Acumular dívida técnica pode levar sua empresa a uma crise. Mas também pode se tornar um poderoso motor de grandes mudanças no processo e ajudar na adoção de práticas de engenharia. Vou contar sobre isso no meu próprio exemplo.
 A equipe de TI da Dodo Pizza
A equipe de TI da Dodo Pizza cresceu de 2 desenvolvedores que atendem a um país para 60 pessoas atendendo a 12 países ao longo de 7 anos. Como Scrum Master e XP Coach, ajudei as equipes a estabelecer processos e adotar práticas de engenharia, mas essa adoção foi muito lenta. Foi um desafio para mim fazer as equipes manterem a alta qualidade do código quando várias equipes trabalham em um único produto. Caímos na armadilha da preferência por características de negócios em detrimento da excelência técnica e acumulamos muita dívida técnica em arquitetura. Quando o marketing lançou uma campanha publicitária massiva em 2018, não conseguimos suportar a carga e caímos. Foi uma pena. Mas durante a crise, percebemos que somos capazes de trabalhar muitas vezes com mais eficiência. A crise nos levou a mudanças revolucionárias nos processos e a rápida introdução das práticas de engenharia mais conhecidas.
Antecedentes
Você pode pensar que a Dodo Pizza é uma rede de pizzarias regular. Mas, na verdade, a
Dodo Pizza é uma empresa de TI que vende pizza . Nosso negócio é baseado no
Dodo IS - plataforma baseada em nuvem, que gerencia todos os processos de negócios, desde o recebimento do pedido até o cozimento e o acabamento, para gerenciamento de inventário, gerenciamento de pessoas e tomada de decisões. Em apenas 7 anos, passamos de 2 desenvolvedores que servem uma única pizzaria para mais de 70 desenvolvedores que servem mais de 470 pizzarias em 12 países.
Quando entrei na empresa, há dois anos, tínhamos 6 equipes e cerca de 30 desenvolvedores. A base de código Dodo IS tinha cerca de 1 milhão de linhas de código. Tinha uma arquitetura monolítica e muito pouca cobertura de testes de unidade. Não tínhamos testes de API / interface de usuário até então. A qualidade do código do sistema foi decepcionante. Sabíamos disso e sonhávamos com um futuro brilhante quando dividimos o monólito em uma dúzia de serviços e reescrevemos as partes mais hediondas do sistema. Nós até desenhamos o diagrama “ser arquitetura”, mas honestamente não fizemos quase nada em relação ao estado futuro.
Meu objetivo principal era ensinar as práticas de engenharia dos desenvolvedores e criar um processo de desenvolvimento, fazendo 6 equipes trabalharem em um único produto .
À medida que a equipe cresceu, sofremos com a falta de práticas claras de processo e engenharia. Nossos lançamentos se tornaram maiores e mais longos, porque cada vez mais desenvolvedores contribuíram para o sistema, mas não tínhamos testes de regressão automatizados e, portanto, perdemos mais tempo em regressão manual a cada lançamento. Sofremos muitas mudanças feitas por 6 equipes em filiais separadas. Quando uma equipe mesclava suas alterações em uma única ramificação antes do lançamento, às vezes perdíamos até 4 horas resolvendo conflitos de mesclagem.
Merda acontece
Em 2018, o Marketing publicou nossa primeira campanha publicitária federal na TV . Foi um grande evento para nós. Gastamos 100 milhões de rublos (US $ 1,5 milhão) financiando a campanha - uma quantia bastante significativa para nós. Equipe de TI preparada para a campanha também. Automatizamos e simplificamos nossa implantação - agora, com um único botão no TeamCity, podemos implantar o monólito em 12 países. Investigamos testes de desempenho e realizamos análises de vulnerabilidade. Fizemos o nosso melhor, mas encontramos problemas inesperados.
A campanha publicitária foi ótima. Passamos de 100 para 300 pedidos / minuto. Esta foi uma boa notícia. As más notícias eram que o Dodo IS não podia suportar tal carga e morreu. Atingimos nossos limites de escala vertical e não conseguimos mais lidar com pedidos. O sistema é reiniciado a cada 3 horas. Cada minuto de inatividade nos custa milhões de dólares, além de perda de respeito de clientes furiosos.
Quando vim para a Dodo há dois anos, como Chief Agile Officer, eu tinha um grande desejo de fazer parte de nossa pequena equipe - cerca de 12 pessoas, uma equipe dos sonhos. Comecei imediatamente a introduzir práticas de engenharia. A maioria das equipes adotou a programação em pares, testes de unidade e DDD em breve. Mas nem tudo foi fácil. Eu tive que superar a resistência dos desenvolvedores, do Product Owner e da equipe de suporte.
Ao contrário das práticas de engenharia, nem todos eram a favor da ideia de equipes de recursos. Os desenvolvedores estavam acostumados a pensar que uma equipe focada em um componente está escrevendo um código melhor. Não ficou claro como combinar o rápido desenvolvimento de recursos de negócios com a refatoração maciça há muito esperada de um sistema complexo. Um fluxo contínuo de bugs também exigia atenção constante. A equipe de suporte preferia ter sua própria equipe focada apenas na correção de bugs. Muitas equipes estavam acostumadas a trabalhar em filiais separadas e tinham medo de se integrar com frequência. Lançamos não mais de uma vez por semana, e cada versão demorou bastante tempo, exigindo uma quantidade enorme de regressão manual e suporte a testes de interface do usuário. Tentei corrigi-lo, mas minhas alterações no processo eram muito lentas e fragmentadas.
A história de queda e ascensão
Estado inicial: Arquitetura Monolítica
Na busca pela velocidade do desenvolvimento de recursos de negócios, nem sempre pensamos bem em soluções técnicas. A falta de experiência também nos afetou. No começo, a empresa não podia contratar os melhores desenvolvedores. Trabalhamos com entusiastas que concordaram em ajudar na criação do Dodo IS, acreditavam no fundador da empresa - Fedor e trabalhavam quase na área de alimentos (pizza, é claro). Os desenvolvedores que ingressaram na equipe posteriormente seguiram a arquitetura estabelecida, que ficou desatualizada. Portanto, tínhamos um aplicativo monolítico com um único banco de dados, contendo todos os dados de todos os componentes em um único local. Rastreador, caixa, site, API para páginas de destino - todos os componentes do sistema trabalhavam com um único banco de dados, que se tornam um gargalo. Nossa arquitetura monolítica criou problemas monolíticos. Uma única postagem no blog levou a uma interrupção no checkout do restaurante.
História verdadeira
Para ilustrar o quão frágil é a arquitetura monolítica, darei apenas um exemplo. Certa vez, todos os nossos restaurantes na Rússia pararam de aceitar pedidos por causa de uma postagem no blog. Como isso pode acontecer?
Um dia, nosso CEO - Fedor publicou um post em seu blog. Este post rapidamente ganhou popularidade. Há um contador no site do blog do Fedor mostrando várias pizzarias em nossa rede e a receita total de todas as pizzarias. Toda vez que alguém lê o blog de Fedor, o servidor envia uma solicitação ao banco de dados mestre para calcular a receita. Essas solicitações sobrecarregaram o banco de dados e pararam de servir solicitações do caixa do restaurante. Assim, um post popular interrompeu o trabalho de toda a cadeia de restaurantes. Corrigimos o problema rapidamente, mas era um sinal claro (entre muitos outros) de que nossa arquitetura não é capaz de atender às necessidades de negócios e precisa ser redesenhada. Mas nós ignoramos esses sinais. Implementamos soluções rápidas e fáceis (como adicionar réplica somente leitura do banco de dados mestre), mas não tínhamos nenhum roteiro de redesenho técnico.
A arquitetura monolítica é boa para começar, porque é simples. Mas não pode suportar a carga alta sendo um único ponto de falha.
Falha no início de 2017
14 de fevereiro é um dia dos namorados . Todo mundo adora esse feriado. Para os amantes se felicitarem, em 14 de fevereiro, fazemos uma pizza especial - calabresa em forma de coração. Vou me lembrar do dia 14 de fevereiro de 2017 para sempre, porque neste dia, quando todas as pizzarias estavam trabalhando a plena carga, o Dodo IS começou a cair. Em cada pizzaria, temos de 4 a 5 comprimidos para rastrear qual pedido um pizzaiolo faz para colocar, colocar ingredientes, assar ou enviar para entrega. O número de pizzarias atingiu mais de 300, cada tablet atualizou seu estado várias vezes por minuto. Todas essas solicitações criaram uma carga tão grande no banco de dados que o servidor SQL deixou de suportar e o banco de dados começou a falhar. Dodo IS estabelecido no momento mais inadequado - durante o pico de vendas. Houve uma temporada de férias movimentada pela frente: 23 de fevereiro (Dia do Exército e da Marinha), 8 de março (Dia Internacional da Mulher), 1 de maio (Dia da Solidariedade Internacional dos Trabalhadores) e 9 de maio (Dia da Vitória na Segunda Guerra Mundial). Durante essas férias, esperávamos um crescimento ainda maior de pedidos.
O dia em que você morrerá . Conhecendo nossos planos de crescimento e o limite de carga que podemos suportar, descobrimos quanto tempo podemos permanecer vivos, isto é, quando o pico de carga de hoje se torna regular. A data estimada do Armagedom prevista para cerca de seis meses - em agosto ou setembro. Como é viver sabendo a data de sua morte?
Pare o desenvolvimento de recursos por um ano . Juntamente com o CEO Fedor, tivemos que tomar uma decisão árdua. Talvez uma das decisões mais difíceis da história da empresa. Paramos o desenvolvimento de recursos de negócios. Pensamos em parar por três meses, mas logo percebemos que o volume de dívida técnica era tão grande que três meses não seriam suficientes e temos que continuar trabalhando em questões técnicas e adiar o atraso dos negócios. De fato, com 6 equipes, fizemos apenas um recurso de negócios durante o próximo ano. No restante do tempo, as equipes estavam envolvidas no pagamento de dívidas técnicas. Essa dívida nos custou muito - mais de US $ 1,5 milhão.
Algumas melhorias após um ano
Ao longo do ano, tivemos essas realizações notáveis:
- Automatizamos e aceleramos nosso pipeline de implantação. Anteriormente, a implantação era semi-manual. Nós implantamos em 10 países em cerca de 2 horas.
- Começou a dividir um monólito. A parte mais carregada do sistema - o rastreador - foi dividida em um serviço separado, com seu próprio banco de dados. Agora, o rastreador se comunica com o resto do sistema através de uma fila de eventos.
- Começamos a separar a Caixa de entrega - o segundo componente que cria uma carga alta.
- Reescreva o sistema de autenticação de usuário e dispositivo.
Nosso arquiteto gerenciava o backlog técnico. Usamos as mudanças arquiteturais para impulsionar o backlog. Cada equipe teve a liberdade de fazer o que era certo para criar uma arquitetura útil. Para o ano com as 6as equipes, criamos para os negócios apenas um recurso valioso. No restante do tempo, as equipes trabalharam em dívidas técnicas. Parece que podemos ter orgulho de nós mesmos. Mas à nossa frente havia uma enorme decepção.
Falha durante a Campanha de Marketing Federal. A segunda crise de confiança.
A dívida técnica é fácil de acumular, mas muito difícil de pagar. É improvável que você seja capaz de entender com antecedência quanto isso lhe custará.
Apesar de termos passado um ano inteiro lutando contra dívidas técnicas, não estávamos prontos para uma campanha de marketing maciça e nos enganamos diante de nossos negócios. Você ganha confiança em quedas, perde-a em baldes. E tivemos que conquistá-lo novamente.
Perdemos o momento em que era necessário diminuir a velocidade do desenvolvimento de recursos de negócios e combater a dívida técnica. Era tarde demais quando notamos. Nós nos deitamos sob carga novamente. O sistema travou e reiniciou a cada 3 horas. Nosso negócio perdeu dezenas de milhões de rublos.

Mas, graças à crise, vimos que, em condições extremas, podemos trabalhar muitas vezes com mais eficiência. Lançamos 20 vezes por dia. Todos trabalhavam como uma equipe, concentrando-se em um único objetivo. Durante duas semanas de crise, fizemos o que tínhamos medo de começar antes, porque acreditávamos que levaria meses de trabalho. Ordem assíncrona, testes de desempenho, logs limpos são apenas uma pequena parte do que fizemos. Estávamos ansiosos para continuar a trabalhar da maneira mais eficaz, mas sem horas extras e estresse.
Lições aprendidas
Após a retrospectiva, reestruturamos completamente nossos processos. Pegamos a estrutura do LeSS e a complementamos com as práticas de engenharia. Nos meses seguintes, fizemos um avanço na adoção de práticas de engenharia. Com base na estrutura LeSS, implementamos e continuamos a usar:
- lista de pendências única;
- equipes de recursos totalmente funcionais e com vários componentes;
- programação em pares;
- Tentando Mob Programming.
- Integração contínua genuína, significando várias integrações de código de 9 equipes em uma única ramificação;
- gerenciamento de configuração simplificado com desenvolvimento baseado em tronco;
- lançamentos frequentes: Implantação Contínua para microsserviços, vários lançamentos por dia para monólito;
- sem uma equipe de controle de qualidade separada, os especialistas em controle de qualidade fazem parte das equipes de desenvolvimento.
6 práticas que escolhemos após a crise
1. O poder do foco . Antes da crise, cada equipe trabalhava em seu próprio estoque e se especializava em seu domínio. No backlog, havia tarefas finamente decompostas, a equipe selecionou várias tarefas para um sprint. Mas durante a crise, trabalhamos de maneira bem diferente. As equipes não tinham tarefas específicas, elas tinham um grande objetivo desafiador. Por exemplo, um aplicativo móvel e uma API devem lidar com 300 pedidos por minuto, não importa o quê. Cabe à equipe como atingir a meta. As próprias equipes formulam hipóteses, rapidamente as verificam em Produção e jogam fora. E é exatamente isso que queríamos continuar fazendo. As equipes não querem ser codificadores idiotas, querem resolver problemas.
O poder do foco se manifestou na solução de problemas complexos. Por exemplo, durante a crise, criamos um conjunto de testes de desempenho, apesar de não termos experiência. Também criamos a lógica de receber um pedido assíncrono. Pensamos muito sobre isso e conversamos, e parecia-nos que essa é uma tarefa muito difícil e longa. Mas a equipe é capaz de fazê-lo em duas semanas, se não estiver distraída e completamente focada no problema.
2. Hackathons regulares . Gostávamos de trabalhar no modo quando todas as equipes visavam um objetivo e decidimos às vezes organizar esses “hackathons”. Não se pode dizer que as realizamos regularmente, mas houve algumas vezes. Por exemplo, houve uma invasão de 500 erros quando todas as equipes limparam os logs e removeram as causas de 500 erros no site e na API. O objetivo era manter os logs limpos. Quando os logs estão limpos, os novos erros estão claramente visíveis, você pode configurar facilmente os valores limite para os alertas. É semelhante aos testes de unidade - eles não podem ser um pouco vermelhos.
Outro exemplo de hackathon são os bugs. Costumávamos ter uma enorme lista de pendências de bugs, alguns dos que estavam na lista de pendências há anos. Parecia que eles nunca terminariam. E todos os dias havia novos. Você precisa, de alguma forma, combinar o trabalho em bugs e em itens regulares de pendências.
Introduzimos a política #zerobugspolicy em 4 etapas.- Limpeza inicial de bugs com base na data. Se o bug estiver no backlog por mais de 3 meses, exclua-o. Provavelmente estava lá há séculos.
- Agora, classifique os defeitos restantes com base em como eles afetam os clientes. Nós cuidadosamente resolvemos os bugs restantes. Mantivemos apenas o defeito que dificulta a vida de um grande grupo de usuários. Se isso é apenas algo que causa inconveniência, mas você pode lidar com isso - exclua impiedosamente. Então reduzimos o número de bugs para 25, o que é aceitável.
- Hackathon. Todas as equipes pululam e consertam todos os bugs. Fizemos isso em alguns sprints. Cada sprint de cada equipe pegava vários bugs e consertava. Após 2-3 sprints, tivemos um registro claro de bugs. Agora você pode inserir #zerobugspolicy.
- #zerobugspolicy. Cada novo bug agora tem apenas duas maneiras. Éter cai na lista de pendências, ou não. Se ele entrar em atraso, nós o corrigimos primeiro. Qualquer bug na lista de pendências tem prioridade mais alta do que qualquer outro item da lista de pendências. Mas, para entrar no backlog, o bug deve ser sério. Ou causa danos irreparáveis ou afeta um grande número de usuários.
3. Equipes de projeto temporárias para equipes de recursos estáveis . Havia uma história engraçada com as equipes de projeto. Durante a crise, formamos equipes de tigres com as melhores habilidades para a tarefa. Após o término da crise, as equipes decidiram continuar essa prática e dispersar as equipes. Apesar de não gostar dessa idéia, deixei que tentassem. Em apenas 2 semanas (uma corrida), na próxima retrospectiva, as equipes abandonaram essa prática (essa decisão me deixou extremamente feliz). Eles tentaram e entenderam por que é muito mais confortável trabalhar em uma equipe de recursos estáveis. Mesmo que a equipe não possua algumas habilidades, eles podem aprender gradualmente. Mas o espírito de equipe, o apoio e a assistência mútua são formados por um longo tempo, leva meses. As equipes de projeto de curto prazo estão constantemente em fase de formação e assalto. Você pode suportar isso por algumas semanas, mas não pode trabalhar assim o tempo todo. É bom que as equipes tenham tentado e compreendido os benefícios das equipes de recursos estáveis.
4. Livre-se da regressão manual . Antes da crise, lançávamos uma vez por semana e durante a crise - dezenas de vezes por dia. Adoramos nossa capacidade de liberar frequentemente. Apreciamos como era conveniente fazer uma pequena alteração, implementá-la rapidamente e obter imediatamente feedback da produção. Portanto, alteramos nossa abordagem de lançamentos, e isso afetou a abordagem de programação e design. Agora lançamos continuamente, a cada 1-2 dias. Tudo no ramo de desenvolvimento entra em produção. Mesmo que alguns recursos não estejam prontos, isso não é motivo para não liberar o código. Se não quisermos mostrar algum recurso ainda não pronto para os usuários, ocultamos-o com alternância de recursos. Essa abordagem nos ajudou a desenvolver em pequenas etapas.
Estabelecemos uma meta para nos livrar das regressões manuais. Levamos 1,5 anos para alcançá-lo. Mas ter um objetivo ambicioso a longo prazo faz você pensar nas etapas que levam ao objetivo.
Fizemos isso em 3 etapas.- Automatize o caminho crítico. Em junho de 2017, formamos a equipe de controle de qualidade. A tarefa da equipe era automatizar a regressão das funções mais críticas do Dodo IS - recebimento e produção de pedidos. Nos próximos 6 meses, uma nova equipe de controle de qualidade de 4 pessoas cobriu todo o caminho crítico. Os desenvolvedores das equipes de recursos os ajudaram ativamente. Juntos, criamos uma linguagem específica de domínio (DSL), bonita e compreensível, que pode ser lida até pelos clientes. Paralelamente aos testes de ponta a ponta, os desenvolvedores cobriram o código com testes de unidade. Alguns novos componentes foram redesenhados com TDD. Depois disso, dissolvemos a equipe de controle de qualidade. Os ex-membros da equipe de controle de qualidade se uniram às equipes de recursos para compartilhar conhecimentos sobre como dar suporte e manter autotestes.
- Modo de sombra. Tendo autotestes, durante 5 lançamentos, fizemos regressões manuais no modo sombra. As equipes confiaram apenas no conjunto de testes automatizados, mas quando a equipe decidiu "Estamos prontos para o lançamento", executamos uma regressão manual para verificar se nossos autotestes perdem algum erro. Nós rastreamos quantos erros foram detectados manualmente e não detectados pelos autotestes. Após 5 lançamentos, revisamos os dados e decidimos confiar em nossos autotestes. Nenhum erro grave foi esquecido.
- Remova as regressões manuais. Quando tivemos testes suficientes e começamos a confiar neles, abandonamos completamente os testes manuais. Quanto mais executamos nossos testes, mais confiamos neles. Mas isso aconteceu apenas 1,5 anos depois que começamos a automatizar o teste de regressão.
5. Teste de desempenho faz parte do teste de regressão . Durante a crise, criamos um conjunto de testes de desempenho. Era uma área completamente nova para nós. No entanto, em apenas duas semanas, conseguimos criar alguns testes de desempenho usando as ferramentas do Visual Studio. Esses testes nos ajudaram a não apenas detectar a degradação do desempenho. Nós os usamos para adicionar carga sintética ao servidor de Produção para identificar os limites de desempenho. Por exemplo, se a carga de produção orgânica for 100 pedidos / min e adicionarmos mais 50 pedidos / min com a ajuda de nossos testes de desempenho, podemos ver se os servidores de Produção podem lidar com o aumento da carga. Assim que notamos exceções ou latência aumentada, paramos o teste. Ao fazer essas experiências, descobrimos a carga máxima que nossos servidores de produção podem suportar e qual será o ponto de acesso.
No próximo ano, superamos os testes de desempenho para a experiente equipe PerformanceLab. Eles se reuniram com nossos desenvolvedores e pessoal de infraestrutura e nos ajudaram a criar um conjunto robusto de testes de desempenho. Agora, executamos esses testes semanalmente e fornecemos feedback rápido às equipes de desenvolvimento, se o desempenho for impactado.
Algumas das práticas de engenharia foram iterativamente refinadas. Por exemplo, lançamentos frequentes. Começamos com ciclos de lançamento semanais, suportados por testes manuais lentos e frágeis. Desenvolvemos recursos por uma semana e testamos por mais uma semana. Mas foi difícil manter as alterações feitas por vários durante uma semana. Depois, tentamos lançamentos isolados de equipe, quando apenas as alterações feitas por uma única equipe foram lançadas. Mas esse processo falhou porque todas as equipes tiveram que esperar na fila por várias semanas. Em seguida, as equipes aprenderam os benefícios da integração frequente e começamos a praticar versões conjuntas de várias mudanças de equipe. Os desenvolvedores começaram a experimentar a alternância de recursos e a avançar para recursos inacabados de produção. Eventualmente, chegamos à Integração Contínua e a vários lançamentos por dia para monólito e Implantação Contínua para microsserviços.
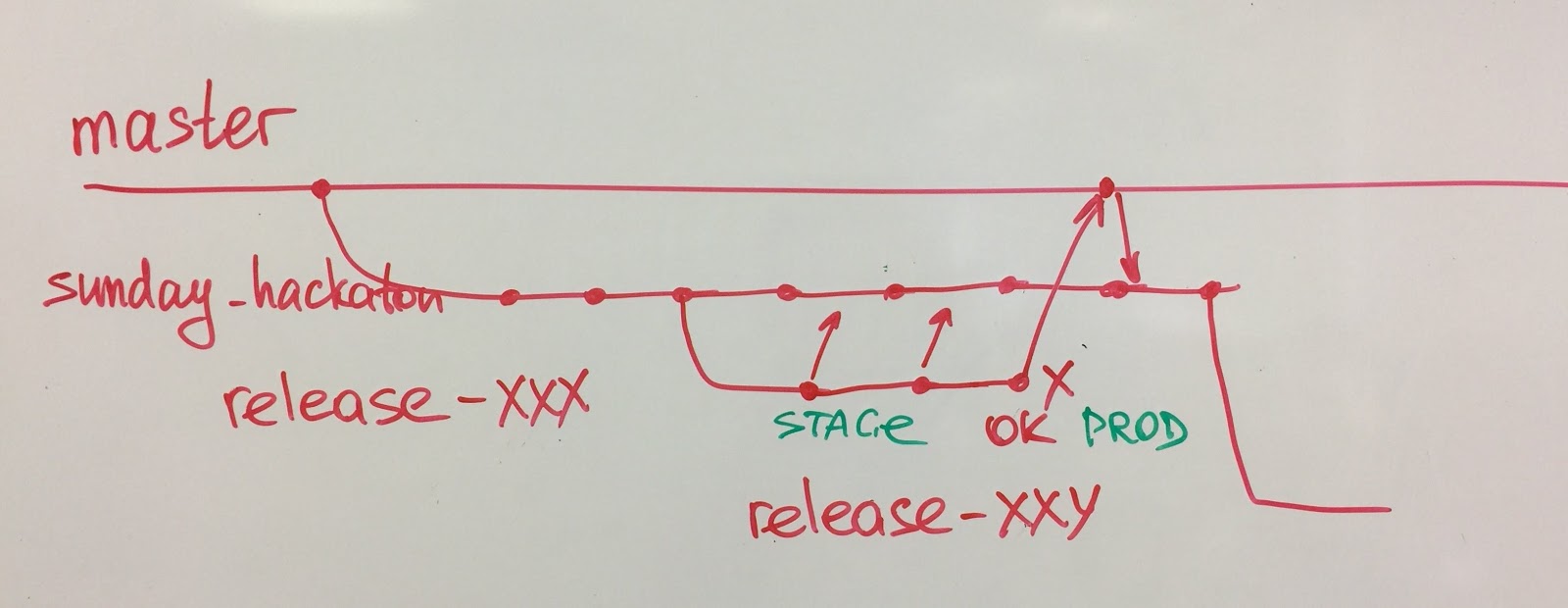
Outro caso interessante é com nosso departamento de controle de qualidade. Antes, não tínhamos uma equipe de controle de qualidade, mas testadores manuais. Percebendo a necessidade de automação de teste, formamos uma equipe de controle de qualidade, mas desde o primeiro dia essa equipe sabia que seria dissolvida um dia. Após 6 meses, a equipe automatizou nossos principais cenários de negócios e, com a ajuda dos desenvolvedores, escreveu uma conveniente DSL (Domain Specific Language) para escrever testes. A equipe se separou e os engenheiros da qualidade se juntaram às equipes de recursos. Agora, as próprias equipes desenvolvem e mantêm autotestes.
Hoje, temos um único atraso em que nove equipes de recursos estão trabalhando. As equipes de recursos são estáveis, multifuncionais e entre componentes. A maioria de nossas equipes são equipes de recursos.
6. Foco nas práticas de engenharia . Todas as nossas equipes usam programação em pares. Considero a programação em pares uma das práticas mais simples, porém poderosas, que ajuda a implementar outras práticas de engenharia. Se você não souber qual prática de engenharia iniciar, recomendo a programação em pares.
Resultados
O principal resultado que a crise nos deu é um abalo. Nós acordamos e começamos a agir. A crise nos ajudou a ver o máximo de nossas oportunidades. Vimos que podemos trabalhar muitas vezes com mais eficiência e rapidez para atingir nossos objetivos. Mas isso requer mudar a maneira regular de trabalhar. Paramos de ter medo de fazer experiências ousadas. Como resultado dessas experiências, ao longo do ano passado, melhoramos significativamente a qualidade e a estabilidade do Dodo IS. Se durante as férias de primavera em 2018 nossas pizzarias não puderam funcionar por causa do Dodo IS, então em 2019, com um crescimento de 300 a 450 pizzarias, o Dodo IS funcionou perfeitamente. Nós experimentamos discretamente o pico de vendas no Ano Novo, durante a segunda Campanha de Marketing e as férias de primavera. Pela primeira vez em muito tempo, estamos confiantes na qualidade do sistema e dormimos bem à noite. Este é o resultado do uso constante de práticas de engenharia e o foco na excelência técnica.
Resultados para empresas
As práticas de engenharia não são necessárias por si próprias se não beneficiarem seus negócios. Como resultado do foco na excelência técnica, melhoramos a qualidade do código e desenvolvemos recursos de negócios com velocidade previsível. Os lançamentos se tornaram um evento regular para nós. Lançamos o monólito a cada 2 dias e serviços menores a cada poucos minutos. Isso significa que podemos fornecer rapidamente valor comercial aos nossos usuários e coletar feedback mais rapidamente. Graças à flexibilidade das equipes de recursos, obtemos alta velocidade de desenvolvimento.
Hoje, temos 480 pizzarias online, das quais 400 na Rússia. Durante as férias de maio deste ano, houve problemas com o processamento de pedidos em nossas pizzarias novamente. Mas desta vez o gargalo foi o atendimento ao cliente nas pizzarias. O Dodo IS estava funcionando como um relógio, apesar do número crescente de pizzarias e pedidos.
Resultados para as equipes
Hoje usamos uma ampla gama de práticas de engenharia:
- Equipes de recursos totalmente funcionais e com vários componentes.
- Programação em Par / Programação em Mob.
- Integração contínua genuína, significando várias integrações de código de 9 equipes em uma única ramificação.
- Gerenciamento de configuração simplificado com desenvolvimento baseado em tronco.
- Objetivo comum para várias equipes.
- O especialista no assunto está na equipe.
- Sem equipe de controle de qualidade separada, os especialistas em controle de qualidade fazem parte das equipes de desenvolvimento.
- Eventual substituição manual do regress com autotestes.
- Política de zero bugs.
- Acumulação de dívidas técnicas.
- Pare a linha como um driver para a aceleração do pipeline de implantação.
Eles ajudam 9 equipes a trabalhar em um código comum e em um único produto que inclui dezenas de componentes - um site móvel e para desktop, um aplicativo móvel para iOS e Android e um back office gigante com caixa registradora, rastreamento, exibição de restaurante, conta pessoal , análise e previsão.
O que pode ser melhor
Pode parecer que já fizemos um bom progresso nas práticas de engenharia, mas estamos apenas no começo, ainda temos espaço para crescer. Por exemplo, tentamos, mas até agora de maneira sistemática, a programação mob. Estudamos a abordagem de redação do teste BDD. Ainda temos espaço para crescer no IC, entendemos que a integração mesmo uma vez ao dia não é suficiente. E quando crescermos até 30 equipes, será necessário integrar com mais frequência. Ainda estamos em andamento a transição do TDD para o ATDD. Temos que criar um processo de tomada de decisão arquitetural sustentável e escalável.
O mais importante é que seguimos para o fortalecimento da excelência técnica.
Devido ao fato de todas as 9 equipes estarem trabalhando em um estoque comum e em um produto, as equipes têm um forte desejo de cooperar entre si. Eles aprenderam a tomar decisões fortes por conta própria.
Por exemplo, as práticas a seguir foram propostas e implementadas pelas próprias equipes.- Interrompa a linha como um driver para a aceleração do pipeline de implantação (consulte meu relatório de experiência "Interrompa a linha para otimizar seu pipeline de implantação").
- Substitua os testes da interface do usuário pelos testes da API.
- Implantação automatizada com um clique.
- Anfitrião do Kubernetes.
- A equipe de desenvolvimento é implantada na produção.
Algumas equipes demonstraram desejo de usar todas as 12 práticas de XP e me pediram ajuda como XP Coach e Scrum Master.
O que aprendemos
Eu gostaria de não deixar a crise acontecer. Como desenvolvedor, senti a responsabilidade pessoal de acumular uma dívida técnica muito grande e de não levantar uma bandeira vermelha anteriormente:
- As práticas de engenharia protegem os negócios da crise.
- Não acumule dívidas técnicas. Pode ser tarde demais e custar muito alto.
- As mudanças evolucionárias demoram várias vezes mais que as revolucionárias.
- Crise nem sempre é uma coisa ruim. Use a crise para revolucionar os processos.
- No entanto, é necessária uma preparação evolutiva longa com antecedência.
- Não implemente cegamente todas as práticas que você gosta. Algumas práticas estão esperando nos bastidores e, quando ele vier, as equipes as usarão sem resistência. Aguarde o momento certo.
- Refine e adapte as práticas ao seu contexto.
- Com o tempo, as próprias equipes começam a tomar fortes decisões e implementá-las. Dê a eles um ambiente seguro para tentar, falhar e aprender com os erros.
Dívidas técnicas nos levam a crises. Mas, com a crise, tanto os desenvolvedores quanto os empresários aprenderam o quão importante é o foco na excelência técnica e nas práticas de engenharia. Usamos a crise como um gatilho para grandes mudanças organizacionais e de processos.
Agradecimentos
Gostaria de agradecer a todas as pessoas que me ajudaram na minha jornada da crise à transformação do LeSS. Eu constantemente sinto seu apoio.
Muito obrigado ao nosso CEO, Fedor Ovchinnikov, pela confiança. Você é o verdadeiro líder da empresa com uma verdadeira cultura ágil.
Muito obrigado a Dmitry Pavlov, nosso Product Owner, meu velho amigo e co-treinador.
Obrigado Alex Andronov e Andrey Morevsky por me apoiarem no meu papel.
Muito obrigado a Dasha Bayanova, nossa primeira Scrum Master em tempo integral, que acreditou em mim e sempre me ajuda e me apoia com toda a nossa iniciativa. É difícil superestimar sua ajuda.
Um enorme agradecimento especial a Johanna Rothman, que me ajudou a escrever este relatório em qualquer condição: estar de férias, se recuperar após uma doença. Johanna, foi um grande prazer trabalhar com você. Sua ajuda, conselho, atenção aos detalhes e diligência são muito apreciados.