De fevereiro a março de 2019, foi realizada uma competição para classificar o feed da rede social SNA Hackathon 2019 , no qual nossa equipe ficou em primeiro lugar. Neste artigo, falarei sobre a organização do concurso, os métodos que tentamos e as configurações do catboost para treinamento em big data.

SNA Hackathon
A hackathon com esse nome é realizada pela terceira vez. Ele é organizado pela rede social ok.ru, respectivamente, a tarefa e os dados estão diretamente relacionados a essa rede social.
O SNA (análise de redes sociais), nesse caso, é melhor entendido não como uma análise de um gráfico social, mas como uma análise de uma rede social.
- Em 2014, a tarefa era prever o número de curtidas que o post obteria.
- Em 2016, o objetivo da VVZ (talvez você esteja familiarizado), mais próximo da análise do gráfico social.
- Em 2019 - classificação do feed de um usuário pela probabilidade de o usuário gostar da postagem.
Não posso dizer sobre 2014, mas em 2016 e 2019, além da capacidade de analisar dados, também foram necessárias habilidades no trabalho com big data. Penso que foi a combinação de tarefas de aprendizado de máquina e processamento de big data que me atraiu para esses concursos, e a experiência nessas áreas ajudou a vencer.
mlbootcamp
Em 2019, o concurso foi organizado na plataforma https://mlbootcamp.ru .
A competição começou on-line em 7 de fevereiro e consistia em 3 tarefas. Todos podem se registrar no site, baixar a linha de base e carregar o carro por várias horas. No final do estágio online, em 15 de março, os 15 principais de cada show foram convidados para o escritório Mail.ru, para o estágio offline, que ocorreu de 30 de março a 1 de abril.
Desafio
Os dados de origem fornecem identificadores de usuário (userId) e identificadores de postagem (objectId). Se foi mostrada uma postagem ao usuário, os dados conterão uma linha contendo userId, objectId, reações do usuário a essa postagem (feedback) e um conjunto de vários sinais ou links para figuras e textos.
| userId | objectId | ownerId | feedback | imagens |
|---|
| 3555 | 22 | 5677 | [gostei, clicou] | [hash1] |
| 12842 | 55 | 32144 | [não gostei] | [hash2, hash3] |
| 13145 | 35 | 5677 | [clicado, compartilhado novamente] | [hash2] |
O conjunto de dados de teste contém uma estrutura semelhante, mas o campo de feedback está ausente. O objetivo é prever a presença de uma reação 'curtida' no campo de feedback.
O arquivo de envio possui a seguinte estrutura:
| userId | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35.61.55 |
| 131 | 35,68,129,11 |
Métrica - AUC média do ROC por usuários.
Uma descrição mais detalhada dos dados pode ser encontrada no site da perfeição . Você também pode fazer o download dos dados, incluindo testes e imagens.
Estágio online
No estágio online, a tarefa foi dividida em 3 partes
- Sistema colaborativo - inclui todos os sinais, exceto imagens e textos;
- Imagens - inclui apenas informações sobre imagens;
- Textos - inclui informações apenas sobre textos.
Estágio offline
No estágio offline, os dados incluíam todos os atributos, enquanto os textos e imagens eram escassos. Havia 1,5 vezes mais linhas no conjunto de dados, das quais já havia muitas.
Resolução de problemas
Como estou trabalhando no currículo, comecei minha jornada nesta competição com a tarefa "Imagens". Os dados fornecidos são userId, objectId, ownerId (o grupo em que a postagem é publicada), carimbos de data e hora de criação e exibição da postagem e, é claro, a imagem dessa postagem.
Depois de gerar vários recursos com base no registro de data e hora, a próxima idéia foi pegar a penúltima camada de um neurônio pré-treinado em imagenet e enviar essas incorporações para aumentar.
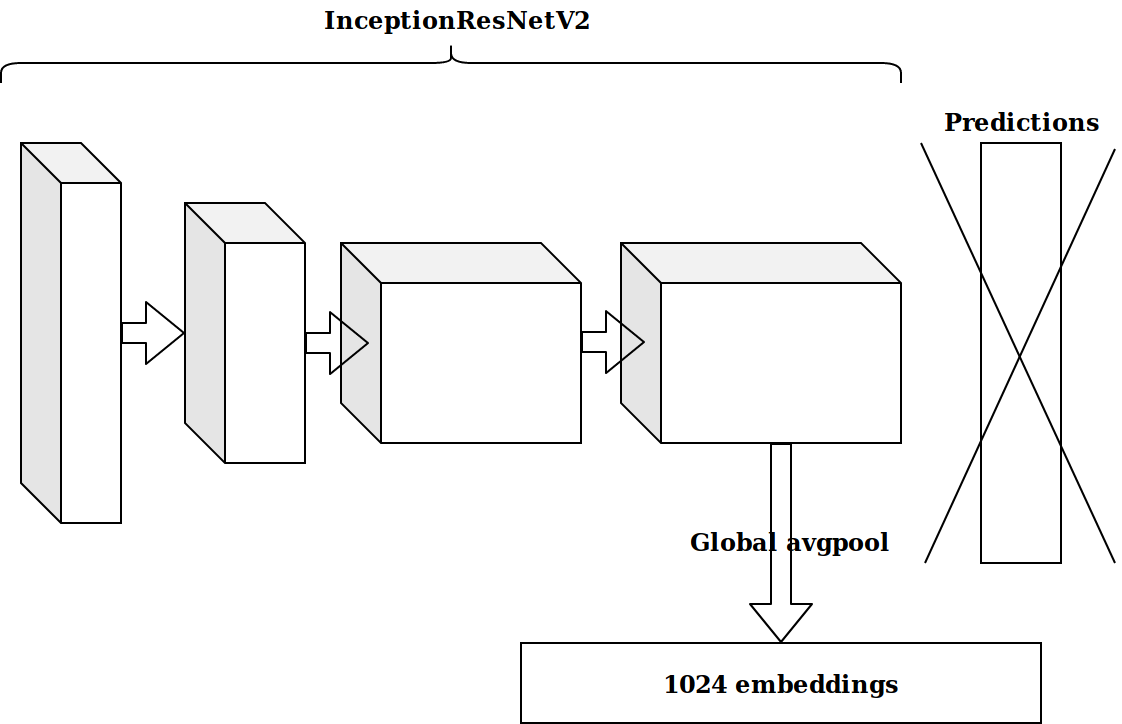
Os resultados não foram impressionantes. Casamentos do neurônio imagenet são irrelevantes, pensei, preciso arquivar meu codificador automático.
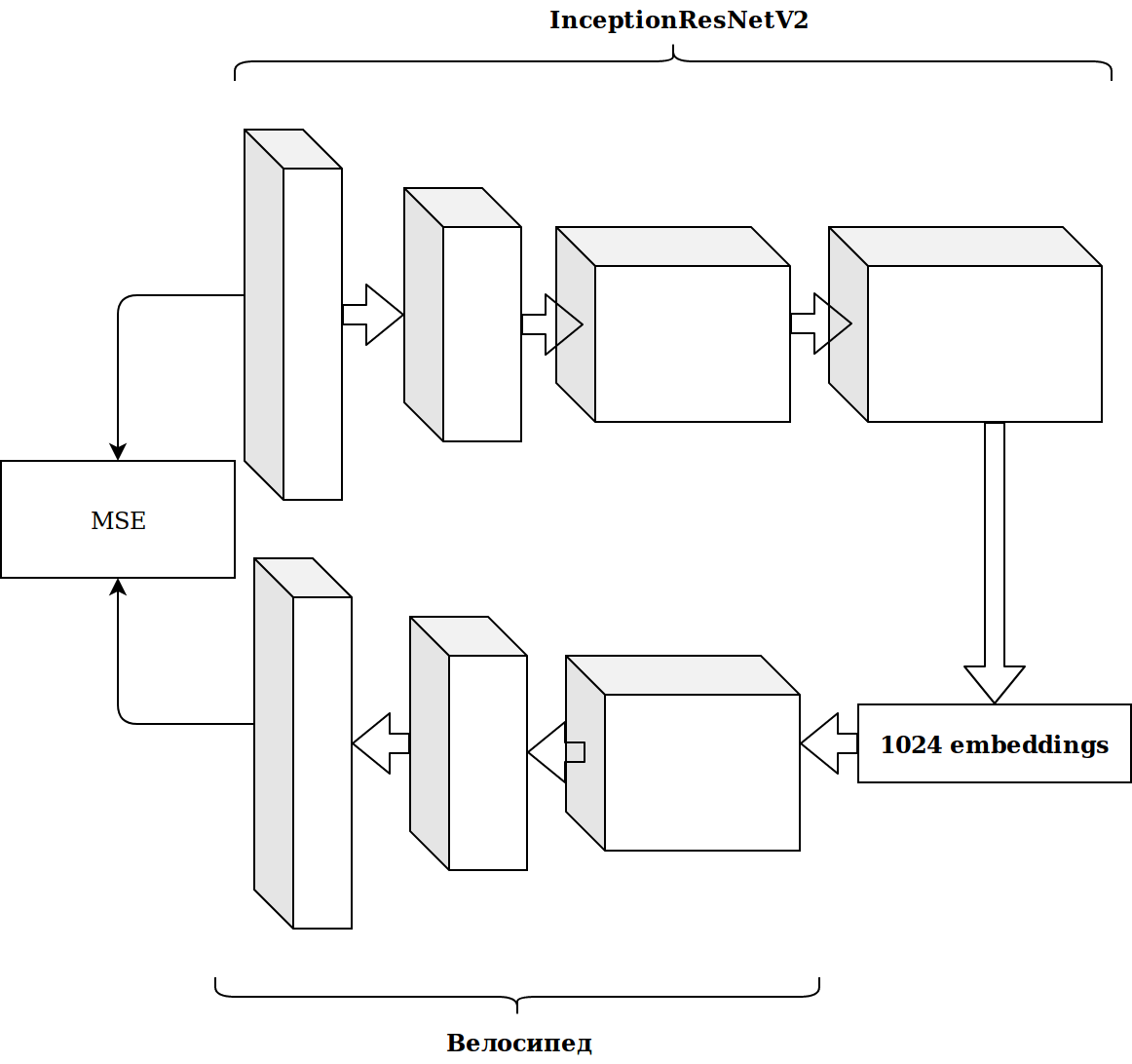
Demorou muito tempo e o resultado não melhorou.
Geração de recursos
Trabalhar com imagens leva muito tempo e decidi fazer algo mais simples.
Como você pode ver imediatamente, existem vários sinais categóricos no conjunto de dados e, para não incomodar muito, eu apenas peguei o catboost. A solução foi excelente, sem configurações, cheguei imediatamente à primeira linha da tabela de classificação.
Há muitos dados, e eles são dispostos em formato de parquet; portanto, sem pensar duas vezes, peguei o scala e comecei a escrever tudo com fagulha.
Os recursos mais simples, que deram mais crescimento do que as imagens incorporadas:
- quantas vezes objectId, userId e ownerId se encontraram nos dados (devem se correlacionar com a popularidade);
- quantas postagens de userId o ownerId viu (deve se correlacionar com o interesse do usuário no grupo);
- quantas postagens assistidas por userId exclusivas por ownerId (refletem o tamanho do público do grupo).
A partir dos registros de data e hora, era possível obter a hora do dia em que o usuário assistia à fita (manhã / dia / tarde / noite). Ao combinar essas categorias, você pode continuar a gerar recursos:
- quantas vezes o userId efetuou login à noite;
- a que horas essa postagem geralmente é exibida (objectId) e assim por diante.
Tudo isso melhorou gradualmente a métrica. Mas o tamanho do conjunto de dados de treinamento é de cerca de 20 milhões de registros, portanto, a adição de recursos desacelerou bastante o aprendizado.
Redefini a abordagem de uso de dados. Embora os dados dependam do tempo, não vi nenhum vazamento explícito de informações no futuro; no entanto, por precaução, eu os quebrei da seguinte maneira:
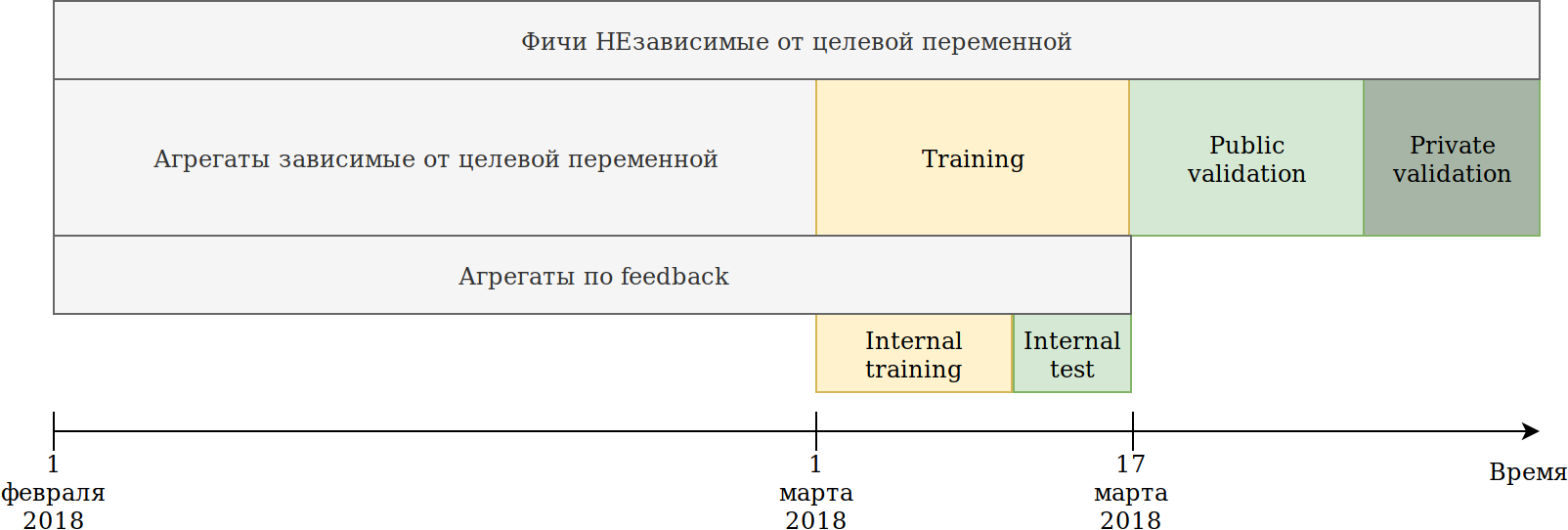
O conjunto de treinamento fornecido a nós (fevereiro e 2 semanas de março) foi dividido em 2 partes.
Nos dados dos últimos N dias, ele treinou o modelo. As agregações descritas acima foram construídas em todos os dados, incluindo o teste. Ao mesmo tempo, surgiram dados nos quais vários codificadores da variável de destino podem ser construídos. A abordagem mais simples é reutilizar o código que já está criando novos recursos e simplesmente fornecer dados que não serão treinados e segmentar = 1.
Assim, temos recursos semelhantes:
- Quantas vezes o userId viu uma postagem no grupo ownerId;
- Quantas vezes userId gostou da postagem em ownerId;
- A porcentagem de postagens que userId gostou de ownerId.
Ou seja, resultou na codificação de destino médio por parte do conjunto de dados de acordo com várias combinações de recursos categóricos. Em princípio, o catboost também cria codificação de destino e, desse ponto de vista, não há benefício, mas, por exemplo, tornou-se possível contar o número de usuários únicos que gostam de postagens neste grupo. Ao mesmo tempo, o principal objetivo foi alcançado - meu conjunto de dados diminuiu várias vezes e foi possível continuar gerando recursos.
Enquanto o catboost só pode criar codificadores de acordo com a reação desejada, o feedback tem outras reações: compartilhadas de novo, não curtidas, não curtidas, clicadas, ignoradas, o que pode ser feito manualmente. Contei todos os tipos de agregados e selecionei os recursos com pouca importância, para não aumentar o conjunto de dados.
Naquela época, eu estava em primeiro lugar por uma ampla margem. O único constrangimento foi o fato de a incorporação das imagens quase não ter ganho. A idéia veio para dar tudo para aumentar o poder. Agrupe imagens do Kmeans e obtenha um novo recurso categórico imageCat.
Aqui estão algumas classes depois de filtrar e mesclar manualmente os clusters obtidos do KMeans.

Com base no imageCat, geramos:
- Novos recursos categóricos:
- Que imageCat mais parecia userId;
- Qual imageCat é mostrado com mais frequência pelo ownerId;
- Qual imageCat gostou mais do userId;
- Vários contadores:
- Quantos imageCat únicos pareciam userId;
- Cerca de 15 recursos semelhantes, além da codificação de destino, conforme descrito acima.
Textos
Os resultados do concurso de imagens combinaram comigo e eu decidi me experimentar nos textos. Anteriormente, não trabalhava muito com textos e, por estupidez, matei um dia no tf-idf e no svd. Então vi uma linha de base com o doc2vec, que faz exatamente o que eu preciso. Depois de ajustar ligeiramente os parâmetros do doc2vec, recebi inserções de texto.
E, em seguida, ele simplesmente reutilizou o código das imagens, no qual substituiu os incorporados de imagem por incorporados de texto. Como resultado, cheguei ao 2º lugar no concurso de texto.
Sistema colaborativo
Havia apenas uma competição na qual eu ainda não tinha "cutucado o bastão", mas, a julgar pela AUC na tabela de líderes, os resultados dessa competição em particular deveriam ter tido o maior impacto no estágio off-line.
Peguei todos os sinais que estavam nos dados de origem, selecionei os categóricos e calculei os mesmos agregados das imagens, exceto os recursos das próprias imagens. Apenas colocando no catboost, cheguei ao 2º lugar.
Os primeiros passos para otimizar o catboost
Um primeiro e dois segundos lugares me agradaram, mas havia um entendimento de que eu não fiz nada de especial, o que significa que podemos esperar uma perda de posição.
A tarefa da competição é classificar as postagens na estrutura do usuário e, durante todo esse tempo, resolvi o problema de classificação, ou seja, otimizei a métrica errada.
Vou dar um exemplo simples:
| userId | objectId | predição | verdade fundamental |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0,8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 1 |
| 1 | 14 | 0,5 | 0 0 |
| 2 | 15 | 0,4 | 0 0 |
| 2 | 16 | 0,3 | 1 |
Fazemos uma pequena permutação
| userId | objectId | predição | verdade fundamental |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0,8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 0 0 |
| 2 | 16 | 0,5 | 1 |
| 2 | 15 | 0,4 | 0 0 |
| 1 | 14 | 0,3 | 1 |
Obtemos os seguintes resultados:
| Modelo | Auc | AUC do usuário1 | AUC do usuário2 | AUC média |
|---|
| Opção 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| Opção 2 | 0,7 | 0,75 | 1,0 | 0.875 |
Como você pode ver, melhorar a métrica geral da AUC não significa melhorar a métrica média da AUC dentro do usuário.
O Catboost pode otimizar as métricas de classificação imediatamente. Eu li sobre métricas de classificação, histórias de sucesso ao usar o catboost e defino o YetiRankPairwise para estudar durante a noite. O resultado não foi impressionante. Tendo decidido que não havia aprendido bem, alterei a função de erro para QueryRMSE, que, a julgar pela documentação do catboost, converge mais rapidamente. Como resultado, obtive os mesmos resultados que durante o treinamento para classificação, mas os conjuntos desses dois modelos deram um bom aumento, o que me levou aos primeiros lugares nas três competições.
5 minutos antes do encerramento da etapa on-line na competição Collaborative Systems, Sergey Shalnov me levou para o segundo lugar. A maneira como fomos juntos.
Preparando para a fase offline
A vitória no estágio on-line nos foi garantida na placa de vídeo RTX 2080 TI, mas o prêmio principal de 300.000 rublos e, antes, o primeiro lugar final nos forçaram a trabalhar nessas duas semanas.
Como se viu, Sergey também usou o catboost. Trocamos idéias e recursos, e eu descobri o relatório de Anna Veronika Dorogush, no qual havia respostas para muitas de minhas perguntas e até para aquelas que ainda não havia aparecido.
A visualização do relatório levou-me à idéia de que é necessário retornar todos os parâmetros ao valor padrão e ajustar as configurações com muito cuidado e somente depois de corrigir um conjunto de sinais. Agora, um treinamento levou cerca de 15 horas, mas um modelo conseguiu melhorar a velocidade do que no ensemble de classificação.
Geração de recursos
Na competição "Sistemas colaborativos", um grande número de recursos é avaliado como importante para o modelo. Por exemplo, auditweights_spark_svd é o atributo mais importante e não há informações sobre o que isso significa. Eu pensei que valia a pena contar as várias unidades com base em sinais importantes. Por exemplo, a média auditweights_spark_svd por usuário, por grupo, por objeto. O mesmo pode ser calculado a partir de dados nos quais o treinamento não é realizado e o destino = 1, ou seja, a média auditweights_spark_svd por usuário para os objetos que ele gostou. Havia vários sinais importantes, além de auditweights_spark_svd . Aqui estão alguns deles:
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
Por exemplo, o valor médio de auditweightsCtrGender por userId acabou por ser um recurso importante, bem como o valor médio de userOwnerCounterCreateLikes por userId + ownerId. Isso deveria ter nos levado a pensar em como entender o significado dos campos.
Outros recursos importantes foram auditweightsLikesCount e auditweightsShowsCount . Dividindo um no outro, foi obtida uma característica ainda mais importante.
Vazamentos de dados
Modelos de competição e produção são tarefas muito diferentes. Ao preparar os dados, é muito difícil levar em consideração todos os detalhes e não transferir algumas informações não triviais sobre a variável de destino no teste. Se criarmos uma solução de produção, tentaremos evitar o uso de vazamentos de dados ao treinar o modelo. Mas se queremos vencer o concurso, os vazamentos de dados são os melhores recursos.
Após examinar os dados, você pode ver que, de acordo com objectId, os valores de auditweightsLikesCount e auditweightsShowsCount mudam, o que significa que a proporção dos valores máximos desses sinais refletirá a pós-conversão muito melhor que a proporção no momento da entrega.
O primeiro vazamento encontrado foi auditweightsLikesCountMax / auditweightsShowsCountMax .
Mas e se você olhar os dados com mais atenção? Classifique por data de entrega e obtenha:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | alvo (gostou) |
|---|
| 1 | 1 | 12 | 3 | provavelmente não |
| 1 | 2 | 15 | 3 | provavelmente sim |
| 1 | 3 | 16 | 4 | |
Foi surpreendente quando encontrei o primeiro exemplo desse tipo e verificamos que minha previsão não se tornou realidade. Mas, como os valores máximos desses sinais na estrutura do objeto aumentaram, não fomos preguiçosos e decidimos encontrar auditweightsShowsCountNext e auditweightsLikesCountNext , ou seja, valores no próximo momento. Adicionando recurso
(auditweightsShowsCountNext-auditweightsShowsCount) / (auditweightsLikesCount-auditweightsLikesCountNext) fizemos um salto acentuado o tempo todo.
Vazamentos semelhantes poderiam ser usados se os seguintes valores fossem encontrados para userOwnerCounterCreateLikes dentro de userId + ownerId e, por exemplo, auditweightsCtrGender dentro de objectId + userGender. Encontramos 6 campos semelhantes com vazamentos e extraímos informações deles o máximo possível.
Naquela época, extraímos o máximo de informações de atributos colaborativos, mas não retornamos a concursos de imagens e textos. Houve uma ótima idéia para verificar: quanto os recursos dão diretamente nas imagens ou textos nas competições correspondentes?
Não houve vazamentos nas competições de imagens e textos, mas naquela época eu havia retornado os parâmetros padrão do catboost, penteei o código e adicionei alguns recursos. Resultado total:
| Solução | velocidade |
|---|
| Máximo com imagens | 0,6411 |
| Máximo sem imagens | 0,6297 |
| Resultado do segundo lugar | 0,6295 |
| Solução | velocidade |
|---|
| Máximo com textos | 0,666 |
| Máximo sem textos | 0,660 |
| Resultado do segundo lugar | 0,656 |
| Solução | velocidade |
|---|
| Máximo em colaboração | 0,745 |
| Resultado do segundo lugar | 0,723 |
Tornou-se óbvio que era improvável que muitos textos e imagens fossem extraídos e, depois de tentar algumas das idéias mais interessantes, paramos de trabalhar com eles.
A geração adicional de recursos em sistemas colaborativos não deu crescimento e começamos a classificar. No estágio on-line, o conjunto de classificação e classificação me deu um pequeno aumento, como se viu porque eu tinha uma classificação insuficiente. Nenhuma das funções de erro, incluindo o YetiRanlPairwise, forneceu resultados próximos do LogLoss (0,745 contra 0,725). Havia esperança de um QueryCrossEntropy que não pudesse ser iniciado.
Estágio offline
No estágio offline, a estrutura de dados permaneceu a mesma, mas houve pequenas alterações:
- identificadores userId, objectId, ownerId foram re-randomizados;
- vários sinais foram removidos e vários foram renomeados;
- os dados se tornaram cerca de 1,5 vezes mais.
Além das dificuldades listadas, havia uma grande vantagem: um servidor grande com RTX 2080TI foi alocado para a equipe. Eu gostei do htop por um longo tempo.
A idéia era única - apenas reproduzir o que já está lá. Depois de passar algumas horas configurando o ambiente no servidor, gradualmente começamos a verificar se os resultados estavam sendo reproduzidos. O principal problema que estamos enfrentando é o aumento no volume de dados. Decidimos reduzir um pouco a carga e definir o parâmetro catboost ctr_complexity = 1. Isso diminui um pouco a velocidade, mas meu modelo começou a funcionar, o resultado foi bom - 0,733. Sergei, diferentemente de mim, não dividiu os dados em duas partes e treinou em todos os dados, embora isso tenha proporcionado o melhor resultado no estágio on-line, houve muitas dificuldades no estágio off-line. Se pegarmos todos os recursos que geramos e tentarmos colocá-lo no catboost "na testa", nada aconteceria no estágio online. Sergey fez otimização de tipo, por exemplo, convertendo tipos float64 em float32. Neste artigo, você pode encontrar informações sobre como otimizar a memória nos pandas. Como resultado, Sergey treinou na CPU todos os dados e resultou em cerca de 0,735.
Esses resultados foram suficientes para vencer, mas escondemos nossa velocidade real e não podíamos ter certeza de que outras equipes não estavam fazendo o mesmo.
Batalha até o último
Catboost de ajuste
Nossa solução foi totalmente reproduzida, adicionamos recursos de dados de texto e imagens, então tudo o que restava era ajustar os parâmetros do catboost. Sergey estudou na CPU com um pequeno número de iterações e eu estudei com ctr_complexity = 1. Restava apenas um dia e, se você apenas adicionar iterações ou aumentar o ctr_complexity, de manhã, poderá obter uma velocidade ainda melhor e caminhar o dia todo.
No estágio offline, as pontuações podem ser muito fáceis de ocultar, simplesmente escolhendo a melhor solução no site. Esperávamos mudanças bruscas na tabela de classificação nos últimos minutos antes do fechamento das inscrições e decidimos não parar.
No vídeo de Anna, aprendi que, para melhorar a qualidade do modelo, é melhor selecionar os seguintes parâmetros:
- learning_rate - O valor padrão é calculado com base no tamanho do conjunto de dados. Com uma diminuição na taxa de aprendizado, para manter a qualidade, é necessário aumentar o número de iterações.
- l2_leaf_reg - Coeficiente de regularização, valor padrão de 3, de preferência de 2 a 30. Uma diminuição no valor leva a um aumento no excesso de ajuste.
- bagging_temperature - Adiciona randomização aos pesos dos objetos na seleção. O valor padrão é 1, no qual os pesos são selecionados na distribuição exponencial. Uma diminuição no valor leva a um aumento no excesso de ajuste.
- random_strength - afeta a escolha de divisões para uma iteração específica. Quanto maior a força aleatória, maior a chance de uma divisão de baixa importância ser selecionada. A cada iteração subsequente, a aleatoriedade diminui. Uma diminuição no valor leva a um aumento no excesso de ajuste.
Outros parâmetros afetam significativamente menos o resultado final, então não tentei selecioná-los. Uma iteração de treinamento no meu conjunto de dados da GPU com ctr_complexity = 1 levou 20 minutos e os parâmetros selecionados no conjunto de dados reduzido foram ligeiramente diferentes dos ideais no conjunto de dados completo. Como resultado, fiz cerca de 30 iterações em 10% dos dados e depois mais 10 iterações em todos os dados. Aconteceu aproximadamente o seguinte:
- Aumentei o learning_rate em 40% do padrão;
- l2_leaf_reg deixou o mesmo;
- bagging_temperature e random_strength reduzidos para 0.8.
Podemos concluir que, com parâmetros padrão, o modelo é sub-treinado.
, :
| Modelo | 1 | 2 | 3 | |
|---|
| 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| 0.7406 | 0.7405 | 0.7406 | 0.7408 |
, , .
GPU. — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
.
. , , , 2 .
Conclusão
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- , . . , , .
- , .
- , .

, .