O aprendizado de máquina é usado em todo o ciclo de pedidos do Yandex.Taxi, e o número de componentes de serviço trabalhando graças ao ML está em constante crescimento. Para construí-los de maneira uniforme, precisávamos de um processo separado. Roman Khalkachev, Chefe do Serviço de Aprendizado de Máquina e Análise de Dados, falou sobre pré-processamento de dados, uso de modelos na produção, serviço de prototipagem e ferramentas relacionadas.
- Na minha opinião, algumas coisas novas são muito mais fáceis de perceber quando são contadas em algum exemplo simples. Portanto, para que o relatório não ficasse seco, decidi falar sobre uma das tarefas que estamos resolvendo. Usando o exemplo dela, mostrarei por que agimos dessa maneira.
Vamos formular o problema. Existem usuários de táxi que precisam ir do ponto A ao ponto B e há motoristas prontos para uma certa quantia para entregar esses usuários do ponto A ao ponto B. O usuário tem várias condições em que está. Ele chama um táxi, seleciona o ponto A, o ponto B, a tarifa e assim por diante, faz um pouso de táxi, dirige e, finalmente, faz um pouso. Hoje eu gostaria de falar sobre entrar em um carro e problemas que possam surgir.

Como regra, esses problemas estão relacionados ao fato de que uma pessoa precisa escolher um local para onde um táxi deve chegar. E aqui há uma série de dificuldades. Essas dificuldades estão relacionadas a quatro coisas que listei no slide.
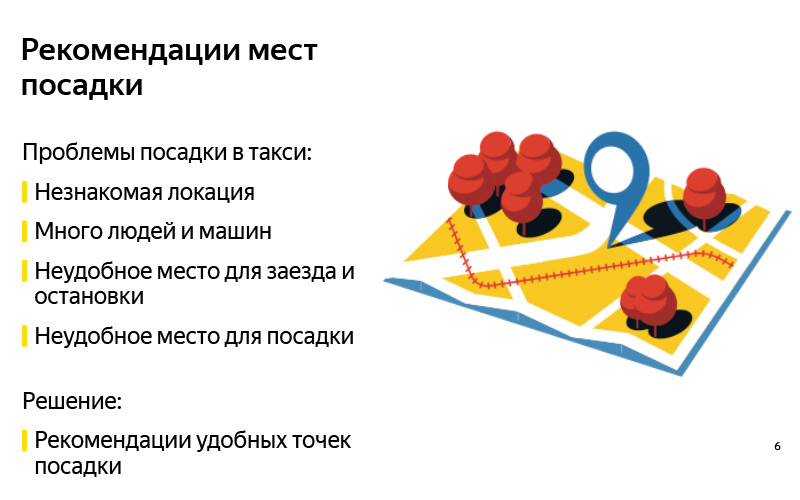
Primeiro, o local pode não ser familiar para o usuário. Como exemplo, você pode se imaginar que veio a algum grande shopping center, no qual você não costuma visitar. Você quer sair e não sabe realmente onde pode chamar um táxi aqui, onde o carro pode ligar, mas onde não pode, por exemplo, por causa da barreira. Existem problemas com o fato de que em alguns lugares há muitas pessoas, muitos carros e é difícil encontrar seu carro. Há lugares onde as pessoas costumam entrar no carro, é mais fácil chegar lá. E você pode não saber, estar em algum lugar novo, não necessariamente no shopping, onde exatamente aterrar. As dificuldades podem estar relacionadas ao fato de o motorista não poder dirigir até o local onde você chamou o táxi: ele é proibido de viajar, há uma grande saída do shopping, em frente à qual você não pode parar, etc.
Por outro lado, você pode ter problemas como usuário. O motorista chegou, está tudo bem, mas você não se sente à vontade para se sentar, porque todos desenterraram. Você pede ao motorista para dirigir para outro lugar. Existem outras razões.
O exemplo mais ilustrativo, a quintessência de todos os itens acima, é o aeroporto, no qual quase tudo é feito. Mesmo se você sair de Sheremetyevo com muita frequência, ainda é um local desconhecido para você, porque muitas coisas mudam para lá. Há muitas pessoas, muitos carros, lugares convenientes para aterrissar, outros desconfortáveis, mas, como regra, nenhum de nós se lembra disso.
A solução é lida no título do slide. Vamos recomendar ao usuário alguns lugares em que, em nossa opinião, é conveniente pousar. O pensamento parece óbvio, mas há muitas nuances aqui.
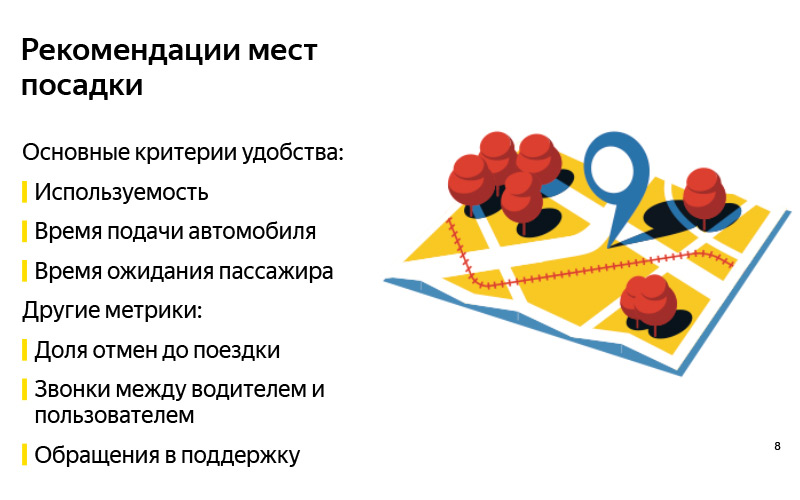
Para iniciantes, “conveniente” é um conceito subjetivo. Parece que antes de resolver o problema, é necessário formular alguns critérios para o fato de que o problema será resolvido corretamente. Nós formulamos três principais para nós mesmos. O primeiro critério é como em qualquer tarefa de recomendação: provavelmente, as recomendações são boas se forem usadas. Se mostrarmos esses pontos dos quais o usuário realmente sairá - esses provavelmente são bons pontos. Mas isso, é claro, não é tudo, porque você pode aprender a recomendar algo, mostrar, incentivar o usuário a usá-lo, mas não obtém nenhum lucro tangível (não obteremos como sistema, nem usuário, nem motorista). Portanto, é muito importante observar outras métricas. Nós escolhemos dois.
Se falarmos sobre um local de pouso para o qual o motorista possa chegar com facilidade, o tempo de entrega do veículo deverá ser reduzido. Por outro lado, se for mais fácil para o usuário encontrar um carro nesse local, é mais fácil pousar, então o tempo de espera do motorista pelo motorista deve ser reduzido. Essa é uma de nossas hipóteses, as quais consideramos um dado adquirido, e essas são algumas métricas que analisamos quando fazemos essas recomendações. Mas é claro que essas não são as únicas métricas a serem observadas. Você pode criar mais uma dúzia. Acho que cada um de vocês pode criar uma centena dessas métricas.
Aqui estão mais alguns exemplos. Essa pode ser a proporção de cancelamentos antes da viagem. Em teoria, deve diminuir se for mais fácil para o usuário pousar. Convencionalmente, são chamadas quando um usuário liga para o motorista tentando encontrá-lo ou, inversamente, o motorista liga para o usuário antes do início da viagem. Este apelo está em apoio, e com uma dúzia de outros.
Nós formulamos o problema. Compreendemos aproximadamente o critério de que podemos resolver esse problema. Vamos agora pensar em como resolver esse problema. A primeira coisa que vem à mente: recomendamos esses pontos de aterrissagem comprovados e compreensíveis. Aqui no slide está um exemplo do Centro Comercial Europeu. E sabemos com certeza que você pode dirigir até as saídas deste shopping center, e isso é algum tipo de orientação, graças à qual o usuário pode encontrar um motorista. Pode ser qualquer organização. Há um exemplo com o ABC of Taste em algum shopping center. Na minha opinião, este é o Yerevan Plaza. Esse também é um tipo de orientação para o usuário e o motorista, sobre os quais sabemos que você pode dirigir até lá.
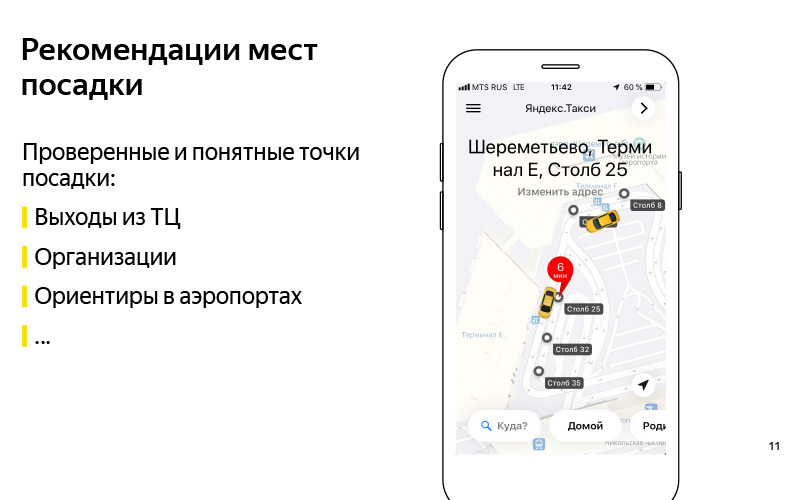
Estes podem ser marcos nos aeroportos de que falei. Convencionalmente, existem pólos em Sheremetyevo com números. É conveniente chamar um táxi e entrar no carro. Uma boa solução, mas tem um sinal de menos que não é muito escalável. Temos muitos países, centenas de cidades, um grande número de diferentes shopping centers, aeroportos, trocas difíceis, lugares desconhecidos para os quais esses pontos são difíceis de serem feitos manualmente, e mantê-los atualizados é ainda mais difícil. É aqui que vem em nosso auxílio o que é alto chamado de "inteligência artificial". Prefiro chamá-lo de mineração de dados ou aprendizado de máquina.
O aprendizado de máquina precisa de algum tipo de dados, e nós realmente temos esses dados. Outra maneira de resolver o problema automaticamente é usar esses dados. A ideia de alto nível é que tenhamos dados sobre GPS, registros de aplicativos e haja um gráfico de estradas. E podemos entender onde os usuários realmente entram no carro. Não os pontos onde eles chamam o carro, mas onde eles pousam. E com base nisso, faça algo assim.

Esses pontos já são recebidos automaticamente para o centro de negócios Aurora, onde atualmente está nossa equipe Yandex.Taxi.
Falei alto nível sobre a nossa tarefa. Agora, vamos falar com mais detalhes sobre em que estágios a solução para esse problema consiste. É claro que há uma etapa de preparação dos dados.

Que dados temos? Em primeiro lugar, temos os dados de GPS de nossos usuários e os dados de GPS de nossos drivers. Quando eles usam nosso aplicativo, sabemos a localização aproximada dos usuários. É claro que o GPS tem um grande erro, na região de 13 a 15 metros, mas, no entanto, há algo. Em segundo lugar, temos informações contidas nos logs do aplicativo sobre quando o driver mudou do status "Estou aguardando o usuário" para o status "Estou levando o usuário". Pode-se supor que, nessa época, o motorista esperou pelo usuário, entrou no carro e partiu. Em torno deste local, foi feito um pouso. E nós temos um gráfico de estradas. Um gráfico de estradas não é apenas um conjunto de arestas, ruas, mas também meta-informações adicionais: barreiras, informações sobre estacionamento etc. Com base nesses dados, você já pode obter algum tipo de pontos automáticos.
Estes foram os dados de origem. E na saída, queremos duas coisas. Estes são alguns dos chamados candidatos a pontos de aterrissagem. Como eles acontecem? É uma pena que não tenha sido possível mostrar o vídeo. O seguinte acontece aproximadamente. Temos muitos pontos de GPS nos quais sabemos que o motorista mudou do status "Aguardando um passageiro" para o status de "Vamos". Podemos, condicionalmente, desenhá-los no gráfico, ou seja, projetá-los no gráfico de estradas, porque, em regra, o carro começa a se mover de alguma estrada. Neste gráfico, execute algum tipo de agrupamento desses pontos. E para conseguir um grande número de candidatos - esses são os lugares em que alguns usuários entraram no carro, e isso era normal, conveniente para eles. Não onde eles ligaram, mas onde eles acabaram sentados.
Depois disso, quando temos muitos candidatos e temos algum usuário on-line, sabemos a sua localização, então ele abriu o aplicativo e quer chamar um táxi, então podemos escolher os cinco melhores dentre um grande número de candidatos e mostrá-los. Os cinco melhores são determinados por um modelo de aprendizado de máquina que aprende a classificar todos os candidatos de acordo com a probabilidade de o usuário neste momento, considerando sua localização e seu histórico de viagens, ser mais conveniente sair. E aproximadamente dessa maneira, podemos gerar automaticamente esses pontos. Além disso, se em algum momento eles desenterram condicionalmente em algum lugar, ou seja, torna-se desconfortável chamar um táxi, ou em algum lugar eles colocam uma placa proibindo uma parada, e motoristas e usuários realmente param de aterrissar neste local no momento em que o algoritmo entender isso, e os dados serão atualizados.
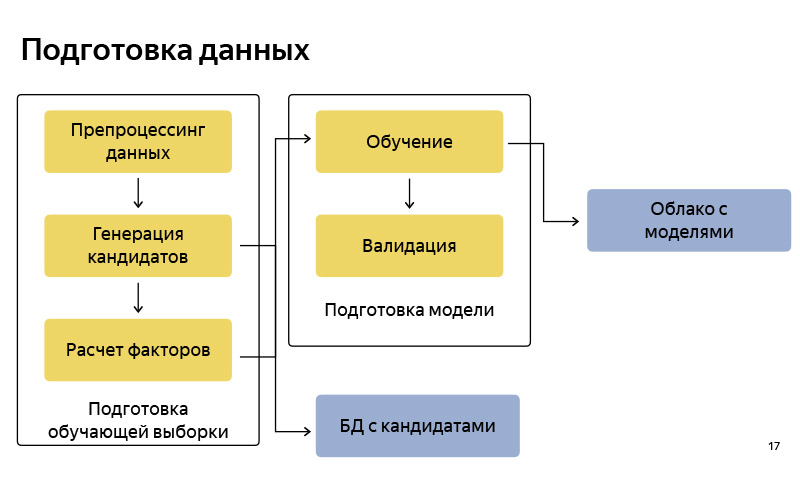
Este é aproximadamente o diagrama de blocos de como preparamos os dados. Portanto, é bastante padrão, como em qualquer pipeline de aprendizado de máquina. Há preparação de dados, há uma geração de candidatos de acordo com o algoritmo, disse uma versão simplificada. Armazenamos esses candidatos em um determinado banco de dados. Depois disso, preparamos um pool para treinamento (amostra de treinamento), no qual existe, condicionalmente, um usuário, tempo, meta-informação, um conjunto de candidatos e sabe-se de que ponto o usuário acabou saindo. Sobre isso, treinamos o modelo de classificação. E então, de acordo com as previsões de probabilidade, classificamos os candidatos. Quando o modelo está pronto, fazemos o upload para alguma nuvem, onde está bem armazenado.
Quais ferramentas usamos na preparação dos dados? Basicamente, toda a preparação de dados que escrevemos em Python, na pilha de Python: estes são padrão NumPy, Pandas, Scikit-learn, etc. Temos muitos dados. Temos milhões de viagens por mês. Muitos dados sobre GPS, trilhas de drivers, logs de aplicativos, portanto, precisamos processá-los da mesma forma no cluster. Para fazer isso, usamos o MapReduce da nossa versão intra-Yandex, chamada YT, e há uma biblioteca escrita em Python, que permite que alguns mapeadores e redutores sejam iniciados e faça alguns cálculos em um cluster grande.
Finalmente, quando o pipeline estiver pronto, precisamos automatizá-lo para que os dados estejam atualizados e, para isso, usamos o Nirvana e Hitman. Isso também é desenvolvimento intra-Yandex. O Nirvana é uma estrutura de gerenciamento de computação em cluster. De fato, ela sabe como executar praticamente qualquer programa, tolerante a falhas e ter cross DC (00:14:53). E no caso de algo cair, ela sabe como reiniciá-lo, para criar lançamentos após a ocorrência de qualquer evento. etc.

Isso é mais ou menos como é a interface da web do nosso cluster MapReduce. Pode-se ver aqui que temos muitas máquinas, nós nos quais os cálculos são realizados.
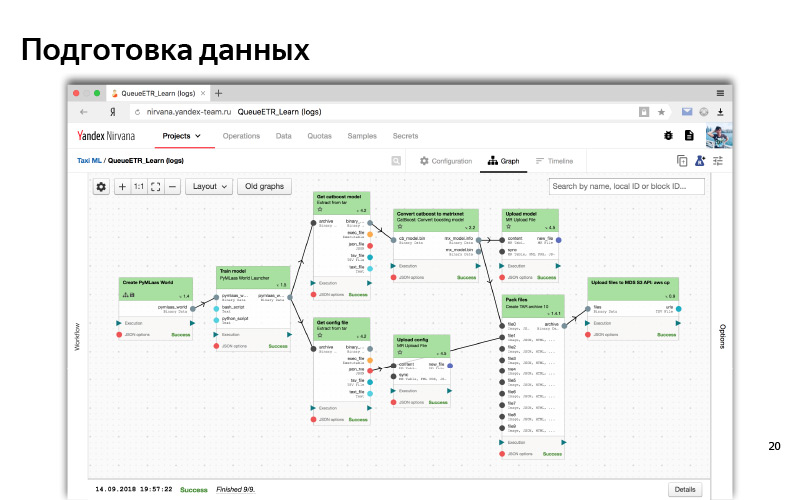
E assim, na interface da Web, parece um processo típico de algum tipo de pré-processamento de dados e treinamento de modelo. Este é um gráfico de dependência. Dependências são como dados, quando uma parte (um cubo) está aguardando dados de outro cubo; e dependência lógica (primeiro preparamos todos os dados e depois iniciamos o treinamento). Este é algum tipo de sistema automatizado. Por tudo isso, geralmente usamos Python.
Formulamos o problema, formulamos critérios de sucesso, aprendemos a resolvê-lo de alguma forma offline, até criamos algum tipo de modelo e parece funcionar de acordo com algumas métricas offline - ele realmente prevê os pontos de onde o usuário sai e encontra esses pontos o que, ao que parece, deve reduzir o tempo de espera e a entrega do carro.

Vamos tentar esses modelos, usar esses dados. Para fazer isso, imagine o que é o serviço Yandex.Taxi.
Um diagrama muito superficial se parece com isso. Existem usuários, eles têm um aplicativo e existem drivers, eles também têm um aplicativo chamado "Taxímetro". Esses aplicativos de alguma forma se comunicam com o back-end, e o back-end é um conjunto de microsserviços que se comunicam - Ilya
falou sobre isso. Um dos microsserviços é o nosso serviço, nossa equipe faz isso, é chamado de ML como serviço, MLaaS.

Tudo o que você precisa saber sobre ele é o MLaaS escrito em C ++, com base no chamado Fastcgi Daemon. Esta é uma biblioteca de código aberto, que, grosso modo, é uma estrutura para escrever um servidor Web que pode obter e publicar solicitações, tudo é padrão. Foi escrito em Yandex, em código aberto. Usamos a versão dopada. O que esse serviço pode fazer? Ele sabe como trabalhar com modelos: aplique-os, mantenha-os em casa e, às vezes, atualize-os, acesse esta maravilhosa nuvem, onde os modelos são atualizados, salvos e baixados regularmente.
Cada funcionalidade, por exemplo, esses pontos de aterrissagem - dentro de nós os chamamos de pontos de captação - ou, por exemplo, as dicas dos pontos B sobre os quais Ilya falou e constantemente quebrou no relatório anterior, cada uma dessas funcionalidades, onde há algum tipo de aprendizado de máquina, corresponde a manipulador, que armazena a lógica de receber uma solicitação, gerar fatores de aprendizado de máquina e aplicar modelos e gerar uma resposta. Obviamente, esse serviço não é isolado, podendo acessar algumas fontes de dados adicionais, bancos de dados e alguns outros microsserviços.
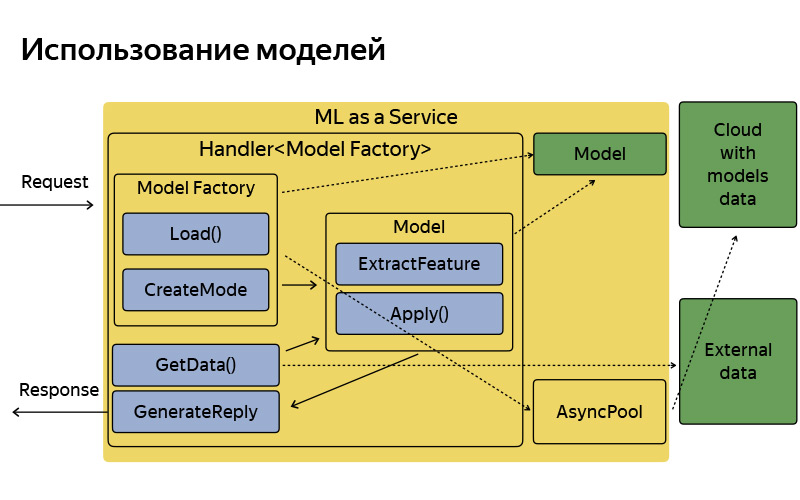
É assim que é organizado, tem uma arquitetura bastante simples. Eu não queria me deter neste slide em detalhes, só queria dizer que, por convenção, a arquitetura é muito simples. Quando a solicitação chega, há uma fábrica de modelos, que às vezes faz o download desses modelos na nuvem. Na memória, eles são armazenados em uma única cópia. Para cada solicitação, é criado um objeto de modelo bastante leve, que extrai recursos, aplica e gera uma resposta.

Mas o que temos para o momento atual? Eu já lhe disse que temos preparação de dados, treinamento, vários estudos, experimentos e tudo isso está escrito em Python Stack, e há alguma produção escrita em C ++, simplesmente porque temos grandes demandas de eficiência e produtividade. Quando você vive nesse ecossistema, dois problemas surgem.
Primeiro de tudo, este é um problema de experimentos. Por exemplo, um cientista de dados que trabalha em nossa equipe teve uma ideia. Se você executar algum tipo de algoritmo de cluster ou classificação com parâmetros ligeiramente diferentes, poderá obter melhor qualidade. Ele tentou testar sua hipótese off-line, incorporada ao nosso processo Python, calculou-a, e realmente acontece. E agora ele quer um experimento AB, ou seja, parte dos usuários para mostrar o novo algoritmo e medir algumas métricas já on-line: o tempo realmente diminui, espera, está aumentando o uso. Para fazer isso, ele possui, condicionalmente, cinco versões de seu algoritmo, nas quais ele acredita, que fornecem offline de boa qualidade: implemente em C ++ e conduza um experimento AB. E após esse experimento da AB, talvez todos os cinco sejam desperdiçados, ou seja, a qualidade deles online ficará pior do que estavam offline, ou seja, pior do que na produção. Ou seja, o processo de experimentação leva muito tempo devido ao fato de que, condicionalmente, duas linguagens diferentes, duas tecnologias diferentes.
Isso é para recursos existentes. E há novos. Uma vez que esses pontos de captação também eram idéias que eu queria verificar rapidamente. Não gaste dois meses de desenvolvimento - é aconselhável obter algo em três semanas. Criar esse protótipo é bastante trabalhoso. Primeiro, escreva em Python a extração de recursos, simplesmente porque é conveniente - mova-se rapidamente, como eles dizem. Você pode criar qualquer protótipo em Python, existem muitas bibliotecas para análise de dados. Você experimentou no seu laptop e agora deseja verificar os usuários. E fazer um protótipo acabou bem difícil. Chegamos à conclusão de que precisamos de algum serviço adicional para montar esses protótipos rapidamente - condicionalmente em uma semana ou até em um dia - e também para realizar experimentos AB.
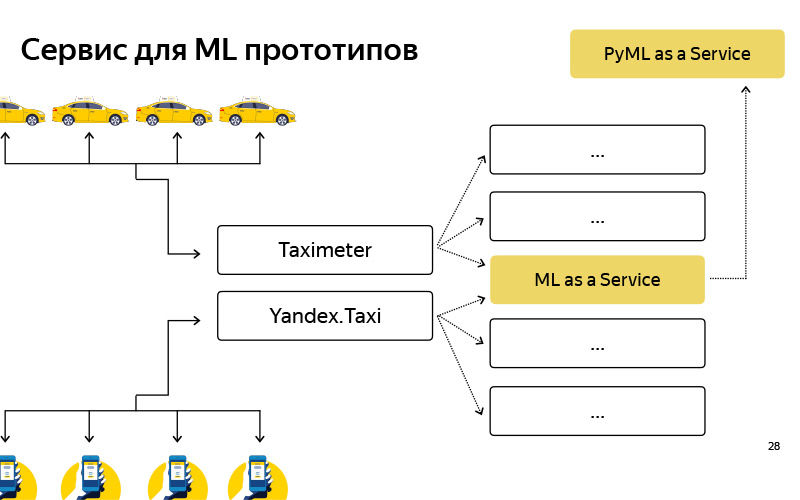
Criamos esse serviço, chamado PyMLaaS. Como ele é? De fato, este é um análogo completo do MLaaS, sobre o qual falei antes, mas escrito em Python baseado em Flask, nginx e Gunicorn. A arquitetura é bastante simples, igual à do MLaaS, mas há uma oportunidade de descobrir rapidamente algum protótipo de suas experiências offline. Além disso, organizamos esse proxy no nível nginx, para que, condicionalmente, tivéssemos a oportunidade de encaminhar parte da carga do MLaaS para o PyMLaaS e, assim, experimentar.

Ou seja, movemos alguns parâmetros e queremos verificar como isso afeta os usuários. Iniciamos 5% da carga no PyMLaaS e veremos o que acontece no experimento. Por fim, é conveniente criar protótipos. Criei um protótipo de algum novo recurso, vi no PyMLaaS e você pode testá-lo imediatamente na produção.
Gostamos tanto que a idéia surgiu - por que não usá-la o tempo todo? Porque, condicionalmente, existem recursos que exigem uma grande carga, 1000 RPS, grandes requisitos de memória. Eu quero ter um paralelismo bastante flexível. Porém, para alguns recursos, para alguns produtos ou serviços que não têm demandas tão grandes de carga, desempenho, RPS etc., estamos usando esse serviço com êxito.

Para resumir. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .