Introdução aos sistemas operacionais
Olá Habr! Quero chamar sua atenção para uma série de artigos - traduções de uma literatura interessante em minha opinião - OSTEP. Este artigo discute profundamente o trabalho de sistemas operacionais semelhantes a unix, ou seja, trabalha com processos, vários agendadores, memória e outros componentes similares que compõem o sistema operacional moderno. O original de todos os materiais que você pode ver
aqui . Observe que a tradução foi feita de maneira não profissional (muito livremente), mas espero ter mantido o significado geral.
O trabalho de laboratório sobre este assunto pode ser encontrado aqui:
Outras partes:
E você pode olhar para o meu canal no
telegrama =)
Alarme! Existe um laboratório para esta palestra! assistir
githubAPI de processo
Considere um exemplo de criação de um processo em um sistema UNIX. Ocorre através de duas chamadas de sistema
fork () e
exec () .
Chamada Fork ()

Considere um programa que faça uma chamada fork (). O resultado de sua implementação será o seguinte.
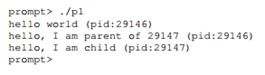
Primeiro, entramos na função main () e executamos a saída da string na tela. A sequência contém o identificador do processo, que no original é chamado de
PID ou identificador do processo. Este identificador é usado no UNIX para se referir a um processo. O próximo comando chamará fork (). Nesse ponto, uma cópia quase exata do processo é criada. Para o sistema operacional, parece que o sistema executa duas cópias do mesmo programa que, por sua vez, sairão da função fork (). O processo filho recém-criado (relativo ao processo pai que o criou) não será mais executado, iniciando com a função main (). Deve-se lembrar que o processo filho não é uma cópia exata do processo pai, em particular, possui seu próprio espaço de endereço, seus próprios registros, seu próprio ponteiro para instruções executáveis e similares. Portanto, o valor retornado ao chamador da função fork () será diferente. Em particular, o processo pai receberá o valor PID do processo da criança como retorno e a criança receberá um valor igual a 0. Com base nesses códigos de retorno, já é possível separar os processos e forçar cada um deles a fazer seu trabalho. Além disso, a execução deste programa não é estritamente definida. Depois de dividir em 2 processos, o sistema operacional também começa a segui-los e a planejar seu trabalho. Se executado em um processador de núcleo único, um dos processos continuará funcionando, nesse caso, o pai e o processo filho receberá o controle. Quando você reinicia, a situação pode ser diferente.
Chamada em espera ()
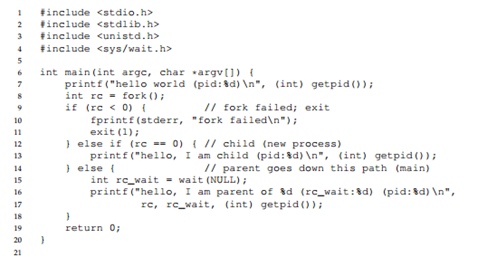
Considere o seguinte programa. Neste programa, devido à presença da chamada
wait () , o processo pai sempre aguardará o processo filho concluir seu trabalho. Nesse caso, obtemos uma saída de texto estritamente definida na tela.

Ligar para exec ()

Considere a chamada para
exec () . Essa chamada do sistema é útil quando queremos executar um programa completamente diferente. Aqui chamaremos
execvp () para executar o programa wc, que é um programa de contagem de palavras. O que acontece quando exec () é chamado? O nome do arquivo executável e alguns parâmetros são passados para esta chamada como argumentos. Depois disso, o código e os dados estáticos desse arquivo executável são baixados e seu próprio segmento com o código é substituído. As seções restantes da memória, como a pilha e a pilha, são reinicializadas. Após o qual o SO simplesmente executa o programa, transmitindo-lhe um conjunto de argumentos. Assim, não criamos um novo processo, simplesmente transformamos o atual programa em execução em outro programa em execução. Após a execução de exec (), o descendente dá a impressão de que o programa original parecia não iniciar em princípio.
Essa complicação de inicialização é absolutamente normal para o shell Unix e permite que ele execute código após chamar
fork () , mas antes de chamar
exec () . Um exemplo desse código pode ser ajustar o ambiente do shell às necessidades do programa que está sendo iniciado, antes de iniciá-lo diretamente.
Shell é apenas um programa de usuário. Ela mostra a linha de prompt e espera que você escreva algo nela. Na maioria dos casos, se você escrever o nome do programa, o shell encontrará sua localização, chamará o método fork () e, para criar um novo processo, chamará alguns dos tipos exec () e esperará que seja executado usando a chamada wait (). Quando o processo filho termina, o shell retorna da chamada wait () e exibe o prompt novamente e aguarda a entrada do próximo comando.
Separar fork () e exec () permite que o shell faça o seguinte, por exemplo:
arquivo wc> novo_arquivo.Neste exemplo, a saída do wc é redirecionada para um arquivo. A maneira como o shell consegue isso é bastante simples - ao criar um processo filho antes de chamar
exec () , o shell fecha o fluxo de saída padrão e abre o arquivo
new_file , para que toda a saída do programa
wc iniciado seja redirecionada para o arquivo em vez da tela.
Os pipes Unix são implementados de maneira semelhante, com a diferença de que eles usam a chamada pipe (). Nesse caso, o fluxo de saída do processo será conectado à fila de pipe localizada no kernel ao qual o fluxo de entrada de outro processo será conectado.