As pessoas aprendem arquitetura a partir de livros antigos que foram escritos para Java. Os livros são bons, mas fornecem uma solução para os problemas da época com instrumentos da época. O tempo mudou, o C # é mais parecido com o Scala leve do que com o Java, e existem poucos bons livros novos.
Neste artigo, examinaremos os critérios para código bom e código ruim, como e o que medir. Veremos uma visão geral das tarefas e abordagens típicas, analisaremos os prós e os contras. No final, haverá recomendações e práticas recomendadas para o design de aplicativos da web.
Este artigo é uma transcrição do meu relatório da conferência DotNext 2018 em Moscou. Além do texto, há um vídeo e um link para os slides abaixo do corte.

Slides e página de relatório no site .
Brevemente sobre mim: sou de Kazan, trabalho para o High Tech Group. Estamos desenvolvendo software para negócios. Recentemente, tenho ministrado um curso na Universidade Federal de Kazan, chamado Corporate Software Development. De tempos em tempos, ainda escrevo artigos sobre a Habr sobre práticas de engenharia, sobre o desenvolvimento de software corporativo.
Como você provavelmente já deve ter adivinhado, hoje vou falar sobre o desenvolvimento de software corporativo, como estruturar aplicativos da Web modernos:
- os critérios
- uma breve história do desenvolvimento do pensamento arquitetônico (o que foi, o que se tornou, o que são problemas);
- visão geral das falhas da arquitetura clássica de sopro
- a decisão
- análise passo a passo da implementação sem entrar em detalhes
- resultados.
Critérios
Nós formulamos os critérios. Eu realmente não gosto quando falar sobre design é do tipo "meu kung fu é mais forte que o seu kung fu". Uma empresa possui, em princípio, um critério específico chamado dinheiro. Todo mundo sabe que tempo é dinheiro, então esses dois componentes costumam ser os mais importantes.

Então, os critérios. Em princípio, a empresa costuma nos perguntar “o maior número possível de recursos por unidade de tempo”, mas com uma ressalva - esses recursos devem funcionar. E o primeiro passo em que isso pode ocorrer é a revisão de código. Ou seja, parece que o programador disse: "Farei isso em três horas". Três horas se passaram, a revisão entrou no código e o líder da equipe disse: "Oh, não, refaça." Existem mais três - e quantas iterações a revisão de código passou, você precisa multiplicar três horas.
O próximo ponto é o retorno do estágio de teste de aceitação. A mesma coisa Se o recurso não funcionar, isso não será feito. Essas três horas se estendem por uma semana, duas - normalmente, como de costume. O último critério é o número de regressões e erros que, apesar de serem testados e aceitos, passaram pela produção. Isso também é muito ruim. Há um problema com esse critério. É difícil rastrear, porque a conexão entre o fato de inserirmos algo no repositório e o fato de que algo quebrou após duas semanas pode ser difícil de rastrear. Mas, no entanto, é possível.
Desenvolvimento de arquitetura
Era uma vez, quando os programadores estavam começando a escrever programas, ainda não havia arquitetura, e todos faziam o que gostavam.

Portanto, temos um estilo arquitetônico tão amplo. Isso é chamado de "código de macarrão" aqui, eles dizem "código de espaguete" no exterior. Tudo está conectado com tudo: mudamos algo no ponto A - ele quebra no ponto B, é completamente impossível entender o que está conectado com o quê. Naturalmente, os programadores rapidamente perceberam que isso não funcionaria, e alguma estrutura precisava ser feita e decidiram que algumas camadas nos ajudariam. Agora, se você imagina que carne picada é código e lasanha é uma camada dessas, aqui está uma ilustração da arquitetura em camadas. A carne picada permaneceu picada, mas agora a carne picada da camada 1 não pode mais falar com a carne picada da camada 2. Demos o código de alguma forma: mesmo na figura, você pode ver que a escalada é mais emoldurada.
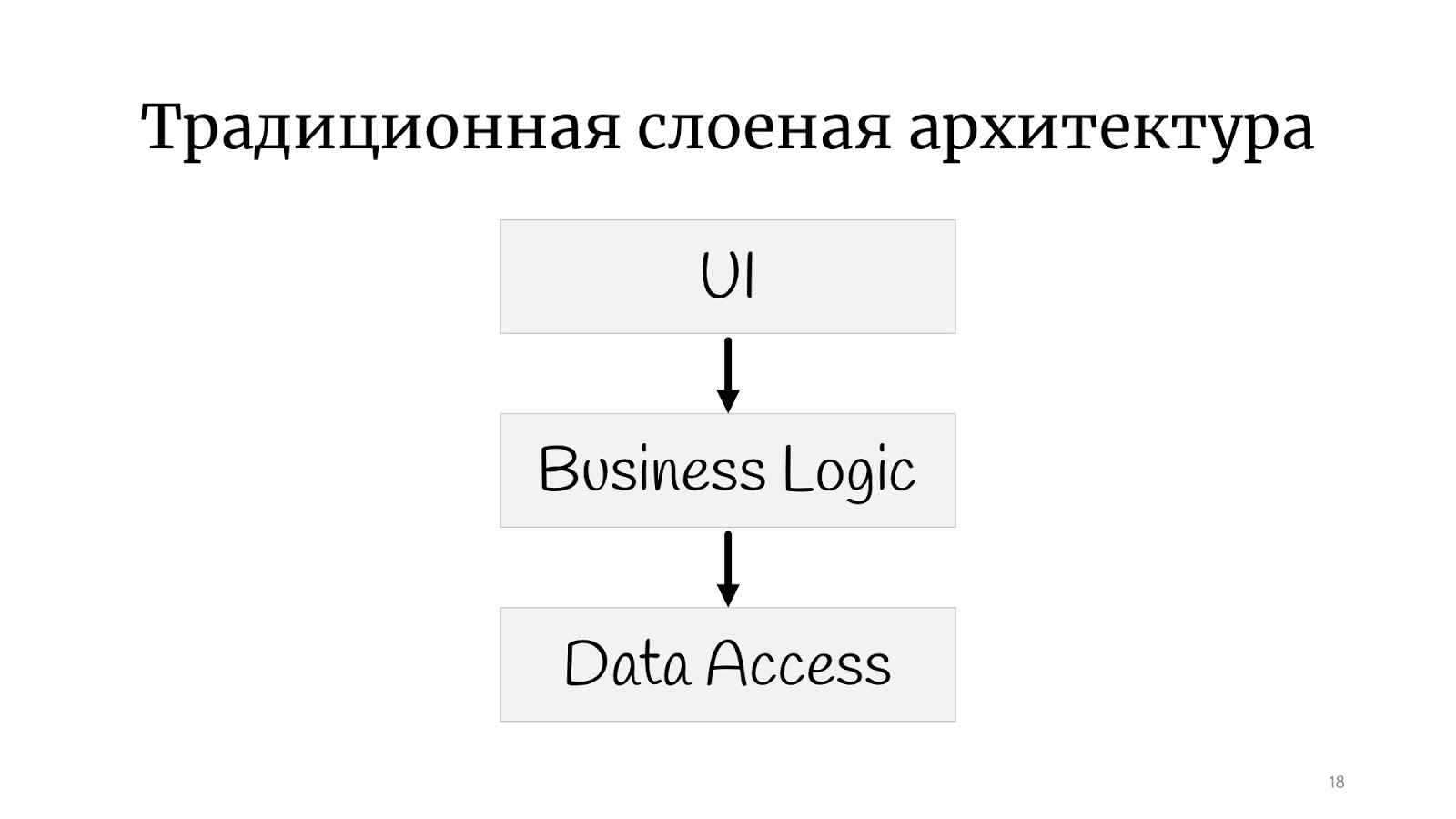
Todos provavelmente estão familiarizados com a
arquitetura clássica em camadas : há uma interface do usuário, há uma lógica de negócios e há uma camada de acesso a dados. Ainda existem todos os tipos de serviços, fachadas e camadas, nomeados para o arquiteto que saiu da empresa, e pode haver um número ilimitado deles.

O próximo estágio foi a chamada
arquitetura da cebola . Parece que há uma enorme diferença: antes disso havia um pequeno quadrado, e aqui havia círculos. Parece ser completamente diferente.
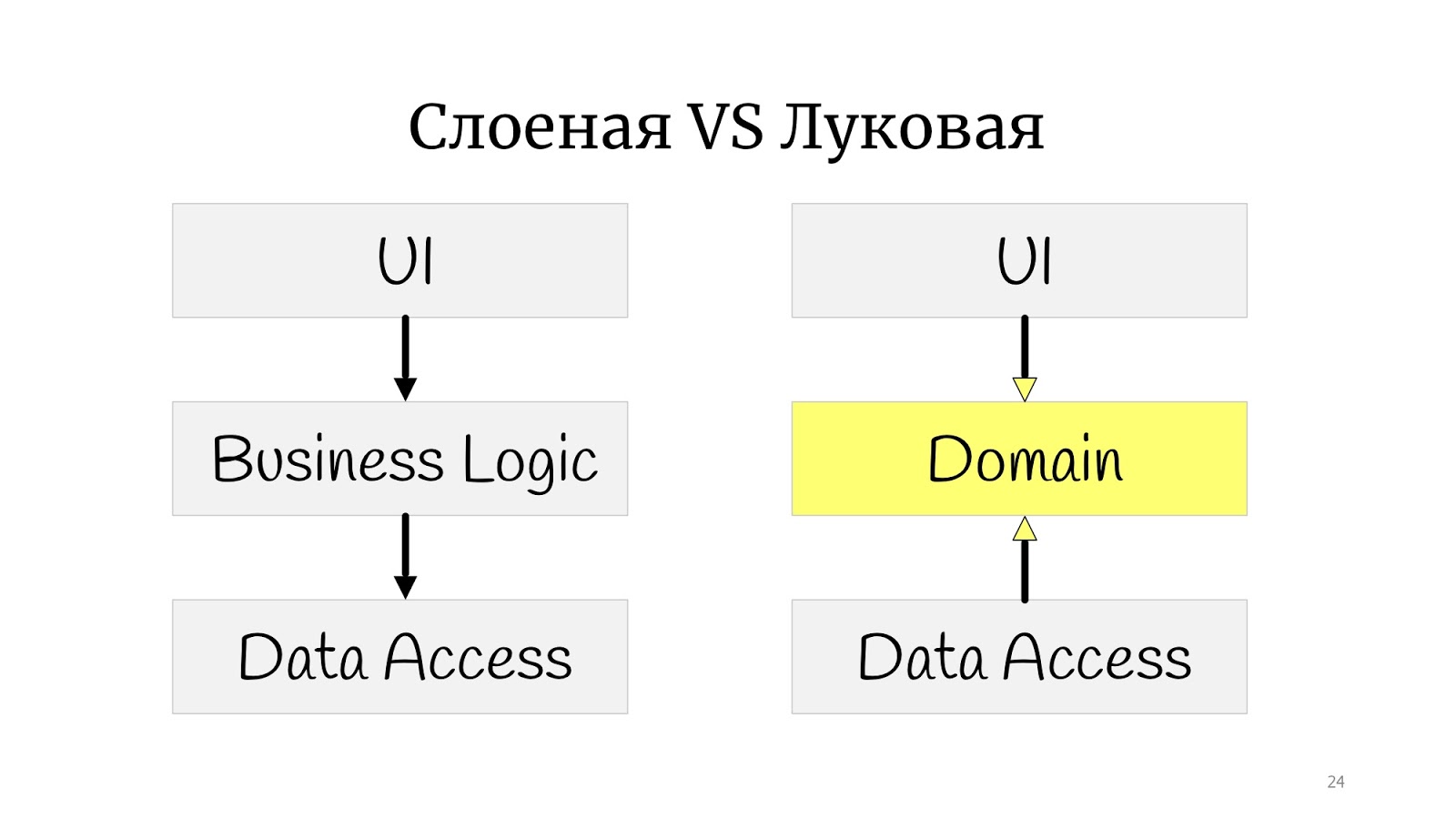
Na verdade não. Toda a diferença é que, em algum momento da época, os princípios do SOLID foram formulados e, na cebola clássica, existe um problema com a inversão de dependência, porque o código de domínio abstrato, por algum motivo, depende da implementação, no Data Access, por isso decidimos implantar o Data Access. e o acesso a dados depende do domínio.

Aqui eu pratiquei desenho e desenhei a arquitetura da cebola, mas não classicamente com os “anéis”. Eu tenho algo entre um polígono e círculos. Fiz isso para mostrar simplesmente que, se você se deparar com as palavras “cebola”, “hexagonal” ou “portas e adaptadores” - essas são todas iguais. O ponto é que o domínio está no centro, está envolto em serviços, eles podem ser serviços de domínio ou aplicativo, como você quiser. E o mundo exterior na forma de interface do usuário, testes e infraestrutura para onde o DAL se mudou - eles se comunicam com o domínio por meio dessa camada de serviço.
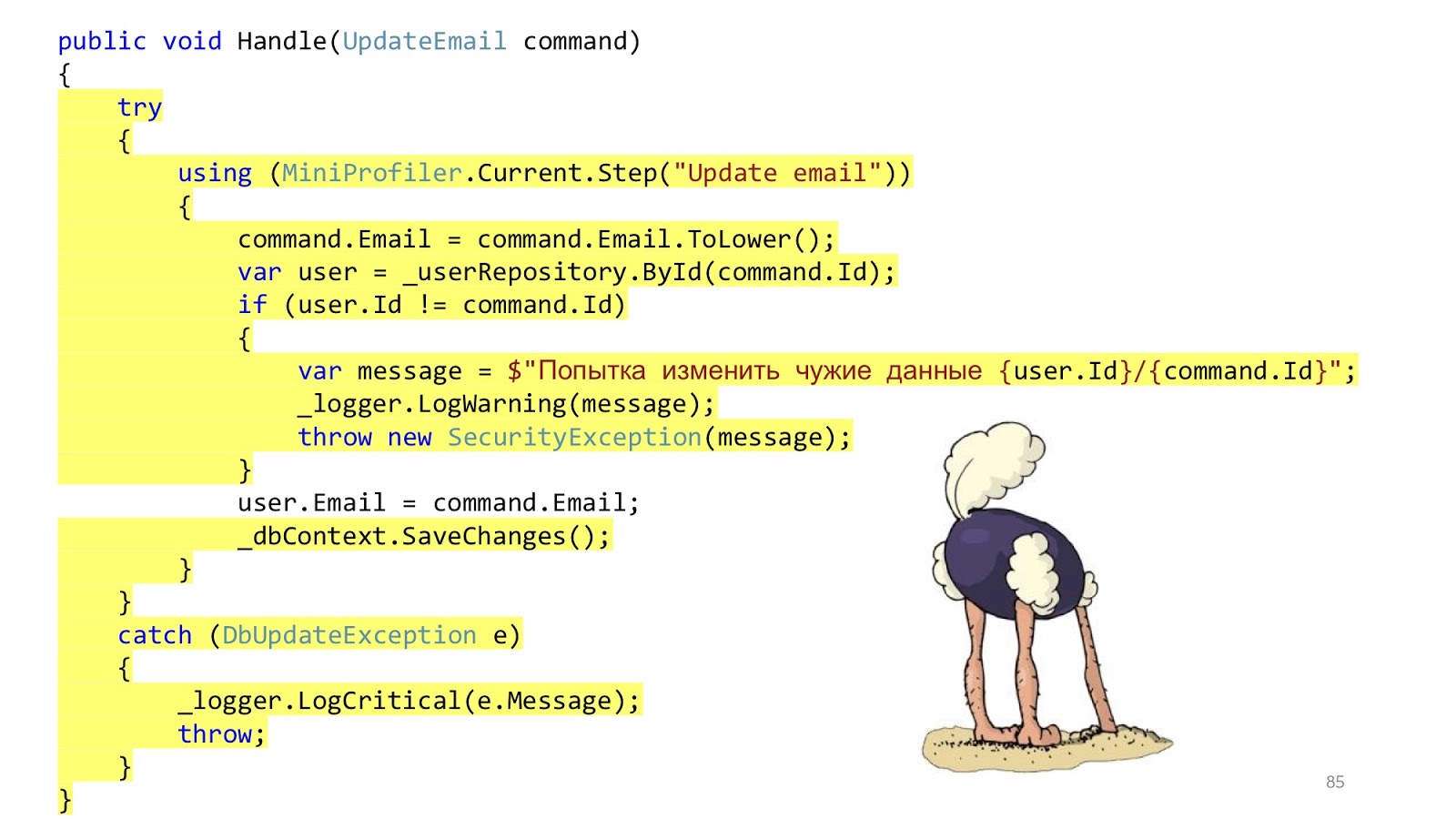
Um exemplo simples. Atualização por email
Vamos ver como seria um caso de uso simples nesse paradigma - atualizando o endereço de email do usuário.
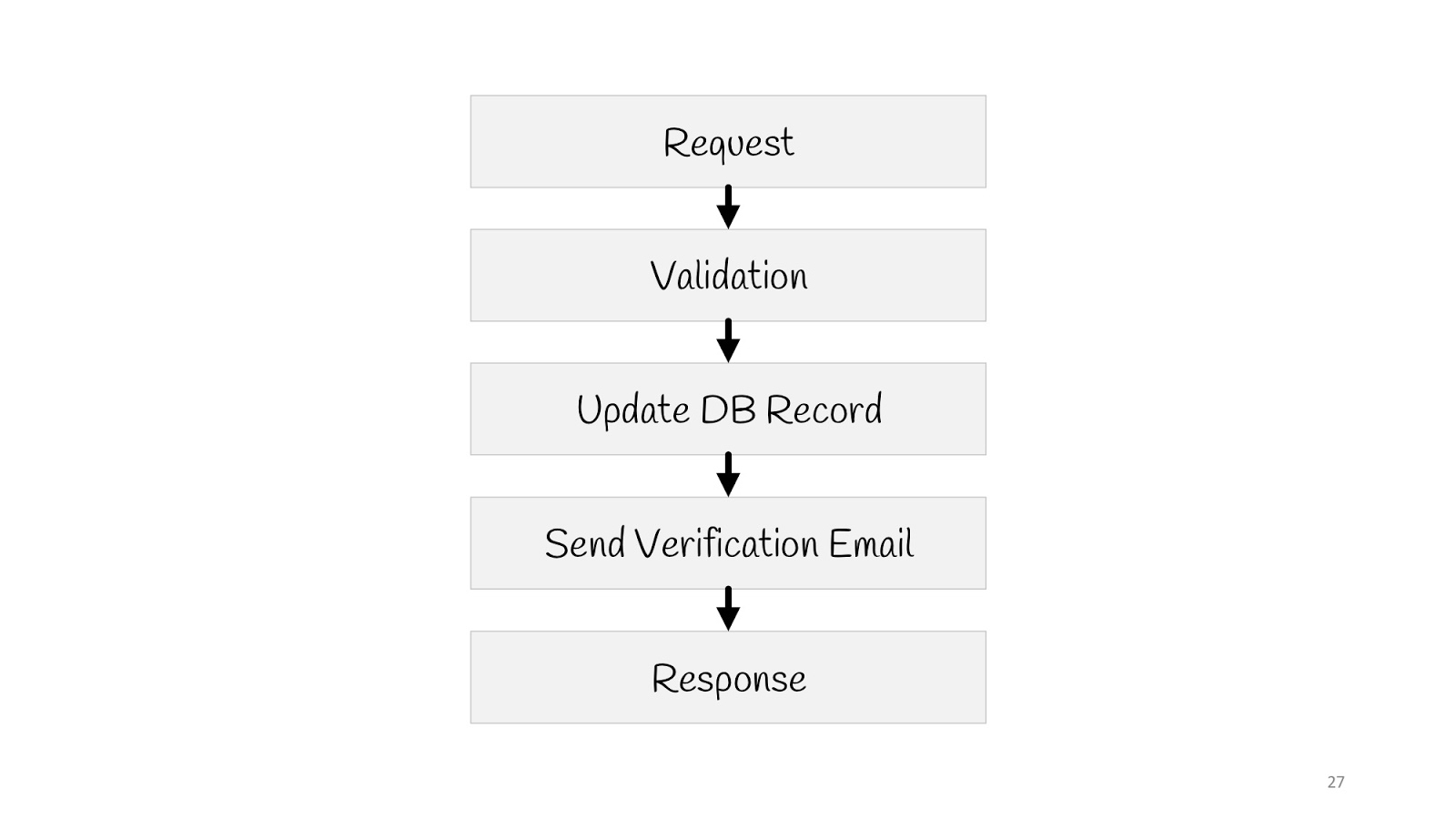
Precisamos enviar uma solicitação, validar, atualizar o valor no banco de dados, enviar uma notificação para um novo email: “Está tudo em ordem, você mudou seu email, sabemos que está tudo bem” e responde ao navegador “200” - está tudo bem.
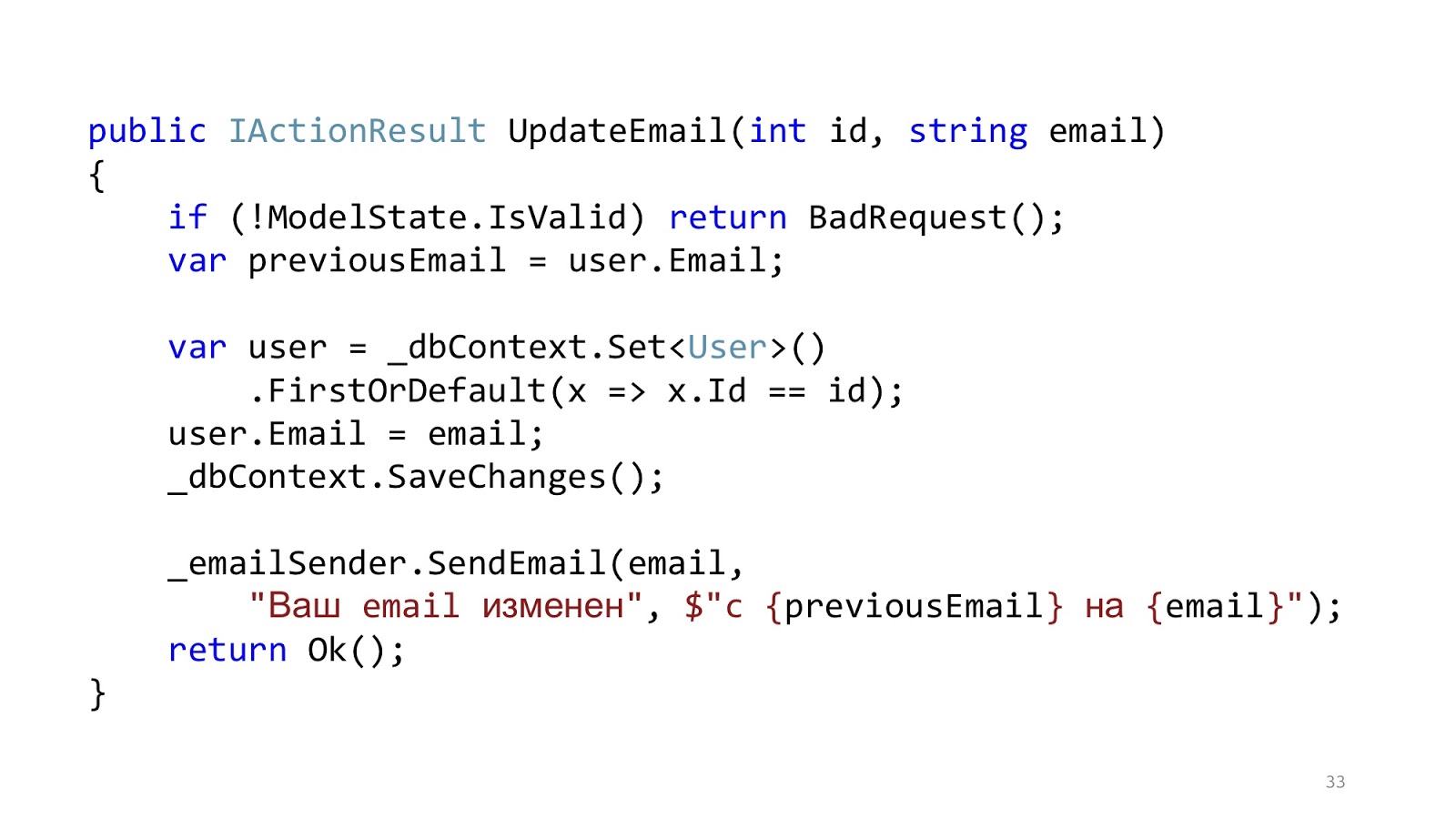
O código pode se parecer com isso. Aqui temos a validação padrão do
ASP.NET MVC, existe o ORM para ler e atualizar os dados e há algum tipo de remetente de email que envia uma notificação. Parece que está tudo bem, certo? Uma ressalva - em um mundo ideal.
No mundo real, a situação é um pouco diferente. O objetivo é adicionar autorização, verificação de erros, formatação, registro e criação de perfil. Isso tudo não tem nada a ver com o nosso caso de uso, mas deve ser. E esse pequeno pedaço de código se tornou grande e assustador: com muito aninhamento, muito código, com o fato de que é difícil de ler e, o mais importante, que há mais código de infraestrutura do que o código de domínio.

"Onde estão os serviços?" você diz. Eu escrevi toda a lógica para os controladores. Claro, isso é um problema, agora vou adicionar serviços e tudo ficará bem.

Adicionamos serviços, e realmente fica melhor, porque em vez de um grande calçado, temos uma pequena linha bonita.
Melhorou? Tornou-se! E agora podemos reutilizar esse método em diferentes controladores. O resultado é óbvio. Vamos olhar para a implementação deste método.
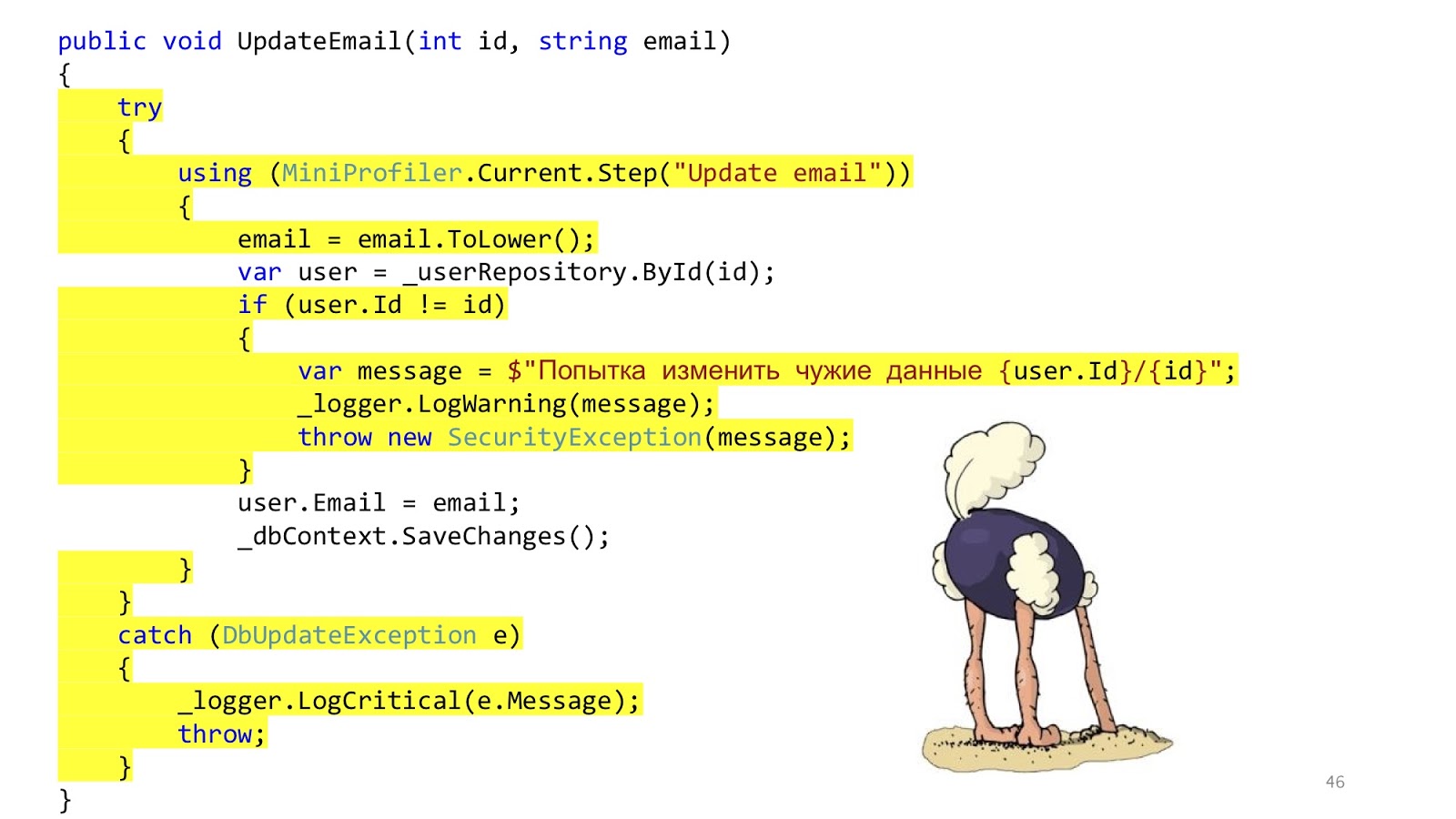
Mas aqui nem tudo é tão bom. Este código ainda está aqui. Acabamos de transferir a mesma coisa para os serviços. Decidimos não resolver o problema, mas simplesmente disfarçá-lo e transferi-lo para outro local. Isso é tudo.

Além disso, surgem outras questões. Devemos fazer a validação no controlador ou aqui? Bem, mais ou menos no controlador. E se você precisar acessar o banco de dados e verificar se existe um ID ou que não há outro usuário com esse email? Hmm, bem, então no serviço. Mas tratamento de erros aqui? Essa manipulação de erros provavelmente está aqui e a manipulação de erros que responderá ao navegador no controlador. E o método SaveChanges, está no serviço ou você precisa transferi-lo para o controlador? Pode ser assim, porque, se um serviço for chamado, é mais lógico chamar o serviço e, se você tiver três métodos de serviços no controlador que precisam ser chamados, precisará chamá-lo fora desses serviços para que a transação seja uma. Essas reflexões sugerem que talvez as camadas não resolvam nenhum problema.

E essa ideia ocorreu a mais de uma pessoa. Se você pesquisar no Google, pelo menos três desses maridos respeitáveis escrevem sobre a mesma coisa. De cima para baixo: Stephen .NET Junkie (infelizmente, não sei o sobrenome dele, porque ela não aparece em nenhum lugar da Internet), a autora do contêiner
Simple Injector IoC. Em seguida, Jimmy Bogard é o autor do
AutoMapper . E abaixo, está Scott Vlashin, autor de
F # por diversão e lucro .
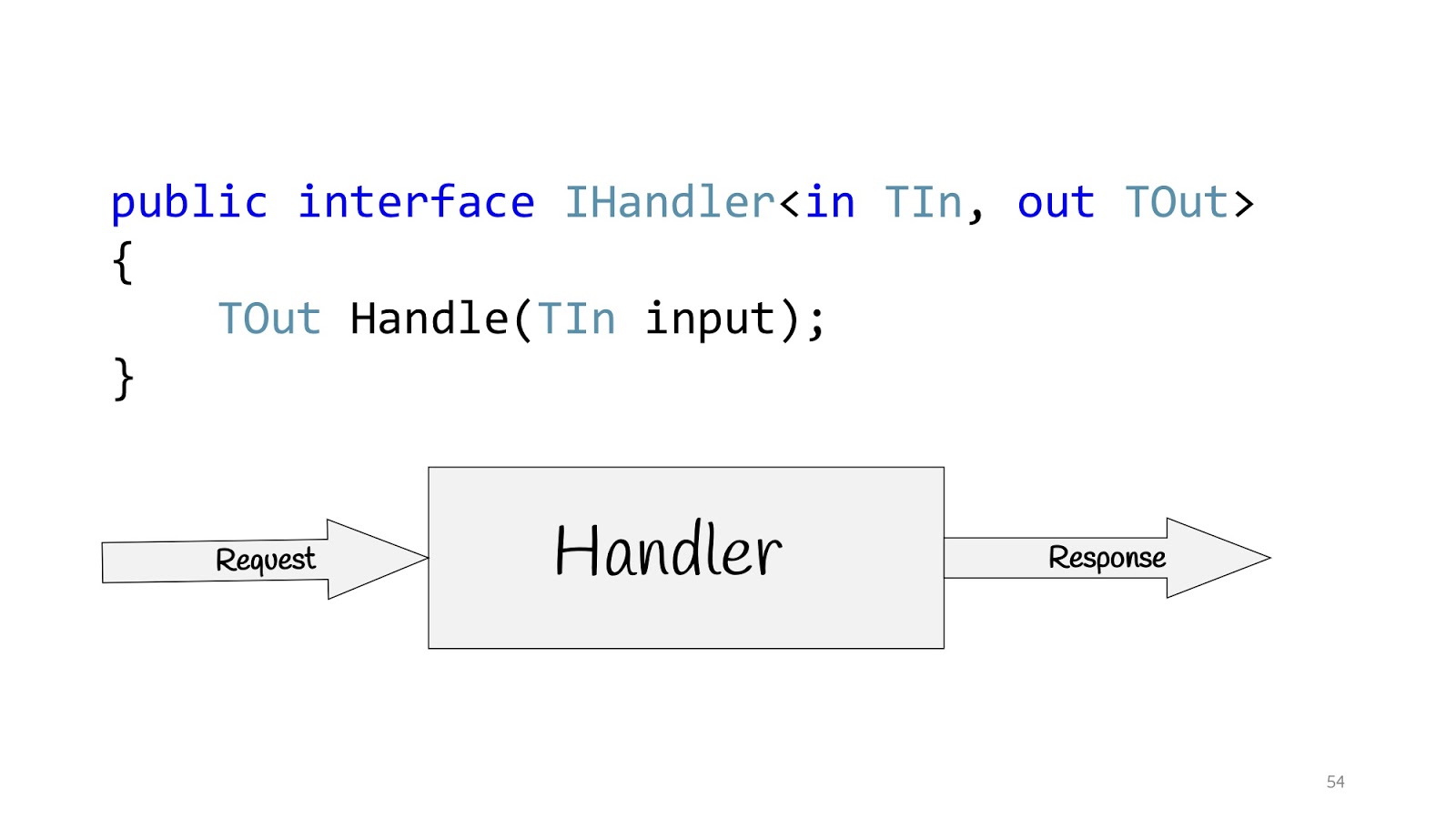
Todas essas pessoas estão falando da mesma coisa e sugerem a criação de aplicativos não com base em camadas, mas com base em casos de uso, ou seja, nos requisitos que a empresa está solicitando. Por conseguinte, o caso de uso em C # pode ser determinado usando a interface IHandler. Ele possui valores de entrada, existem valores de saída e existe um método em si que realmente executa esse caso de uso.

E dentro desse método, pode haver um modelo de domínio ou algum modelo desnormalizado para leitura, talvez com o Dapper ou com o Elastic Search, se você precisar procurar algo e talvez tenha o Legacy sistema com procedimentos armazenados - não há problema, assim como solicitações de rede - bem, em geral, qualquer coisa que você possa precisar lá. Mas se não houver camadas, o que fazer?

Para começar, vamos nos livrar do UserService. Nós removemos o método e criamos uma classe. E vamos removê-lo e removê-lo novamente. E então tire e remova a classe.

Vamos pensar, essas classes são equivalentes ou não? A classe GetUser retorna dados e não altera nada no servidor. Isso, por exemplo, sobre a solicitação "Dê-me o ID do usuário". As classes UpdateEmail e BanUser retornam o resultado da operação e alteram o estado. Por exemplo, quando dizemos ao servidor: "Por favor, altere o estado, você precisa alterar alguma coisa."
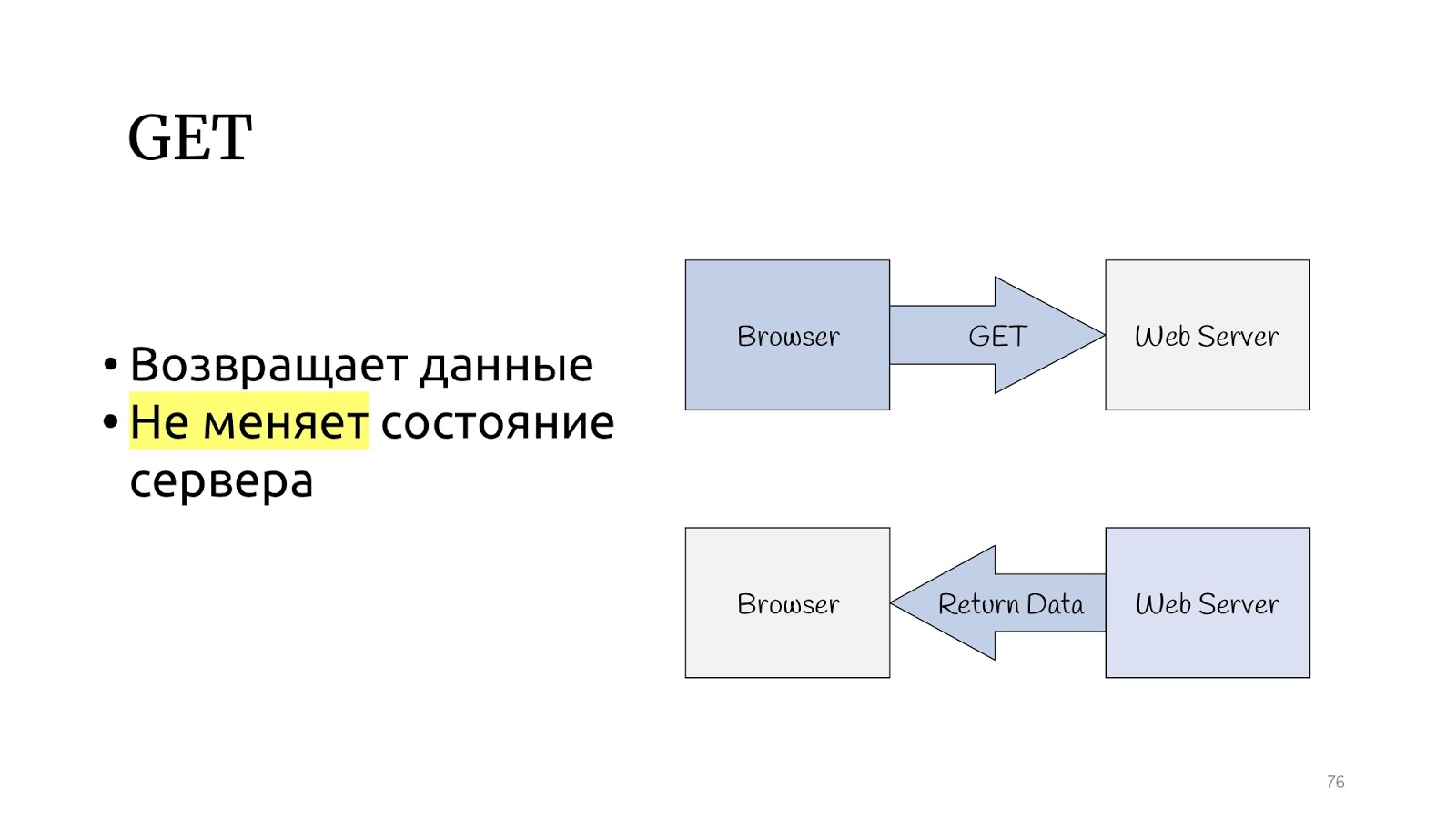
Vamos dar uma olhada no protocolo HTTP. Existe um método GET que, de acordo com a especificação do protocolo HTTP, deve retornar dados e não alterar o estado do servidor.

E existem outros métodos que podem alterar o status do servidor e retornar o resultado da operação.

O paradigma CQRS parece ter sido projetado especificamente para o protocolo HTTP. Consulta são operações GET e comandos são PUT, POST, DELETE - não é necessário inventar nada.
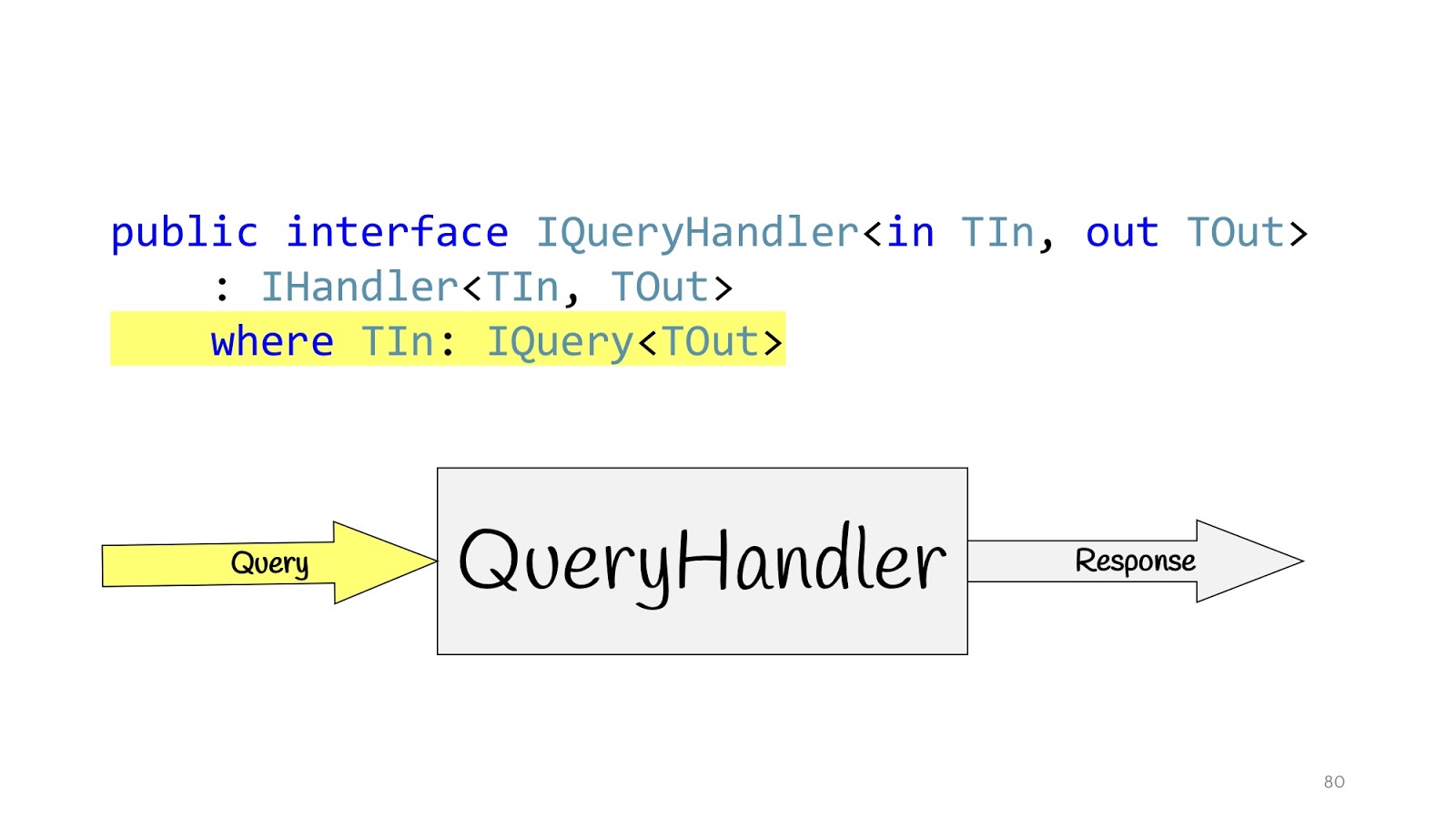
Redefinimos nosso manipulador e definimos interfaces adicionais. IQueryHandler, que difere apenas na pendência da restrição de que o tipo de valores de entrada seja IQuery. O IQuery é uma interface de marcador, não há nada além deste genérico. Precisamos do genérico para colocar restrições no QueryHandler e, agora, declarando QueryHandler, não podemos passar para lá não, mas passando o objeto Query para lá, sabemos seu valor de retorno. Isso é conveniente se você tiver apenas uma interface, para que não precise procurar a implementação deles no código e, novamente, para não atrapalhar. Você escreve IQueryHandler, escreve uma implementação lá e no TOut não pode substituir outro tipo de valor de retorno. Simplesmente não compila. Assim, você pode ver imediatamente quais valores de entrada correspondem a quais dados de entrada.

A situação é completamente semelhante para o CommandHandler com uma exceção: esse genérico é necessário para mais um truque, que veremos um pouco mais adiante.
Implementação do manipulador
Manipuladores, anunciamos, qual é a implementação deles?
Existe algum problema, sim? Algo parece ter falhado.
Decoradores correm para o resgate
Mas não ajudou, porque ainda estamos no meio do caminho, precisamos finalizar um pouco mais e, desta vez, precisamos usar o padrão
decorador , ou seja, seu maravilhoso recurso de layout. O decorador pode ser embrulhado em um decorador, embrulhado em um decorador, embrulhado em um decorador - continue até ficar entediado.
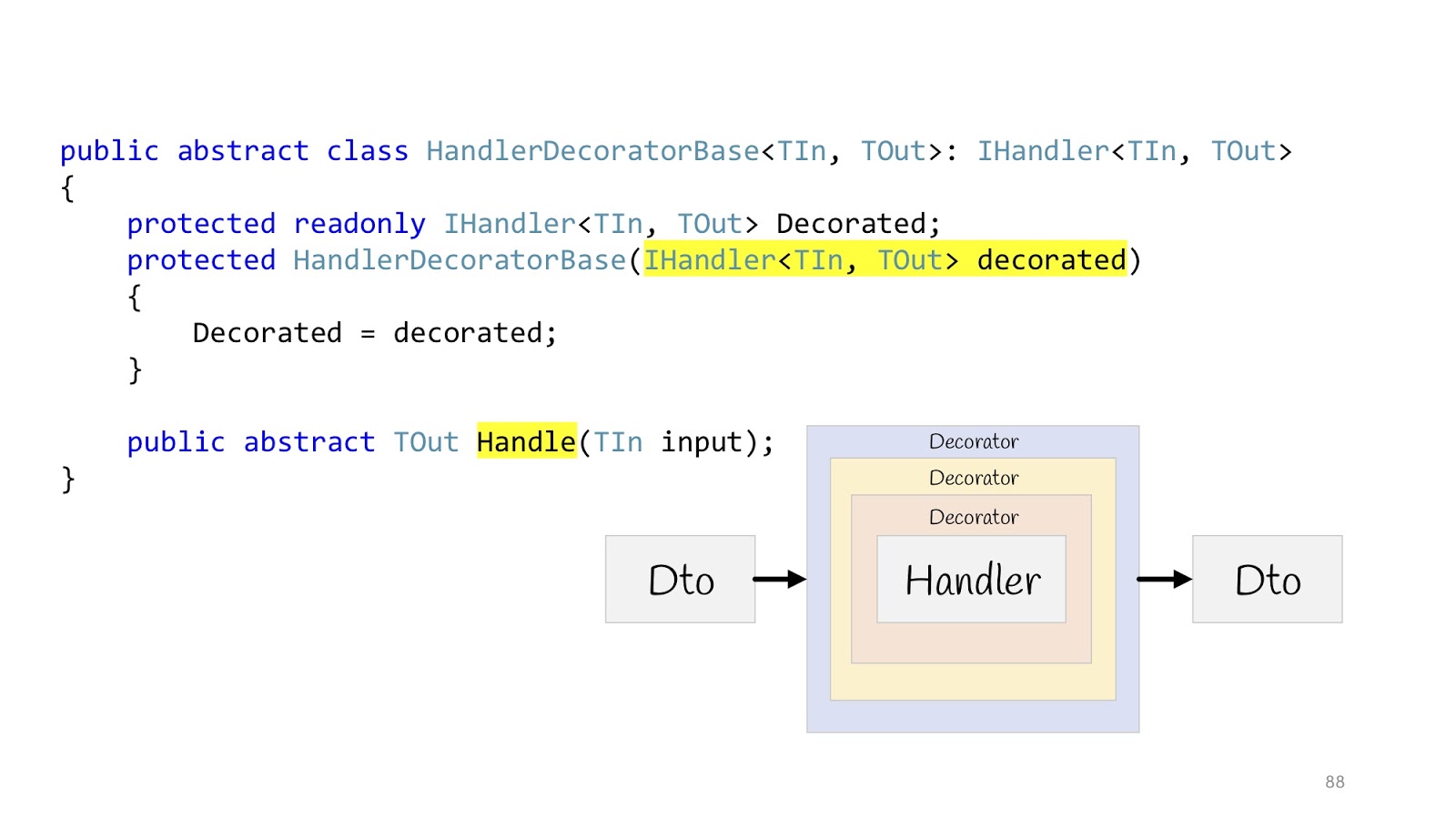
Então, tudo ficará assim: existe uma entrada Dto, ela entra no primeiro decorador, no segundo, terceiro, depois entramos no Handler e também saímos, passamos por todos os decoradores e retornamos o Dto no navegador. Declaramos uma classe base abstrata para herdar posteriormente, o corpo de Handler é passado para o construtor e declaramos o método Handle abstrato, no qual a lógica decoradora adicional será suspensa.
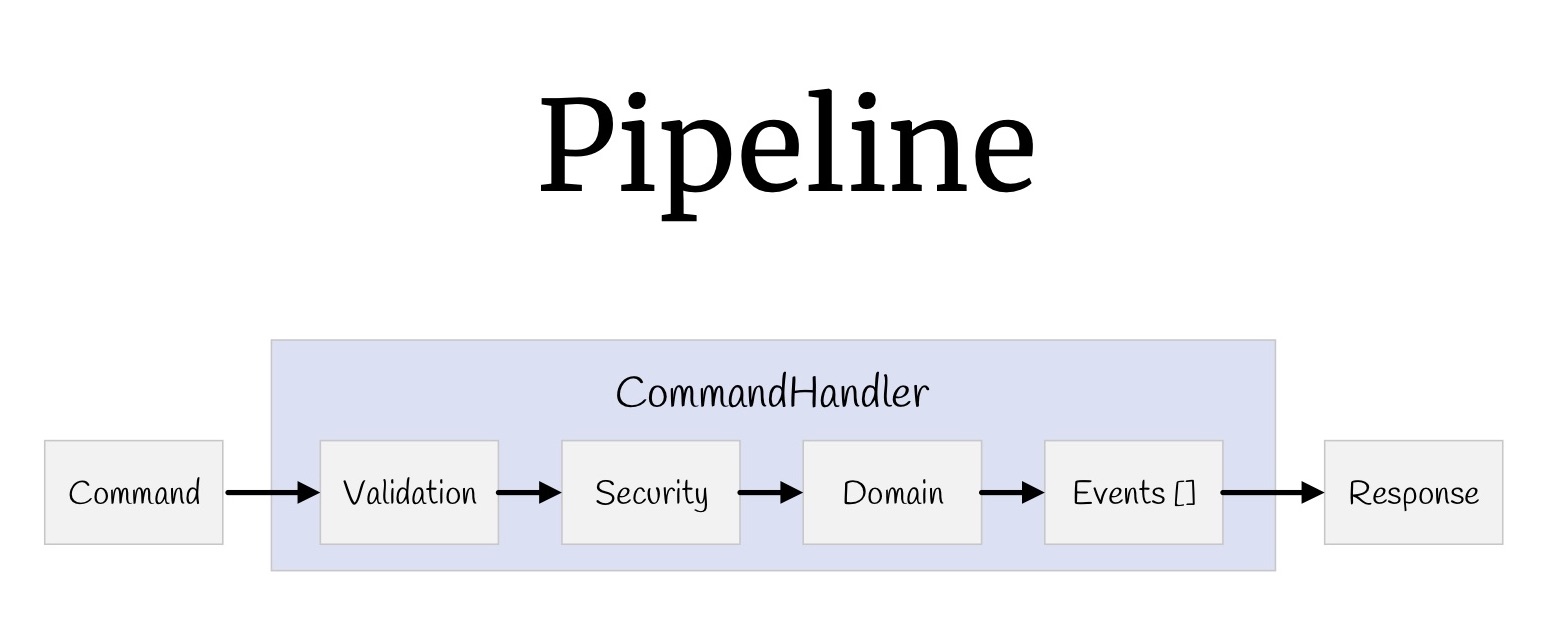
Agora, com a ajuda de decoradores, você pode construir um pipeline inteiro. Vamos começar com as equipes. O que nós tínhamos? Insira valores, validação, verificação de direitos de acesso, a própria lógica, alguns eventos que ocorrem como resultado dessa lógica e retorne valores.

Vamos começar com a validação. Declaramos um decorador. O IEnumerable dos validadores do tipo T. entra no construtor deste decorador.Executamos todos eles, verificamos se a validação falha e o tipo de retorno é
IEnumerable<validationresult> , e podemos devolvê-lo porque os tipos correspondem. E se for algum outro Hander, bem, você precisará lançar uma exceção, porque não há resultado aqui, o tipo de outro valor de retorno.
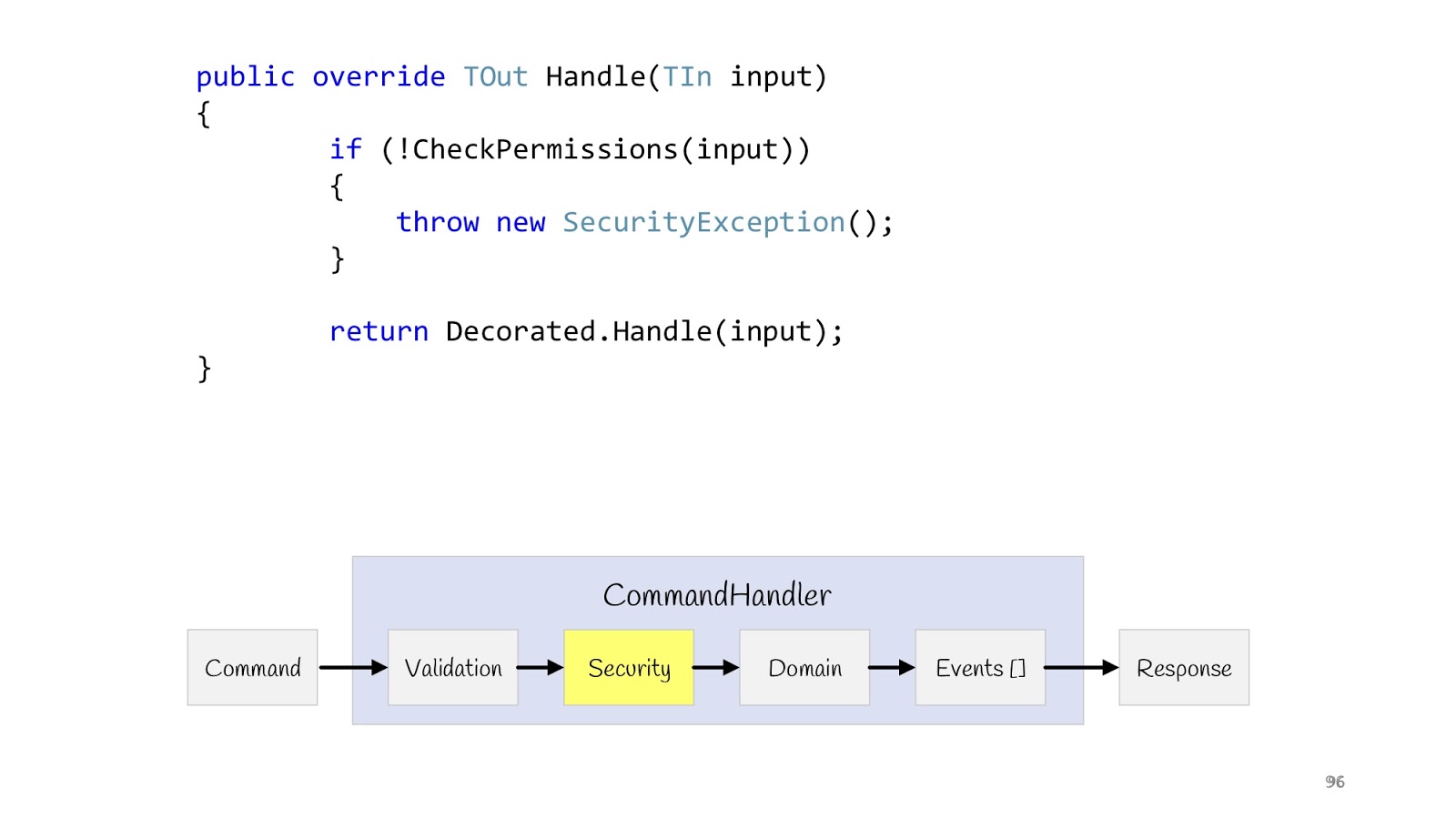
O próximo passo é segurança. Também declaramos o decorador, fazemos o método CheckPermission e verificamos. Se de repente algo deu errado, tudo, não continuamos. Agora, depois de concluir todas as verificações e ter certeza de que está tudo bem, podemos cumprir nossa lógica.
Antes de mostrar a implementação da lógica, quero começar um pouco mais cedo, ou seja, com os valores de entrada que chegam lá.
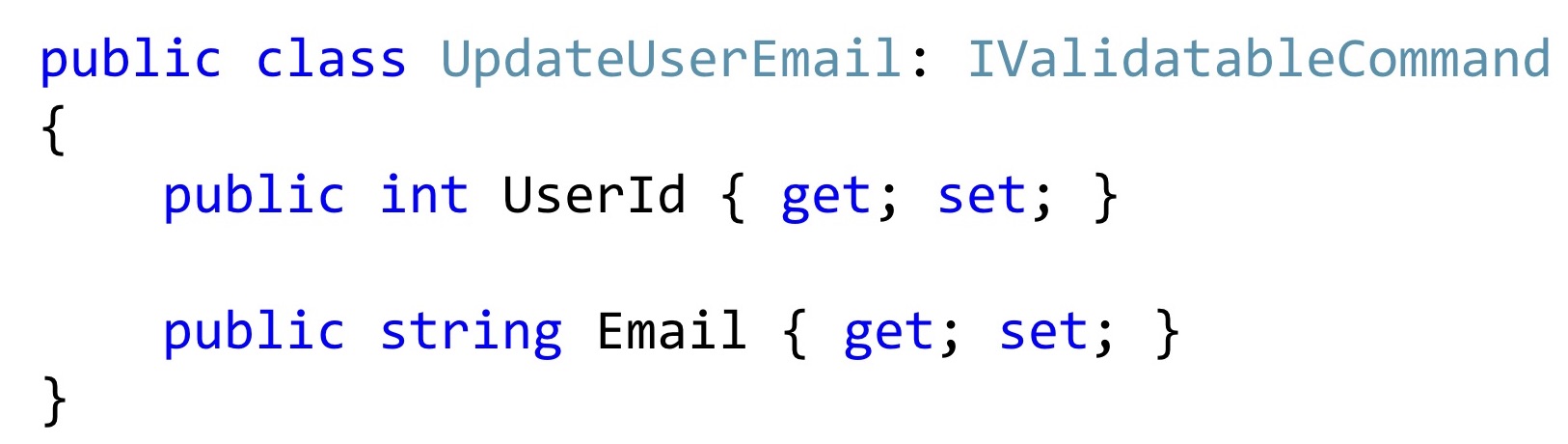
Agora, se destacarmos essa classe, na maioria das vezes ela pode ser algo assim. Pelo menos o código que vejo no trabalho diário.
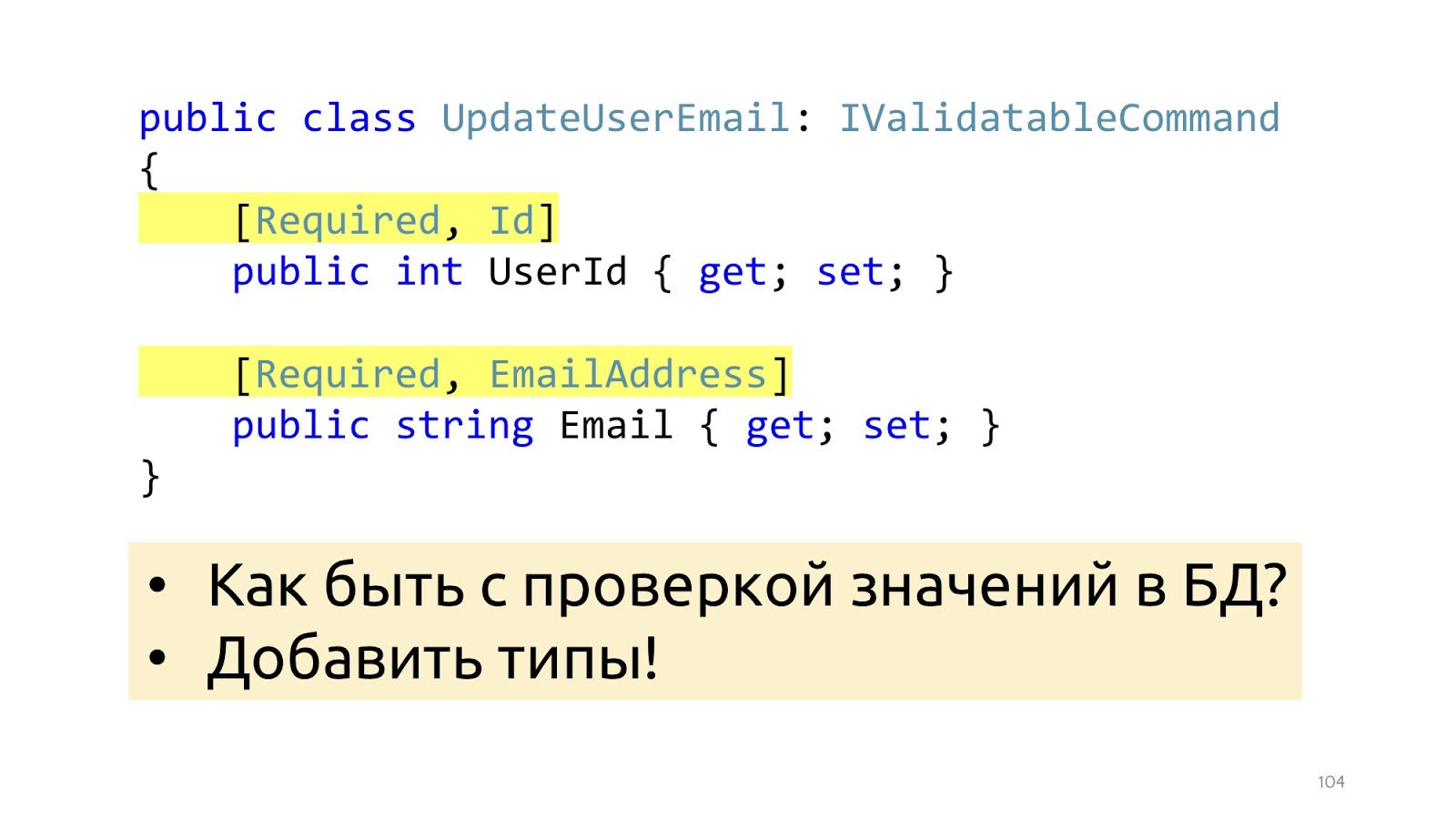
Para que a validação funcione, adicionamos aqui alguns atributos que informam que tipo de validação é essa. Isso ajudará do ponto de vista da estrutura de dados, mas não ajudará com a validação como verificar valores no banco de dados. É apenas EmailAddress, não está claro como, onde verificar como usar esses atributos para acessar o banco de dados. Em vez de atributos, você pode ir para tipos especiais, esse problema será resolvido.

Em vez da primitiva
int , declaramos que um tipo de ID que possui um genérico é uma determinada entidade com uma chave int. E nós passamos essa entidade para o construtor ou passamos seu ID, mas, ao mesmo tempo, devemos passar uma função que por Id possa receber e retornar, verificando se ela é nula ou não.
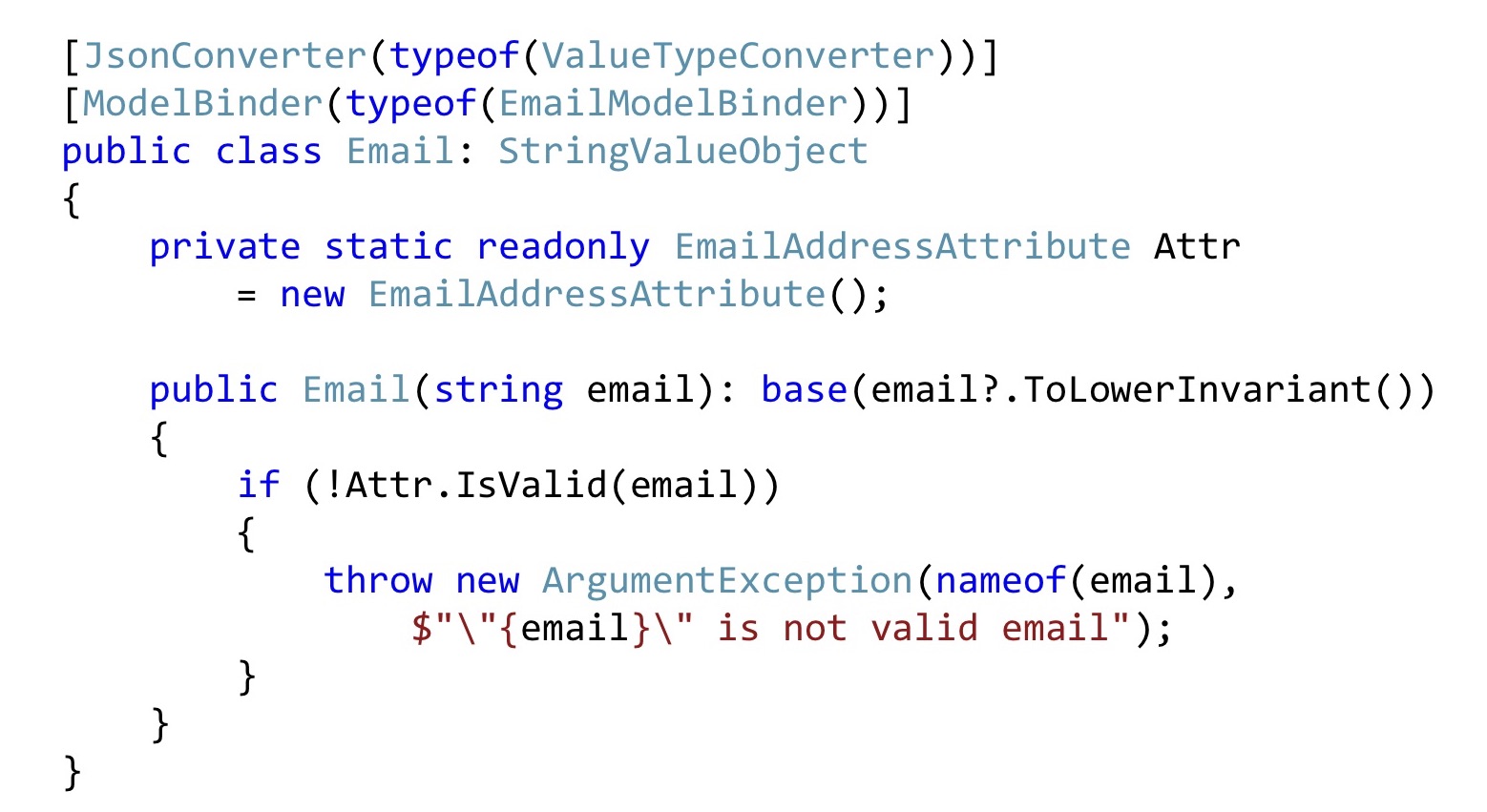
Fazemos o mesmo com o email. Converta todos os e-mails na linha inferior para que tudo pareça o mesmo para nós. Em seguida, pegamos o atributo Email, declaramos como estático para compatibilidade com a validação do ASP.NET, e aqui simplesmente o chamamos. Ou seja, isso também pode ser feito. Para que a infraestrutura do ASP.NET capte tudo isso, você precisa modificar levemente a serialização e / ou ModelBinding. Não há muito código lá, é relativamente simples, então não vou parar por aí.
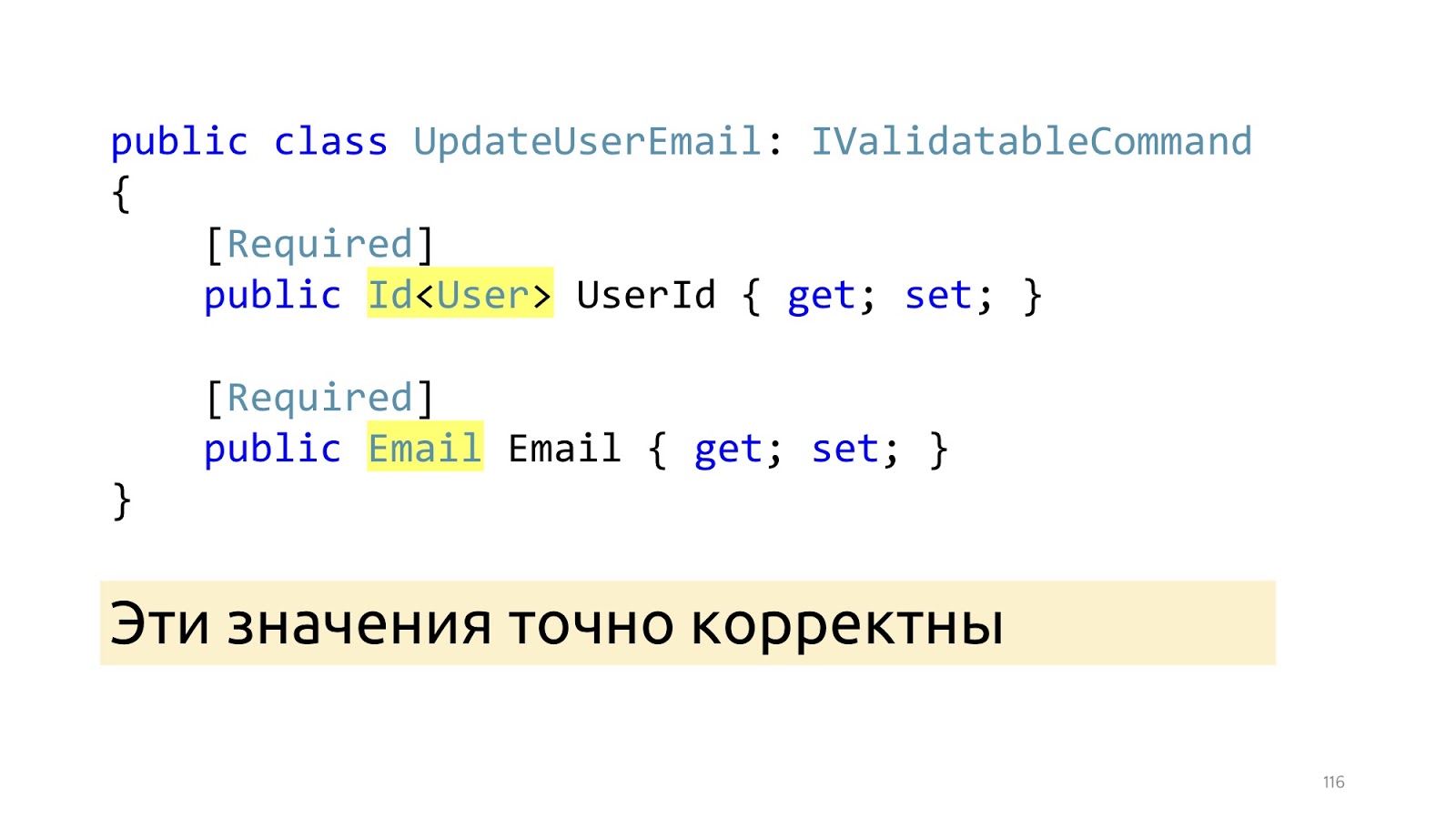
Após essas alterações, em vez de tipos primitivos, os tipos especializados aparecem aqui: ID e email. E depois que o ModelBinder e o desserializador atualizado forem executados, sabemos com certeza que esses valores estão corretos, incluindo que esses valores estão no banco de dados. "Invariantes"

O próximo ponto em que gostaria de me debruçar é sobre o estado dos invariantes na classe, porque muitas vezes é usado um
modelo anêmico , no qual há apenas uma classe, muitos getter-setters, não está totalmente claro como eles devem trabalhar juntos. Como trabalhamos com lógica de negócios complexa, é importante para nós que o código seja auto-documentado. Em vez disso, é melhor declarar o construtor real junto com vazio para o ORM, ele pode ser declarado protegido para que os programadores em seu código de aplicativo não possam chamá-lo e o ORM poderia. Aqui não passamos o tipo primitivo, mas o tipo E-mail, ele já está correto, se for nulo, ainda lançamos uma exceção. Você pode usar algum Fody, PostSharp, mas o C # 8. estará disponível em breve.Em conseqüência, haverá um tipo de referência Não anulável e é melhor aguardar pelo suporte no idioma. No momento seguinte, se quisermos alterar o nome e o sobrenome, é provável que desejemos alterá-los juntos; portanto, deve haver um método público apropriado que os altere.

Nesse método público, também verificamos que o comprimento dessas linhas corresponde ao que usamos no banco de dados. E se algo estiver errado, pare a execução. Aqui eu uso o mesmo truque. Declaro um atributo especial e apenas o chamo no código do aplicativo.
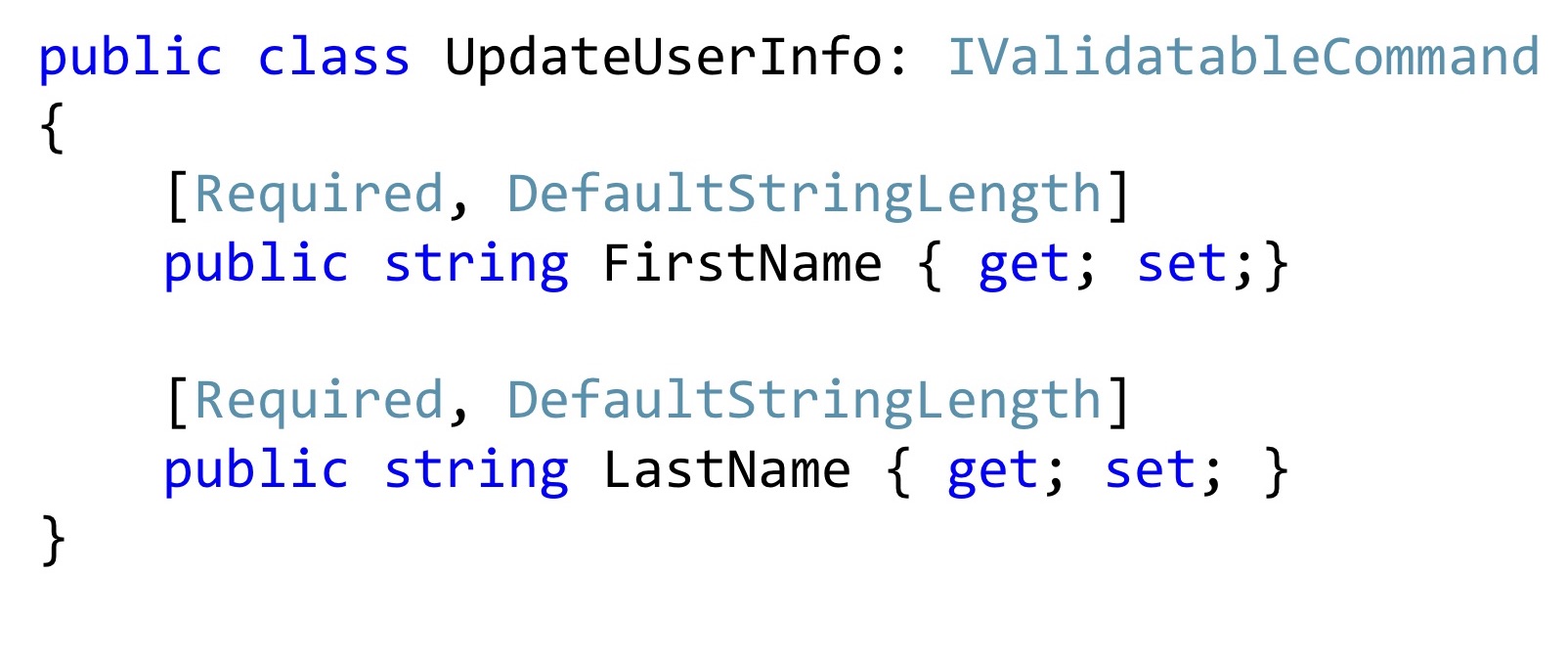
Além disso, esses atributos podem ser reutilizados no Dto. Agora, se eu quiser alterar o nome e o sobrenome, posso ter um comando de alteração. Vale a pena adicionar um construtor especial aqui? Parece valer a pena. Ficará melhor, ninguém mudará esses valores, não os quebrará, eles estarão exatamente certos.

Na verdade não. O fato é que Dto não são realmente objetos. Esse é um dicionário no qual colocamos dados desserializados. Ou seja, eles fingem ser objetos, é claro, mas eles têm apenas uma responsabilidade - é ser serializado e desserializado. Se tentarmos combater essa estrutura, começaremos a anunciar alguns ModelBinders com os designers, fazer algo assim é incrivelmente cansativo e, o mais importante, será romper com os novos lançamentos de novas estruturas. Tudo isso foi bem descrito por Mark Simon no artigo
"Nas fronteiras do programa não são orientadas a objetos" , se é interessante, é melhor ler o post dele, onde é descrito em detalhes.

Em resumo, temos um mundo externo sujo, colocamos verificações na entrada, convertemos para nosso modelo limpo e depois transferimos tudo de volta para serialização, para o navegador, novamente para o mundo externo sujo.
Handler
Depois de todas essas alterações, como será o Hander aqui?

Escrevi duas linhas aqui para facilitar a leitura, mas em geral pode ser escrita em uma. Os dados estão exatamente corretos, porque temos um sistema de tipos, existe validação, ou seja, os dados são de concreto armado, não é necessário verificá-los novamente. Esse usuário também existe, não há outro usuário com um e-mail tão ocupado, tudo pode ser feito. No entanto, ainda não há chamada para o método SaveChanges, não há notificação e não há logs e criadores de perfil, certo? Nós seguimos em frente.
Eventos
Eventos de domínio.

Provavelmente, a primeira vez que este conceito foi popularizado por Udi Dahan em seu post
"Domain Events - Salvation" . Lá, ele sugere simplesmente declarar uma classe estática com o método Raise e lançar esses eventos. Um pouco mais tarde, Jimmy Bogard propôs uma melhor implementação, chamada
"Um melhor padrão de eventos de domínio" .
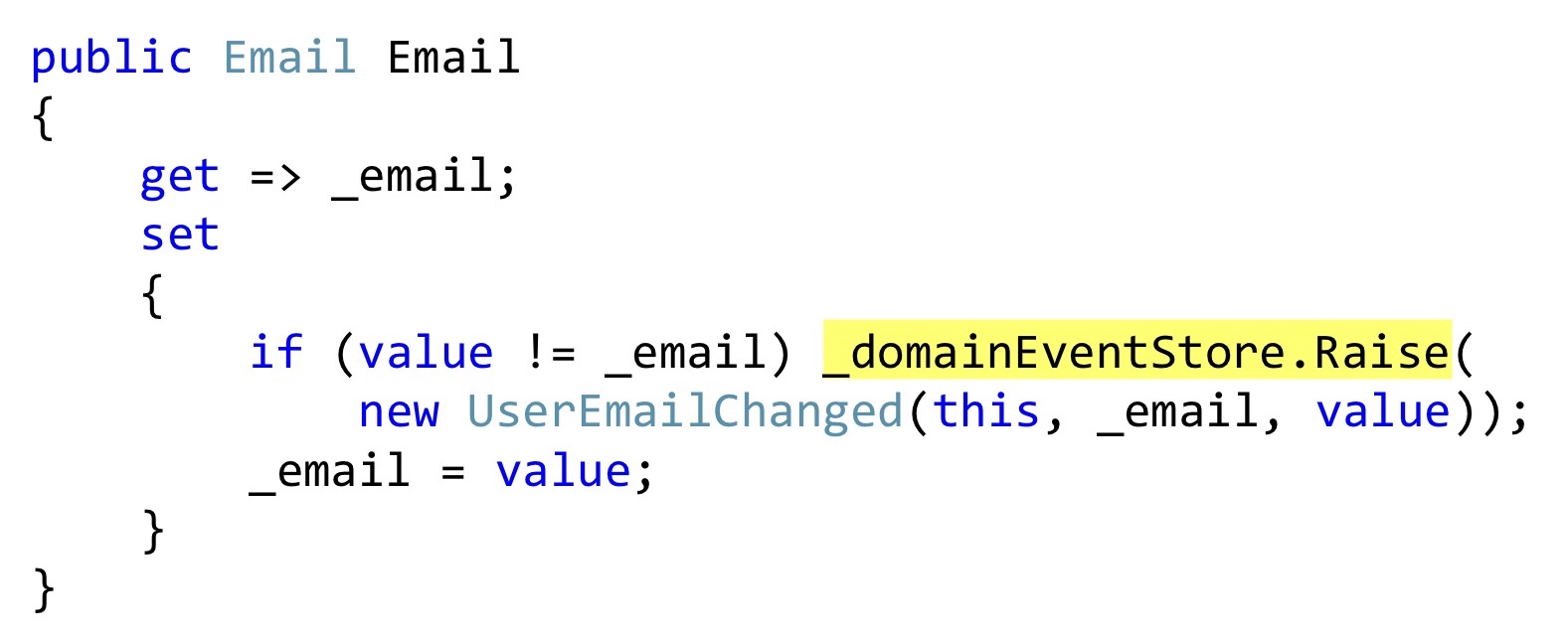
Mostrarei a serialização de Bogard com uma pequena alteração, mas importante. Em vez de lançar eventos, podemos declarar alguma lista e, nos locais em que algum tipo de reação deve ocorrer, diretamente dentro da entidade para salvar esses eventos. Nesse caso, esse getter de
email também é uma classe User e essa classe, essa propriedade não finge ser uma propriedade com getters e setters automáticos, mas realmente adiciona algo a isso. Ou seja, isso é encapsulamento real, não profanação. Ao alterar, verificamos que o email é diferente e lançamos um evento. Este evento ainda não chegou a lugar algum, apenas o temos na lista interna de entidades.

Além disso, no momento em que chamaremos o método SaveChanges, pegamos o ChangeTracker, verificamos se existem entidades que implementam a interface, se elas têm eventos de domínio. E, se houver, vamos pegar todos esses eventos de domínio e enviá-los a algum despachante que sabe o que fazer com eles.
A implementação desse expedidor é um tópico para outra discussão, existem algumas dificuldades com o envio múltiplo em C #, mas isso também é feito. Com essa abordagem, há outra vantagem não óbvia. Agora, se tivermos dois desenvolvedores, um pode escrever um código que altera esse email e o outro pode criar um módulo de notificação. Eles não estão absolutamente conectados entre si, escrevem códigos diferentes, estão conectados apenas no nível desse evento de domínio de uma classe Dto. O primeiro desenvolvedor simplesmente joga fora essa classe em algum momento, o segundo responde e sabe que precisa ser enviado por email, SMS, notificações por push para o telefone e todos os outros milhões de notificações, levando em consideração as preferências do usuário que geralmente acontecem.
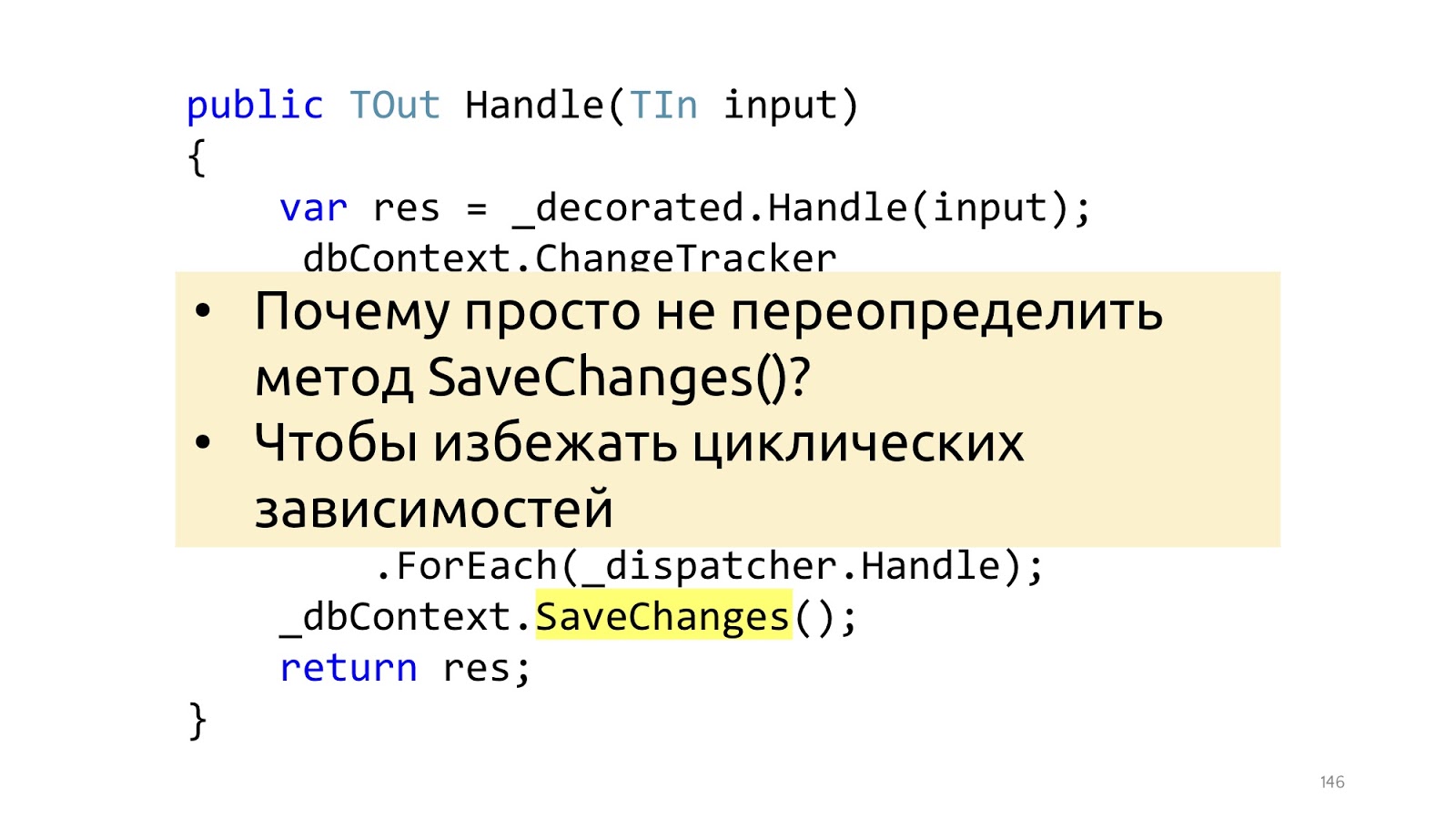
Aqui está o ponto menor, mas importante. O artigo de Jimmy usa uma sobrecarga do método SaveChanges, e é melhor não. E é melhor fazê-lo no decorador, porque se sobrecarregarmos o método SaveChanges e precisarmos do dbContext no Handler, obteremos dependências circulares. Você pode trabalhar com isso, mas as soluções são um pouco menos convenientes e um pouco menos bonitas. Portanto, se o pipeline é construído com decoradores, não vejo razão para fazê-lo de maneira diferente.
Registro e criação de perfil

O aninhamento do código permaneceu, mas no exemplo inicial, primeiro tínhamos usando o MiniProfiler, depois tentamos pegar e depois se. No total, havia três níveis de aninhamento, agora cada um desse nível de aninhamento está em seu próprio decorador. E dentro do decorador, que é responsável pela criação de perfil, temos apenas um nível de aninhamento, o código é lido perfeitamente. Além disso, é claro que nesses decoradores há apenas uma responsabilidade. Se o decorador for responsável pelo registro, ele registrará apenas, se a criação de perfis, respectivamente, apenas o perfil, todo o resto estiver em outros lugares.
Resposta
Depois que todo o pipeline tiver funcionado, só podemos pegar o Dto e enviá-lo ao navegador, serializando JSON.
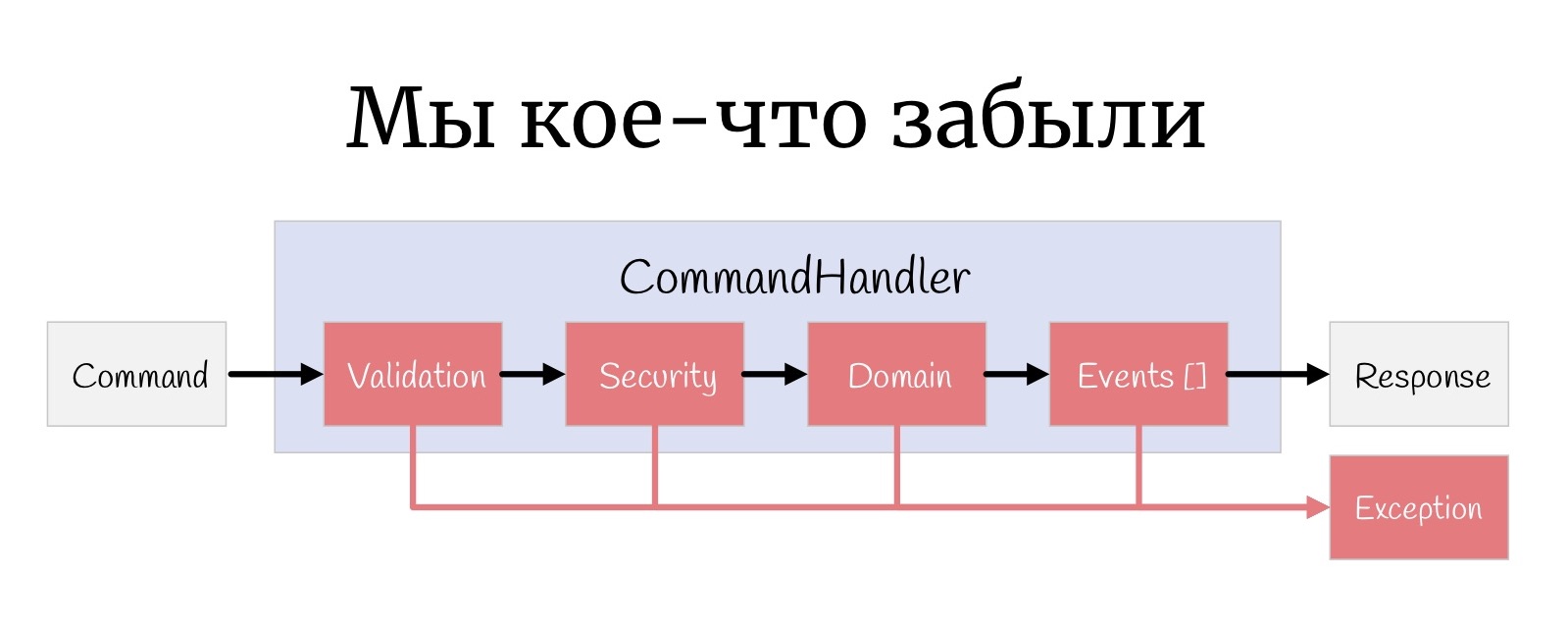
Mas mais uma coisa pequena, algo que às vezes é esquecido: a cada estágio, uma Exceção pode acontecer aqui e, na verdade, você precisa lidar com eles de alguma forma.

Não posso deixar de mencionar Scott Vlashin e seu relatório
"Programação Orientada a Ferrovias" aqui novamente. Porque O relatório original é inteiramente dedicado ao trabalho com erros na linguagem F #, como organizar o fluxo de maneira um pouco diferente e por que essa abordagem pode ser preferível ao uso de Exception'ov. No F #, isso realmente funciona muito bem, porque o F # é uma linguagem funcional e Scott usa a funcionalidade de uma linguagem funcional.

Uma vez que, provavelmente, a maioria de vocês ainda escreve em C #, se você escreve
um analógico em C # , essa abordagem será mais ou menos assim. Em vez de lançar exceções, declaramos uma classe Result que possui uma ramificação bem-sucedida e uma ramificação sem êxito. Assim, dois designers. Uma classe pode estar em apenas um estado. Essa classe é um caso especial de tipo de união, união discriminada de F #, mas reescrita em C #, porque não há suporte interno em C #.

Em vez de declarar public getters que alguém pode não procurar nulo no código, a Correspondência de Padrões é usada. Novamente, em F #, seria uma linguagem interna de correspondência de padrões; em C #, precisamos escrever um método separado no qual passaremos uma função que sabe o que fazer com o resultado bem-sucedido da operação, como convertê-la ainda mais na cadeia e com erro. Ou seja, não importa qual ramo funcionou para nós, devemos converter isso em um único resultado retornado. No F #, tudo isso funciona muito bem, porque existe uma composição funcional e tudo o que eu já listei. No .NET, isso funciona um pouco pior, porque assim que você tem mais de um resultado, mas muito - e quase todo método pode falhar por um motivo ou outro - quase todos os tipos de função resultantes se tornam tipos de resultado, e você precisa deles como para combinar alguma coisa.

A maneira mais fácil de combiná-los é
usar o LINQ , porque, de fato, o LINQ funciona não apenas com o IEnumerable, se você redefinir os métodos SelectMany e Select da maneira correta, o compilador C # verá que você pode usar a sintaxe do LINQ para esses tipos. Em geral, o papel é traçado com doação de Haskell ou com as mesmas expressões de computação em F #. Como isso deve ser lido? Aqui temos três resultados da operação e, se tudo estiver bem nos três casos, pegue esses resultados r1 + r2 + r3 e adicione-os. O tipo do valor resultante também será Resultado, mas o novo Resultado, que declaramos em Selecionar. Em geral, essa é mesmo uma abordagem de trabalho, se não uma, mas.

Para todos os outros desenvolvedores, assim que você começa a escrever esse código em C #, você começa a se parecer com isso. “Essas são exceções assustadoras, não as escreva! Eles são maus! Melhor escrever código que ninguém entende e não pode depurar! ”

C # não é F #, é um pouco diferente, não há conceitos diferentes com base nos quais isso é feito, e quando tentamos puxar uma coruja no globo, verifica-se, para dizer o mínimo, incomum.

Em vez disso, você pode usar as
ferramentas normais integradas documentadas, que todos sabem e que não causarão dissonância cognitiva entre os desenvolvedores. O ASP.NET possui uma exceção de manipulador global.

Sabemos que, se houver algum problema com a validação, você precisará retornar o código 400 ou 422 (entidade não processável). Se houver um problema com autenticação e autorização, existem 401 e 403. Se algo deu errado, algo deu errado. E se algo der errado e você desejar informar exatamente ao usuário, defina seu tipo de exceção, diga que é IHasUserMessage, declare um getter de mensagens nessa interface e verifique: se essa interface estiver implementada, você poderá receber uma mensagem de Exception e passe-o em JSON para o usuário. Se essa interface não for implementada, há algum tipo de erro no sistema e simplesmente dizemos aos usuários que algo deu errado, já estamos fazendo isso, todos sabemos - como sempre.
Pipeline de consulta
Concluímos isso com as equipes e analisamos o que temos na pilha de leitura. Quanto ao pedido, validação, resposta diretamente - é a mesma coisa, não vamos parar separadamente. Ainda pode haver um cache adicional, mas em geral também não há grandes problemas com o cache.
Segurança
Vamos dar uma olhada melhor em uma verificação de segurança. Também pode haver o mesmo decorador de segurança, que verifica se esta solicitação pode ser feita ou não:

Mas há outro caso em que exibimos mais de um registro e exibimos listas. Para alguns usuários, precisamos exibir uma lista completa (por exemplo, para alguns superadministradores), e para outros usuários, temos que listar listas limitadas, terceirizadas. para outro, bem, e como costuma ser o caso em aplicativos corporativos, os direitos de acesso podem ser extremamente sofisticados; portanto, você precisa garantir que os dados que não visam esses usuários não entrem nessas listas.
O problema é resolvido de maneira
bastante simples . Podemos redefinir a interface (IPermissionFilter) na qual o questionável original chega e retorna questionável. A diferença é que, para o questionável que retorna, já impusemos condições adicionais onde, verificamos o usuário atual e dissemos: "Aqui, devolva apenas esses dados para esse usuário ..." - e então toda a sua lógica relacionada a permissões . Novamente, se você tem dois programadores, um programa usa permissões de gravação, ele sabe que precisa escrever apenas muitos filtros de permissão e verificar se eles funcionam corretamente para todas as entidades. E outros programadores não sabem nada sobre permissão, em sua lista os dados corretos simplesmente sempre passam, só isso. Porque eles recebem na entrada não mais o original consultável do dbContext, mas limitado a filtros. Esse permissionFilter também possui uma propriedade de layout, podemos adicionar e aplicar todos os permissionFilters. Como resultado, obtemos o permissionFilter resultante, que restringirá a seleção de dados ao máximo, levando em consideração todas as condições adequadas para essa entidade.

Por que não fazer isso com ferramentas internas do ORM, por exemplo, Filtros Globais em uma estrutura de entidade? Novamente, para não fazer dependências cíclicas e não arrastar nenhuma história adicional sobre sua camada de negócios para o contexto.
Pipeline de consulta. Ler modelo
Resta olhar para o modelo de leitura. O paradigma CQRS não usa o modelo de domínio na pilha de leitura; em vez disso, criamos imediatamente o Dto de que o navegador precisa no momento.

Se escrevermos em C #, provavelmente usaremos o LINQ, se não houver requisitos de desempenho monstruosos e, se houver, talvez você não tenha um aplicativo corporativo. Em geral, esse problema pode ser resolvido de uma vez por todas com um LinqQueryHandler. Aqui está uma restrição bastante assustadora sobre o genérico: esta é a Consulta, que retorna uma lista de projeções e ainda pode filtrar essas projeções e classificá-las. Ela também trabalha apenas com alguns tipos de entidades e sabe como converter essas entidades em projeções e retornar a lista dessas projeções na forma de Dto para o navegador.

A implementação do método Handle pode ser bastante simples. Por precaução, verifique se esse filtro TQuery é implementado para a entidade original. Além disso, fazemos uma projeção, é a extensão consultável AutoMapper. Se alguém ainda não souber, o AutoMapper pode criar projeções no LINQ, ou seja, aquelas que criarão o método Select e não mapeá-lo na memória.
Em seguida, aplicamos a filtragem, a classificação e exibimos tudo no navegador. , DotNext, ,
, , , , expression' , .
. , DotNext', — SQL. Select , , , queryable- .
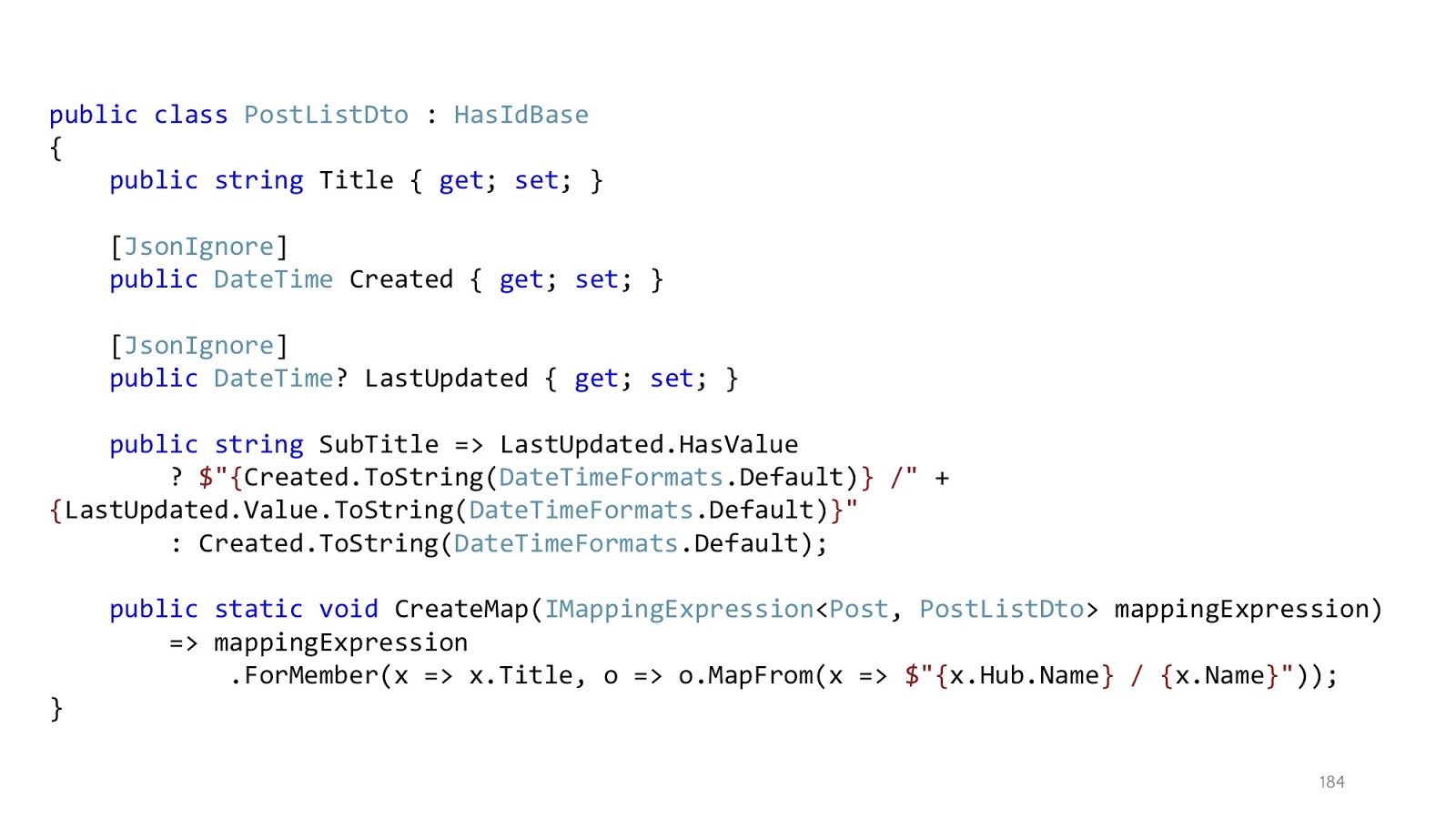
, . , Title, Title , . , . SubTitle, , , - , queryable- . , .
, . , , . , , . «JsonIgnore», . , , Dto. , , . JSON, , Created LastUpdated , SubTitle — , . , , , , , . , - .

. , -, , . , pipeline, . — , , . , SaveChanges, Query SaveChanges. , , , NuGet, .
. , - , , . , , , , , — . , , : « », — . .
, ?

- . .

, , , . MediatR , . , , — , MediatR pipeline behaviour. , Request/Response, RequestHandler' . Simple Injector, — .

, , , , TIn: ICommand.

Simple Injector' constraint' . , , , constraint', Handler', constraint. , constraint ICommand, SaveChanges constraint' ICommand, Simple Injector , constraint' , Handler'. , , , .
? Simple Injector MeriatR — , , Autofac', -, , , . , .
,
, «».
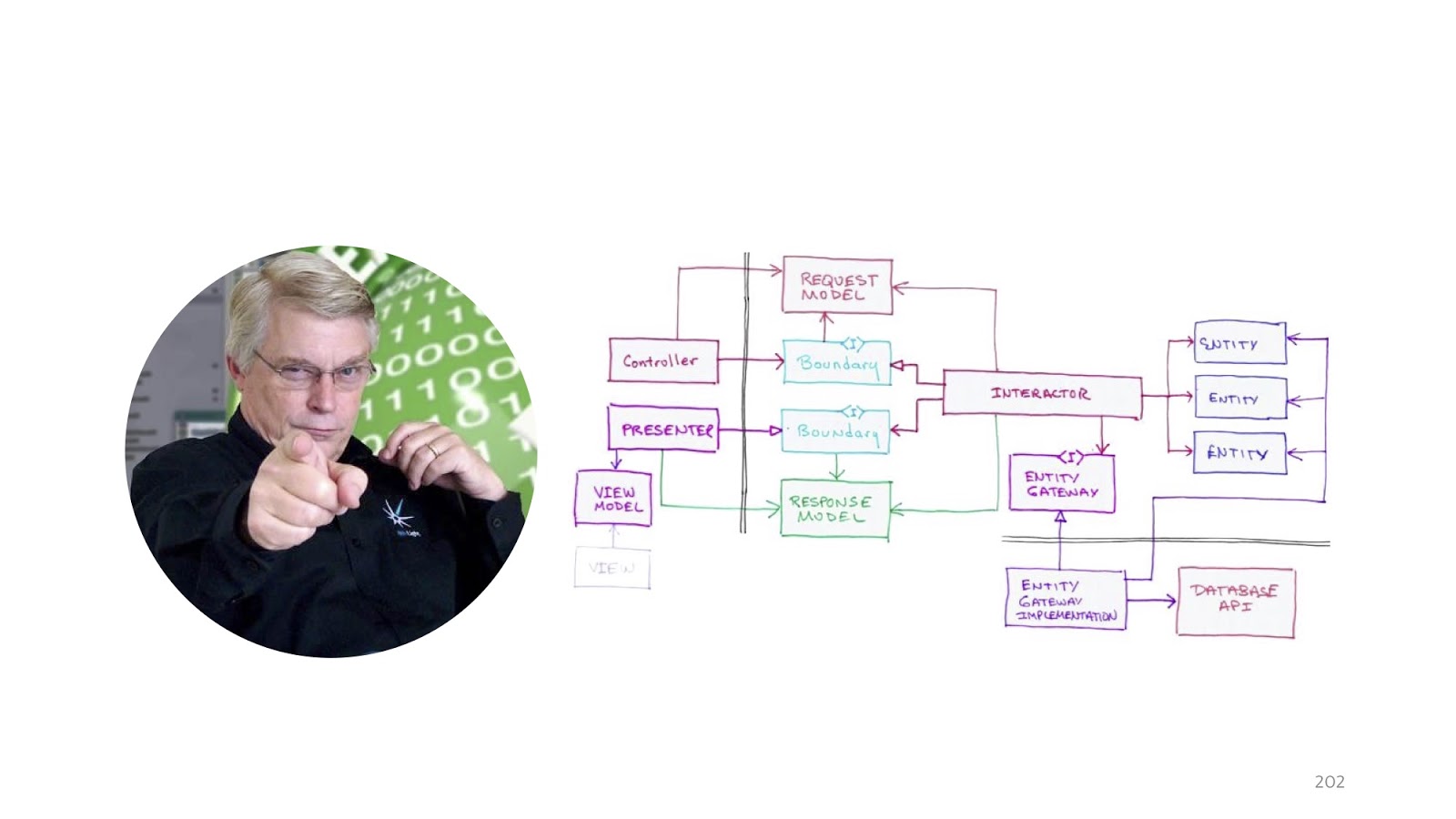
, «Clean architecture». .

- - , MVC, , .

, , , Angular, , , , . , : « — MVC-», : « Features, : , Blog - Import, - ».
, , , , MVC-, , - , . MVC . , , — . .


- , - -, .
-, , . , . , - , User Service, pull request', , User Service , . , - , - , . - , .
. , . , , , . , , , , , , , - . , ( , ), , «Delete»: , , . .
— «», , , , . , : , , , . , . , , . , , .
: . « », : , , . , , , , , , , . , . , - pull request , — , — - , . VCS : - , ? , - , , .

, , , . : . , . , , , , . , , , . , , . « », , . , , — , , .
: , - , . . - , , , , . - , - , , , , . .

. , IHandler . .
IHandler ICommandHandler IQueryHandler , . , , . , CommandHandler, CommandHandler', .
Porque , Query , Query — . , , , Hander, CommandHandler QueryHandler, - use case, .
— , , , , : , .
, . , . , -.
C# 8, nullable reference type . , , , , .
ChangeTracker' ORM.
Exception' — , F#, C#. , - , - , . , , Exception', , LINQ, , , , , , Dapper - , , , .NET.
, LINQ, , permission' — . , , - , , . , — .
. :
- Vertical Slices
- Domain Events
- DDD
- ROP
- LINQ Expressions:
- Clean Architecture

— . . — «Domain Modeling Made Functional», F#, F#, , , , , . C# , , Exception'.
, , — «Entity Framework Core In Action». , Entity Framework, , DDD ORM, , ORM DDD .
Minuto de publicidade. 15-16 2019 .NET- DotNext Piter, . , .