
Olá pessoal! Com este artigo, o AERODISK abre um blog sobre Habré. Viva, camaradas!
Em artigos anteriores sobre o Habr, foram consideradas questões sobre a arquitetura e a configuração básica dos sistemas de armazenamento. Neste artigo, consideraremos uma pergunta que não foi abordada anteriormente, mas que frequentemente foi perguntada sobre a tolerância a falhas dos sistemas de armazenamento do AERODISK ENGINE. Nossa equipe fará tudo para que o sistema de armazenamento AERODISK pare de funcionar, ou seja, quebrando ela.
Acontece que artigos sobre a história da nossa empresa, sobre nossos produtos, bem como um exemplo de implementação bem-sucedida, já estão presentes na Habré, pelos quais muitos agradecem aos nossos parceiros - empresas TS Solution e Softline.
Portanto, não treinarei habilidades de gerenciamento de copiar e colar aqui, mas simplesmente fornecer links para os originais destes artigos:
Eu também quero compartilhar as boas notícias. Mas vou começar, é claro, com o problema. Nós, como jovens fornecedores, entre outros custos, enfrentamos o tempo todo o fato de que muitos engenheiros e administradores são brega, não sabem como operar adequadamente nossos sistemas de armazenamento.
É claro que o gerenciamento da maioria dos sistemas de armazenamento parece aproximadamente o mesmo do ponto de vista do administrador, mas cada fabricante tem suas próprias características. E não somos exceção.
Portanto, para simplificar a tarefa de treinar profissionais de TI, decidimos dedicar este ano à educação gratuita. Para fazer isso, em muitas grandes cidades da Rússia, estamos abrindo uma rede de Centros de Competência AERODISK nos quais qualquer especialista técnico interessado poderá fazer um curso totalmente gratuito e receber um certificado de administração de armazenamento do AERODISK ENGINE.
Em cada Competence Center, instalaremos um suporte de demonstração completo do sistema de armazenamento AERODISK e um servidor físico no qual nosso professor realizará o treinamento em período integral. Publicaremos a programação dos Centros de Competência assim que aparecerem, mas agora abrimos um centro em Nizhny Novgorod e a cidade de Krasnodar é a próxima da fila. Você pode se inscrever para o treinamento usando os links abaixo. Trago as informações atualmente conhecidas sobre cidades e datas:
- Nizhny Novgorod (JÁ TRABALHA - você pode se registrar aqui https://aerodisk.promo/nn/ );
Até 16 de abril de 2019, você pode visitar o centro a qualquer momento e, em 16 de abril de 2019, será organizado um grande curso de treinamento. - Krasnodar (EM BREVE - inscreva-se aqui https://aerodisk.promo/krsnd/ );
De 9 a 25 de abril de 2019, você pode visitar o centro a qualquer momento e, em 25 de abril de 2019, será organizado um grande curso de treinamento. - Ecaterimburgo (EM BREVE ABERTURA, siga as informações em nosso site ou em Habré);
Maio a junho de 2019. - Novosibirsk (siga as informações em nosso site ou em Habré);
Outubro 2019 - Krasnoyarsk (siga as informações em nosso site ou em Habré);
Novembro 2019
E, é claro, se Moscou não está longe de você, a qualquer momento você pode visitar nosso escritório em Moscou e receber treinamento semelhante.
Só isso. Amarrado ao marketing, vá para a técnica!
Na Habré, publicaremos regularmente artigos técnicos sobre nossos produtos, testes de estresse, comparações, recursos de uso e implementações interessantes.
AERODISK ENGINE N2 Testes de colisão com armazenamento, Teste de força
ACHTUNG! Depois de ler o artigo, você pode dizer: bem, é claro, o fornecedor verificará a si próprio para que tudo funcione "estrondosamente", condições de efeito estufa, etc. Eu vou responder: nada disso! Ao contrário de nossos concorrentes estrangeiros, estamos aqui, perto de você, e você sempre pode vir até nós (em Moscou ou em qualquer Comitê Central) e testar nosso sistema de armazenamento de qualquer maneira. Portanto, não fazemos muito sentido ajustar os resultados à imagem ideal do mundo, porque somos muito fáceis de verificar. Para quem tem preguiça de andar e não tem tempo, podemos organizar testes remotos. Temos um laboratório especial para isso. Contato.
ACHTUNG-2! Este teste não é um teste de carga porque aqui estamos preocupados apenas com a tolerância a falhas. Dentro de algumas semanas, prepararemos uma posição mais poderosa e realizaremos testes de carga dos sistemas de armazenamento, publicando os resultados aqui (a propósito, os desejos de testes são aceitos).
Então, vamos quebrar.
Suporte de teste
Nosso suporte consiste no seguinte ferro:
- 1 x armazenamento Aerodisk Engine N2 (2 controladores, cache de 64 GB, portas 8xFC 8Gb / s, 4x portas Ethernet 10Gb / s SFP +, 4x portas Ethernet 1Gb / s); Os seguintes discos estão instalados no sistema de armazenamento:
- 4 x disco SSD SAS de 900 GB;
- 12 x SAS 10k drives 1,2 TB;
- 1 x servidor físico com Windows Server 2016 (2xXeon E5 2667 v3, 96GB RAM, portas 2xFC 8Gb / s, 2x portas Ethernet 10Gb / s SFP +);
- 2 x switch SAN 8G;
- 2 x switch LAN 10G;
Conectamos o servidor ao armazenamento via comutadores via FC e Ethernet 10G. Esquema do estande abaixo.
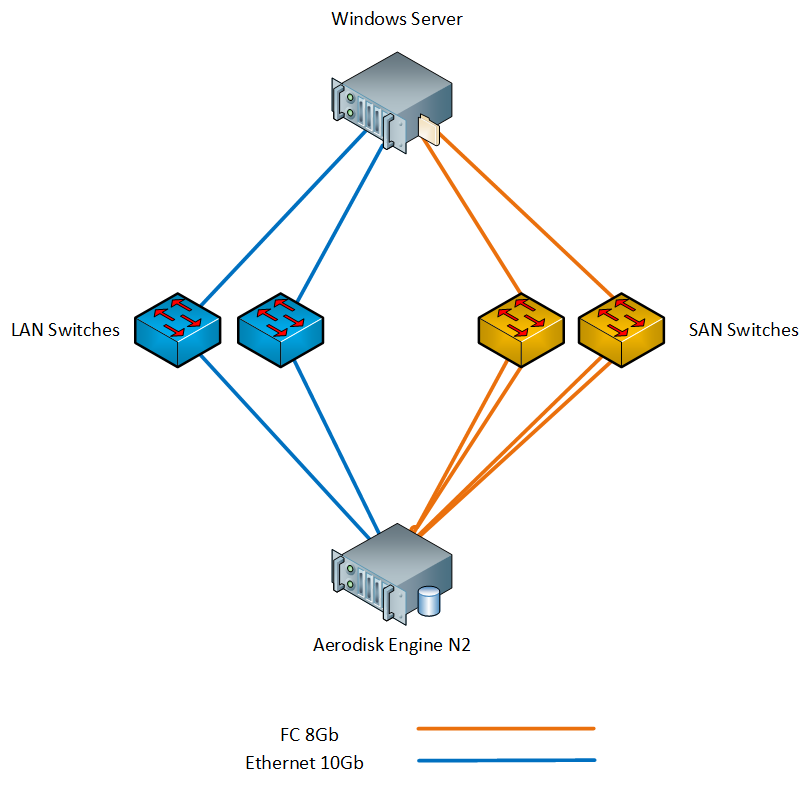
Os componentes necessários, como o iniciador MPIO e iSCSI, estão instalados no Windows Server.
As zonas são configuradas nos comutadores FC, as VLANs correspondentes são configuradas nos comutadores LAN e o MTU 9000 é instalado nas portas, comutadores e host de armazenamento (como fazer tudo isso é descrito em nossa documentação, portanto, não descreveremos esse processo aqui).
Metodologia de teste
O plano de teste de colisão é o seguinte:
- FC e verificação de falha na porta Ethernet.
- Verificação de falha de energia.
- Verificando falha do controlador.
- Verifique a falha do disco em um grupo / pool.
Todos os testes serão realizados em condições de carga sintética, que serão gerados com o IOMETER. Paralelamente, executaremos os mesmos testes, mas em condições de copiar arquivos grandes para o sistema de armazenamento.
A configuração do IOmeter é a seguinte:
- Leitura / Gravação - 70/30
- Bloco - 128k (decidimos molhar o sistema de armazenamento com blocos grandes)
- O número de encadeamentos é 128 (que é muito semelhante à carga de trabalho)
- Aleatório completo
- Número de trabalhadores - 4 (2 para FC, 2 para iSCSI)
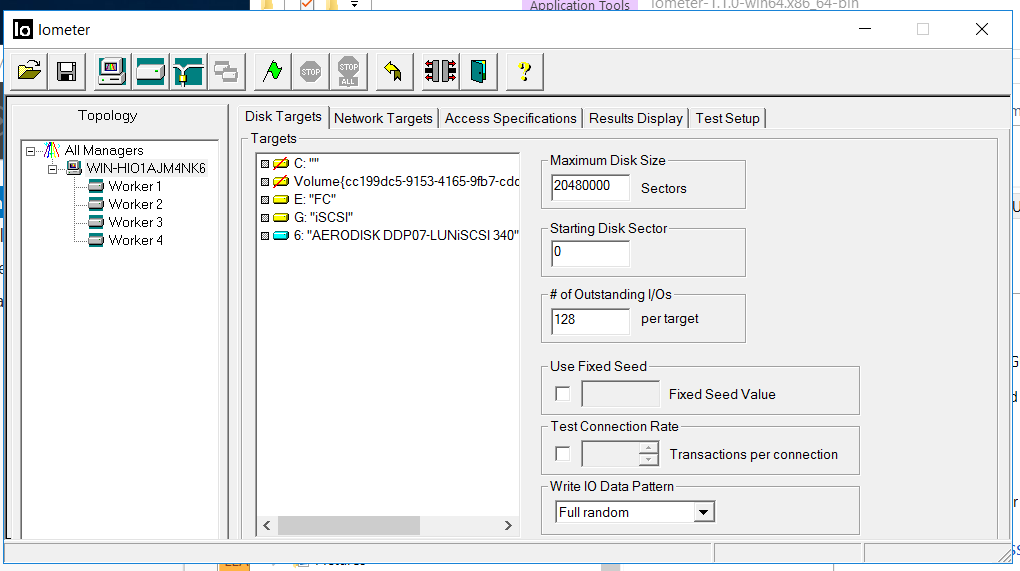
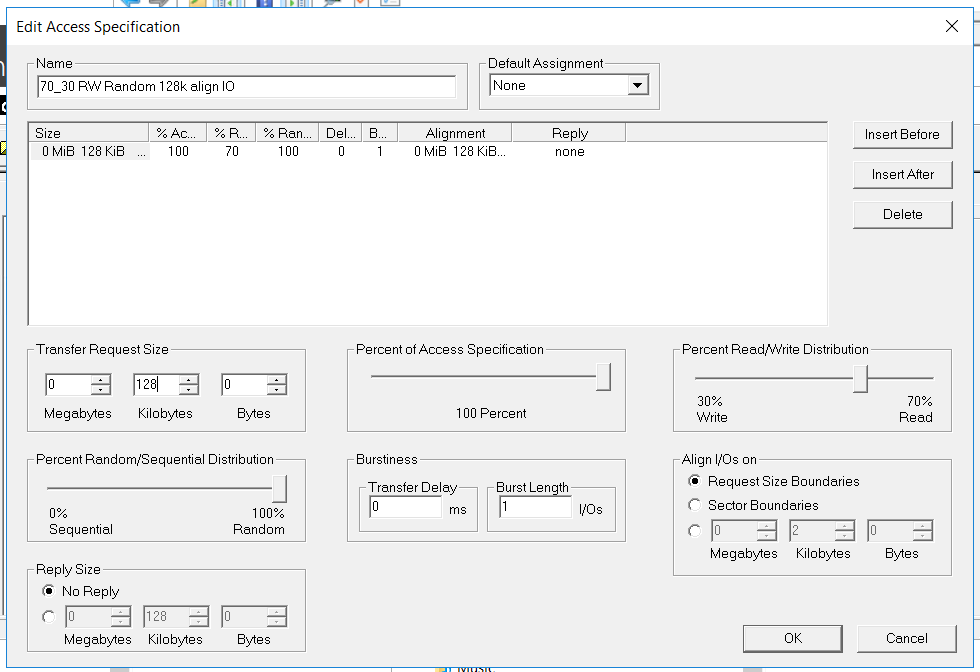 O teste tem as seguintes tarefas:
O teste tem as seguintes tarefas:- Certifique-se de que a carga sintética e o processo de cópia não sejam interrompidos e não causem erros em vários modos de falha.
- Certifique-se de que o processo de alternar portas, controladores etc. seja suficientemente automatizado e não exija ações do administrador em caso de falhas (ou seja, com failover, é claro, não se fala em failback).
- Verifique se as informações são exibidas corretamente nos logs.
Preparação de host e armazenamento
Configuramos o acesso ao bloco no armazenamento usando as portas FC e Ethernet (FC e iSCSI, respectivamente). Como fazer isso, os caras da TS Solution descreveram em detalhes em um artigo anterior ( https://habr.com/en/company/tssolution/blog/432876/ ). Bem e, é claro, ninguém cancelou manuais e cursos.
Montamos um grupo híbrido usando todas as unidades que temos. 2 discos SSD são adicionados ao cache, 2 discos SSD são adicionados como um nível de armazenamento adicional (camada Online). Agrupamos 12 discos SAS10k em RAID-60P (paridade tripla) para verificar a falha de três discos em um grupo ao mesmo tempo. Um disco foi deixado para a AutoCorreção.
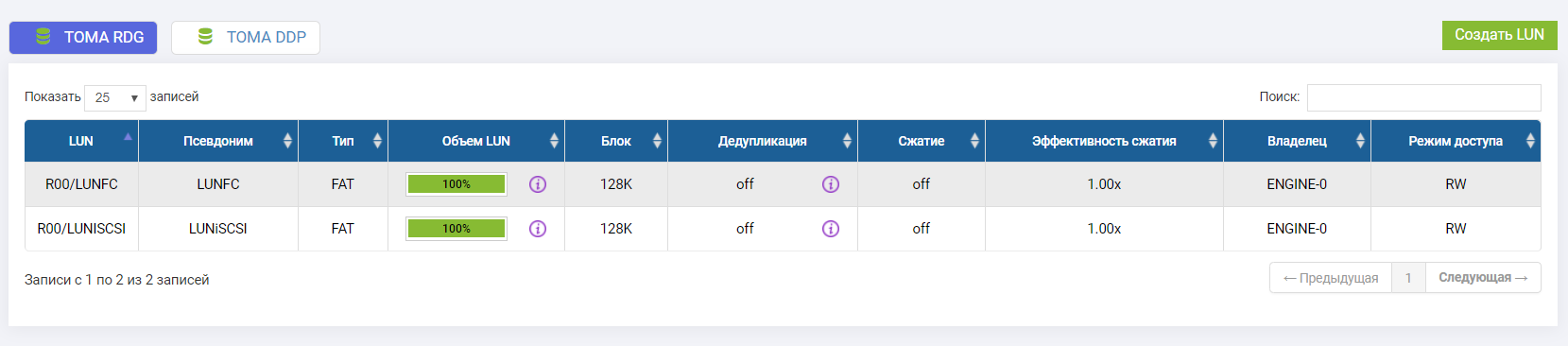
Conectamos dois LUNs (um no FC, um no iSCSI).
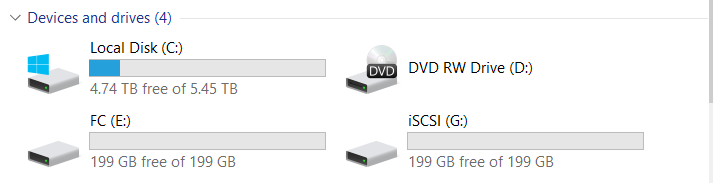
Ambos os LUNs pertencem ao controlador Engine-0.
Iniciar o teste
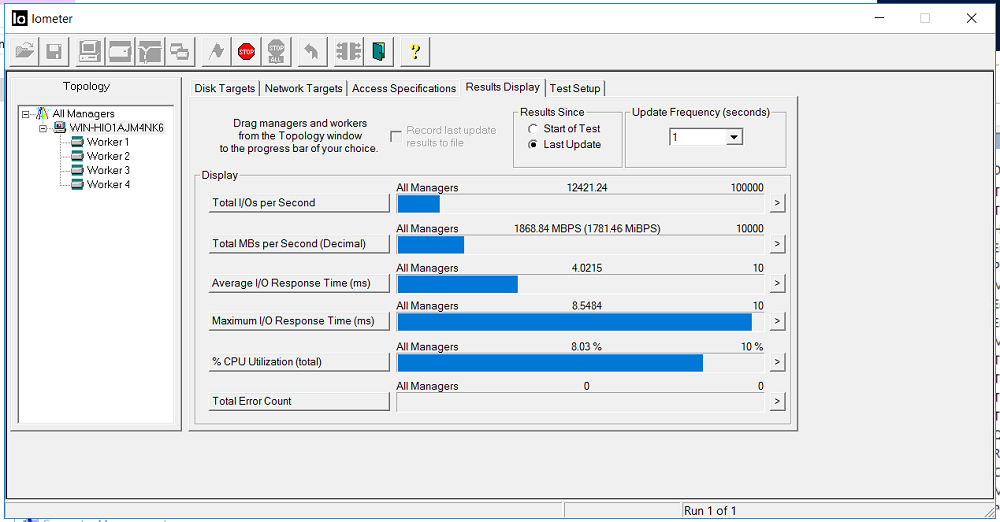
Ligue o IOMETER com a configuração acima.
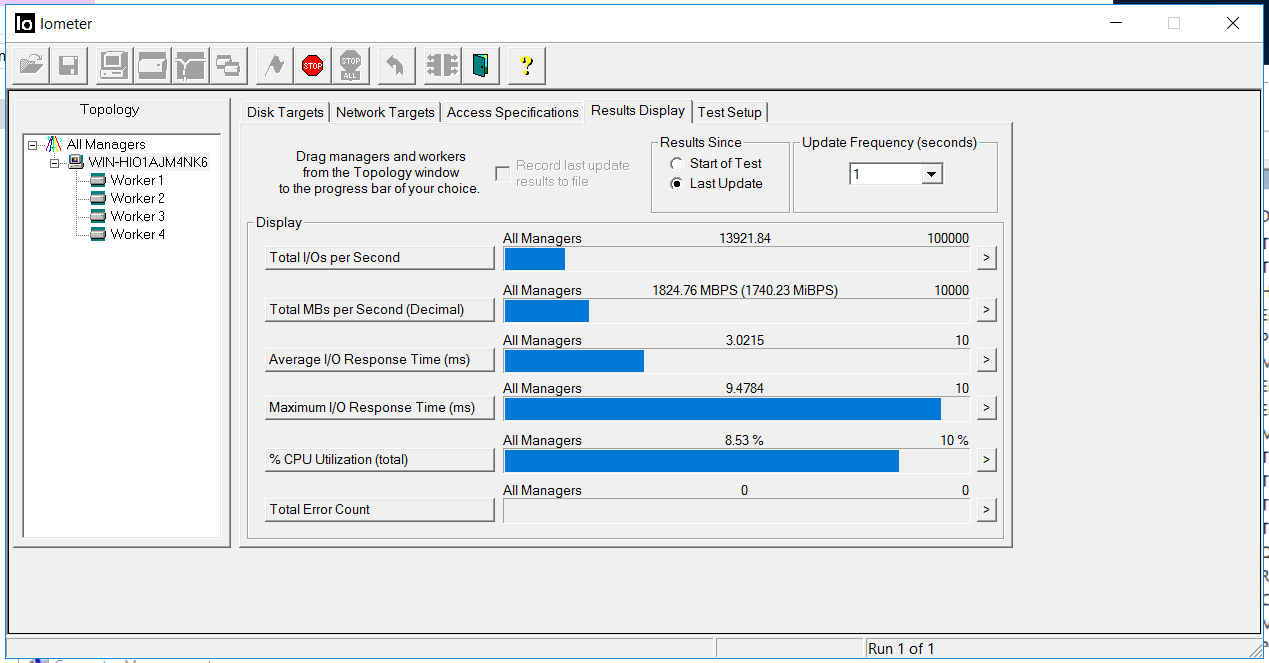
Corrigimos a largura de banda de 1,8 GB / se um atraso de 3 milissegundos. Não há erros (contagem total de erros).
Ao mesmo tempo, a partir da unidade local "C" do nosso host, simultaneamente começamos a copiar dois grandes arquivos de 100 GB para o armazenamento FC e iSCSI LUN (unidades E e G no Windows), usando outras interfaces.
Acima está o processo de cópia para o LUN FC, abaixo está o iSCSI.

Teste nº 1. Desativando portas de E / S
Nós nos aproximamos da parte traseira do sistema de armazenamento))) e, com um movimento do pulso, retiramos todos os cabos FC e Ethernet 10G do controlador Engine-0. Como se uma faxineira com uma esfregona passasse e decidisse lavar o chão exatamente onde ranho mentiroso cabos estavam mentindo (ou seja, o controlador continua funcionando, mas as portas de E / S estão mortas).

Observamos o IOMETER e a cópia de arquivos. A largura de banda caiu para 0,5 GB / s, mas retornou rapidamente ao nível anterior (em cerca de 4-5 segundos). Não há erros.
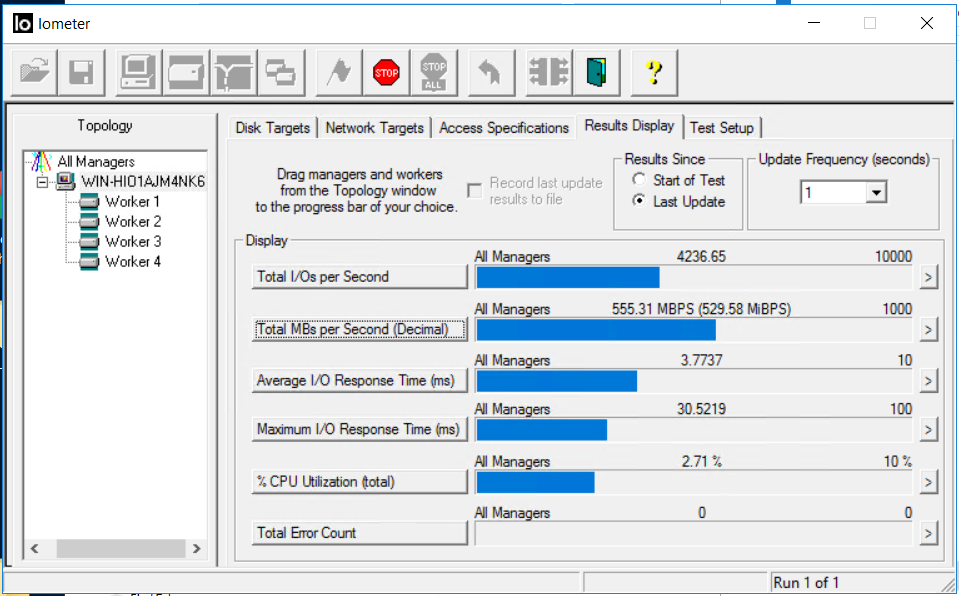
A cópia dos arquivos não foi interrompida, há uma diminuição na velocidade, mas é completamente acrítica (de 840 MB / s caiu para 720 MB / s). A cópia não parou.
Examinamos os logs do sistema de armazenamento e vemos uma mensagem sobre a indisponibilidade de portas e a movimentação automática do grupo.

Além disso, o painel nos diz que nem tudo é muito bom com as portas FC.
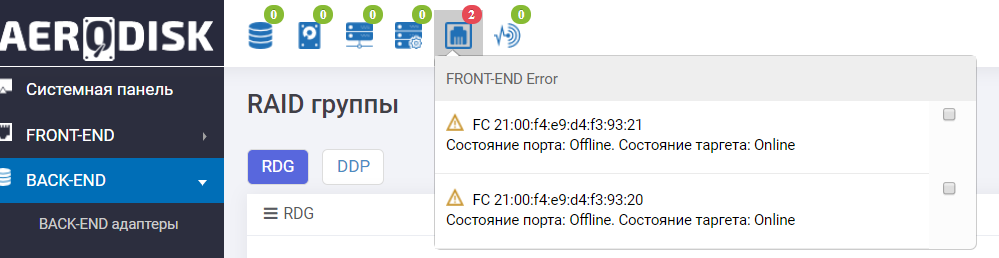
As portas de E / S de armazenamento falharam com sucesso.
Teste número 2. Desativando o controlador de armazenamento
Quase imediatamente (depois de conectar os cabos novamente ao sistema de armazenamento), decidimos terminar o armazenamento puxando o controlador para fora do chassi.
Novamente, abordamos o sistema de armazenamento por trás (gostamos))) e desta vez retiramos o controlador Engine-1, que neste momento é o proprietário do RDG (para o qual o grupo mudou).
A situação no IOmeter é a seguinte. A saída de entrada parou por cerca de 5 segundos. Erros não se acumulam.
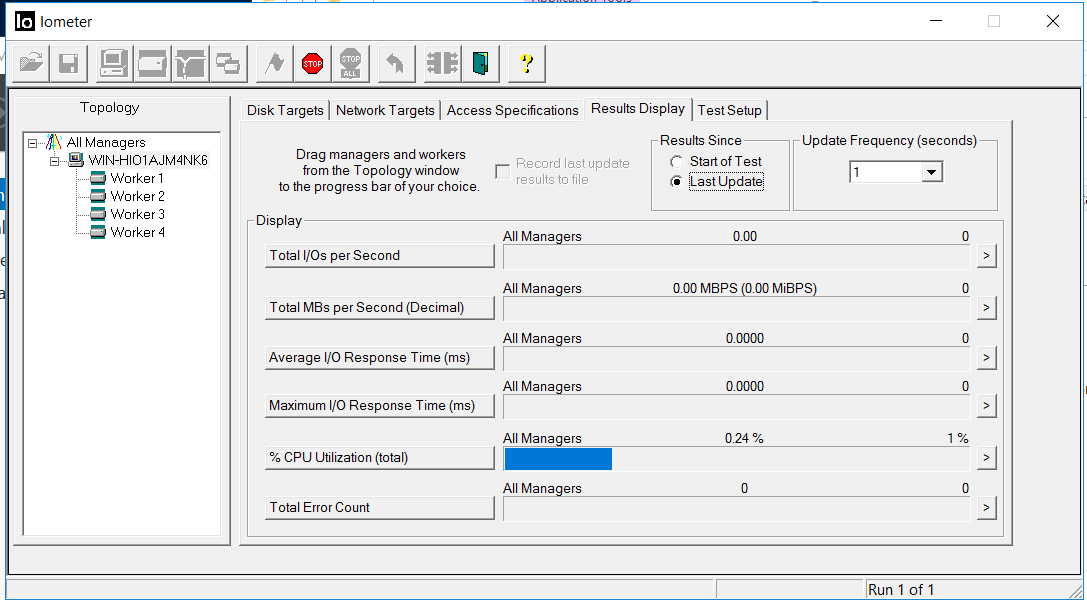
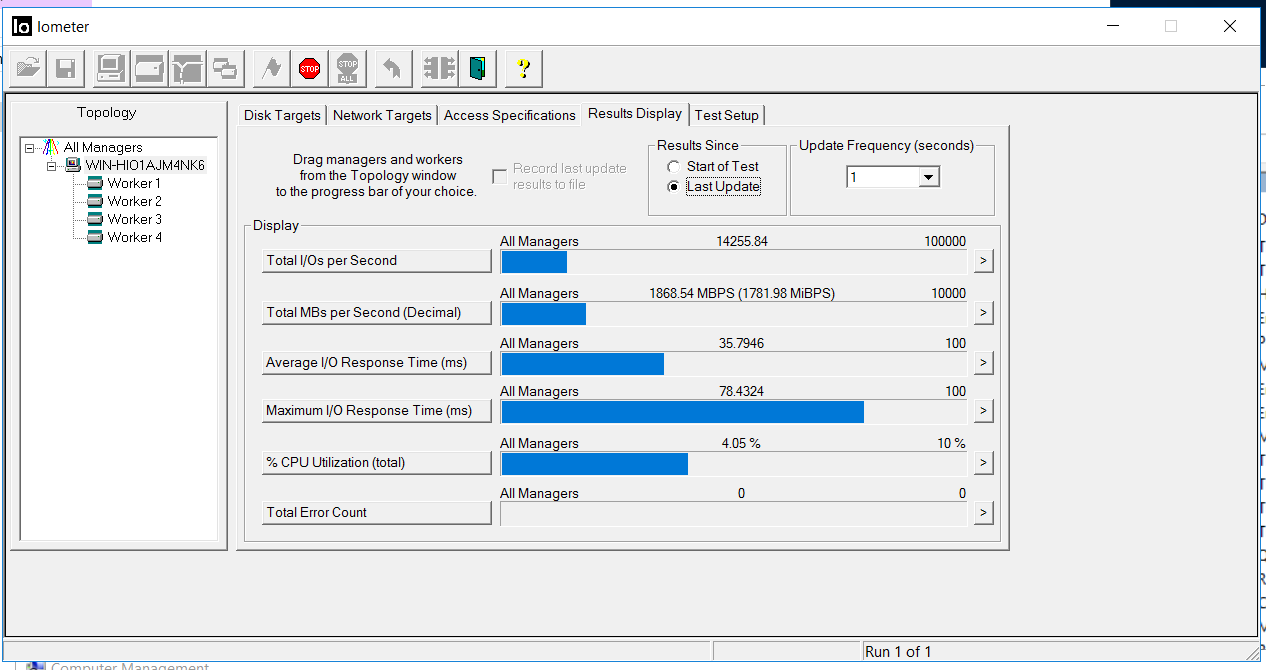
Após 5 segundos, a E / S foi retomada, com aproximadamente as mesmas taxas de taxa de transferência, mas com atrasos de 35 milissegundos (os atrasos foram corrigidos após alguns minutos). Como pode ser visto nas capturas de tela, o valor da contagem total de erros é 0, ou seja, não houve erros de gravação ou leitura.
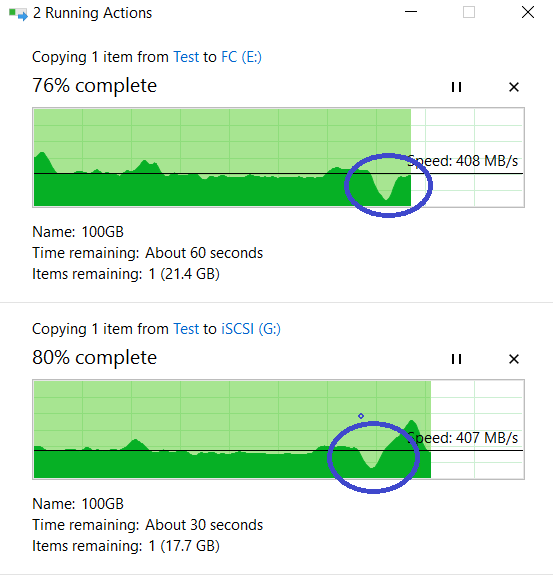
Nós olhamos para copiar nossos arquivos. Como você pode ver, ele não interrompeu, houve uma pequena queda no desempenho, mas, em geral, tudo voltou aos mesmos ~ 800 MB / s.
Nós vamos ao sistema de armazenamento e vemos abusos no painel de informações que o controlador Engine-1 não está disponível (é claro, nós batemos nele).
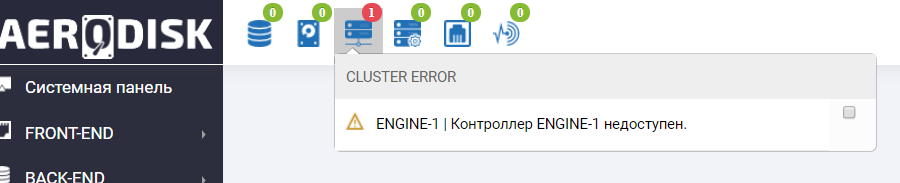
Também vemos uma entrada semelhante nos logs.

A falha do controlador de armazenamento também sobreviveu com sucesso.
Teste número 3. Desconectando a fonte de alimentação.
Por precaução, começamos a copiar os arquivos novamente, mas o IOMETER não parou.
Nós puxamos a BP-Schnick.

Outro alerta foi adicionado ao armazenamento no painel de informações.

Também vemos no menu sensores que os sensores associados à fonte de alimentação removida ficam vermelhos.

SHD continua a trabalhar. A falha do BP-Schnick não afeta a operação do sistema de armazenamento de forma alguma, do ponto de vista do host, a velocidade da cópia e os indicadores IOMETER permaneceram inalterados.
Teste de falha de energia concluído com sucesso.
Antes do teste final, decidimos trazer um pouco de vida à SHD, colocar o controlador e o BP-shnik novamente e também colocar as coisas em ordem com os cabos, que a SHD nos informou com ícones verdes em seu painel de saúde.

Número do teste 4. Falha em três discos no grupo
Antes deste teste, realizamos uma etapa preparatória adicional. O fato é que o armazenamento ENGINE fornece uma coisa muito útil - diferentes políticas de reconstrução (reconstrução). Anteriormente, a TS Solution escrevia sobre esse recurso, mas lembra sua essência. O administrador de armazenamento pode especificar a prioridade da alocação de recursos durante a reconstrução. Ou na direção do desempenho de E / S, ou seja, uma reconstrução mais longa, mas não há redução no desempenho. Ou na direção da velocidade de reconstrução, mas o desempenho será reduzido. Ou uma opção equilibrada. Como o desempenho do armazenamento durante a reconstrução de um grupo de discos é sempre uma dor de cabeça para o administrador, testaremos a política com um viés na direção do desempenho de E / S e em detrimento da velocidade da reconstrução.

Agora verifique a falha das unidades. Também habilitamos a gravação em LUNs (arquivos e IOMETER). Como temos um grupo de paridade tripla (RAID-60P), isso significa que o sistema deve suportar a falha de três discos e, após a falha, ele deve funcionar com substituição automática, um disco deve ficar no RDG no lugar de um dos com falha e a reconstrução deve começar nele.
Nós começamos. Primeiro, através da interface de armazenamento, destaque os discos que queremos extrair (para não perder e não puxar o disco de substituição automática).

Verifique a indicação no ferro. Tudo está bem, vemos as três unidades destacadas.

E retire esses três discos.

Nós olhamos para o anfitrião. E aí ... nada de especial aconteceu.
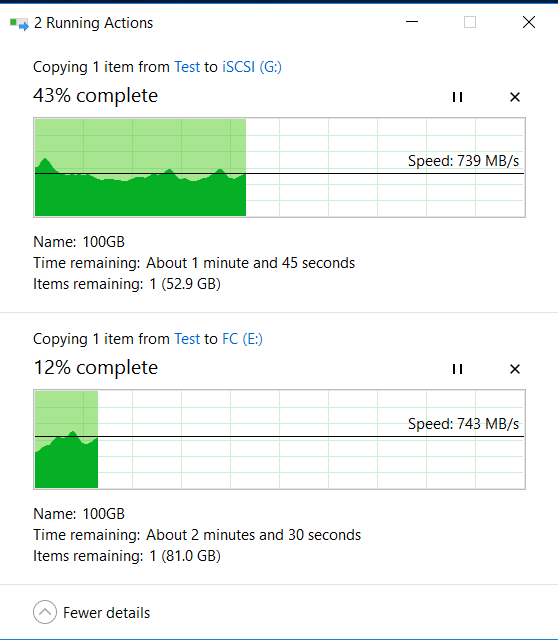
Os indicadores de cópia (eles são mais altos do que no início, porque o cache foi aquecido) e o IOMETER não mudam muito ao puxar discos e iniciar a reconstrução (dentro de 5 a 10%).
Nós olhamos para o armazenamento.
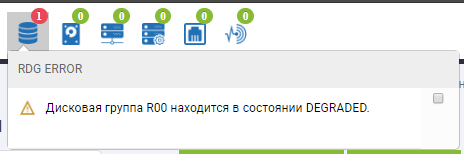
No status do grupo, vemos que o processo de reconstrução começou e está próximo da conclusão.

O esqueleto RDG mostra que 2 discos estão no status vermelho e um já foi substituído. O disco de AutoCorreção não está mais lá, substituiu o terceiro disco com falha. O Rebild foi executado por vários minutos, a gravação do arquivo não foi interrompida quando três discos falharam, o desempenho de E / S não mudou muito.
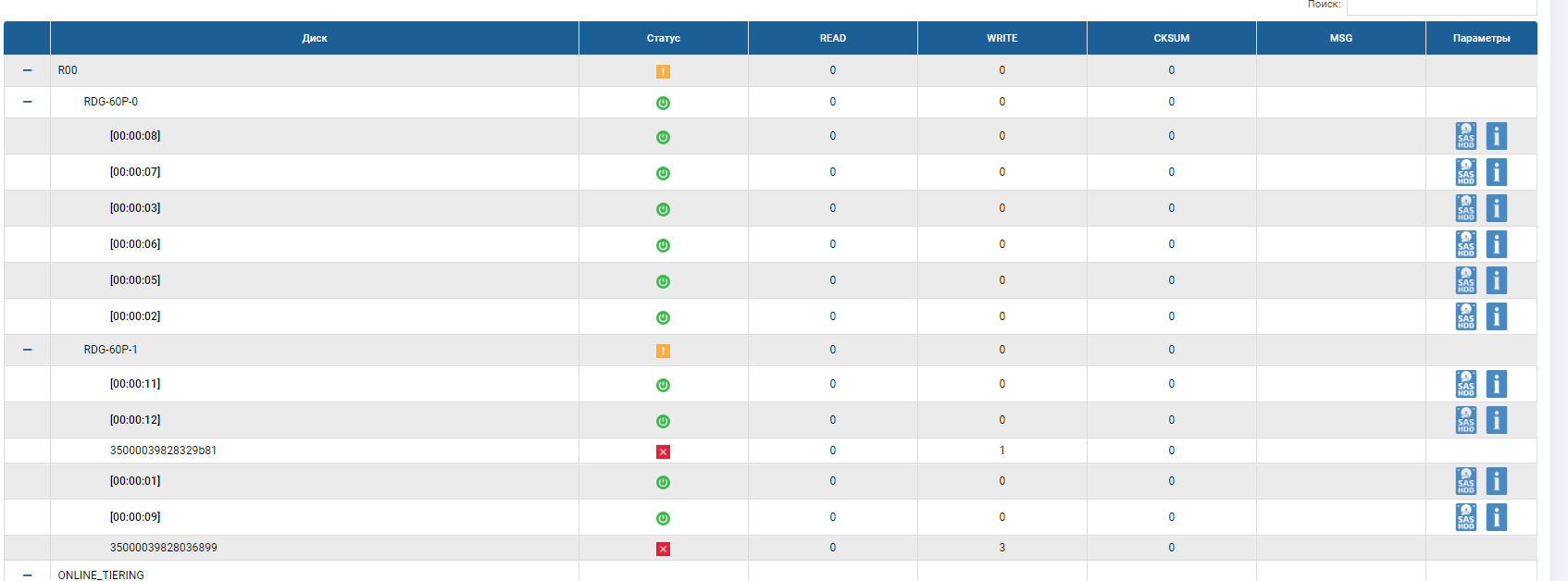
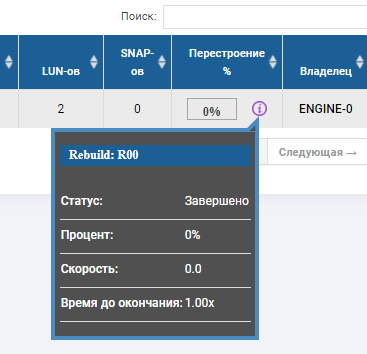
O teste de falha da unidade foi definitivamente bem-sucedido.
Conclusão
Por isso, decidimos parar o abuso de sistemas de armazenamento. Para resumir:
- Verificação de falha de porta FC - bem-sucedida
- Verificação de falha na porta Ethernet - bem-sucedida
- Verificação de falha do controlador - bem-sucedida
- Verificação de falha de energia - bem-sucedida
- Verifique a falha do disco no grupo \ pool - com êxito
Nenhuma das falhas interrompeu a gravação e não causou erros de carga sintéticos; o rebaixamento do desempenho, é claro, foi (e sabemos como derrotar isso, o que faremos em breve), mas, considerando que são segundos, é bastante aceitável. Conclusão: a tolerância a falhas de todos os componentes de armazenamento do AERODISK trabalhados no nível, não há pontos de falha.
Obviamente, na estrutura de um artigo, não podemos testar todos os cenários de falha, mas tentamos cobrir os mais populares. Portanto, envie seus comentários, desejos para as seguintes publicações e, é claro, críticas adequadas. Teremos o maior prazer em discutir (e melhor vir para o treinamento, apenas no caso de duplicar a programação)! Até novos testes!
- Nizhny Novgorod (JÁ TRABALHA - você pode se registrar aqui https://aerodisk.promo/nn/ );
Até 16 de abril de 2019, você pode visitar o centro a qualquer momento e, em 16 de abril de 2019, será organizado um grande curso de treinamento. - Krasnodar (EM BREVE - inscreva-se aqui https://aerodisk.promo/krsnd/ );
De 9 a 25 de abril de 2019, você pode visitar o centro a qualquer momento e, em 25 de abril de 2019, será organizado um grande curso de treinamento. - Ecaterimburgo (EM BREVE ABERTURA, siga as informações em nosso site ou em Habré);
Maio a junho de 2019. - Novosibirsk (siga as informações em nosso site ou em Habré);
Outubro 2019 - Krasnoyarsk (siga as informações em nosso site ou em Habré);
Novembro 2019