Em 26 de fevereiro, realizamos a reunião do Apache Ignite GreenSource, onde os colaboradores de código aberto do projeto
Apache Ignite se apresentaram. Um evento importante na vida dessa comunidade foi a reestruturação do componente
Ignite Service Grid , que permite implantar microsserviços personalizados diretamente no cluster Ignite.
Vyacheslav Daradur , desenvolvedor sênior do Yandex e colaborador do Apache Ignite por mais de dois anos, falou sobre esse difícil processo na reunião.
Para começar, o que é o Apache Ignite em geral. Este é um banco de dados que é um repositório de Chave / Valor distribuído com suporte para SQL, transacional e cache. Além disso, o Ignite permite implantar serviços do usuário diretamente no cluster Ignite. O desenvolvedor torna disponível todas as ferramentas fornecidas pelo Ignite - estruturas de dados distribuídas, sistema de mensagens, streaming, computação e grade de dados. Por exemplo, ao usar o Data Grid, o problema de administrar uma infraestrutura separada para o armazém de dados e, como resultado, a sobrecarga resultante disso desaparece.

Usando a API da Grade de Serviço, você pode implantar um serviço simplesmente especificando o esquema de implantação na configuração e, consequentemente, o próprio serviço.
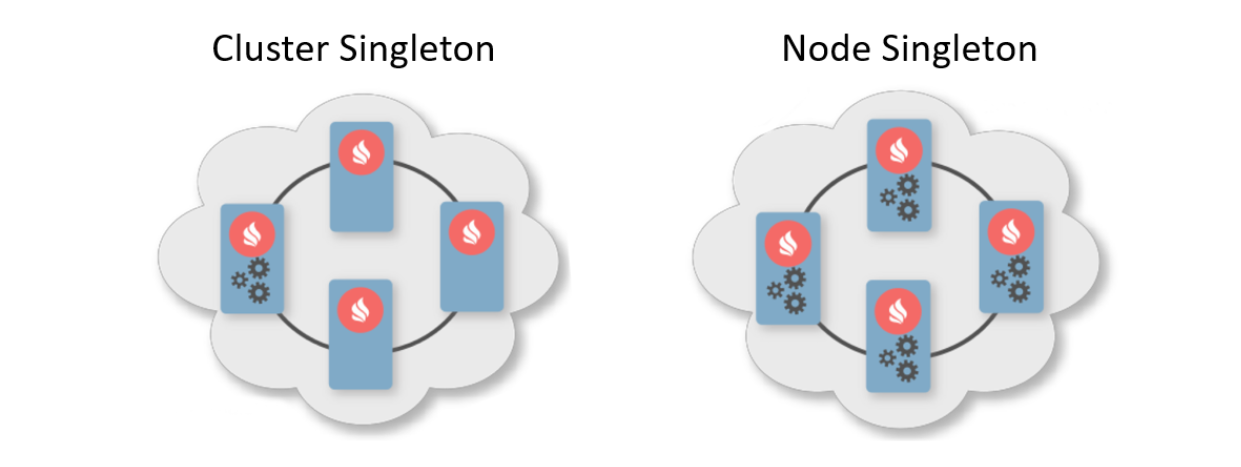
Normalmente, um padrão de implementação é uma indicação do número de instâncias que devem ser implementadas nos nós do cluster. Existem dois padrões de implantação típicos. A primeira é o Cluster Singleton: a qualquer momento no cluster, uma instância do serviço do usuário estará disponível. A segunda é o Nó Singleton: uma instância do serviço é implantada em cada nó do cluster.
O usuário também pode especificar o número de instâncias de serviço em todo o cluster e definir um predicado para filtrar nós adequados. Nesse cenário, a grade de serviço calcula a distribuição ideal para a implantação de serviços.
Além disso, existe um recurso como o Affinity Service. Afinidade é uma função que define o relacionamento de chaves com partições e o relacionamento de partes com nós na topologia. Usando a chave, você pode determinar o nó principal no qual os dados são armazenados. Assim, você pode associar seu próprio serviço à chave e ao cache da função de afinidade. Se a função de afinidade mudar, uma reoperação automática ocorrerá. Portanto, o serviço será sempre colocado próximo aos dados que ele deve manipular e, consequentemente, reduzir a sobrecarga de acesso às informações. Esse esquema pode ser chamado de tipo de computação colocada.
Agora que descobrimos qual é a beleza do Service Grid, falaremos sobre seu histórico de desenvolvimento.
O que era antes
A implementação anterior do Service Grid foi baseada no cache do sistema replicado transacional Ignite. A palavra "cache" em Ignite significa armazenamento. Ou seja, isso não é algo temporário, como você pode pensar. Apesar do cache ser replicável e de cada nó conter todo o conjunto de dados, dentro do cache ele possui uma visualização particionada. Isso ocorre devido à otimização do armazenamento.

O que aconteceu quando um usuário quis implantar um serviço?
- Todos os nós no cluster se inscreveram para atualizar dados no repositório usando o mecanismo de Consulta Contínua interno.
- Um nó inicial em uma transação confirmada por leitura fez um registro no banco de dados que continha a configuração do serviço, incluindo a instância serializada.
- Ao receber a notificação de um novo registro, o coordenador calculou a distribuição com base na configuração. O objeto resultante é gravado de volta no banco de dados.
- Os nós lêem informações sobre a nova distribuição e serviços implementados para
se necessário.
O que não nos convinha
Em algum momento, chegamos à conclusão: é impossível trabalhar com serviços. Houve várias razões.
Se algum tipo de erro ocorreu durante a implantação, você poderá descobrir isso apenas nos logs do nó em que tudo aconteceu. Havia apenas uma implantação assíncrona; portanto, após retornar o controle do método de implantação para o usuário, demorou um tempo extra para iniciar o serviço - e naquele momento o usuário não conseguia controlar nada. Para desenvolver ainda mais o Service Grid, ver novos recursos, atrair novos usuários e tornar a vida mais fácil para todos, você precisa mudar alguma coisa.
Ao projetar uma nova grade de serviço, queríamos principalmente fornecer uma garantia de implantação síncrona: assim que o usuário retornasse o controle da API, ele poderia usar imediatamente os serviços. Eu também queria dar ao iniciador a oportunidade de lidar com erros de implantação.
Além disso, eu queria facilitar a implementação, ou seja, fugir das transações e do reequilíbrio. Apesar do cache ser replicável e não haver balanceamento, houve problemas durante uma grande implantação com muitos nós. Ao alterar a topologia, os nós precisam trocar informações e, com uma grande implantação, esses dados podem pesar muito.
Quando a topologia era instável, o coordenador precisava recalcular a distribuição de serviços. E, em geral, quando você precisa trabalhar com transações em uma topologia instável, isso pode levar a erros difíceis de prever.
Os problemas
O que muda global sem acompanhar problemas? A primeira delas foi uma mudança na topologia. Você precisa entender que a qualquer momento, mesmo no momento da implantação do serviço, um nó pode entrar ou sair de um cluster. Além disso, se no momento da implantação o nó entrar no cluster, será necessário transferir consistentemente todas as informações sobre os serviços para o novo nó. E estamos falando não apenas sobre o que já foi implantado, mas também sobre implantações atuais e futuras.
Este é apenas um dos problemas que podem ser reunidos em uma lista separada:
- Como implantar serviços configurados estaticamente ao iniciar um nó?
- Saída do nó do cluster - e se o host hospedar serviços?
- O que fazer se o coordenador mudou?
- O que fazer se o cliente se reconectar ao cluster?
- Preciso processar solicitações de ativação / desativação e como?
- Mas e se eles chamarem o cache Destroy e tivermos serviços de afinidade vinculados a ele?
E isso não é tudo.
Solução
Como alvo, escolhemos a abordagem orientada a eventos com a implementação de processos de comunicação usando mensagens. O Ignite já implementou dois componentes que permitem que os nós encaminhem mensagens entre si - communication-spi e discovery-spi.
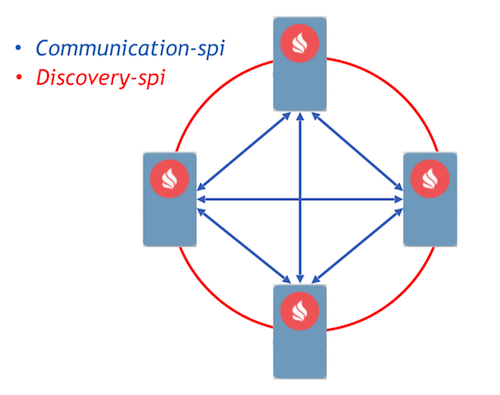
O Communication-spi permite que os nós se comuniquem e encaminhem mensagens diretamente. É adequado para o envio de grandes quantidades de dados. O Discovery-spi permite enviar uma mensagem para todos os nós no cluster. Em uma implementação padrão, isso é feito de acordo com a topologia em anel. Também há integração com o Zookeeper; nesse caso, a topologia em estrela é usada. Outro ponto importante a ser observado: o discovery-spi garante que a mensagem será entregue na ordem correta para todos os nós.
Considere o protocolo de implantação. Todas as solicitações de usuários para implantação e distribuição são enviadas via discovery-spi. Isso fornece as seguintes
garantias :
- A solicitação será recebida por todos os nós no cluster. Isso permitirá que você continue processando a solicitação ao alterar o coordenador. Isso também significa que em uma mensagem cada nó terá todos os metadados necessários, como a configuração do serviço e sua instância serializada.
- Uma ordem estrita de entrega de mensagens permite resolver conflitos de configuração e solicitações concorrentes.
- Como a entrada do nó na topologia também é processada pelo discovery-spi, todos os dados necessários para trabalhar com serviços chegarão ao novo nó.
Após o recebimento da solicitação, os nós no cluster a validam e formam tarefas para processamento. Essas tarefas são enfileiradas e processadas em outro encadeamento por um trabalhador separado. Isso é implementado dessa maneira, porque uma implantação pode levar um tempo considerável e atrasar um fluxo de descoberta caro, que é inaceitável.
Todas as solicitações da fila são processadas pelo gerenciador de implementação. Ele tem um trabalhador especial que extrai uma tarefa dessa fila e a inicializa para iniciar a implantação. Depois disso, ocorrem as seguintes ações:
- Cada nó calcula independentemente a distribuição graças a uma nova função de atribuição determinística.
- Os nós formam uma mensagem com os resultados da implantação e a enviam ao coordenador.
- O coordenador agrega todas as mensagens e gera o resultado de todo o processo de implantação, que é enviado via discovery-spi para todos os nós no cluster.
- Após o recebimento do resultado, o processo de implantação é concluído, após o qual a tarefa é removida da fila.
 Novo design orientado a eventos: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Novo design orientado a eventos: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.javaSe ocorreu um erro no momento da implantação, o nó inclui imediatamente esse erro na mensagem, que o envia ao coordenador. Após a agregação da mensagem, o coordenador terá informações sobre todos os erros durante a implantação e enviará essa mensagem via discovery-spi. As informações de erro estarão disponíveis em qualquer nó do cluster.
De acordo com esse algoritmo, todos os eventos importantes na grade de serviço são processados. Por exemplo, uma alteração na topologia também é uma mensagem de descoberta-spi. E, em geral, quando comparado com o que era, o protocolo acabou sendo bastante leve e confiável. Tanto para lidar com qualquer situação durante a implantação.
O que acontecerá a seguir
Agora sobre os planos. Qualquer grande desenvolvimento no projeto Ignite é realizado como uma iniciativa para melhorar o Ignite, o chamado IEP. O redesenho da Grade de Serviço também possui um IEP -
IEP No. 17 com o nome de brincadeira "Mudança de Óleo na Grade de Serviço". Mas, na verdade, mudamos não o óleo no motor, mas o motor inteiro.
Dividimos as tarefas no IEP em 2 fases. A primeira é uma fase importante, que consiste em alterar o protocolo de implantação. Já foi colocado no assistente, você pode tentar a nova Service Grid, que aparecerá na versão 2.8. A segunda fase inclui muitas outras tarefas:
- Redeep quente
- Versão de serviço
- Maior resiliência
- Thin client
- Ferramentas para monitorar e contar várias métricas
Por fim, podemos aconselhar o Service Grid para a construção de sistemas de alta disponibilidade tolerantes a falhas. Também convidamos você a
lista dev e lista de usuários para compartilhar sua experiência. Sua experiência é realmente importante para a comunidade; isso ajudará você a entender para onde ir em seguida, como desenvolver o componente no futuro.