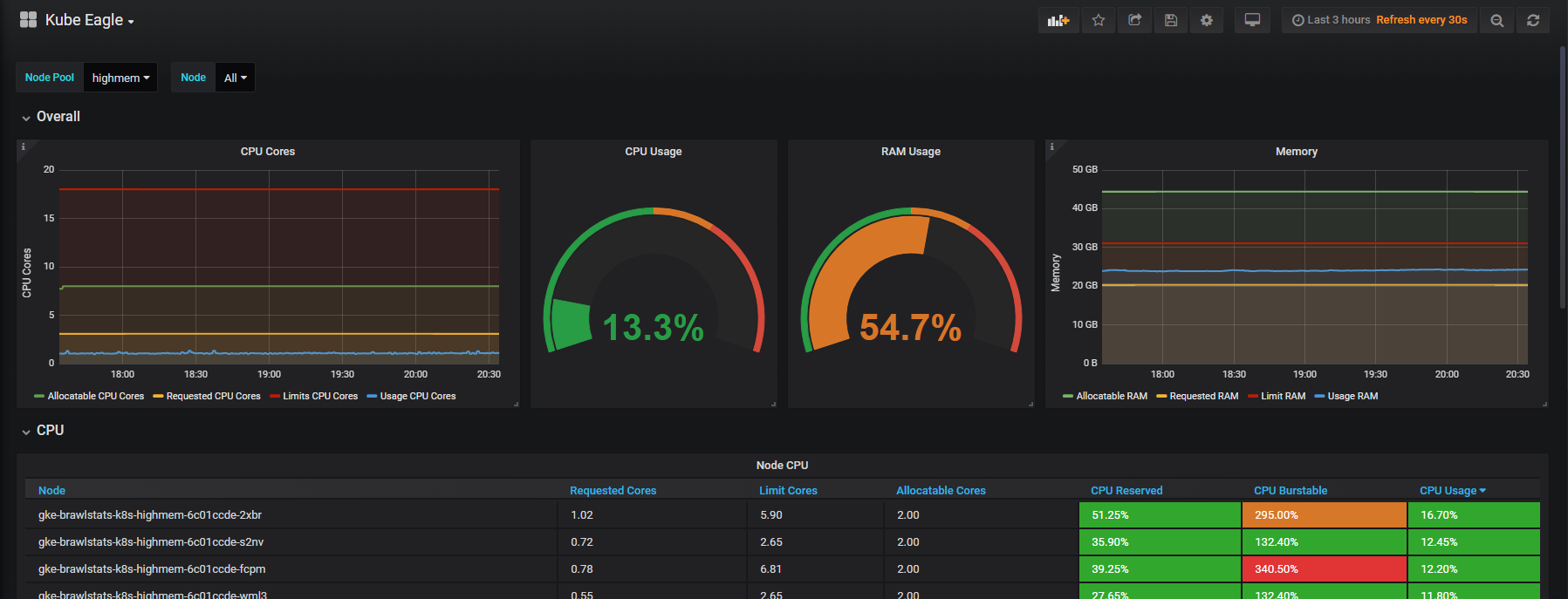
Criei a Kube Eagle - uma exportadora da Prometheus. Acabou sendo uma coisa interessante que ajuda a entender melhor os recursos de pequenos e médios clusters. Como resultado, economizei mais de cem dólares, porque selecionei os tipos certos de máquinas e configurei limites de recursos de aplicativos para cargas de trabalho.
Vou falar sobre as vantagens do Kube Eagle , mas primeiro vou explicar por que o barulho saiu e por que o monitoramento de alta qualidade foi necessário.
Eu gerenciei vários clusters de 4-50 nós. Em cada cluster - até 200 microsserviços e aplicativos. Para fazer melhor uso do hardware disponível, a maioria das implantações foi configurada com recursos de RAM e CPU expansíveis. Portanto, os pods podem usar os recursos disponíveis, se necessário, e ao mesmo tempo não interferem com outros aplicativos nesse nó. Bem, não é ótimo?
E, embora o cluster tenha consumido relativamente pouca CPU (8%) e RAM (40%), sempre tivemos problemas com a exclusão de lareiras quando tentavam alocar mais memória do que a disponível no nó. Depois, tínhamos apenas um painel para monitorar os recursos do Kubernetes. Aqui está um:
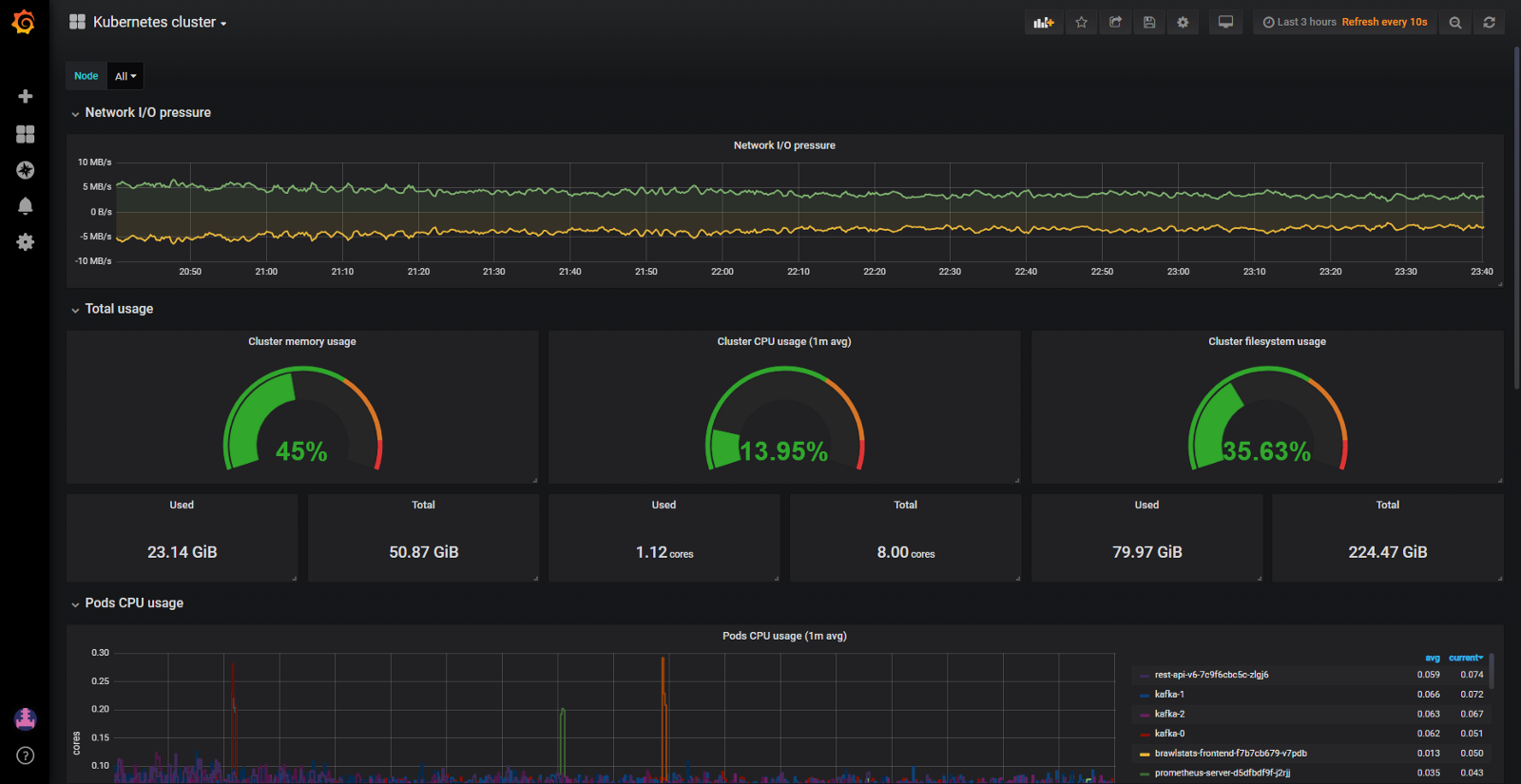
Painel Grafana apenas com métricas cAdvisor
Com esse painel, os nós que consomem muita memória e CPU não são um problema. O problema é descobrir o motivo. Para manter os pods no lugar, você pode, é claro, configurar recursos garantidos em todos os pods (os recursos solicitados são iguais ao limite). Mas esse não é o uso mais inteligente de ferro. Havia várias centenas de gigabytes de memória no cluster, enquanto alguns nós estavam passando fome, enquanto outros tinham 4-10 GB de reserva.
Acontece que o agendador do Kubernetes distribuiu cargas de trabalho pelos recursos disponíveis de maneira desigual. O Kubernetes Scheduler leva em consideração diferentes configurações: regras de afinidade, retenções e tolerâncias, seletores de nós que podem limitar os nós disponíveis. Mas, no meu caso, não havia nada disso, e os pods foram planejados dependendo dos recursos solicitados em cada nó.
Para a lareira, foi selecionado um nó que possui os recursos mais livres e que satisfaz as condições de solicitação. Descobriu-se que os recursos solicitados nos nós não correspondem ao uso real, e aqui o Kube Eagle e sua capacidade de monitorar recursos foram úteis.
Eu tenho quase todos os clusters do Kubernetes rastreados apenas com o exportador do Node e as métricas de estado do Kube . O Node Exporter fornece estatísticas de uso de E / S e disco, CPU e RAM, e o Kube State Metrics mostra métricas de objeto do Kubernetes, como solicitações e limites de recursos de CPU e memória.
Precisamos combinar as métricas de uso com as métricas de solicitação e limite no Grafana e, em seguida, obtemos todas as informações sobre o problema. Parece simples, mas, na verdade, essas duas ferramentas têm nomes diferentes para rótulos e algumas métricas não possuem rótulos de metadados. O Kube Eagle faz tudo sozinho e o painel fica assim:
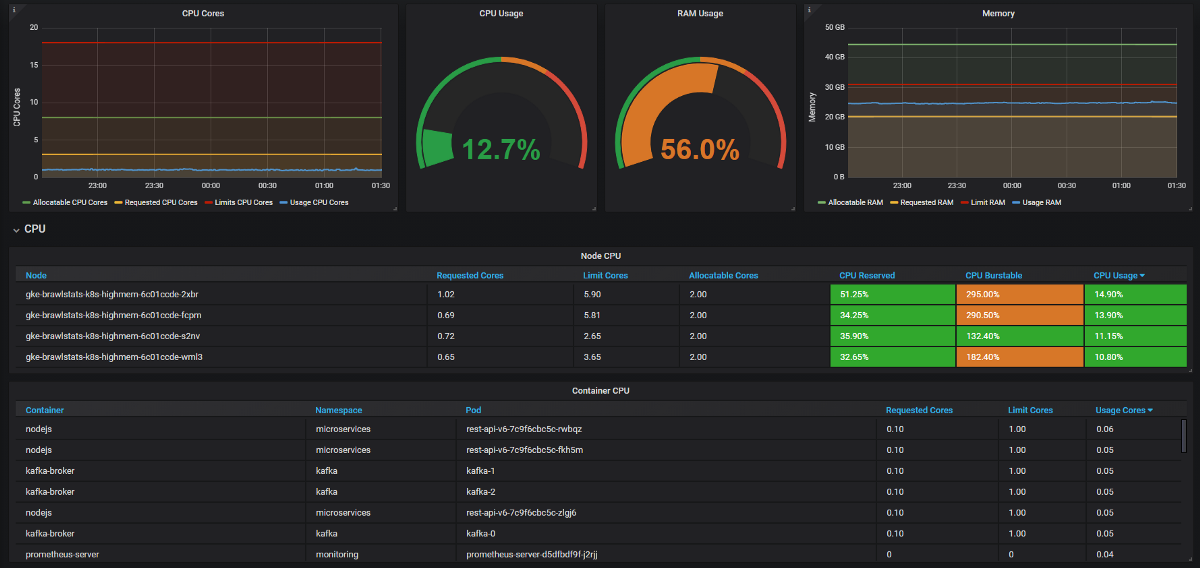
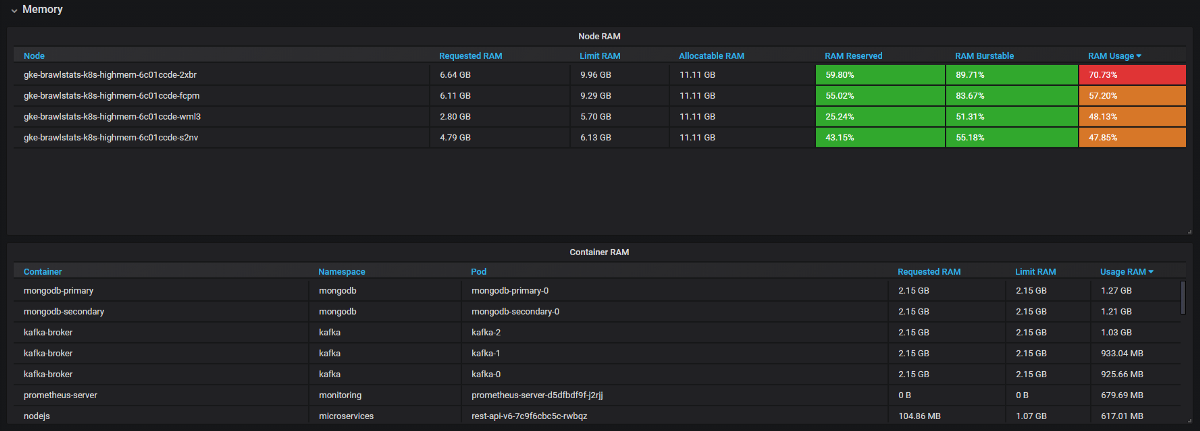
Kube Eagle Dashboard
Conseguimos resolver muitos problemas com recursos e economizar equipamentos:
- Alguns desenvolvedores não sabiam quantos recursos os microsserviços precisavam (ou simplesmente não se incomodavam). Não tínhamos nada para encontrar as solicitações erradas de recursos - para isso, precisamos conhecer o consumo, mais solicitações e limites. Agora eles veem as métricas do Prometheus, monitoram o uso real e ajustam consultas e limites.
- Os aplicativos JVM consomem tanta RAM quanto eles. O coletor de lixo libera memória apenas se mais de 75% estiver envolvido. E como a maioria dos serviços possui memória expansível, a JVM sempre a ocupou. Portanto, todos esses serviços Java consumiram muito mais RAM do que o esperado.
- Alguns aplicativos solicitaram muita memória e o agendador do Kubernetes não deu esses nós para outros aplicativos, embora, na verdade, eles fossem mais livres que outros nós. Um desenvolvedor acidentalmente adicionou um dígito extra na solicitação e pegou uma grande quantidade de RAM: 20 GB em vez de 2. Ninguém percebeu. Como o aplicativo tinha três réplicas, três nós foram afetados.
- Introduzimos limites de recursos, planejamos novamente os pods com as solicitações corretas e obtivemos o equilíbrio perfeito do uso de ferro em todos os nós. Geralmente, alguns nós podem ser fechados. E então vimos que tínhamos as máquinas erradas (orientadas à CPU, não orientadas à memória). Alteramos o tipo e excluímos mais alguns nós.
Sumário
Com recursos expansíveis em um cluster, você usa o hardware existente com mais eficiência, mas o agendador do Kubernetes agenda pods em solicitações de recursos, o que é complicado. Para matar dois coelhos com uma cajadada: para evitar problemas e usar os recursos ao máximo, é necessário um bom monitoramento. O Kube Eagle (exportador de Prometheus e painel Grafana) é útil para isso.