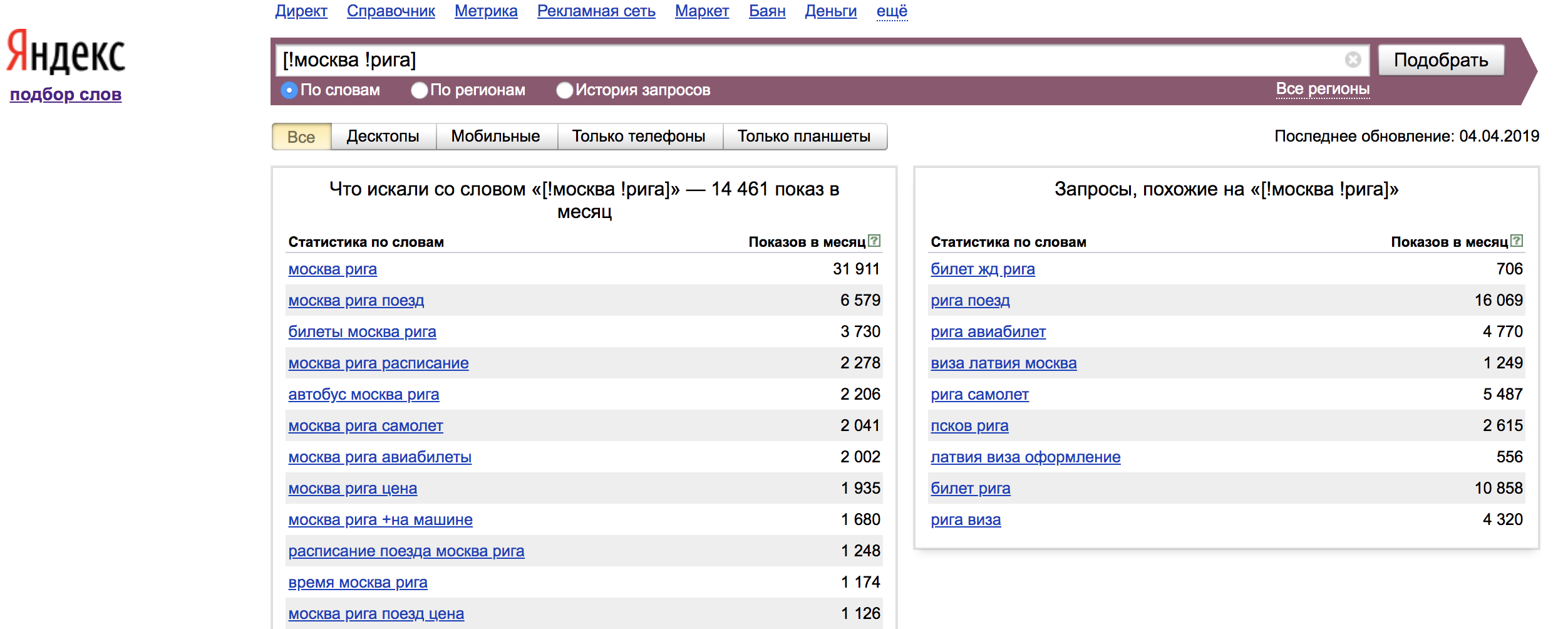
O operador "!" - corrige a forma da palavra (número, caso, hora);

Operador "[]" - corrige a ordem das palavras. Nesse caso, todas as formas de palavras e palavras de parada são consideradas.
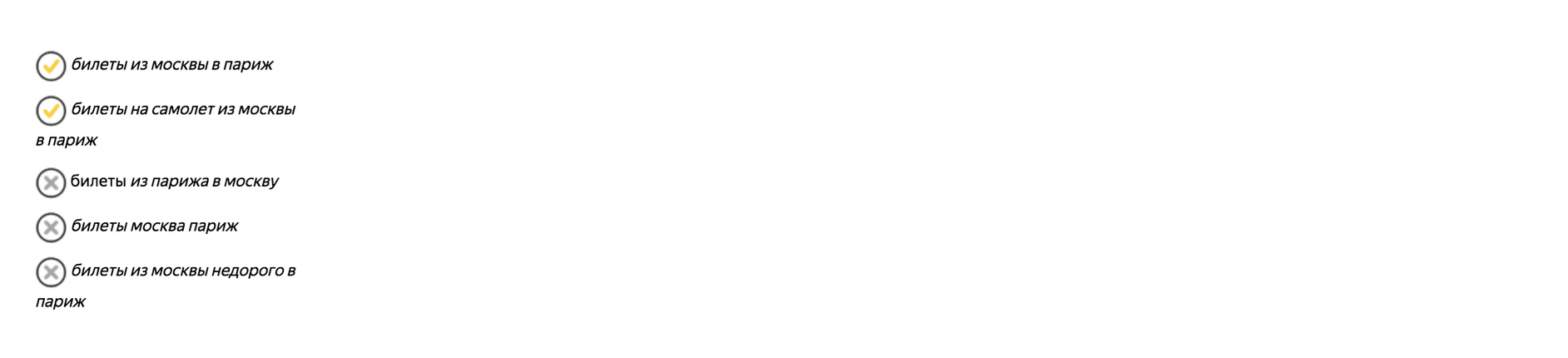
Leia mais sobre operadores
aqui .
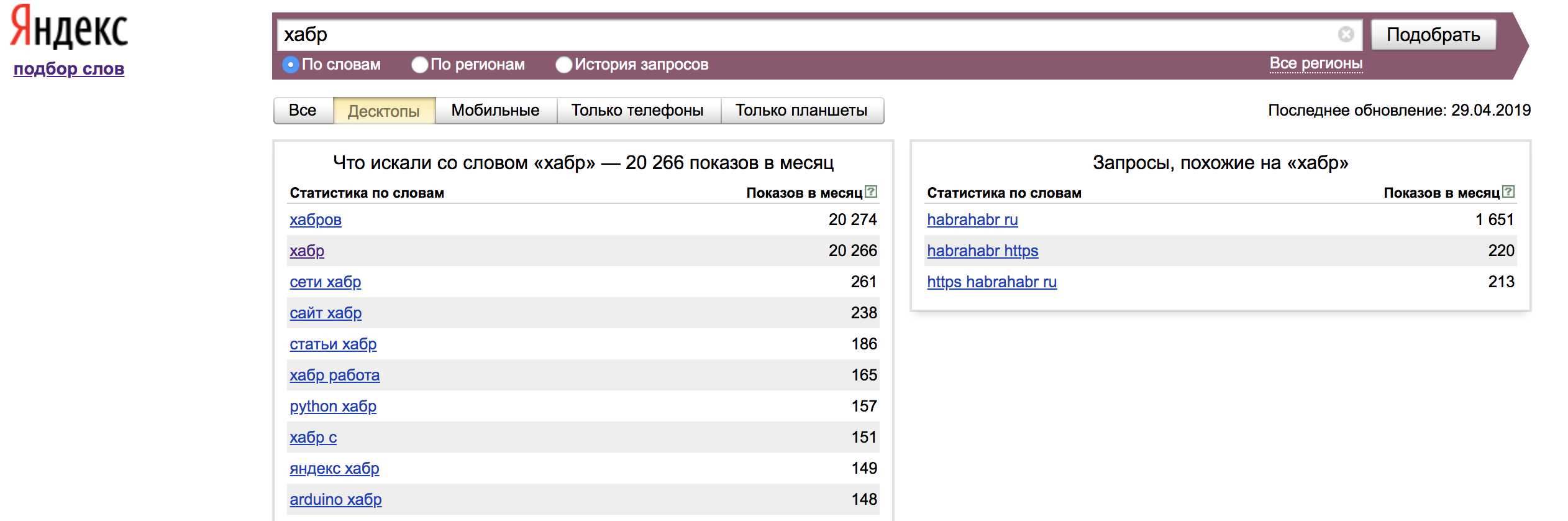
Por padrão, o Wordstat mostra solicitações para todos os tipos de dispositivos. As configurações podem ser alteradas: somente desktop / celular / telefones / tablets. No nosso caso, apenas filtramos os desktops.
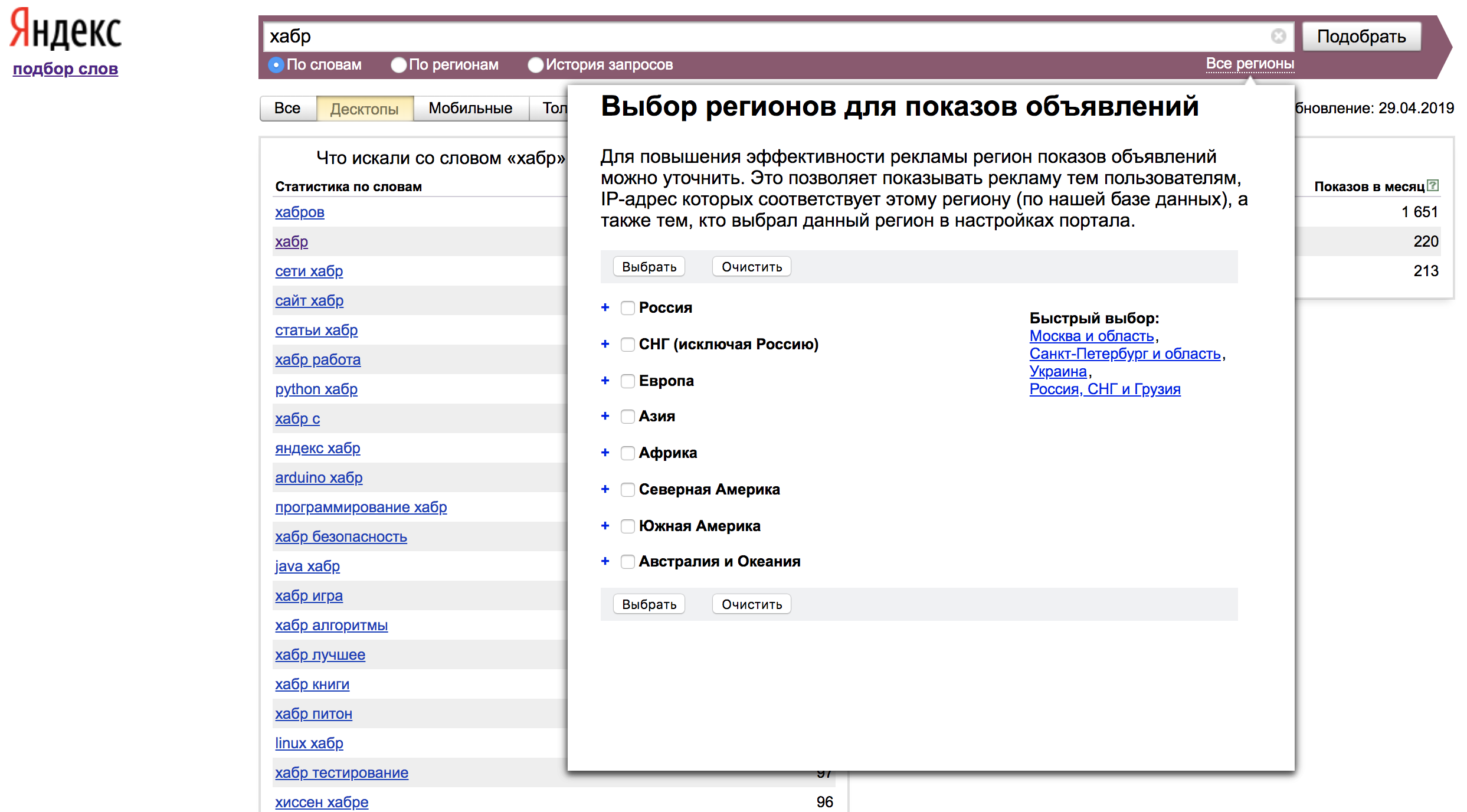
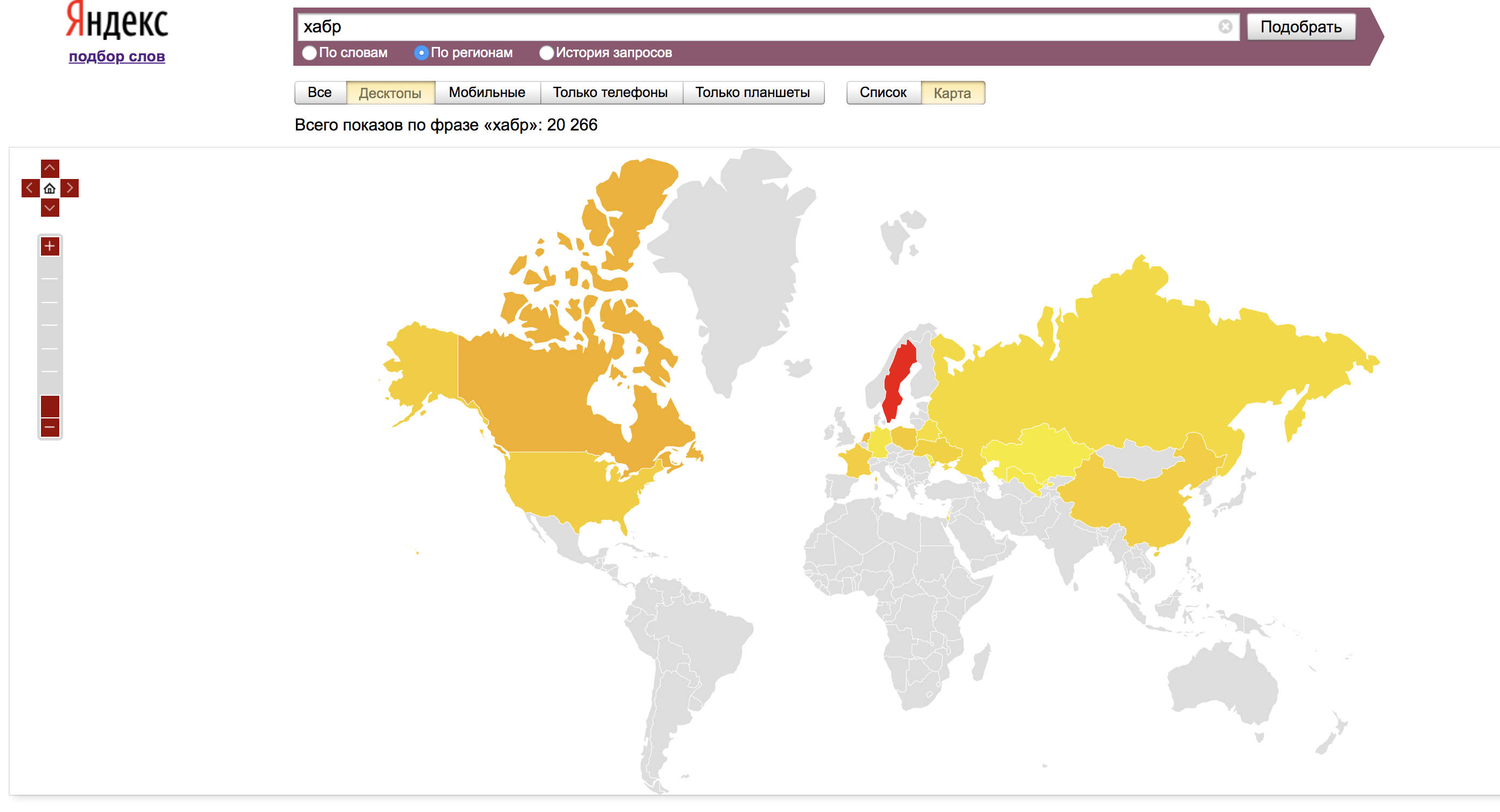
Por padrão, as estatísticas são mostradas para todas as regiões. Você pode optar por exibir estatísticas da região de interesse para nós na guia "Todas as regiões":
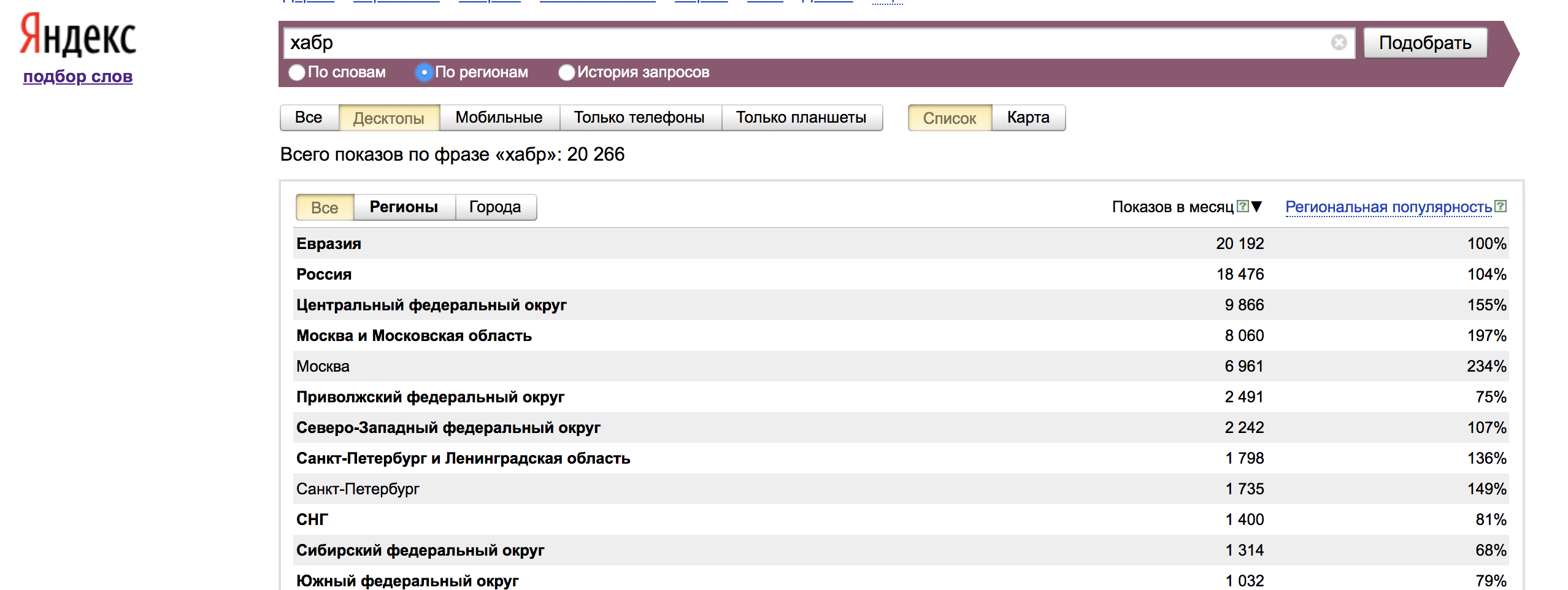
A guia "Por região" exibe dados de todas as regiões, bem como a popularidade regional - o compartilhamento que a região ocupa nas impressões por palavra dividido pelo compartilhamento de todas as impressões dos resultados de pesquisa atribuíveis a essa região.
Por conveniência, os mesmos dados são exibidos no mapa:
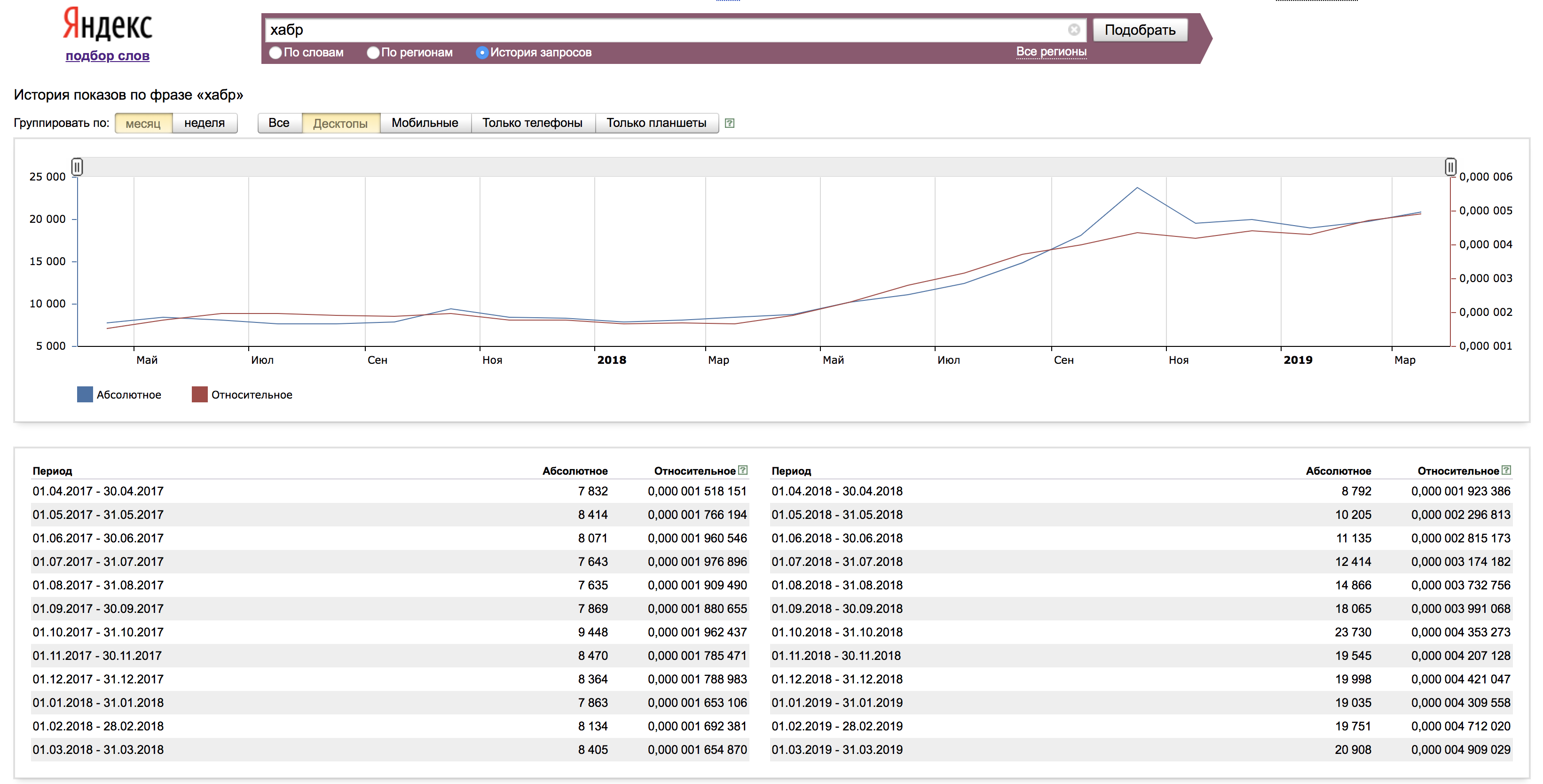
Na guia "Histórico da consulta", vemos dados sobre a solicitação, geralmente por 1,5 anos. Aqui podemos avaliar claramente as tendências e sua influência em determinadas solicitações.
As estatísticas podem ser visualizadas tanto em valores absolutos quanto em valores relativos. Para obter um valor relativo, o valor absoluto é normalizado para o número de impressões dos resultados da pesquisa Yandex no mês correspondente.
Neste estudo de ferramentas, você pode finalizar e prosseguir para nosso próximo objetivo - a coleta correta do núcleo semântico.
A coleção correta do núcleo semântico
Na Internet, muitos serviços e métodos para coletar o núcleo semântico, bem como sua criação artificial. Não criaremos uma bicicleta e dançaremos com um pandeiro, mas coletaremos a semântica de maneira fácil, simples e gratuita.
Para coletar nossa semântica, a primeira coisa que fazemos é baixar a versão mais recente do site oficial do Yandex, o Yandex
Direct Commander .
Após o download, execute o programa, faça o login e crie (independentemente do nome) a campanha:
Adicione um grupo de anúncios (ainda não faz sentido se preocupar com o nome):
Vá para a aba "Seleção de frase" e pronto! É o mesmo Wordstat, apenas no programa Direct Commander. A lógica de trabalhar com ele é a mesma, apenas ao contrário da versão web do Wordstat, aqui podemos indicar imediatamente menos palavras:
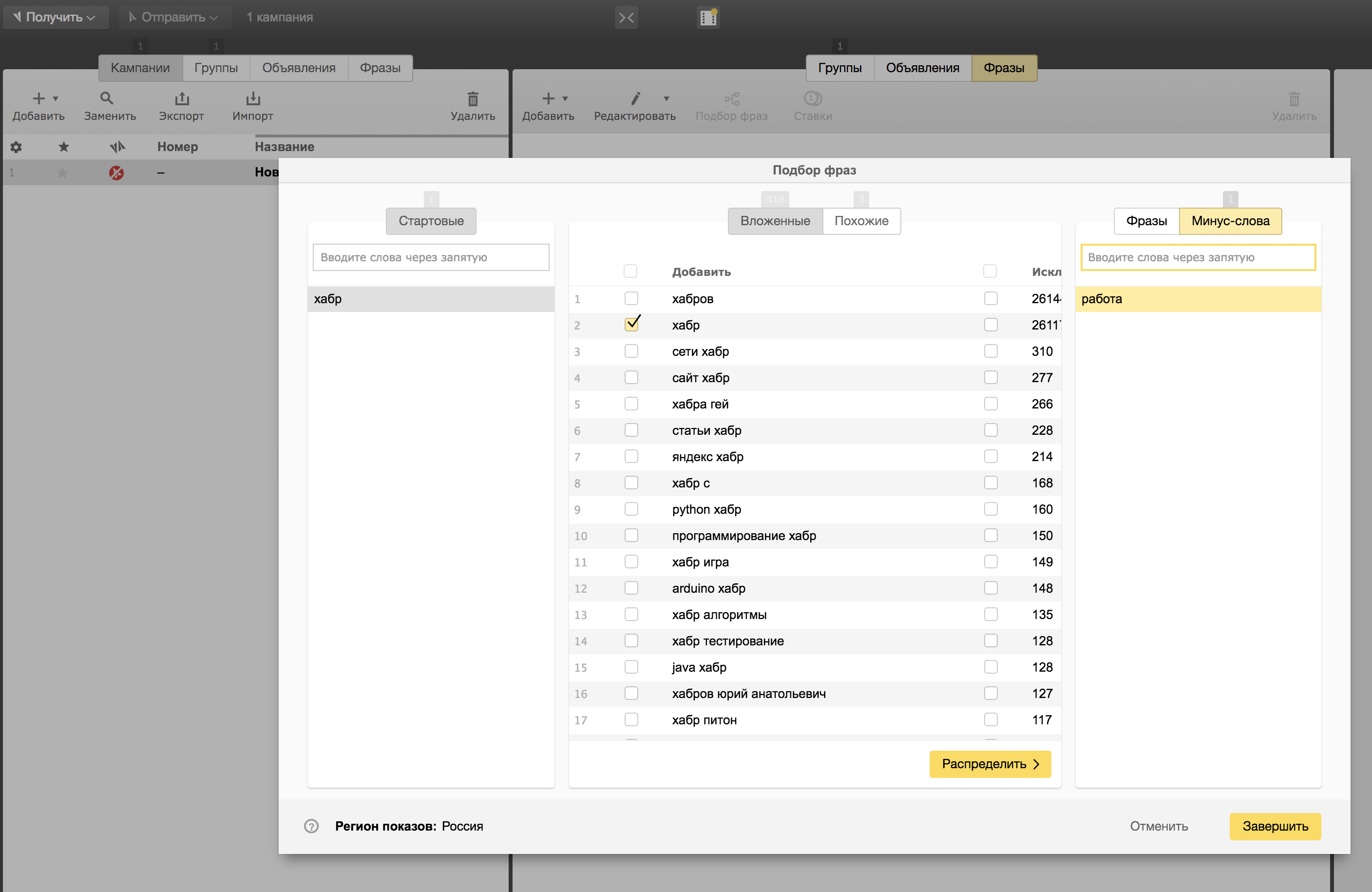
Depois de filtrar cuidadosamente
toda a lista de consultas
de pesquisa de consultas desnecessárias, podemos continuar exportando nossa campanha para um arquivo csv. Tudo o que resta a fazer é remover as colunas extras. Nosso núcleo semântico está na coluna "Frase (com palavras-chave negativas)":
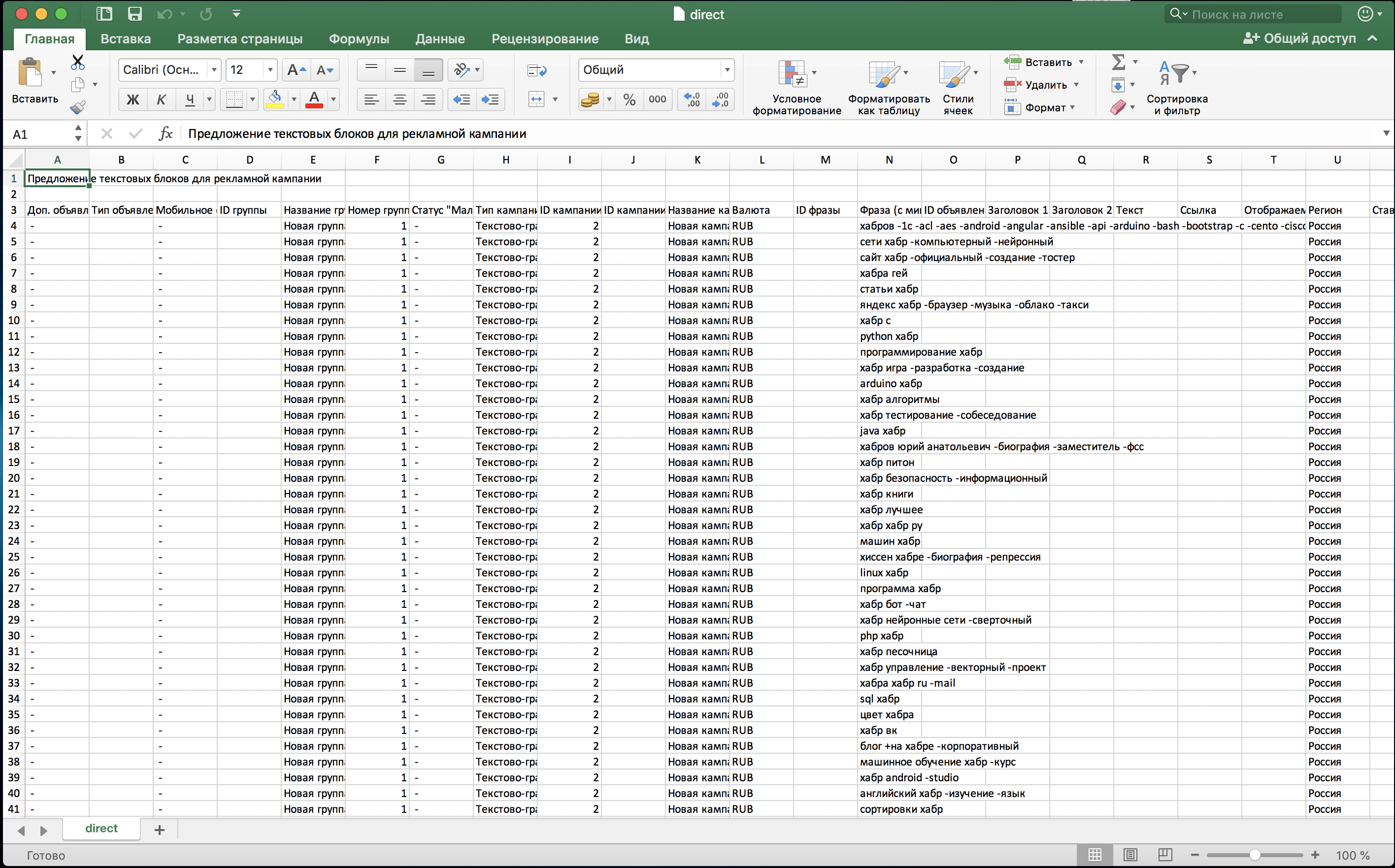
As vantagens de coletar semântica desta maneira:
- Cobertura de solicitações com frequência de até 1 por mês;
- Não estamos construindo semânticas artificiais, nas quais provavelmente haverá consultas que realmente não existem no histórico real de pesquisas;
- Aumentamos a CTR dos anúncios o máximo possível (é claro, não apenas por causa da semântica, mas também pela divisão adequada dos anúncios em grupos de solicitações e seus textos. No entanto, tudo isso é baseado em nossa semântica);
- Os cliques estão ficando mais baratos para nós;
- É absolutamente grátis.
Trabalhar com a API do Wordstat
Antes de começar, conheceremos as informações básicas da Ajuda do Yandex.Direct.
Referência da API do Wordstat
Descrição dos parâmetrosParâmetros GET Necessários
request - Solicitar dados
Parâmetros GET
lr - código da região, se 0 - todas as regiões
imp - se 1 - então um pedido importante
A resposta contémstatus - Código de status (0 - sem erros)
err_msg - Texto do erro
dados - impressões por mês
Para indicar a região, os códigos do Yandex são usados. Baixe a lista de regiões
pelo link<?php $array = array(); $array["user"] = '#_'; $array["password"] = '123456'; $array["lr"] = "1"; $array["imp"]=1; $array["request"] = ""; $content = file_get_contents("#url_user_auth".http_build_query($array)); $json = json_decode($content); if( !is_object($json) ){ echo ' '; exit(); } if($json->status!=0){ echo $json->err_msg; exit; } echo $json->data . " . "; ?>
Resultado:
{"Status": 0, "err_msg": "OK", "dados": "11284", "date_update": "29/04/2019"}
Com isso, todos os objetivos que estabelecemos no final do artigo foram alcançados.
Todo conhecimento!