Oi No final do ano passado, começamos a ocultar automaticamente os números das placas nas fotografias dos cartões de anúncio Avito. Sobre por que fizemos isso e quais são as maneiras de resolver esses problemas, leia o artigo.

Desafio
No Avito, em 2018, foram vendidos 2,5 milhões de carros. Isso é quase 7000 por dia. Todos os anúncios à venda precisam de uma ilustração - foto de um carro. Mas pelo número do estado, você pode encontrar muitas informações adicionais sobre o carro. E alguns de nossos usuários tentam fechar a matrícula por conta própria.
Os motivos pelos quais os usuários desejam ocultar o número da placa podem ser diferentes. De nossa parte, queremos ajudá-los a proteger seus dados. E tentamos melhorar os processos de venda e compra para os usuários. Por exemplo, um serviço de número anônimo trabalha conosco há muito tempo: quando você vende um carro, um número de celular temporário é criado para você. Bem, para proteger os dados das placas, anonimizamos as fotos.

Visão geral da solução
Para automatizar o processo de proteção de fotos do usuário, você pode usar redes neurais convolucionais para detectar um polígono com uma placa de carro.
Agora, para a detecção de objetos, são usadas arquiteturas de dois grupos: redes de dois estágios, por exemplo, Faster RCNN e Mask RCNN; estágio único (single shot) - SSD, YOLO, RetinaNet. Detectar um objeto é a derivação das quatro coordenadas do retângulo nas quais o objeto de interesse está inscrito.
As redes mencionadas acima são capazes de encontrar muitos objetos de classes diferentes nas fotos, o que já é redundante para solucionar o problema de busca de placas, porque geralmente temos apenas um carro nas fotos (há exceções quando as pessoas tiram fotos do carro vendido e do vizinho aleatório). , mas isso acontece muito raramente, portanto, isso pode ser negligenciado).
Outra característica dessas redes é que, por padrão, elas produzem uma caixa delimitadora com lados paralelos aos eixos de coordenadas. Isso acontece porque um conjunto de tipos predefinidos de quadros retangulares chamados caixas âncora é usado para detecção. Mais precisamente, primeiro usando uma rede convolucional (por exemplo, resnet34), uma matriz de atributos é obtida a partir da figura. Então, para cada subconjunto de atributos obtidos usando a janela deslizante, ocorre uma classificação: existe um objeto para a caixa âncora k ou não e uma regressão é realizada nas quatro coordenadas do quadro, que ajustam sua posição.
Leia mais sobre isso
aqui .
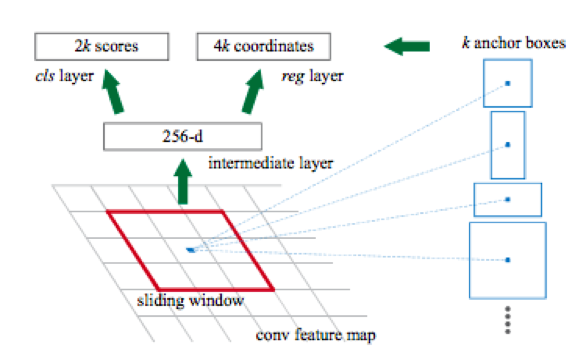
Depois disso, existem mais duas cabeças:
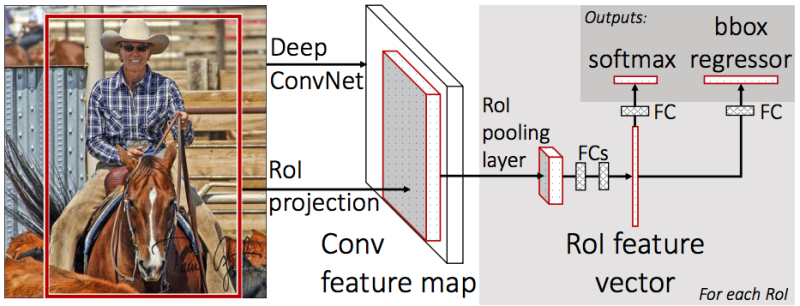
um para classificar o objeto (cão / gato / planta etc.),
o segundo (regressor bbox) - para regressão das coordenadas do quadro obtidas na etapa anterior, a fim de aumentar a proporção da área do objeto para a área do quadro.
Para prever o quadro de boxe girado, você precisa alterar o regressor bbox para obter também o ângulo de rotação do quadro. Se isso não for feito, será de alguma forma.

Além do R-CNN mais rápido de dois estágios, existem detectores de um estágio, como o RetinaNet. Difere da arquitetura anterior, pois prediz imediatamente a classe e o quadro, sem o estágio preliminar de propor seções da imagem que podem conter objetos. Para prever máscaras rotacionadas, você também deve alterar o cabeçalho da sub-rede da caixa.
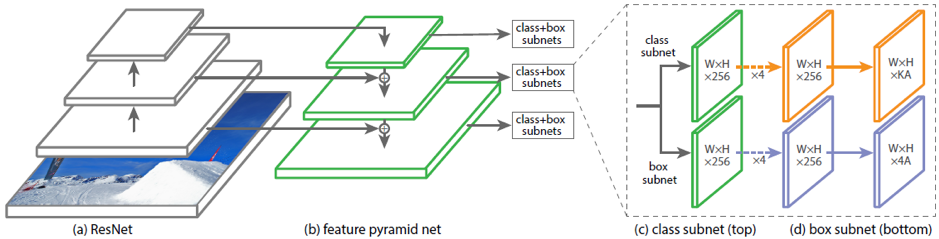
Um exemplo de arquiteturas existentes para prever caixas delimitadoras giradas é o DRBOX. Essa rede não usa o estágio preliminar da proposta da região, como no RCNN mais rápido; portanto, é uma modificação dos métodos de um estágio. Para treinar essa rede, K é rotacionado em certos ângulos da caixa delimitadora (rbox). A rede prevê as probabilidades de cada K rbox conter o objeto de destino, coordenadas, tamanho da bbox e ângulo de rotação.

Modificar a arquitetura e treinar novamente uma das redes consideradas em dados com caixas delimitadoras giradas é uma tarefa realizável. Mas nosso objetivo pode ser alcançado com mais facilidade, porque o escopo da rede que temos é muito mais restrito - apenas para ocultar placas.
Portanto, decidimos começar com uma rede simples para prever os quatro pontos do número e, posteriormente, será possível complicar a arquitetura.
Dados
A montagem do conjunto de dados é dividida em duas etapas: para coletar fotos de carros e marcar a área com uma placa. A primeira tarefa já foi resolvida em nossa infraestrutura: armazenamos cuidadosamente todos os anúncios que já foram colocados no Avito. Para resolver o segundo problema, usamos Toloka. No
toloka.yandex.ru/requester, criamos uma tarefa:
A tarefa deu uma fotografia do carro. É necessário destacar a placa do carro usando um quadrilátero. Nesse caso, o número do estado deve ser alocado com a maior precisão possível.

Usando o Toloka, você pode criar tarefas para marcar dados. Por exemplo, avalie a qualidade dos resultados da pesquisa, marque diferentes classes de objetos (textos e imagens), marque vídeos, etc. Eles serão executados pelos usuários da Toloka, pela taxa que você cobrar. Por exemplo, no nosso caso, os tolokers devem destacar o aterro com o número da placa do carro na foto. Em geral, é muito conveniente marcar um grande conjunto de dados, mas obter alta qualidade é bastante difícil. Há muitos bots na multidão, cuja tarefa é obter dinheiro de você, dando respostas aleatoriamente ou usando algum tipo de estratégia. Para combater esses bots, existe um sistema de regras e verificações. A verificação principal é a mistura de perguntas de controle: você marca manualmente parte das tarefas usando a interface Toloki e depois as mistura na tarefa principal. Se a marcação é frequentemente confundida com perguntas de controle, você a bloqueia e não leva em consideração a marcação.
Para a tarefa de classificação, é muito simples determinar se a marcação está errada ou não e, para o problema de destacar uma região, não é tão simples. A maneira clássica é contar IoU.
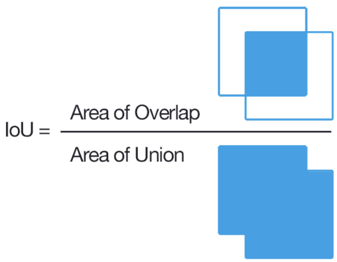
Se essa proporção for menor que um determinado limite para várias tarefas, esse usuário será bloqueado. No entanto, para dois quadrângulos arbitrários, o cálculo da IoU não é tão simples, especialmente porque no Tolok é necessário implementá-lo em JavaScript. Fizemos um pequeno hack e acreditamos que o usuário não se enganou se, para cada ponto do polígono de origem em um pequeno bairro, houvesse um ponto marcado com um escriba. Também existe uma regra de resposta rápida para bloquear os usuários que responderem com muita rapidez, captcha, discrepância com a opinião da maioria etc. Depois de definir essas regras, você pode esperar uma marcação muito boa, mas se realmente precisa de alta qualidade e marcação complexa, precisa contratar especificamente freelancers-escritores. Como resultado, nosso conjunto de dados chegou a 4 mil imagens marcadas e custou US $ 28 na Tolok.
Modelo
Agora vamos criar uma rede para prever os quatro pontos da área. Obteremos os sinais usando resnet18 (11,7 milhões de parâmetros versus 21,8 milhões de parâmetros para resnet34), depois faremos uma regressão para quatro pontos (oito coordenadas) e uma classificação para saber se há uma placa na foto ou não. A segunda cabeça é necessária, porque em anúncios de venda de carros, nem todas as fotos com carros. A foto pode ser um detalhe do carro.

Semelhante a nós, é claro, não é necessário detectar.
Realizamos o treinamento de dois objetivos ao mesmo tempo, adicionando ao conjunto de dados uma foto sem placa com uma caixa delimitadora (0,0,0,0,0,0,0,0,0) alvo e um valor para o classificador “imagem com / sem placa” - (0, 1)
Em seguida, você pode criar uma única função de perda para ambos os objetivos como a soma das seguintes perdas. Para regressão às coordenadas do polígono da placa, usamos uma perda suave de L1.
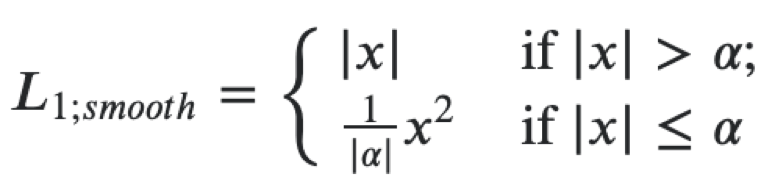
Pode ser interpretado como uma combinação de L1 e L2, que se comporta como L1 quando o valor absoluto do argumento é grande e como L2 quando o valor do argumento é próximo de zero. Para classificação, usamos perda softmax e crossentropy. O extrator de recursos é resnet18, usamos pesos pré-treinados no ImageNet, depois treinamos o extrator e lideramos nosso conjunto de dados. Nesse problema, usamos a estrutura mxnet, pois é a principal para visão computacional no Avito. Em geral, a arquitetura de microsserviço permite que você não esteja vinculado a uma estrutura específica, mas quando você tem uma grande base de código, é melhor usá-la e não escrever o mesmo código novamente.
Tendo recebido uma qualidade aceitável em nosso conjunto de dados, procuramos os designers para obter uma placa com o logotipo Avito. No começo, tentamos fazer isso sozinhos, é claro, mas não parecia muito bonito. Em seguida, você precisa alterar o brilho da placa do Avito para o brilho da área original com a placa e pode sobrepor o logotipo na imagem.

Lançamento em prod
O problema da reprodutibilidade dos resultados, suporte e desenvolvimento de projetos, resolvido com algum erro no mundo do desenvolvimento de back-end e front-end, permanece aberto onde é necessário o uso de modelos de aprendizado de máquina. Você provavelmente precisou entender o modelo de código legado. É bom que o leia-me tenha links para artigos ou repositórios de código aberto nos quais a solução foi baseada. O script para iniciar a reciclagem pode falhar com erros, por exemplo, a versão cudnn foi alterada e essa versão do tensorflow não funciona mais com esta versão do cudnn, e o cudnn não funciona com esta versão dos drivers da nvidia. Talvez para o treinamento tenhamos usado um iterador de acordo com os dados e para testes na produção outro. Isso pode continuar por algum tempo. Em geral, existem problemas de reprodutibilidade.
Tentamos removê-los usando o ambiente nvidia-docker para modelos de treinamento, ele possui todas as dependências necessárias para cuda e também instalamos dependências para python lá. A versão da biblioteca com um iterador de acordo com modelos de dados, aprimoramentos e inferência é comum para o estágio de treinamento / experimentação e para produção. Portanto, para treinar o modelo em novos dados, você precisa bombear o repositório para o servidor, executar o script de shell que coletará o ambiente do docker, dentro do qual o notebook jupyter aumentará. No interior, você terá todos os notebooks para treinamento e teste, o que certamente não falhará com um erro devido ao ambiente. É melhor, é claro, ter um arquivo train.py, mas a prática mostra que você sempre precisa olhar com atenção o que o modelo oferece e mudar alguma coisa no processo de aprendizado; assim, no final, você ainda executará o jupyter.
Os pesos do modelo são armazenados no git lfs - esta é uma tecnologia especial para armazenar arquivos grandes em um git. Antes disso, usamos artefatos, mas usar o git lfs é mais conveniente, pois ao fazer o download do repositório com o serviço, você obtém imediatamente a versão atual das balanças, como na produção. Os autotestes são escritos para inferência de modelo, para que você não possa implementar um serviço com pesos que não os passam. O serviço em si é iniciado na janela de encaixe dentro da infraestrutura de microsserviço no cluster kubernetes. Para monitorar o desempenho, usamos grafana. Após a rolagem, aumentamos gradualmente a carga nas instâncias de serviço com um novo modelo. Ao lançar um novo recurso, criamos testes a / b e emitimos um veredicto sobre o destino futuro do recurso, com base em testes estatísticos.
Como resultado: lançamos o encobrimento de números em anúncios na categoria automática para negociantes privados, o percentil 95 do tempo de processamento de uma imagem para ocultar o número é de 250 ms.